






索引是排好序的数据结构,帮助数据库高效获取数据。如果要按某列的条件查询某条数据,假设该列没有索引,就只能逐行比对,也就是全表扫描,效率将非常低下。因此,数据库系统加入索引,以提高查询效率。

常用的索引数据结构有:二叉搜索树、红黑树、Hash表、B-Tree等。MySQL就是用的B-Tree的一个变种,叫B+Tree,它是在B-Tree的基础上的一种优化。那么MySQL为什么这样选择呢?其它几种数据结构为什么不合适呢?理解了原因,也就对MySQL底层数据结构有了跟好的理解,对于索引的优化大有帮助。
对于学习数据结构的朋友,推荐一个学习网站,可以图像化动态展示数据结构的原理。https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
一、二叉搜索树
二叉搜索树是二叉树的一种,他的特点是根节点/父节点的左子树上的节点都比根节点/父节点小,而右子树上的节点都比根节点/父节点要大。
由于二叉搜索树的这种顺序,因此对于Col1列这种顺序增长的主键来说,生成二叉树是不平衡的。
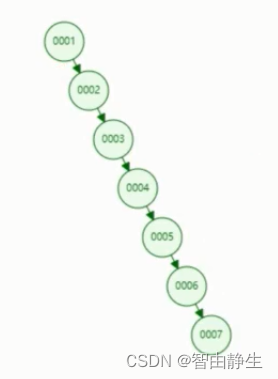
这种结构去查找跟没有建索引没有任何区别,也是从第一行开始逐条比对查找。因此二叉搜索树不适合作为关系数据库索引。
二、红黑树
红黑树是一种二叉平衡树,二叉平衡树是二叉搜索树的一种拓展。跟二叉搜索树相比,它的特点是可以通过每次插入后的调整,使得左右两个子树的高度差的绝对值不超过1,达到让树保持一定程度的矮胖,优化搜索的效率。
Jdk1.8以后对HashMap底层链表的数据结构进行了比较大的改进,就把它优化成了红黑树,效率提高了很多。
对于Col1列这种顺序增长的主键来说,当插入数据不平衡时,它会自动调整,使左右两边尽量平衡。

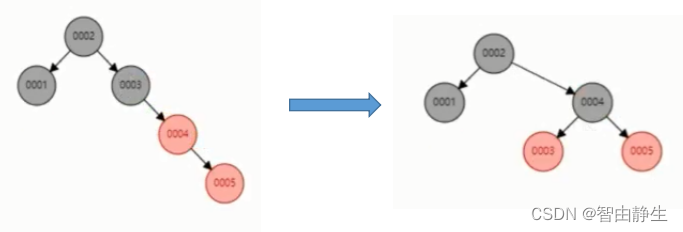 Sql语句在查找时就会从根节点开始比对,根据比较结果快速选择一侧继续,比逐行扫描提高了效率。
Sql语句在查找时就会从根节点开始比对,根据比较结果快速选择一侧继续,比逐行扫描提高了效率。
但是红黑树确点还是比较大,它的高度是数据量的对数(logn)。如果数据量大的时候,这种结构的层级太多,深度太深。对于数据表动辄几十上百万的情况,用红黑树做索引显然不合适。
三、Hash表
Hash表的原理是对索引字段上的数据进行Hash运算,得到一个散列值。将此散列值和对应数据行地址存储到一个映射表中。按索引查询数据时,将查询条件值进行Hash运算得到散列值,到这个映射表中可以快速定位到对应的数据行。
这种查找是很快的,只需要一次hash运算就可以快速定位数据地址。但是它有一个致命缺陷,虽然对于精确查询效率很高,但对范围查询无法处理,所以不是主流,只用在特殊场景。MySQL也支持Hash索引,只是用的很少。
四、B-Tree
前面讲到红黑树的缺点是层级太多,深度太深,造成每次查询比对次数仍然较多,效果不理的想。那么为什么每个节点只能存一个数据呢?是否可以增加每个节点的数据量,这样不就可以减少层数了吗。这就是B树的思想。
B-Tree是对红黑树进行改造,使一个节点可以存多个索引元素,防止层级过多。因为一个节点存放了多个元素,B-Tree就变成了多叉树,但对于节点上的某个元素来说,只有左右两个指针,其实还是二叉树,依然遵循左子树上的节点都比父节点小,而右子树上的节点都比父节点要大。B-Tree可以控制树的高度,只要根据总数据量把节点的横向数据量设置到一个合适的值即可。
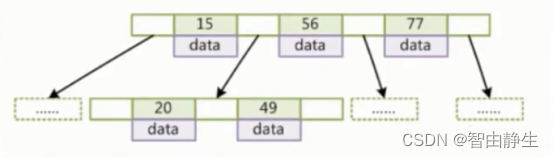
B-Tree节点包含键和值,是key-value的形式,每个节点最多有M-1个key,并且从左向右以升序排列,每个节点最多有M个子节点。叶节点具有相同的深度,叶节点的指针为空。
B-Tree适合做数据库索引,key存的是索引值,value存的就是索引对应的数据,如果是索引组织表就是数据行本身,如果是堆表就是指向数据文件的指针。MySQL用的是B-Tree的变种B+Tree,对B-Tree做了一些改进。
五、B+Tree
B+Tree是B-Tree的变种,非叶子节点不存储data,只存储索引(冗余),叶子节点包含所有索引字段。
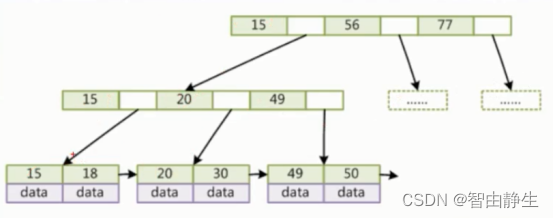
与B-Tree的区别:
- 叶子节点包含索引和数据,非叶子节点只存储索引不存储数据
- 叶子节点用指针连接起来
- 叶子节点包含全部索引值,非叶子节点的索引值只是叶子节点的冗余
为什么要做这些改进呢?有什么好处呢?下面重点说说!
1、叶子节点包含索引和数据,非叶子节点只存储索引不存储数据
节点数据是存放在硬盘上(根节点一般会提前加载到内存)。当找到某个节点元素,就会将该节点加入到内存,在内存中查找当然会很快。但是也不能把节点做的过大,极端情况甚至所有数据放到一个节点呀!内存很宝贵,不可能存储那么大量的数据。MySQL对于一个节点的大小是有设置的,默认是16KB。可以通过下面语句查看。
SHOW GLOBAL STATUS like 'Innodb_page_size';因此非叶子节点只存储索引不存储数据,可以让一个节点尽可能多的存储索引元素。
2、叶子节点用指针连接起来
叶节点是从左到右依次递增的,右边的节点永远大于左边的节点。叶子节点用指针连接起来,可以跨节点快速找到下一个元素,从而可以很好地支持范围查询。而普通的B-Tree处理范围查询,当跨节点时必须返回先上级节点进行比较,效率很低。
3、叶子节点包含全部索引值,非叶子节点的索引值只是叶子节点的冗余
叶子节点存储了一份完整的索引元素,把一些处于中间位置的索引元素提上去,放到非叶子节点作为冗余存放。这个就是基于第一点和第二点的优化的需要而顺理成章进行的设计。
此外,大家应该都听说过,“索引建议使用整形自增主键”这个说法吧!为什么呢?
当向B+Tree索引中插入不规则数据时,如果节点已满,为了维持左到右依次递增的顺序,索引不得不进行重新组织,将元素进行重新分配,带来性能的开销,这称为页分裂。以下图为例,节点最大容量为4,当新插入元素006时,进行了重新分配。
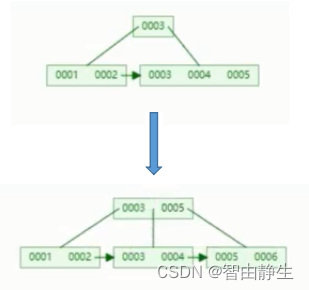
聚簇索引因为节点下有数据文件,所以节点的分裂将会比较慢。因此对于B+Tree索引都建议使用整形自增主键,这样永远都是在后面增加元素,防止出现页分裂。















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









