






MySQL
数据库
- DOS命令 启动和关闭MySQL数据库
net start mysql
net stop mysql
- DOS命令 连接到MySQL
mysql -h 主机名 -P 端口 -u 用户名 -p密码
创建数据库 (进入mysql命令行执行)
-- 使用指令创建数据库
CREATE DATABASE db_name;
-- 删除数据库指令
DROP DATABASE db_name
-- 创建一个使用 utf8字符集 的数据库
CREATE DATABASE db_name CHARSET utf8
-- 创建一个使用 utf8字符集,并带校对规则的 数据库
CREATE DATABASE db_name CHARSET utf8 COLLATE utf8_bin
-- 校对规则 utf8_bin 区分大小 默认utf8_general_ci 不区分大小写
查询数据库 (进入mysql命令行执行)
- 查看当前数据库服务器中的所有数据库
SHOW DATABASES
- 查看前面创建的数据库的定义信息
SHOW CREATE DATABASE `db_name`
-- 老师说明 在创建数据库,表的时候,为了规避关键字,可以使用反引号解决
切换数据库
USE db_name
备份数据库 (退出mysql命令行执行)
mysqldump -u 用户名 -p -B 数据库1 数据库2 数据库n > d:\\文件名.sql
备份数据库的表
mysqldump -u 用户名 -p 数据库 表1 表2 表n > d:\\文件名.sql
恢复数据库(进入mysql命令行执行)
- source d:\文件名.sql
- 复制sql文件里的所有语句 到查询编辑器中
表
- 选择对哪个数据库进行操作
USE db_name
创建表
CREATE TABLE table_name ( column_name1 datatype,column_name2 datatype ...)
CHARSET utf8 #字符集
COLLATE utf8_bin #校对规则
ENGINE INNODB; #引擎
删除表
DROP TABLE table_name
修改表
- 添加列
ALTER TABLE table_name ADD column_name datatype... [AFTER column_name]
- 修改列
ALTER TABLE table_name MODIFY column_name datatype...
- 删除列
ALTER TABLE table_name DROP column_name
- 修改列名
ALTER TABLE table_name CHANGE column_name new_name datatype
- 查看表结构
DESC table_name
- 修改表名
RENAME TABLE table_name TO new_name
- 修改表的字符集
ALTER TABLE table_name CHARSET utf8
MySQL列类型

数据库CRUD
insert语句(添加数据)
- 基本语法
INSERT INTO table_name (column_name...) VALUES (expr...);
- 使用细节
-- 1.插入的数据应与字段的数据类型相同
-- 比如 把 'abc' 添加到 int 类型会错误
INSERT INTO `goods` (id, goods_name, price)
VALUES('abc', '苹果手机', 2000);
-- 2. 数据的长度应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中
INSERT INTO `goods` (id, goods_name, price)
VALUES(40, 'vovo手机vovo手机vovo手机vovo手机vovo手机', 3000);
-- 3. 在values中列出的数据位置必须与被加入的列的排列位置相对应
INSERT INTO `goods` (id, goods_name, price) -- 不对
VALUES('vivo手机',40, 2000);
-- 4. 字符和日期型数据应包含在单引号中
INSERT INTO `goods` (id, goods_name, price)
VALUES(40, vivo手机, 3000); -- 错误的 vivo手机 应该 'vivo手机'
-- 5. 列可以插入空值[前提是该字段允许为空],insert into table value(null)
INSERT INTO `goods` (id, goods_name, price)
VALUES(40, 'vivo手机', NULL);
-- 6. insert into tab_name (列名..) values (),(),() 形式添加多条记录
INSERT INTO `goods` (id, goods_name, price)
VALUES(50, '三星手机', 2300),(60, '华为手机', 1800);
-- 7. 如果是给表中的所有字段添加数据,可以不写前面的字段名称
INSERT INTO `goods` VALUES(70, '小米手机', 2000);
-- 8. 默认值的使用,当不给某个字段值时,如果有默认值就会添加默认值,否则报错
-- 如果某个列 没有指定 not null ,那么当添加数据时,没有给定值,则会默认给null
-- 如果我们希望指定某个列的默认值,可以在创建表时指定 default
Update语句(更新数据)
- 基本语法
UPDATE table_name SET column_name=expr ... [WHERE where_definition];
- 使用细节
- UPDATE语法可以更新原有表行的各列数据
- SET 指示要修改的列和修改的值
- WHERE 指定更新哪些行,!如果不写WHERE会更新所有行!
- 如果需要修改多个列,可以通过逗号间隔
SET 列1=值1,列2=值2 ...[WHERE ...]
Delete语句(删除数据)
- 基本语法
DELETE FROM table_name [WHERE where_definition]
- 使用细节
- WHERE 指定删除哪些行,如果不写WHERE,会删除所有行,索引不重置 不回收空间
- truncate语句 删除表中所有行,索引重置并释放空间,不能rollback,效率高
TRUNCATE TABLE table_name
- Delete语句只能删除整行,不能指定删除列的值(可以使用update 为 null)
- Delete语句只是删除数据,不删除表本身
Select语句(查询数据)
- 基本语法
- DISTINCT可选,指显示结果时,是否去掉重复数据
- *代表所有列,也可以指定查询哪些列
- FROM 指定查询的表
SELECT [DISTINCT] * | column1,column2... FROM table_name [WHERE where_definition]
可以使用表达式对列计算
-- 比如:查询 name 和 column1+column2
-- 任意数和null 计算 结果为null
SELECT [DISTINCT] `name`,(column1+column2) FROM table_name
as语句 更改显示的列名
SELECT column1_name AS new1_name,column2_name AS new2_name... FROM table_name
-- 也可以不写,如果别名有空格需要加''
SELECT column1_name 'new1 name',column2_name new2_name... FROM table_name
where语句经常使用的运算符
-- < > = >= <= != 基本运算符
-- BETWEEN ... AND ... 显示值在某闭区间的数据
SELECT * FROM table_name WHERE column_name BETWEEN 10 AND 100
-- IN 显示值在某列表中的数据
SELECT * FROM table_name WHERE column_name IN(10,11,12)
-- LIKE / NOT LIKE 模糊查询
SELECT * FROM table_name WHERE column_name LIKE '李%'
SELECT * FROM table_name WHERE column_name NOT LIKE '李%'
-- IS NULL 显示值为空的数据
SELECT * FROM table_name WHERE column_name IS NULL
-- AND 和 显示多个条件同时成立的数据
SELECT * FROM table_name WHERE column1>10 AND column2>10
-- OR 或 显示满足任一条件的数据
SELECT * FROM table_name WHERE column1>10 OR column2>10
-- NOT 显示条件不成立的数据
SELECT * FROM table_name WHERE NOT (column_name>10)
order by语句排序查询
- 基本语法
ASC 升序(默认)、DESC 降序
SELECT [DISTINCT] * | column1,column2... FROM table_name ORDER BY column_name asc | desc;
函数
统计函数
- count 统计数量
SELECT COUNT(* | column_name) FROM table_name
-- count(*)返回满足条件数据的行数
-- count(column) 满足条件的某列 有多少行,会排除 null 的数据
- sum 求和
SELECT SUM(column_name) FROM table_name
- avg 求平均值
SELECT AVG(column_name) FROM table_name
- max 求最大值
SELECT MAX(column_name) FROM table_name
- min 求最小值
SELECT MIN(column_name) FROM table_name
group by语句 进行分组统计
having 后加条件 进行过滤
- 基本语法
SELECT column1,column2... FROM table_name GROUP BY column_name [HAVING ...]
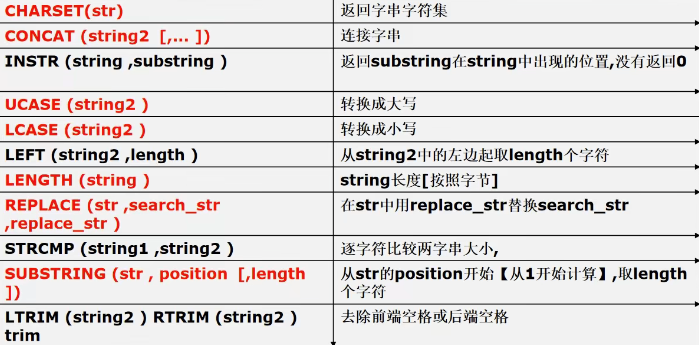
字符串相关函数
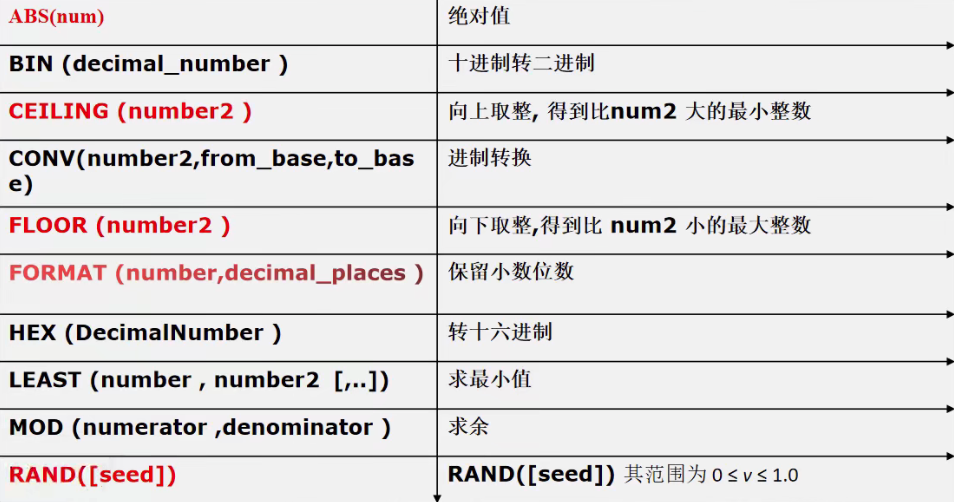
数学相关函数
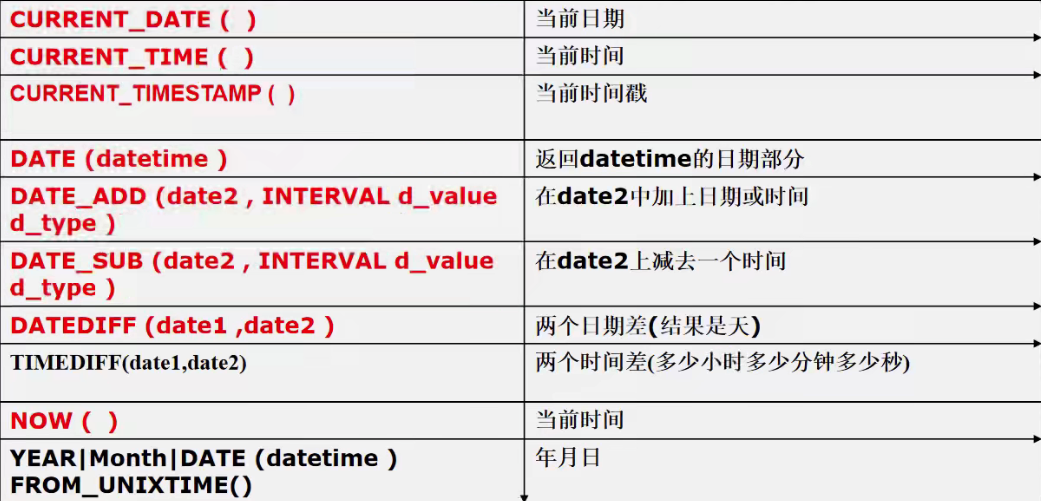
日期相关函数
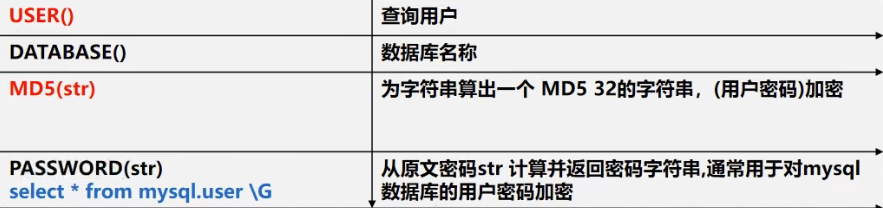
系统和加密函数
流程控制函数

多子句查询
- 基本语法
GROUP BY column [HAVING …] 分组查询
ORDER BY column [LIMIT start,rows] 分表查询 start = (页数-1) * rows ; rows是每页个数
SELECT * | column1,column2... FROM table_name
[GROUP BY column1
HAVING condition
ORDER BY column1
LIMIT start,rows]
多表查询
- 多表查询没有过滤,默认处理后的结果称为 笛卡尔集
SELECT * | column1,column2... FROM table1_name,table2_name...
- 解决笛卡尔集的关键就是要写出正确的过滤条件 WHERE
SELECT * | column1,column2... FROM table1_name,table2_name... WHERE ...
- 如果多表查询中有重复的列名,需要用 表名.列名
自连接
- 自连接是指在同一张表的连接查询【把同一张表当做两张表使用】
- 需要给表取别名
SELECT table1.column_name,table2.column_name FROM table0 table1,table0 table2 WHERE ...
mysql表子查询
- 子查询是指嵌套在其他sql语句中的select语句,也叫嵌套查询
多行子查询
- 多行子查询是指返回多行数据的子查询
SELECT * | column1... FROM table_name
WHERE column1 IN (SELECT column2
FROM table_name
WHERE ...)
多列子查询
- 多列子查询是指查询返回多列数据的子查询语句
SELECT * | column1... FROM table_name
WHERE(column1,column2 ...) = (SELECT column1,column2...
FROM table_name
WHERE ...)
表的复制和去重
CREATE TABLE table02 LIKE table01
INSERT INTO table02 SELECT DISTINCT * FROM table01
DELETE FROM table01
INSERT INTO table01 SELECT * FROM table02
DROP TABLE table02
合并查询
- 合并多个select语句的结果,可以使用集合操作符号union,union all
- union all 取得两个结果的并集,会有重复
- union 取得两个结果的并集,不会有重复
mysql表 外连接
- 左外连接,显示 匹配的数据 和 左表没有匹配的数据
SELECT * | column1... from table1 LEFT JOIN table2 ON definition
- 右外连接,显示 匹配的数据 和 右表没有匹配的数据
SELECT * | column1... from table1 RIGHT JOIN table2 ON definition
mysql 约束
primary key 主键
- primary key不能重复而且不能为 null
- 一张表最多只能有一个主键, 可以是复合主键( 比如 PRIMARY KEY(id+name) )
-- 一个主键
CREATE TABLE table1_name (column1 datatype PRIMARY KEY, column2 datatype...)
-- 复合主键
CREATE TABLE table2_name(column1 datatype,column2 datatype, PRIMARY KEY(column1,column2))
- 主键的指定方式 有两种
- 直接在字段名后指定:column datatype primakry key
- 在表定义最后写 primary key(column…),复合主键只能采用这种方式;
- 使用desc table_name,可以看到primary key的情况
not null 和 unique
- unique 不能重复,可以为null,一张表可以有多个unique
- 如果没有指定not null,则unique字段可以有多个null
- unique not null 效果类似 primary key
CREATE TABLE table_name (column1 UNIQUE,column2 UNIQUE NOT NULL...)
foreign key 外键
- 外键用于定义主表和从表之间的关系:外键约束要定义在从表上,主表则必须具有主键约束或是unique约束
-- 主表
CREATE TABLE table1_name (column1 datatype PRIMARY KEY, column2 datatype...)
-- 从表
CREATE TABLE table2_name (column1 datatype, column2 datatype, FOREIGN KEY (column2) REFERENCES table1_name(column1))
- 外键使用细节
1.外键指向表的列,要求是primary key 或 unique
2.表的引擎是 innodb 才支持外键
3.使用外键的列类型要一致(长度可以不同)
4.外键字段的值,必须在主表字段出现过,或者为null(前提是外键字段允许为null)
5.一旦建立主外键关系,主键字段不能随意删除
check
- mysql 5.7 目前不支持check,只做语法校验,不会生效
可以用enum枚举指定数据,如
CREATE TABLE table_name(sex ENUM('男','女'))
自增长 auto_increment
- 整数列数据从 1 开始自动的增长,自增长的列一般不指定数据
CREATE TABLE table_name(id INT PRIMARY KEY AUTO_INCREMENT)
INSERT INTO table_name VALUES (null)
- 自增长使用细节
- 一般 自增长 和 主键 配合使用
- 自增长单独使用 要配合 unique
- 自增长的列类型 为整型(可以为小数但是很少使用)
- 自增长默认从 1 开始,也可以通过 ALTER TABLE table_name AUTO_INCREMENT = xx 修改开始值
mysql索引
- 没有索引为什么慢?
因为进行全表扫描 - 使用索引为什么快?
因为形成了一个索引的数据结构,如二叉树 - 索引的代价
1.磁盘的占用
2.对dml(update, delete, insert)语句的效率影响
索引的类型
- 主键索引,primary key 类型的是主键索引
- 唯一索引,unique 类型的是唯一索引
- 普通索引(index)
- 全文索引(fulltext) ,一般不使用mysql自带的全文索引,开发中使用搜索引擎:全文搜索 Solr 和 ElasticSearch(ES)
创建索引
- 方式1:建表时添加约束 PRIMARY KEY 和 UNIQUE
- 方式2
CREATE [UNIQUE] INDEX index_name ON table_name (column_name)
- 方式3
ALTER TABLE table_name ADD INDEX/PRIMARY KEY/UNIQUE index_name (column_name)
删除索引
DROP INDEX index_name ON table_name
- 删除主键索引
ALTER TABLE table_name DROP PRIMARY KEY
修改索引就是先删除再创建
查询索引
SHOW INDEX FROM table_name
SHOW KEYS FROM table_name
哪些列(字段)适合添加索引
- 频繁作为查询条件的列 应该添加索引
- 唯一性太差的字段 即使查询频繁 也不适合添加索引,比如:性别 ‘男’,‘女’
- 更新非常频繁的字段 不适合添加索引
- 不会作为(WHERE)查询条件的字段 不该添加索引
mysql事务
- 事务用来保证数据的一致性,它由一组相关的dml语句组成,该组dml语句要么全部成功,要么全部失败,应用场景如:转账。
- 当执行事务操作时(dml语句),mysql会在表上加锁,防止其他用户改变表的数据
- 事务的几个基本操作
START TRANSACTION -- 开始一个事务
SAVEPOINT xx -- 设置保存点xx
ROLLBACK TO xx -- 回退事务到保存点xx
ROLLBACK -- 回退到开始事务
COMMIT -- 提交事务,所有操作生效,不能回退
事务的使用细节
- 如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚
- 如果开启一个事务,rollback 默认回到开启事务的状态
- 可以在事务中,创建多个保存点 savepoint ,并可以在事务提交前,选择回到哪个保存点
- mysql的事务机制需要在 innodb 的存储引擎下使用
- 开启一个事务,start transaction / set autocommit-off
隔离级别
- 多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性,隔离级别定义了事务与事务之间的隔离程度
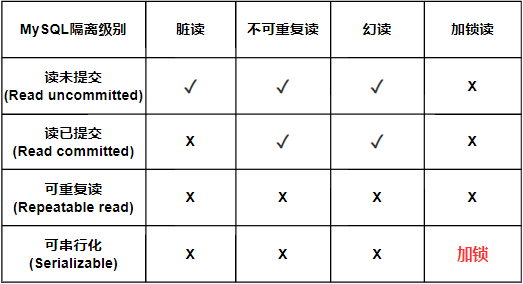
- 不考虑隔离性,可能引发如下问题:
- 脏读(dirty read):当一个事务读取到另一个事务未提交的操作的数据时,产生脏读
- 不可重复读(nonrepeatable read):同一查询在同一事务多次进行,受到其他提交事务所做的修改或删除影响,读取到其他事务操作后的结果,此时发生不可重复读
- 幻读(phantom read):同一查询在同一事务中多次进行,受到其他提交事务所做的插入影响,读取到其他事务操作后的结果,此时发生幻读
-- 查看当前会话隔离级别
SELECT @@tx_isolation;
-- 查看系统当前隔离级别
SELECT @@global.tx_isolation;
-- 设置当前会话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 设置系统当前隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- mysql默认的隔离级别是 Repeatable read ,一般情况不需要修改
- 事务的ACID特性
- 原子性(Atomicity):事务是不可分割的工作单位,事务的操作要么都发生,要么都不发生
- 一致性(Consistency):提交事务使数据库从一个一致性状态变换到另一个一致性状态
- 隔离性(Isolation):多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作干扰
- 持久性(Durability):一旦提交事务,对数据库的改变是永久性的
mysql存储引擎
- mysql的表类型由存储引擎(storage engines)决定,主要包括MyISAM、InnoDB,Memory等
- MyISAM 不支持事务,也不支持外键,但其访问速度快,对事务完整性没有要求
- InnoDB 具有提交、回滚和崩溃恢复能力的事务安全,但是效率低,并且会占用更多的磁盘空间
- Memory 使用存在内存中的数据来创建表。每个Memory表只实际对应一个磁盘文件。Memory类型的表访问速度非常快,因为数据是存在内存中的,并且默认使用HASH索引。但一旦服务关闭,表中的数据就会丢失,但表的结构还在。
- mysql数据表支持六种类型分为两类,其中第一类是“事务安全型”,比如InnoDB,第二类是“非事务安全型”,比如MyISAM、Memory等
- 修改存储引擎
ALTER TABLE table_name ENGINE=存储引擎;
视图
- 视图是一个虚拟表,根据基表(可以是多个)创建。视图也有列,数据来自基表,修改视图数据就是修改基表数据,视图也可以创建视图
- 视图的基本使用
CREATE VIEW view_name AS SELECT column1,column2... FROM table_name
ALTER VIEW view_name AS SELECT column1,column2... FROM table_name
SHOW CREATE VIEW view_name
DROP VIEW view_name
mysql管理
mysql用户
- mysql中的用户,都存储在系统数据库mysql中的user表
- 基本操作
-- 创建用户
CREATE USER '用户名'[@'允许登录位置'] [IDENTIFIED BY '密码']
# 如果不指定允许登录位置,则为% 代表所有IP都可以连接
-- 删除用户
DROP USER '用户名'@'允许登录位置'
-- 修改自己的密码
SET PASSWORD = PASSWORD('密码')
-- 修改其他用户的密码(需要修改密码的权限)
SET PASSWORD FOR '用户名'@'允许登录的位置' = PASSWORD('密码')
mysql中的权限
- mysql中不同的用户,登录到DBMS后,根据相应的权限,操作的数据库和数据对象(表,视图,存储过程等)都不一样
- 基本操作
-- 给用户授权
GRANT 权限列表 ON 库.对象名 TO '用户名'@'登录位置'
# 如果 库.对象名 是 *.* 那就是所有数据库的所有对象
# 权限列表可以是 ALL 代表 全部权限
-- 回收用户授权
REVOKE 权限列表 ON 库.对象名 FROM '用户名'@'登录位置'
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









