







语言处理器
编译器:阅读以某一种语言(源语言)编写的程序,并把该程序翻译成为一个等价的、用另一种语言(目标语言)编写的程序。
解释器:并不通过翻译的方式生成目标程序,直接利用用户提供的输入执行源程序中指定的操作。
| 编译器 | 解释器 |
|---|---|
| 执行速度更快 | 错误诊断效果更好 |
创建可执行的目标执行还需要的其他程序,比如
预处理器:把分割为多个模块的源程序聚合在一起。
汇编器:生成可重定位的机器代码。
加载器:把所有的可执行目标文件放到内存中执行。
编译器
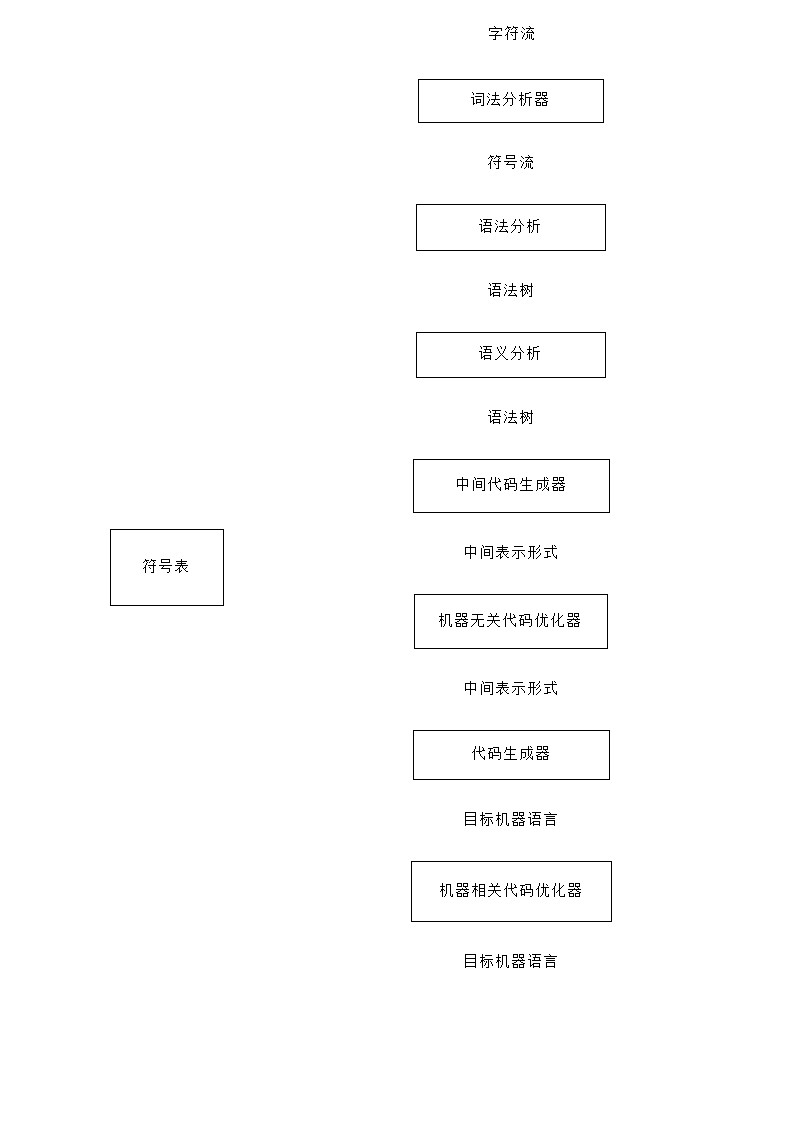
词法分析
词法分析器读取组成源程序的字符流,并且将它们组织成为有意义的词素的序列。
对于每个词素,词法分析器产生如下形式的词法单元(token)作为输出。
(token-name, attribute-value)
比如:
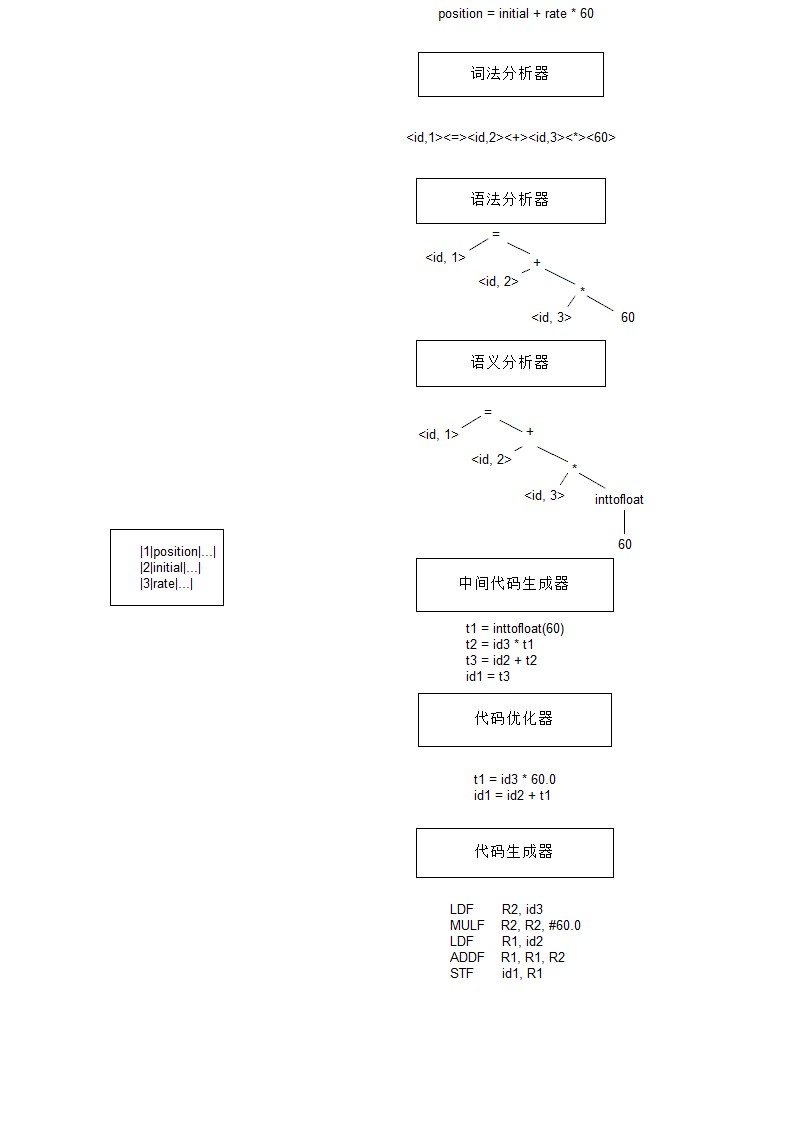
position = initial + rate * 60
- position是一个词素,被映射成(id,1),其中id表示标识符的抽象符号,而1指向符号表中position对应的条目。
- =是一个词素,被映射成(=),因为不需要属性值,所以忽略第二个分量。
- initial是一个词素,被映射成(id,2)
- +是一个词素,被映射成(+)
- rate是一个词素,被映射成(id,3)
- 是一个词素,被映射成()
- 60是一个词素,被映射成(60)
(id, 1)(=)(id,2)(+)(id,3)(*)(60)
符号表
符号表数据结构为每个变量名字创建了一个记录条目。记录的字段就是名字的各个属性,包括存储分配、类型、作用域等,过程名字包括参数数量和类型、传递方法(传值或传引用)、返回类型等。
| 1 | position | … |
|---|---|---|
| 2 | initial | … |
| 3 | rate | … |
语法分析
语法分析器使用由词法分析器生成的各个词法单元的第一个分量来创建树形的中间表示。一个常用的表示方法是语法树,树中的每个内部节点表示一个运算,而该节点的子节点表示该运算的分量。
语义分析
使用语法书和符号表中的信息来检查源程序是否和语言定义的语义一直。它同时也收集类型信息,并把这些信息存放在语法树或符号表中,以便在随后的中间代码生成过程中使用。
语义分析的一个重要部分是类型检查。
中间代码生成
在把一个源程序翻译成目标代码的过程中,一个编译器可能构造出一个或多个中间表示。这些中间表示可以有多种形式。语法树是一种中间表示形式。
代码优化
机器无关的代码优化步骤试图改进中间代码,以便生成更好的目标代码。
代码生成
代码生成器以源程序的中间表示形式作为输入,并把它映射到目标语言。















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









