







本系列属于学习路径记录,学习的主要内容来自并发编程网
1. Java的多线程和并发性
Java从一开始就支持多线程,因此Java开发者能常遇到异常问题场景,比如:
- 一个线程在读一个内存时,另一个线程正向该内存进行写操作,那进行读操作的那个线程会获得上面结果呢?
- 两个线程同时写同一个内存,在操作完成后会是什么结果呢?
2. 多线程的优点
- 资源利用率好
- 场景:一个应用程序需要从本地文件系统中读取和处理文件:
- 读取一个文件要5秒
- 处理一个文件要2秒
- 多线程
- 5秒读取文件A
- 5秒读取文件B + 2秒处理文件A
- 2秒处理文件B
总的说来,CPU能够在等待IO的时候做一些其他的事情。(等待IO可能是磁盘IO、网络IO、用户输入等等)
- 程序设计在某些情况下更简单
现象:
- 在单线程情况下,如果你想处理上面说的读取和处理文件的顺序,你必须记录每个文件读取和处理的状态
- 在多线程情况下,每个线程处理一个文件的读取和操作,线程会在等待磁盘读取文件的过程中阻塞,其等待之时,其它线程能够使用CPU去处理已经读取完的文件
- 程序响应更快
想象:
- 一个服务器应用,它的某一个端口监听进来的请求,当一个请求到来时,它去处理这个请求,然后再返回去监听
// 服务器的流程如下
while(server is active){
listen for request
process request
}如果一个请求需要占用大量时间处理
- 单线程时:在这段时间内新的客户端就无法发送请求给客户端
- 多线程时:监听线程把请求传递给工作者线程,然后立刻返回去监听。而工作者线程能够处理这个请求并发送另一个回复给客户端
while(server is active){
listen for request
hand request to worker thread
}这种方式,服务器线程能迅速地返回去监听。因此,更多的客户端能够发送请求给服务端,这个服务也变得响应更快
3. 多线程的代价
要使用多线程,就必须明确使用多线程获得的好处比所付出的代价大的时候,才使用多线程
设计更复杂
- 虽然有一些多线程应用程序比单线程的应用程序要简单,当一般来所,都是更复杂的。
- 在多线程访问共享数据的时候,这部分代码需要特别的注意
- 线程之间的交互往往非常复杂
- 不正确的线程同步产生的错误非常难被发现
上下文切换的开销
当CPU从执行一个线程切换到执行另一个线程时,它需要先存储当前线程的本地数据、程序指针等,然后载入另一个线程的本地数据、程序指针等,最后才开始执行。这种切换叫做“上下文切换”
增加资源的消耗
线程的运行所需资源。除了CPU,线程还需要一些内存来维持它本地的堆栈。它也需要占用操作系统中的资源来管理线程
小实验:尝试编写一个程序,它创建100个线程,这些线程只是wait,然后看看这个程序占用了多少内存?
4. 并发编程模型
并发模型与分布式系统之间的相似性
线程与进程之间具有很多相似的特性,这就是并发模型与分布式系统相似的原因
- 例如,为工作者们(线程)分配作业的模型一般与分布式系统中的负载均衡系统比较相似。同样,它们在日志记录、失效转移、幂等性等错误处理技术上也具有相似性。
模型1. 并行工作者
- 并行工作者模型:传入的作业会被分配到不同的工作者上

- 该模型中,委派者将传入的作业分配给不同的工作者,每个工作者完成整个任务(工作者们将运行在不同的线程上,甚至可能在不同的CPU上)
- 如果某个帽子生成作坊实现了并行工作者模型,则每个帽子都会由一个工人来生产,她收到帽子的制作要求,然后将负责完成整个帽子
在java应用系统中,并行工作者模型是很常见的
- java.util.concurrent包中的许多并发使用工具都是设计用于这个模型的
J2EE 应用服务器的设计中也能看到这个模型的踪迹
- 并行工作者模型的优点
简单、易于理解
- 并行工作者模型的缺点
共享状态可能会很复杂
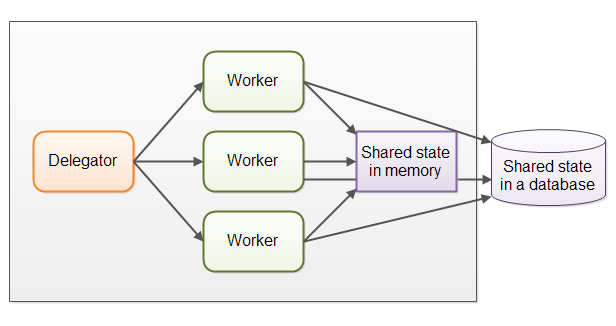
当共享状态潜入工作者模型中——
要确保某个线程的修改能够对其它线程可见(数据修改要同步到主存中,不仅仅将数据保存在执行这个线程的CPU的缓存中)。线程需要避免竞态、死锁以及很多其它共享状态的并发性问题
在等待访问共享数据结构时,线程之间的互相等待将会丢失部分并行性
链接知识:非阻塞并发算法 也许可以降低竞争并提升性能,但实现比较困难
可持久化的数据结构是另一种选择。在修改的时候,可持久化的数据结构总是保护它的前一个版本不受影响。因此,如果多个线程指向同一个可持久化的数据结构,并且其中一个线程进行了修改,进行修改的线程会获得一个指向新结构的引用。所有其他线程保持对旧结构的引用,旧结构没有被修改并且因此保证一致性。
无状态的工作者
共享状态能够被系统中的其它线程修改,所以工作者每次需要的时候必须重读状态,以确保每次都能访问到最新的副本,不管共享状态是保存在内存还是外部数据库中。工作者是无状态的(无法在内部保存这个状态)。
任务顺序是不确定的
并行工作者模式的另一个缺点是执行顺序是不确定的
模型2.流水线模式

- 每个工作者只负责作业中的部分工作。当完成了自己的这部分工作时工作者会将作业转发给下一个工作者。
通常使用非阻塞的IO来设计使用流水线并发模型的系统。非阻塞IO意味着,一旦某个工作者开始一个IO操作的时候(比如读取文件或从网络连接中读取数据),这个工作者不会一直等待IO操作的结束。IO操作速度很慢,所以等待IO操作结束很浪费CPU时间。此时CPU可以做一些其他事情。当IO操作完成的时候,IO操作的结果(比如读出的数据或者数据写完的状态)被传递给下一个工作者。
有了非阻塞IO,就可以使用IO操作确定工作者之间的边界。工作者会尽可能多运行直到遇到并启动一个IO操作。然后交出作业的控制权。当IO操作完成的时候,在流水线上的下一个工作者继续进行操作,直到它也遇到并启动一个IO操作。


反应器,事件驱动系统
采用流水线并发模型的系统有时称为反应器系统或事件驱动系统。系统内的工程对系统内出现的事件做出反应,这些事件也有可能来自外部世界或者发自其他工作者。事件可以是传入的HTTP请求,也可以是某个文件成功加载到内存中等。
流水线模型的优点
无需共享的状态
工作者之间无需共享的状态,意味着实现的时候无需考虑所有因并发访问共享对象产生的并发性问题
有状态的工作者
当工作者知道了没有其他线程可以修改它们的数据,工作者可以变成有状态的。
较好的硬件整合
单线程代码在整合底层硬件的时候往往具有更好的优势。
合理的作业顺序
基于流水线并发模型实现的并发系统,在某种程度上是有可能保证作业的顺序的。作业的有序性使得它更容易地推出系统在某个特定时间点的状态。更进一步,你可以将所有到达的作业写入到日志中去。

流水线模型的缺点
流水线并发模型最大的缺点是作业的执行往往分布到多个工作者上,并因此分布到项目中的多个类上。这样导致在追踪某个作业到底被什么代码执行时变得困难。
函数式并行
函数可以看作是”代理人(agents)“或者”actor“,函数之间可以像流水线模型(AKA 反应器或者事件驱动系统)那样互相发送消息。某个函数调用另一个函数,这个过程类似于消息发送。















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









