







 本文详细介绍了如何在CentOS系统上搭建Hadoop 2.7.3集群,包括准备阶段、设置SSH免密登录、安装Java环境、配置Hadoop、创建集群节点以及启动和测试Hadoop集群。通过SSH免密登录简化集群管理,通过配置Hadoop环境实现分布式计算。
本文详细介绍了如何在CentOS系统上搭建Hadoop 2.7.3集群,包括准备阶段、设置SSH免密登录、安装Java环境、配置Hadoop、创建集群节点以及启动和测试Hadoop集群。通过SSH免密登录简化集群管理,通过配置Hadoop环境实现分布式计算。
一、说明:
到写本文时间为止,3.0没有发布稳定的版本,所以本文基于2.7.3
系统为centOS ,用 debian核心的linux(比如ubuntu) 基本设置相同,只要把yum换成apt-get,推荐使用更稳定的centOS
二、集群部署
1、 准备
理论实验室没有服务器,我利用自己的电脑和舍友的电脑搭建了1个namenode 7个datanode的分布式集群,虚拟机为VMware Workstation,虚拟机部分有问题可以找虚拟机教程,这里不过多讲解
第一步创建新的虚拟机:
我的配置如下:
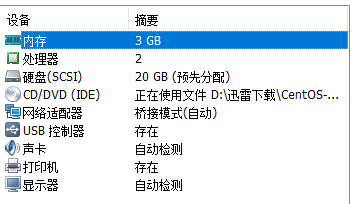
这里cpu内存根据自己的机器配置,但是注意,网络适配器一定设置成桥接
第二步 安装系统:
在centOS官网下载centOS 下载minimal版本,也就是只有linux内核和少量软件的版本,因为节点只用来计算,所以尽可能的少运行不必要的程序
VMware中选择虚拟机创建位置尽可能选择SSD,hadoop处理数据会大量读取磁盘,ssd在随机存储上会显著加快性能
第三步 配置CentOS:
请直接用root用户登录,如果没有root用户登录,使用
$ sudo passwd
输入密码:
确认密码:
$ su
输入root密码:获取root权限,在root用户下会省去许多麻烦
设置网卡的IP地址、网关、DNS(此处CentOS跟ubuntu不一样,ubuntu直接在界面右上角选择网络设置就行)
# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736下面是我的设置:
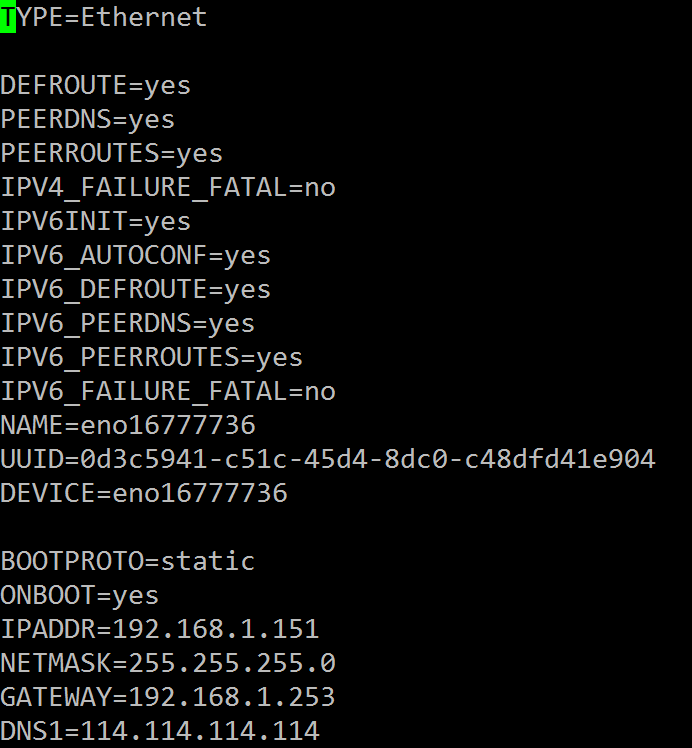
注意IP地址、网关设置成自己网络的,如果用路由器wifi上网,那么网关就是路由器ip地址,本机ip一定记住
然后安装神器vim:
# yum install vim配置host:
#vim /etc/hosts我的配置如下:
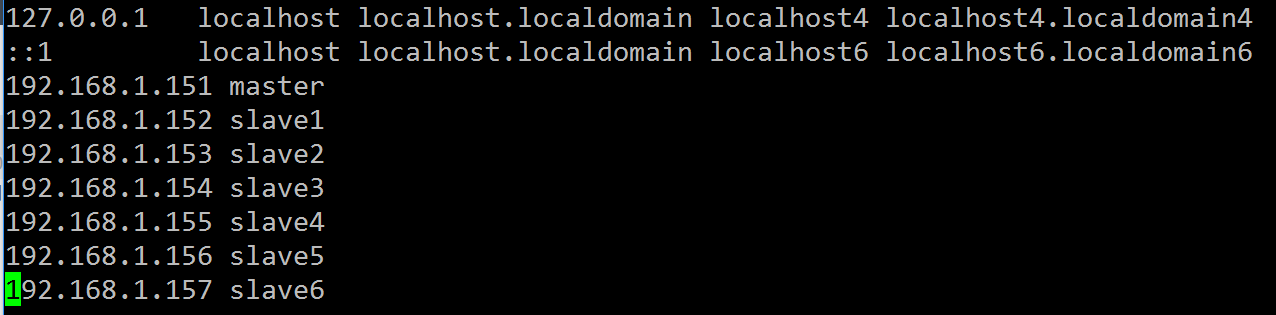
这里前面的ip地址是集群节点的ip,后面是名称,以后可以直接用后面的名称访问,等效于ip地址
2、设置SSH免密登录
确认是否安装ssh,即使是minimal版本,CentOS也安装了ssh,如果没有用下面命令安装
# yum install sshssh协议是hadoop集群节点之间通信的根本
首先在root根目录下创建.ssh文件夹:
# mkdir /root/.ssh
# cd ~/.ssh然后,生成秘钥,此处一定用RSA!!!!!尤其是ubuntu用户,因为ssh服务器配置文件里很可能没有DSA的相关设置
# ssh-keygen然后一路回车,默认生成了一个无密码的RSA公钥和RSA私钥分别为 id_rsa.pub id_rsa
使用ls命令可以看见生成了三个文件,(其中authorized_keys一般没有):

known_hosts是用来写入信任节点的,否则每次会进行询问
新建authorized_keys文件:
# touch authorized_keys这个文件用来写入其他节点的rsa公钥,这样,通过非对称加密实现免密登录
首先将本机公钥写入
# cat id_rsa.pub >> authorized_keys然后ssh登录本机
# ssh master如果出现(yes/no)输入yes,这是写入known_hosts,只要这一次,以后不需要
这样就成功了:

3、 安装java环境
无论是debain核心还是redhat核心的linux系统都已经安装了openJDK,可以直接使用,但是Oracle有一部分并未开放给openJDK,所以我们还是安装一下Oracle的JDK,去官网下载linux版本的JDK:jdk-8u111-linux-x64.rpm,这里注意要一次下完,因为下载地址不是静态的,并不支持断点续传
卸载openJDK
# rpm -qa | grep
你的openjdk版本
#yum -y remove 上面显示的版本安装Oracle JDK
# rpm -ivh jdk-8u111-linux-x64.rpm添加环境变量
# vim /etc/profile在最后追加
export JAVA_HOME=/usr/java/jdk1.8.0_111
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar 注意 JAVA_HOME这个变量的路径可能有所不同,写成自己系统的
然后使其生效:
# source /etc/profile 验证:
java -version出现如下画面表示成功,我安装的时候还是_101现在应该是_111了

4、配置hadoop
在hadoop官网下载-编译好的二进制文件,如果想要学习hadoop的源码,请下载-src的原码版本
# cd
# wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz解压
# tar -zvf hadoop-2.7.3.tar.gz配置hadoop环境,这里依然可以用/etc/profile一样的
# vim ~/.bashrc追加
export HADOOP_HOME=/root/hadoop-2.7.3
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin生效:
source ~/.bashrc这一步没有也是可以的,但是设置环境变量以后使用/bin 和/sbin中的脚本命令就不用进入这两个文件夹内了
然后我们需要配置hadoop的一些设置
首先进入hadoop文件夹:
# cd /root/hadoop-2.7.3/etc/hadoop我们需要修改这几个文件:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves 一一展开:
1
# vim hadoop-env.shjavahome这行去掉注释并改成自己的
export JAVA_HOME=/usr/java/jdk1.8.0_1112
# vim yarn-env.shjavahome这行去掉注释并改成自己的
export JAVA_HOME=/usr/java/jdk1.8.0_1113
# vim core-site.xml改成如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.151:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop-2.7.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
注意:<value>hdfs://192.168.1.151:9000</value> 这行要把IP改成自己的ip或者master(如果你一步步按我的配置)
4
# vim hdfs-site.xml改成如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop-2.7.3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop-2.7.3/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>5
mapred-site.xml 并不存在,而是作为mapred-site.xml.template 保存,所以需要先生成
# cp mapred-site.xml.template mapred-site.xml
# vim hdfs-site.xml改成如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>6
vim yarn-env.sh改成如下
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>7
vim slavesslaves 文件里是datanode的ip地址,所以有几个datanode就写几个,因为节点太少,这里我把master节点也作为一个datanode运行
master
slave1
slave2
slave3
slave4
slave5
slave6
创建必须文件夹
# cd /root/hadoop-2.7.3
# mkdir tmp
# mkdir hdfs
# cd ./hdfs
# mkdir name
# mkdir data至此hadoop配置已经结束
5 、创建集群其他节点
关闭虚拟机,右键管理机选择 管理>克隆 打开克隆窗口,只需要注意在后面步骤选择“创建完整克隆”,这样就创建了一个跟刚才我们配置节点一模一样的虚拟机,所以我们已经不需要每一个克隆再进行上面的步骤,但是我们需要重新设置本机ip地址,按照/etc/hosts 中的对应信息配置每个节点的ip地址
6、用ssh连通集群
这里我们需要在每个节点生成秘钥并把公钥写入所有其他节点的authorized_keys中,如果随便乱写我们需要做
n(n−1)/2
次操作,这里有个小窍门,我们在每个slave节点生成rsa然后所有节点都发给master节点,让master节点写入后,吧写好的 authorized_keys文件分发到每个slave节点,这样只需要
2n
次操作
在每个slave节点执行:
# cd
# mkdir .ssh
# cd ./.ssh
# ssh-keygen
# scp id_rsa.pub root@master:/root/这时是没有免密登录的,所以scp命令需要输入对方的密码,也就是安装系统的时候root的密码
每个slave执行完后,切换到master执行
# cd
# cat id_rsa.pub >> ./.ssh/authorized_keys再切换到下一个slave
当我们都设置完成后在master节点用scp命令挨个发送到每个slave节点的/root/.ssh文件夹下
最后用ssh命令检查是否成功,ssh是直接登录,比如ssh slave1后你就到了slave1的系统中,并不是还在master节点系统里
# ssh slave1
# ssh slave2
# ssh slave3
ssh 每个节点
# ssh master注意: 如果这一步后如果无法免密登录请修改文件权限:
# cd
# chmod 700 .ssh
# chmod 600 ./.ssh/authorized_keys三、启动hadoop集群
经过上面的配置,我们的hadoop已经饥渴难耐只等着你来跑数据了!
首先格式化namenode节点,注意在master节点上!
# cd /root/hadoop-2.7.3/bin
# hadoop namenode -format然后启动集群
# start-dfs.sh
# start-yarn.sh在master节点运行
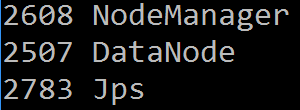
# jps看到如下进程:
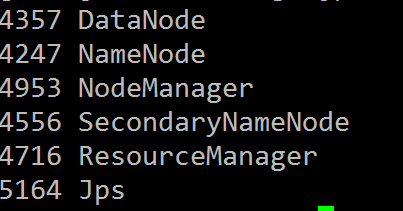
切换到slave节点
# jps看到如下进程
浏览器中打开namenode(master)的50070端口http://192.168.1.151:50070/dfshealth.html#tab-datanode,可以看见

四、运行测试用例
切换到hadoop根目录
执行:
# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 20 10
如果显示如下:
[root@master hadoop-2.7.3]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 20 10
Number of Maps = 20
Samples per Map = 10
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot create directory /user/root/QuasiMonteCarlo_1477866128357_872988341/in. Name node is in safe mode.
The reported blocks 126 needs additional 15 blocks to reach the threshold 0.9990 of total blocks 141.
The number of live datanodes 7 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached.
证明hadoop处于安全模式,我们执行
# bin/hadoop dfsadmin -safemode leave然后再运行例子
成功后会做如下输出:
[root@master hadoop-2.7.3]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 20 10
Number of Maps = 20
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10
Wrote input for Map #11
Wrote input for Map #12
Wrote input for Map #13
Wrote input for Map #14
Wrote input for Map #15
Wrote input for Map #16
Wrote input for Map #17
Wrote input for Map #18
Wrote input for Map #19
Starting Job
16/10/31 06:26:11 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.1.151:8032
16/10/31 06:26:11 INFO input.FileInputFormat: Total input paths to process : 20
16/10/31 06:26:13 INFO mapreduce.JobSubmitter: number of splits:20
16/10/31 06:26:13 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1477865558623_0002
16/10/31 06:26:14 INFO impl.YarnClientImpl: Submitted application application_1477865558623_0002
16/10/31 06:26:14 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1477865558623_0002/
16/10/31 06:26:14 INFO mapreduce.Job: Running job: job_1477865558623_0002
16/10/31 06:26:20 INFO mapreduce.Job: Job job_1477865558623_0002 running in uber mode : false
16/10/31 06:26:20 INFO mapreduce.Job: map 0% reduce 0%
16/10/31 06:26:27 INFO mapreduce.Job: map 5% reduce 0%
16/10/31 06:26:32 INFO mapreduce.Job: map 10% reduce 0%
16/10/31 06:26:33 INFO mapreduce.Job: map 15% reduce 0%
16/10/31 06:26:34 INFO mapreduce.Job: map 25% reduce 0%
16/10/31 06:26:35 INFO mapreduce.Job: map 35% reduce 0%
16/10/31 06:26:36 INFO mapreduce.Job: map 50% reduce 0%
16/10/31 06:26:37 INFO mapreduce.Job: map 55% reduce 0%
16/10/31 06:26:39 INFO mapreduce.Job: map 60% reduce 0%
16/10/31 06:26:41 INFO mapreduce.Job: map 100% reduce 0%
16/10/31 06:26:43 INFO mapreduce.Job: map 100% reduce 100%
16/10/31 06:26:44 INFO mapreduce.Job: Job job_1477865558623_0002 completed successfully
16/10/31 06:26:44 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=446
FILE: Number of bytes written=2500465
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=5350
HDFS: Number of bytes written=215
HDFS: Number of read operations=83
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=20
Launched reduce tasks=1
Data-local map tasks=6
Rack-local map tasks=14
Total time spent by all maps in occupied slots (ms)=276691
Total time spent by all reduces in occupied slots (ms)=12644
Total time spent by all map tasks (ms)=276691
Total time spent by all reduce tasks (ms)=12644
Total vcore-milliseconds taken by all map tasks=276691
Total vcore-milliseconds taken by all reduce tasks=12644
Total megabyte-milliseconds taken by all map tasks=283331584
Total megabyte-milliseconds taken by all reduce tasks=12947456
Map-Reduce Framework
Map input records=20
Map output records=40
Map output bytes=360
Map output materialized bytes=560
Input split bytes=2990
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=560
Reduce input records=40
Reduce output records=0
Spilled Records=80
Shuffled Maps =20
Failed Shuffles=0
Merged Map outputs=20
GC time elapsed (ms)=5447
CPU time spent (ms)=16120
Physical memory (bytes) snapshot=5005144064
Virtual memory (bytes) snapshot=43973459968
Total committed heap usage (bytes)=3805175808
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2360
File Output Format Counters
Bytes Written=97
Job Finished in 33.959 seconds
Estimated value of Pi is 3.12000000000000000000
至此,hadoop配置及验证全部完成















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









