



- Presto 是一个 facebook 开源的分布式 SQL 查询引擎,适用于交互式分析查询,数据量支持 GB 到 PB 字节。Presto 的架构由关系型数据库的架构演化而来。它是 hadoop 生态中著名的分布式 SQL 引擎。2019年原作者从 Facebook 分道扬镳更名 Trino。有关这段爱恨情仇可以在 trino 官网中看到。
简介
- Presto 是 Facebook 研发的基于 SQL 进行大数据分析的高性能分布式计算引擎,最开始是用来解决Hive速度慢以及异构数据源互通的问题。它在大数据家族中属于MPP(massive parallel processing)计算引擎范畴,其原理是火山(volcano)模型:将SQL抽象成一个个算子(operator),形成管线(pipeline)。目前能够支持 Hive、HBase、ES、Kudu、Kafka、MySQL、Redis、ElasticSearch等 等几十种数据源的读取。
- 它为何是 SQL 查询引擎?而不是数据库?
和Oracle、MySQL、Hive等数据库相比,他们都具有存储数据和计算分析的能力。如MySQL具有InnoDB存储引擎和有SQL的执行能力;如Hive有多种数据类型、内外表(且这么叫)的管理能力,且能利用MR、TEZ执行HQL。而Presto并不直接管理数据,它只有计算的能力。 - Presto 支持从多种数据源获取数据来进行运算分析,一条SQL查询可以将多个数据源的数据进行合并分析。比如下面的SQL:a可以来源于MySQL,b可以来源于Hive。
select a.*,b.* from a join b on (a.id = b.id);
产生背景
简单说,MapReduce 不能满足大数据快速实时 adhoc(即席查询)查询计算的性能要求。
Presto 最初是由 Facebook 开发的一个分布式 SQL 执行引擎, 它被设计为用来专门进行高速、实时的数据分析,以弥补 Hive 在速度和对接多种数据源上的短板。
Facebook 2012年开发,2013 年开源。发展历史如下:
2012年秋季,Facebook启动Presto项目;
2013年冬季,Presto 开源;
2017年11月,11888 commits,203 releases,198 contributors;
2019年1月,Presto 分家,目前有 PrestoDB 和 PrestoSQL(更名为 trino) 两个社区。Presto 团队的三位创始人离开了 Facebook。从此,Presto 项目被一分为二,由 Facebook 维护 PrestoDB,Martin、Dain、David 三位 Presto 项目最早的发起人维护 PrestoSQL。
两个社区:
PrestoDB:https://prestodb.io,面向大数据的分布式 SQL 查询引擎
trino:trino,PrestoSQL,一个速度不可置信的查询引擎
特点
Presto有如下特点:
- 基于SQL语言,上手成本低,而且功能强大,支持reduce和lambda函数;
- 纯计算引擎,解耦底层存储,可快速缩扩容;
- 纯内存计算,速度快,提供交互式的查询体验;
- 通过插件的方式实现拓展功能,二次开发友好;
- 通过不同的连接器(connector)插件读取异构数据源,进行联邦查询。
另外还有以下特点: - 多数据源、混合计算支持:支持众多常见的数据源,并且可以进行混合计算分析;
- 大数据:完全的内存计算,支持的数据量完全取决于集群内存大小。它不像SparkSQL可以配置把溢出的数据持久化到磁盘,Presto是完完全全的内存计算;
- 高性能:低延迟高并发的内存计算引擎,相比Hive(无论MR、Tez、Spark执行引擎)、Impala 执行效率要高很多。根据Facebook的测试报告,至少提升10倍以上;
- 支持ANSI SQL:这点不像Hive、SparkSQL都是以HQL为基础,Presto是标准的SQL。用户可以使用标准SQL进行数据查询和分析计算;
- 扩展性:有众多SPI扩展点支持,开发人员可编写UDF、UDTF。甚至可以实现自定义的Connector,实现索引下推,借助外置的索引能力,实现特殊场景下的MPP;
- 流水线:Presto是基于PipeLine进行设计,在大量数据计算过程中,终端用户(Driver)无需等到所有数据计算完成才能看到结果。一旦开始计算就可立即产生一部分结果返回,后续的计算结果会以多个Page返回给终端用户(Driver)。
架构
Trino(Presto) 是典型的 MPP 架构,由一个 Coordinator 和多个 Worker 组成,其中 Coordinator 负责 SQL 的解析和调度,Worker 负责任务的具体执行。可配置多个不同类型的 Catalog,实现对多个数据源的访问。
Presto 架构
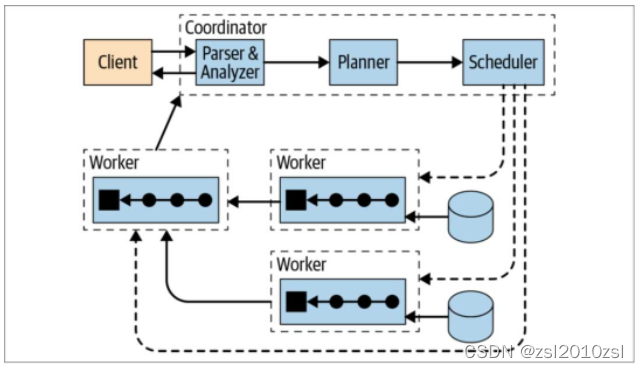
Presto 在整体业务中的架构图如下:
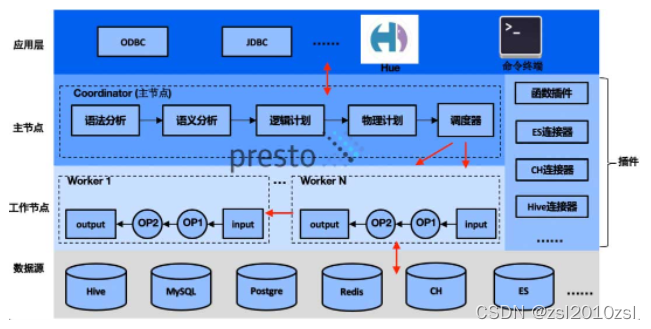
应用场景
常见以下场景:
- 实时计算:Trino(Presto)性能优越,实时查询工具上的重要选择。
- Ad-Hoc查询:数据分析应用、Trino(Presto)根据特定条件的查询返回结果和生成报表。
- ETL:因支持的数据源广泛、可用于不同数据库之间迁移,转换和完成ETL清洗的能力。
- 实时数据流分析:Presto-Kafka Connector 使用 SQL对Kafka的数据流进行清洗、分析。
- MPP:Presto Connector有非常好的扩展性,可进行扩展开发,可支持其他异构非SQL查询引擎转为SQL,支持索引下推。
参考
https://www.gairuo.com/p/trino-presto

















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









