






layout: post title: "JavaSE基础知识" date: 2018-06-28 10:36 toc: true comments: true categories: 技术学习 tags: - Java - web
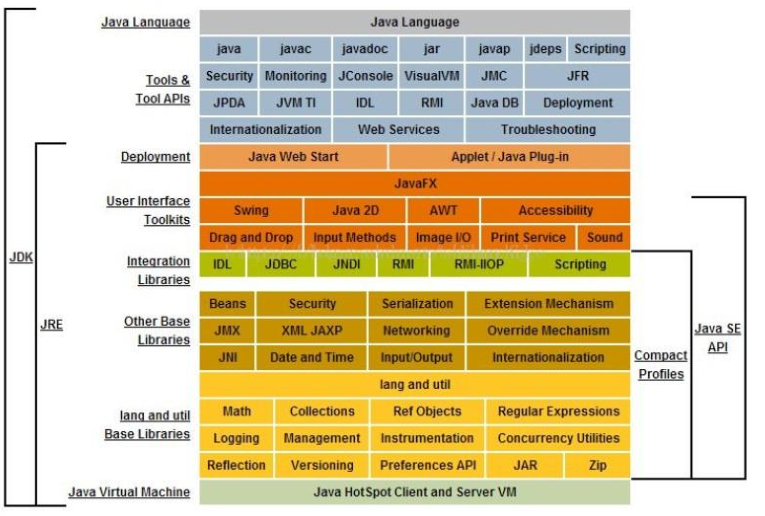
概述
字节是我们常见的计算机中最小存储单元。计算机存储任何的数据,都是以字节的形式存储,8个bit(二进制位) 0000-0000表示为1个字节,写成1 byte或者1 B。
Dos命令((Microsoft Disk Operating System)):dir,cls,exit
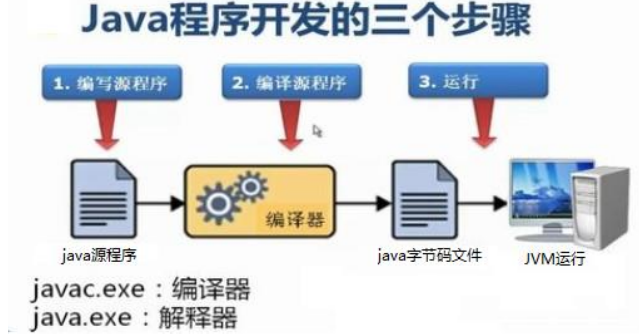
编译 :是指将我们编写的Java源文件翻译成JVM认识的class文件,在这个过程中, javac 编译器会检查我们所写的程序是否有错误,有错误就会提示出来,如果没有错误就会编译成功。 运行 :是指将 class 文件 交给JVM去运行,此时JVM就会去执行我们编写的程序了。
main 方法:称为主方法。写法是固定格式不可以更改。main方法是程序的入口点或起始点,无论我们编写多少程序,JVM在运行的时候,都会从main方法这里开始执行。
数据类型
基本数据类型
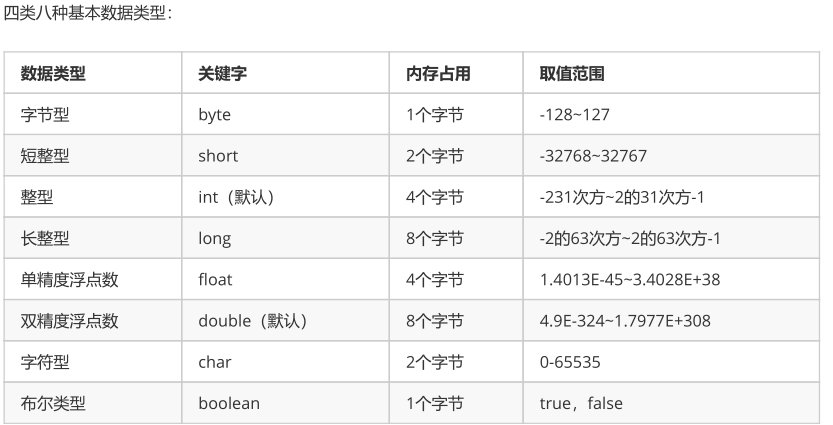
Java中的默认类型:整数类型是 int 、浮点类型是 double ,float要在数字后加F,long要加L,推荐使用大写字母后缀。
String#intern()
在 JAVA 语言中有8中基本类型和一种比较特殊的类型String。这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。常量池就类似一个JAVA系统级别提供的缓存。
8种基本类型的常量池都是系统协调的,String类型的常量池比较特殊。它的主要使用方法有两种:
- 直接使用双引号声明出来的
String对象会直接存储在常量池中。 - 如果不是用双引号声明的
String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中
接下来我们主要来谈一下String#intern方法。
public native String intern(); String#intern方法中看到,这个方法是一个 native 的方法,但注释写的非常明了。“如果常量池中存在当前字符串, 就会直接返回当前字符串. 如果常量池中没有此字符串, 会将此字符串放入常量池中后, 再返回”。
native 代码
在 jdk7后,oracle 接管了 JAVA 的源码后就不对外开放了,根据 jdk 的主要开发人员声明 openJdk7 和 jdk7 使用的是同一分主代码,只是分支代码会有些许的变动。所以可以直接跟踪 openJdk7 的源码来探究 intern 的实现。
####native实现代码: \openjdk7\jdk\src\share\native\java\lang\String.c
Java_java_lang_String_intern(JNIEnv *env, jobject this)
{
return JVM_InternString(env, this);
} \openjdk7\hotspot\src\share\vm\prims\jvm.h
/*
* java.lang.String
*/
JNIEXPORT jstring JNICALL
JVM_InternString(JNIEnv *env, jstring str); \openjdk7\hotspot\src\share\vm\prims\jvm.cpp
// String support ///
JVM_ENTRY(jstring, JVM_InternString(JNIEnv *env, jstring str))
JVMWrapper("JVM_InternString");
JvmtiVMObjectAllocEventCollector oam;
if (str == NULL) return NULL;
oop string = JNIHandles::resolve_non_null(str);
oop result = StringTable::intern(string, CHECK_NULL);
return (jstring) JNIHandles::make_local(env, result);
JVM_END \openjdk7\hotspot\src\share\vm\classfile\symbolTable.cpp
oop StringTable::intern(Handle string_or_null, jchar* name,
int len, TRAPS) {
unsigned int hashValue = java_lang_String::hash_string(name, len);
int index = the_table()->hash_to_index(hashValue);
oop string = the_table()->lookup(index, name, len, hashValue);
// Found
if (string != NULL) return string;
// Otherwise, add to symbol to table
return the_table()->basic_add(index, string_or_null, name, len,
hashValue, CHECK_NULL);
} \openjdk7\hotspot\src\share\vm\classfile\symbolTable.cpp
oop StringTable::lookup(int index, jchar* name,
int len, unsigned int hash) {
for (HashtableEntry<oop>* l = bucket(index); l != NULL; l = l->next()) {
if (l->hash() == hash) {
if (java_lang_String::equals(l->literal(), name, len)) {
return l->literal();
}
}
}
return NULL;
} 它的大体实现结构就是: JAVA 使用 jni 调用c++实现的StringTable的intern方法, StringTable的intern方法跟Java中的HashMap的实现是差不多的, 只是不能自动扩容。默认大小是1009。
要注意的是,String的String Pool是一个固定大小的Hashtable,默认值大小长度是1009,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降(因为要一个一个找)。
在 jdk6中StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。在jdk7中,StringTable的长度可以通过一个参数指定:
-XX:StringTableSize=99991
相信很多 JAVA 程序员都做做类似 String s = new String("abc")这个语句创建了几个对象的题目。 这种题目主要就是为了考察程序员对字符串对象的常量池掌握与否。上述的语句中是创建了2个对象,第一个对象是”abc”字符串存储在常量池中,第二个对象在JAVA Heap中的 String 对象。
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
- jdk6 下`false false`
- jdk7 下`false true`注:图中绿色线条代表 string 对象的内容指向。 黑色线条代表地址指向
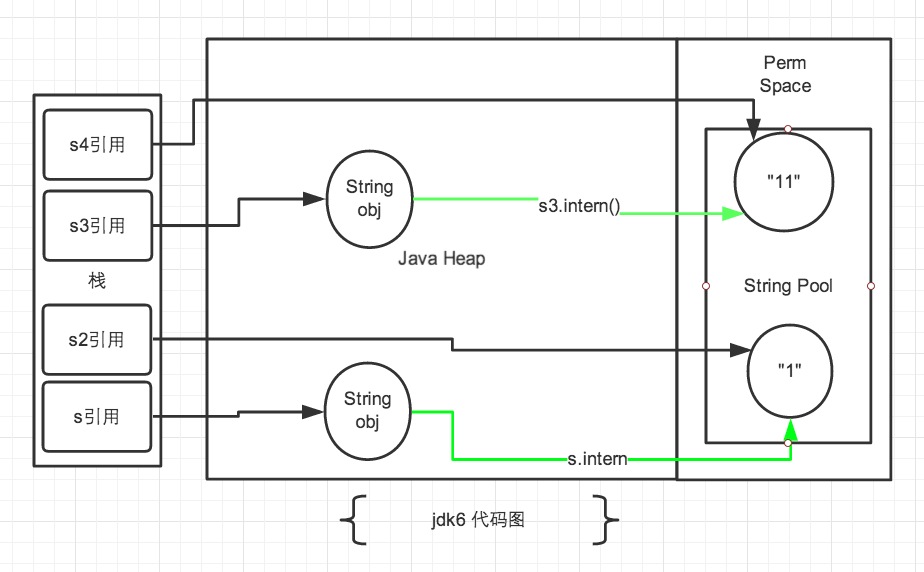
jdk6中的常量池是放在 Perm 区中的,Perm 区和正常的 JAVA Heap 区域是完全分开的。上面说过如果是使用引号声明的字符串都是会直接在字符串常量池中生成,而 new 出来的 String 对象是放在 JAVA Heap 区域。所以拿一个 JAVA Heap 区域的对象地址和字符串常量池的对象地址进行比较肯定是不相同的,即使调用String.intern方法也是没有任何关系的。
在 Jdk6 以及以前的版本中,字符串的常量池是放在堆的 Perm 区的,Perm 区是一个类静态的区域,主要存储一些加载类的信息,常量池,方法片段等内容,默认大小只有4m,一旦常量池中大量使用 intern 是会直接产生java.lang.OutOfMemoryError: PermGen space错误的。 所以在 jdk7 的版本中,字符串常量池已经从 Perm 区移到正常的 Java Heap 区域了。为什么要移动,Perm 区域太小是一个主要原因, jdk8 已经直接取消了 Perm 区域,而新建立了一个元区域。
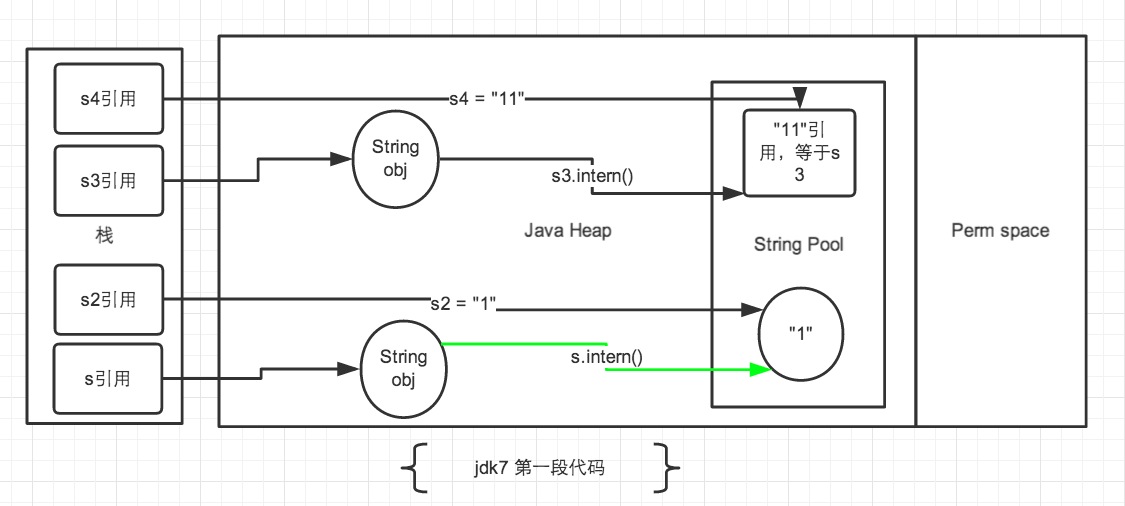
- 先看 s3和s4字符串。
String s3 = new String("1") + new String("1");,这句代码中现在生成了2最终个对象,是字符串常量池中的“1” 和 JAVA Heap 中的 s3引用指向的对象。中间还有2个匿名的new String("1")我们不去讨论它们。此时s3引用对象内容是”11”,但此时常量池中是没有 “11”对象的。 - 接下来
s3.intern();这一句代码,是将 s3中的“11”字符串放入 String 常量池中,因为此时常量池中不存在“11”字符串,因此常规做法是跟 jdk6 图中表示的那样,在常量池中生成一个 “11” 的对象,关键点是 jdk7 中常量池不在 Perm 区域了,这块做了调整。常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用指向 s3 引用的对象。 也就是说引用地址是相同的。 - 最后
String s4 = "11";这句代码中”11”是显示声明的,因此会直接去常量池中创建,创建的时候发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。所以 s4 引用就指向和 s3 一样了。因此最后的比较s3 == s4是 true。 - 再看 s 和 s2 对象。
String s = new String("1");第一句代码,生成了2个对象。常量池中的“1” 和 JAVA Heap 中的字符串对象。s.intern();这一句是 s 对象去常量池中寻找后发现 “1” 已经在常量池里了。 - 接下来
String s2 = "1";这句代码是生成一个 s2的引用指向常量池中的“1”对象。 结果就是 s 和 s2 的引用地址明显不同。图中画的很清晰。
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
打印结果为:
jdk6 下false false
jdk7 下false false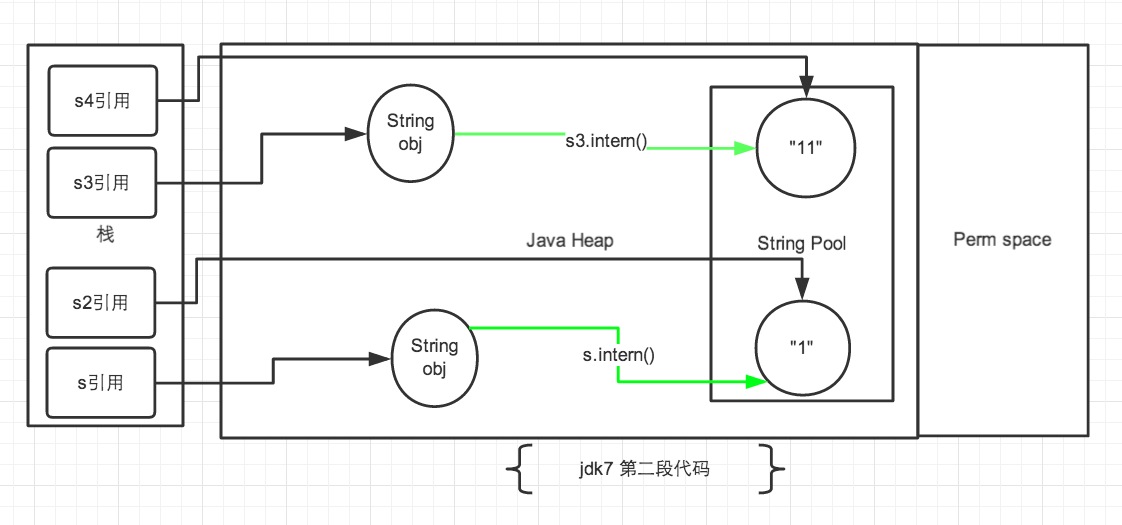
- 来看第二段代码,从上边第二幅图中观察。第一段代码和第二段代码的改变就是
s3.intern();的顺序是放在String s4 = "11";后了。这样,首先执行String s4 = "11";声明 s4 的时候常量池中是不存在“11”对象的,执行完毕后,“11“对象是 s4 声明产生的新对象。然后再执行s3.intern();时,常量池中“11”对象已经存在了,因此 s3 和 s4 的引用是不同的。 - 第二段代码中的 s 和 s2 代码中,
s.intern();,这一句往后放也不会有什么影响了,因为对象池中在执行第一句代码String s = new String("1");的时候已经生成“1”对象了。下边的s2声明都是直接从常量池中取地址引用的。 s 和 s2 的引用地址是不会相等的。
####小结 从上述的例子代码可以看出 jdk7 版本对 intern 操作和常量池都做了一定的修改。主要包括2点:
- 将String常量池 从 Perm 区移动到了 Java Heap区
String#intern方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。
包装类
包装类分成引用和实例,引用在栈(stack)中,具体实例在堆(heap)中,jdk5.0开始增加自动装箱/拆箱。
Integer i = Integer.valueOf(1); //手动装箱
Integer j = 1; //自动装箱
Integer i0 = new Integer(1);
int i1 = i0; //自动拆箱
int i2 = i0.intValue(); //手动拆箱包装类缓存机制
Java对部分经常使用的数据采用缓存技术,在类第一次被加载时换创建缓存和数据。当使用等值对象时直接从缓存中获取,从而提高了程序执行性能。(通常只对常用数据进行缓存)
1 equals方法比较的是真正的值
double i0 = 0.1;
Double i1 = new Double(0.1);
Double i2 = new Double(0.1);
System.out.println(i1.equals(i2)); //true 2个包装类比较,比较的是包装的基本数据类型的值
System.out.println(i1.equals(i0)); //true 基本数据类型和包装类型比较时,会先把基本数据类型包装后再比较基本数据类型和包装类比较时,会先把基本数据类型包装成对应的包装类型,再进行比较。查看JDK中Double包装类的equals方法:

equals方法中的参数是一个Object对象,而基本数据类型并不是一个对象类型,所以需要先将基本数据类型包装成对应的包装类后才能作为参数传入equals方法中。
2 ==(双等号)比较对象内存地址
对于基本数据类型,==(双等号)比较的是值,而对于包装类型,==(双等号)比较的则是2个对象的内存地址。
double i0 = 0.1;
Double i1 = new Double(0.1);
Double i2 = new Double(0.1);
System.out.println(i1 == i2); //false new出来的都是新的对象
System.out.println(i1 == i0); //true 基本数据类型和包装类比较,会先把包装类拆箱new出来的都是新的对象。2个新的对象内存地址不同,那么==号比较的结果肯定是false。 基本数据类型和包装类型比较时,会先把包装类拆箱再进行值比较(和equals是反的)。
另一个陷阱:
Double i1 = Double.valueOf(0.1);
Double i2 = Double.valueOf(0.1);
System.out.println(i1 == i2); //false valueOf方法内部实际上也是newvalueOf内部也是用的new方法来构造对象的。2个new出来的对象,内存地址肯定是不一样的。

下面的代码运行结果却让人大跌眼镜:(缓存机制)
System.out.println(Integer.valueOf(1) ==Integer.valueOf(1)); //true
System.out.println(Integer.valueOf(999) ==Integer.valueOf(999)); //false 查看Integer.valueOf方法的源码:

可以看到,当i的值在low和high范围内是,返回的是一个cache里的Integer对象。从-128到到127之间的值都被缓存到cache里了。这个叫做包装类的缓存。 Integer默认缓存是-128到127之间的对象,最大值127可以通过-XX:AutoBoxCacheMax=size修改。
包装类中整数型的类型基本上都有缓存数据。可以通过阅读源码了解。不过只有Integer类可以通过修改JVM参数来更改缓存上限。
1. Integer类型有缓存-128-127的对象。缓存上限可以通过配置jvm更改
2. Byte,Short,Long类型有缓存(-128-127)
3. Character缓存0-127
4. Boolean缓存TRUE、FALSE尤其需要特别注意的是,只有valueOf方法构造对象时会用到缓存,new方法等不会使用缓存!
Integer i4 = Integer.valueOf(1);
Integer i5 =1;
System.out.println(i4 == i5); //true
Integer i7 = Integer.valueOf(999);
Integer i8 = 999;
System.out.println(i7 == i8); //false自动包装时实际上还是调用的valueOf方法。而上面我们讲过的,valueOf方法用到了缓存池。
Java基本类型内存占用
Java数据类型在不同机器中的大小都相同。
内存公式:Java对象的内存布 = 对象头(Header) + 实例数据(Instance Data) + 补齐填充(Padding)。
对象头不开压缩16字节,开压缩12字节;对象引用不开压缩8字节,开压缩4字节;填充到8字节的倍数;数组对象头24字节,压缩后16字节;String包含2个属性,一个用于存放字符串数据的char[], 一个int类型的hashcode
对象头:Instance Header,Java对象最复杂的一部分,采用C++定义了头的协议格式,存储了Java对象hash、GC年龄、锁标记、class指针、数组长度等信息,稍后做出详细解说。在64位机器上,默认不开启指针压缩(-XX:-UseCompressedOops)的情况下,对象头占用16bytes,开启指针压缩(-XX:+UseCompressedOops)则占用12bytes。
实例数据:Instance Data,这部分数据才是真正具有业务意义的数据,实际上就是当前对象中的实例字段。在VM中,对象的字段是由基本数据类型和引用类型组成的。对象引用(ref)类型在64位机器上,关闭指针压缩时占用8bytes, 开启时占用4bytes。

补齐填充:Java对象占用空间是8字节对齐的,即所有Java对象占用bytes数必须是8的倍数
Shallow Size 对象自身占用的内存大小,不包括它引用的对象。 针对非数组类型的对象,它的大小就是对象与它所有的成员变量大小的总和。当然这里面还会包括一些java语言特性的数据存储单元。 针对数组类型的对象,它的大小是数组元素对象的大小总和。
Retained Size Retained Size=当前对象大小+当前对象可直接或间接引用到的对象的大小总和。(间接引用的含义:A->B->C, C就是间接引用) 换句话说,Retained Size就是当前对象被GC后,从Heap上总共能释放掉的内存。 不过,释放的时候还要排除被GC Roots直接或间接引用的对象。他们暂时不会被被当做Garbage。
JProfiler可以验证内存占用,默认64位,打开指针压缩
1 新建一个空对象,观察空对象内存占用
public class TestObject {}
一般自建空对象占用内存 \16b*,16 = 12(Header) + 4(Padding)*
2 在TestObj中新增一个 int 属性,观察对象内存占用
public class TestObj {private int i;}int 占用 \4b*, 16 = 12(Header) + 4(int)*
3 在TestObj中新增一个 long 属性,观察对象内存占用

long 占用 \8b*, 24 = 12(Header) + 8(long) + 4(Padding)*
Java包装类型内存占用
包装类(Boolean/Byte/Short/Character/Integer/Long/Double/Float)占用内存的大小 = 对象头大小 + 底层基础数据类型的大小。包装类和其他引用类一样,会产生一个引用(reference)

1 在TestObj中新增一个 Integer 属性,观察对象内存占用
public class TestObj { private Integer i =128; }
Integer 占用 \16b*, 32 = 12 (Header) + 16(Integer) + 4(reference)*
特别的:-128~127 在常量池,只占用 \4b****,且不产生引用(reference)
2 在TestObj中新增一个 Long 属性,观察对象内存占用
public class TestObj { private Long l = new Long(1); }
Long 占用 \24b*, 40 = 12 (Header) + 24(Long) + 4(reference)*
java数组内存占用
64位机器上,数组对象的对象头占用24 bytes,启用压缩后占用16字节。比普通对象占用内存多是因为需要额外的空间存储数组的长度。基础数据类型数组占用的空间包括数组对象头以及基础数据类型数据占用的内存空间。由于对象数组中存放的是对象的引用,所以对象数组本身的大小=数组对象头+length * 引用指针大小,总大小为对象数组本身大小+存放的数据的大小之和。
int[10]:
开启压缩:16 + 10 * 4 = 56 bytes;
关闭压缩:24 + 10 * 4 = 64bytes。
new Integer[3]:
关闭压缩:
Integer数组本身:24(header) + 3 * 8(Integer reference) = 48 bytes;
总共:48 + 3 * 24(Integer) = 120 bytes。
开启压缩:
Integer数组本身:16(header) + 3 * 4(Integer reference) = 28(padding) -> 32 (bytes)
总共:32 + 3 * 16(Integer) = 80 (bytes)在TestObj中新增一个 char[] 属性,观察对象内存占用
public class TestObj { private char[] c = {'a','b','c'}; }
char[3] 占用 \24b*, 24 = 40 - 16,24 = 16(Header) + 3 \ 2(char) + 2(Padding)**
封装类型数组比基本类型的数组,需要多管理元素的引用
对象数组本身的大小=数组对象头+length * 引用指针大小 + length * 存放单个元素大小public class TestObj { private Integer[] i = {128,129,130}; }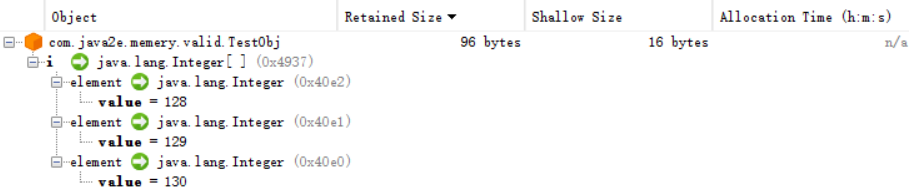
Integer[3] 占用 \80b*, 80 = 96 - 16, 80 = 16(Header) + 3 \ 4 (reference)+ 3 * 16(Integer) +4(padding)**
String内存占用
在JDK1.7及以上版本中,String包含2个属性,一个用于存放字符串数据的char[], 一个int类型的hashcode, 部分源代码如下:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
}在关闭指针压缩时,一个空字符串("")的大小应为
一个String本身需要 16(Header) + 8(char[] reference) + 4(int) = 32 bytes。
一个char[]占用24 + length * 2 bytes(8字节对齐)
即一个String占用的内存空间大小为:56 + length * 2 bytes (8字节对齐)。
一个空字符串("")的大小应为:56 + 0 * 2 bytes = 56 bytes。字符串"abcde"在开启指针压缩时的大小为:
String本身:12(Header) + 4(char[] reference) + 4(int hash) = 20(padding) -> 24 (bytes);
存储数据:16(char[] header) + 5*2 = 26(padding) -> 32 (bytes)
总共:24 + 32 = 56 (bytes) 在TestObj中新增一个空 String 属性,观察对象内存占用
public class TestObj {private String s = new String("");}
String 本身占用 \24b*, 24 = 40 -16*,也就是说空""也需要16b
这里为什么要写String s = new String("")?
答:如果写成String s = “”,是不会再堆中开辟内存的,也就看不到String占用的空间,你看到的将会是下面的,至于为什么,都是因为final

复杂对象内存占用
class Parent {
protected int x; // 4字节
protected int y; // 4字节
protected boolean flag; // 1字节
}
class Child extends Parent {
private int z; // 4字节
}
public class ExtendsObjectSizer {
public static void main(String[] args) {
System.out.println("继承对象的大小为:" + ObjectSizeFetcher.sizeOf(new Child()) + "字节");
}
}
## 没有开启指针压缩功能 40byte
java -XX:-UseCompressedOops -javaagent:ObjectSizeFetcherAgent-1.0-SNAPSHOT.jar com.twq.ExtendsObjectSizer
## 开启指针压缩功能 32byte
java -XX:+UseCompressedOops -javaagent:ObjectSizeFetcherAgent-1.0-SNAPSHOT.jar com.twq.ExtendsObjectSizer不开压缩40字节 = 16 + (4 + 4 + 1 + 7) + 4 + 7

32字节 = 12 + 4 + 4 + 1 + 7 + 4

class Employee {
private int age; // 4字节
private double high; // 8字节
}
class Dept {
private int num; // 4字节
private Employee[] employees = new Employee[3];
public Dept() {
for (int i = 0; i < employees.length; i++) {
employees[i] = new Employee();
}
}
}
public class CompositeObjectSizer {
public static void main(String[] args) throws IllegalAccessException {
System.out.println("复合对象内存的大小为:" + ObjectSizeFetcher.sizeOf(new Dept()) + "字节");
System.out.println("复合对象内存的总大小为:" + ObjectSizeFetcher.fullSizeOf(new Dept()) + "字节");
}
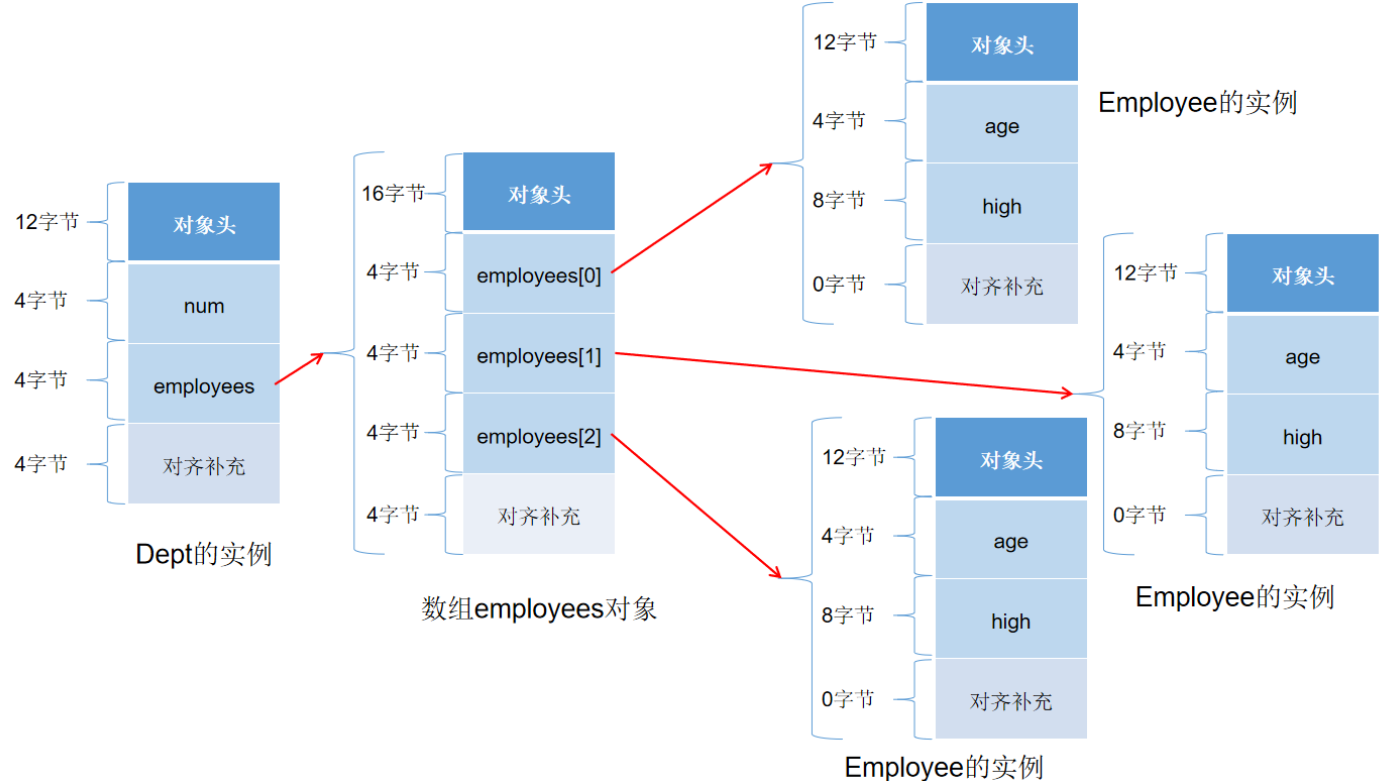
}可以看出复合对象内存的大小为32字节 = 对象头16字节 + num属性4字节 + employees引用类型的大小8字节 + 对齐补充4字节
这个32字节也只是直接计算当前Dept对象占用空间大小,这个大小并没有包含数组employees中所有的Employee的内存大小,那么这个复合对象的总大小为176字节,这个大小包括了数组employees中所有的Employee的内存大小,也就是递归计算当前对象占用空间总大小。
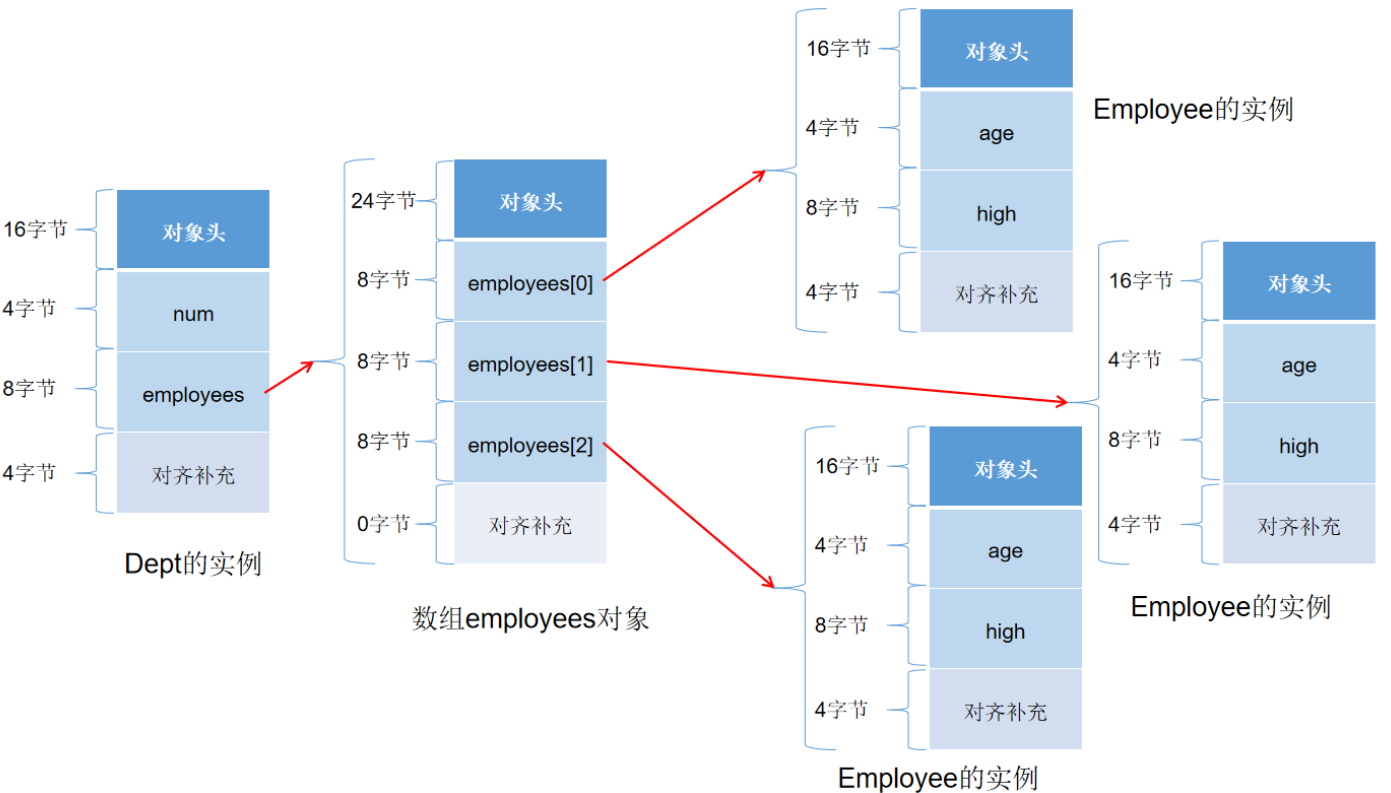
## 开启指针压缩功能
java -XX:+UseCompressedOops -javaagent:ObjectSizeFetcherAgent-``1.0``-SNAPSHOT.jar com.twq.CompositeObjectSizer可以看出复合对象内存的大小为24字节 = 对象头12字节 + num属性4字节 + employees引用类型的大小4字节 + 对齐补充4字节
在开启指针压缩功能的情况下,Dept复合对象的总大小为128字节,如下图:
ArrayList
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
protected transient int modCount = 0;
}
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // non-private to simplify nested class access
private int size;
}static变量属于类,不属于实例,存放在全局数据段。普通变量才纳入Java对象占用空间的计算,一个用于存放数组元素的Object[], 一个int类型的size,还有一个是父类中int类型的modCount。因此:
- 在64位操作系统,且未开启指针压缩功能的前提下,
new ArrayList()的内存大小应为:对象头16字节 + 父类属性modCount大小4字节 + 对齐补充4字节 + 子类Object[]引用类型的8字节 + 子类int类型的属性大小4字节 + 对齐补充4字节 = 40字节 - 在64位操作系统,且开启了指针压缩功能的前提下,
new ArrayList()的内存大小应为:对象头12字节 + 父类属性modCount大小4字节 + 对齐补充4字节 + 子类Object[]引用类型的4字节 + 子类int类型的属性大小4字节 + 对齐补充4字节 = 32字节
常用数据类型转换
范围小的类型向范围大的类型提升, byte 、short、char 运算时直接提升为 int 。
byte、short、char‐‐>int‐‐>long‐‐>float‐‐>double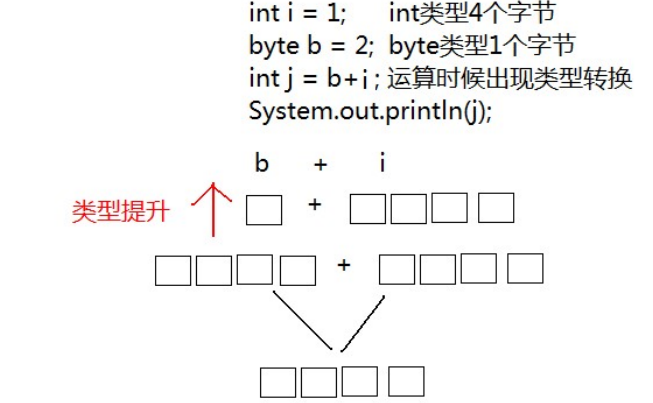
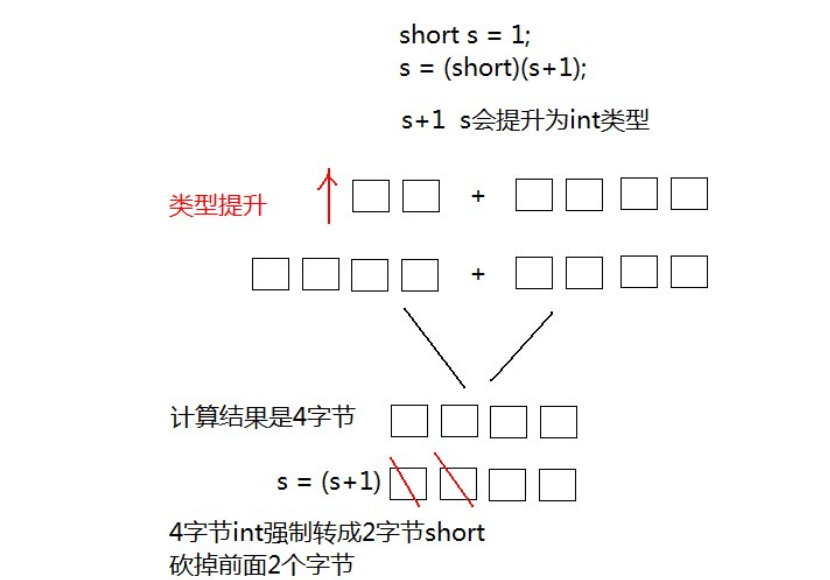
强制类型转换 :将 取值范围大的类型 强制转换成 取值范围小的类型 。
String的类型转换
String转int和long和float
把String类型转换为int类型,常用的有以下三种方法:parseInt,强制转换,先转Integer类型再调用intValue()
public static void main(String[] args) {
String number = "123456";
int num1 = Integer.parseInt(number);//使用Integer的parseInt方法
int num2 = new Integer(number);//强制转换
int num3 = Integer.valueOf(number).intValue();//先转Integer类型,再调用intValue()转为int
long num1 = Long.parseLong(number);//调用Long类型的parseLong方法
long num2 = new Long(number);//强制转换
long num3 = Long.valueOf(number).longValue();//先转换Long类型,再使用longValue方法转为long
float num1 = Float.parseFloat(number);//调用Float的parseFloat方法
float num2 = new Float(number);//强制转换
float num3 = Float.valueOf(number).floatValue();//先转为Float类型再使用floatValue转为float
}String转byte[]
使用String类自带的getBytes()方法。
byte[] num = "1234567890".getBytes();这里补充一个path类型转换为String类型的方法:
String fileName=path.getFileName().toString();long类型转换
long转String
long number = 1234567890l;
String num1 = Long.toString(number);//Long的tostring方法
String num2 = String.valueOf(number);//使用String的valueOf方法
String num3 = "" + number;//这个应该属于强制转换吧long转int
long number = 121121121l;
int num1 = (int) number;// 强制类型转换
int num2 = new Long(number).intValue();// 调用intValue方法
int num3 = Integer.parseInt(String.valueOf(number));// 先把long转换位字符串String,然后转换为Integerbyte数组类型转换
在Java的网络编程中传输的经常是byte数组,但我们实际中使用的数据类型可能是任一种数据类型,这就需要在它们之间相互转换,转换的核心在于将其他类型的数据的每一位转换成byte类型的数据。
string与byte数组的互转
byte[] number = "121121".getBytes();
String num1 = new String(number);short与byte数组的互转
//转换short为byte
public static void putShort(byte b[], short s, int index) {
b[index + 1] = (byte) (s >> 8);//取最高8位放到1下标
b[index + 0] = (byte) (s >> 0);
}
//通过byte数组取到short
public static short getShort(byte[] b, int index) {
return (short) (((b[index + 1] << 8) | b[index + 0] & 0xff));
}int与byte数组的互转
//将32位的int值放到4字节的byte数组
public static byte[] intToByteArray(int num) {
byte[] result = new byte[4];
result[0] = (byte)(num >>> 24);//取最高8位放到0下标
result[1] = (byte)(num >>> 16);//取次高8为放到1下标
result[2] = (byte)(num >>> 8); //取次低8位放到2下标
result[3] = (byte)(num ); //取最低8位放到3下标
return result;
}
//将4字节的byte数组转成一个int值
public static int byteArrayToInt(byte[] b){
byte[] a = new byte[4];
int i = a.length - 1,j = b.length - 1;
for (; i >= 0 ; i--,j--) {//从b的尾部(即int值的低位)开始copy数据
if(j >= 0)
a[i] = b[j];
else
a[i] = 0;//如果b.length不足4,则将高位补0
}
int v0 = (a[0] & 0xff) << 24;//&0xff将byte值无差异转成int,避免Java自动类型提升后,会保留高位的符号位
int v1 = (a[1] & 0xff) << 16;
int v2 = (a[2] & 0xff) << 8;
int v3 = (a[3] & 0xff) ;
return v0 + v1 + v2 + v3;
}long与byte数组的互转
//将64位的long值放到8字节的byte数组
public static byte[] longToByteArray(long num) {
byte[] result = new byte[8];
result[0] = (byte) (num >>> 56);// 取最高8位放到0下标
result[1] = (byte) (num >>> 48);// 取最高8位放到0下标
result[2] = (byte) (num >>> 40);// 取最高8位放到0下标
result[3] = (byte) (num >>> 32);// 取最高8位放到0下标
result[4] = (byte) (num >>> 24);// 取最高8位放到0下标
result[5] = (byte) (num >>> 16);// 取次高8为放到1下标
result[6] = (byte) (num >>> 8); // 取次低8位放到2下标
result[7] = (byte) (num); // 取最低8位放到3下标
return result;
}
//将8字节的byte数组转成一个long值
public static long byteArrayToInt(byte[] byteArray) {
byte[] a = new byte[8];
int i = a.length - 1, j = byteArray.length - 1;
for (; i >= 0; i--, j--) {// 从b的尾部(即int值的低位)开始copy数据
if (j >= 0)
a[i] = byteArray[j];
else
a[i] = 0;// 如果b.length不足4,则将高位补0
}
// 注意此处和byte数组转换成int的区别在于,下面的转换中要将先将数组中的元素转换成long型再做移位操作,
// 若直接做位移操作将得不到正确结果,因为Java默认操作数字时,若不加声明会将数字作为int型来对待,此处必须注意。
long v0 = (long) (a[0] & 0xff) << 56;// &0xff将byte值无差异转成int,避免Java自动类型提升后,会保留高位的符号位
long v1 = (long) (a[1] & 0xff) << 48;
long v2 = (long) (a[2] & 0xff) << 40;
long v3 = (long) (a[3] & 0xff) << 32;
long v4 = (long) (a[4] & 0xff) << 24;
long v5 = (long) (a[5] & 0xff) << 16;
long v6 = (long) (a[6] & 0xff) << 8;
long v7 = (long) (a[7] & 0xff);
return v0 + v1 + v2 + v3 + v4 + v5 + v6 + v7;
}float与byte数组的互转
public static void putFloat(byte[] bb, float x, int index) {
// byte[] b = new byte[4];
int l = Float.floatToIntBits(x);
for (int i = 0; i < 4; i++) {
bb[index + i] = new Integer(l).byteValue();
l = l >> 8;
}
}
public static float getFloat(byte[] b, int index) {
int l;
l = b[index + 0];
l &= 0xff;
l |= ((long) b[index + 1] << 8);
l &= 0xffff;
l |= ((long) b[index + 2] << 16);
l &= 0xffffff;
l |= ((long) b[index + 3] << 24);
return Float.intBitsToFloat(l);
}double与byte数组的互转
public static void putDouble(byte[] bb, double x, int index) {
// byte[] b = new byte[8];
long l = Double.doubleToLongBits(x);
for (int i = 0; i < 4; i++) {
bb[index + i] = new Long(l).byteValue();
l = l >> 8;
}
}
public static double getDouble(byte[] b, int index) {
long l;
l = b[0];
l &= 0xff;
l |= ((long) b[1] << 8);
l &= 0xffff;
l |= ((long) b[2] << 16);
l &= 0xffffff;
l |= ((long) b[3] << 24);
l &= 0xffffffffl;
l |= ((long) b[4] << 32);
l &= 0xffffffffffl;
l |= ((long) b[5] << 40);
l &= 0xffffffffffffl;
l |= ((long) b[6] << 48);
l &= 0xffffffffffffffl;
l |= ((long) b[7] << 56);
return Double.longBitsToDouble(l);
}int类型的转换
int转String
int number = 121121;
String num1 = Integer.toString(number);//使用Integer的toString方法
String num2 = String.valueOf(number);//使用String的valueOf方法
String num3 = "" + number;//也是强制转换吧int转long
int number = 123111;
long num1 = (long) number;//强制
long num2 = Long.parseLong(new Integer(number).toString());//先转String再进行转换
long num3 = Long.valueOf(number);int转Interger
int number = 123456;
Integer num1 = Integer.valueOf(number);
Integer num2 = new Integer(number);int 进制转换
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
System.out.println("十进制转换到其它进制:");
int x = 123 ;
String str1 = Integer.toHexString(x) ; ///10进制转换成16进制的字符串
System.out.println(str1);
String str2 = Integer.toOctalString(x) ; ///10进制转换成8进制的字符串
System.out.println(str2);
String str3 = Integer.toBinaryString(x) ; ///10进制转换成2进制的字符串
System.out.println(str3);
String str4 = Integer.toString(123456,7) ; ///10进制转换成7进制的字符串
///String str4 = Integer.toString(i,x) ; ///10进制的数字i转换成x进制的字符串
System.out.println("其它制转换到十进制:");
int y1= Integer.valueOf("FFFF",16); ///16进制转换成10进制
System.out.println(y1);
int y2=Integer.valueOf("776",8); ///8进制转换成10进制
System.out.println(y2);
int y3=Integer.valueOf("0101",2); //2进制转换成10进制
System.out.println(y3);
int y4=Integer.valueOf("101",7); //7进制转换成10进制
System.out.println(y4);
///Integer.valueOf("str",x); ///可以为任意进制的字符串str转换成x进制的10进制数
System.out.println("其它的可能用到的函数:");
//static int parseInt(String s, int radix) //使用第二个参数指定的基数,将字符串参数解析为有符号的整数。
int n = Integer.parseInt("776", 8) ; ///8进制转换成10进制
System.out.println(n);
///Integer.valueOf()返回一个“integer对象”和Integer.parseInt()返回一个“int值”的区别在于,返回值不同
///基本常识,其他的非10进制的数的保存,基本都是以字符串的形式
///例子:7进制到8进制的转换
String q = "6523" ; ///7进制的字符串
String b = Integer.toString(Integer.valueOf(q,7),8) ;///这样7进制就变成8进制了
}
}运算符
Integer.MAX_VALUE = 0x7fffffff 最大值 (2^31-1)
Integer.MIN_VALUE = 0x80000000 最小值 (-2^31)
++a:变量a自己加1,将加1后的结果赋值给b;
byte b=2;
b+=1;//s = (short)(s + 1)
System.out.println(b);b3 = 1 + 2 , 1 和 2 是常量,为固定不变的数据,在编译的时候(编译器javac),已经确定了 1+2 的结果并没有超过byte类型的取值范围,可以赋值给变量 b3 ,因此 b3=1 + 2 是正确的。但b3=1+200报错。b4=byte1+byte2报错
流程控制
for(初始化表达式①; 布尔表达式②; 步进表达式④){
循环体③
}
执行顺序:①②③④ >②③④>②③④…②不满足为止。for(初始化表达式①; 循环条件②; 步进表达式⑦) {
for(初始化表达式③; 循环条件④; 步进表达式⑥) {
执行语句⑤;
}
}
执行顺序:①②③④⑤⑥ >④⑤⑥>⑦②③④⑤⑥>④⑤⑥IDEA
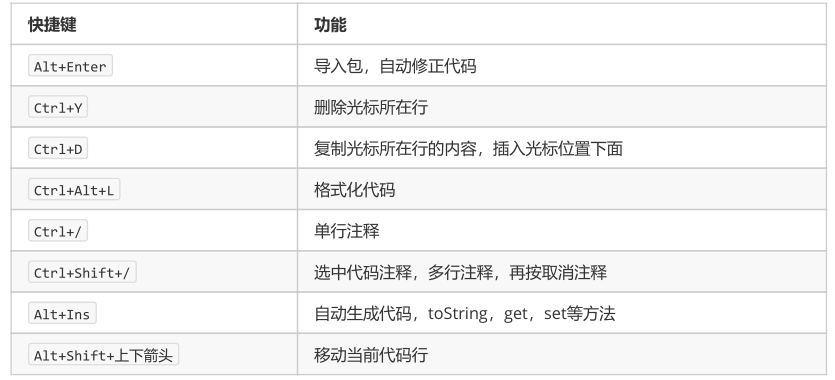
IDEA设置jdk为1.8
Project Structure->Project里Project sdk以及project language level
Project Structure->Modules里Sources里的Language level
打开【File】—【Settings】,找到【Java Compiler】将下边的5或者1.5修改为8或者1.8
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>Idea控制台中文乱码解决:-Dfile.encoding=gb2312
方法
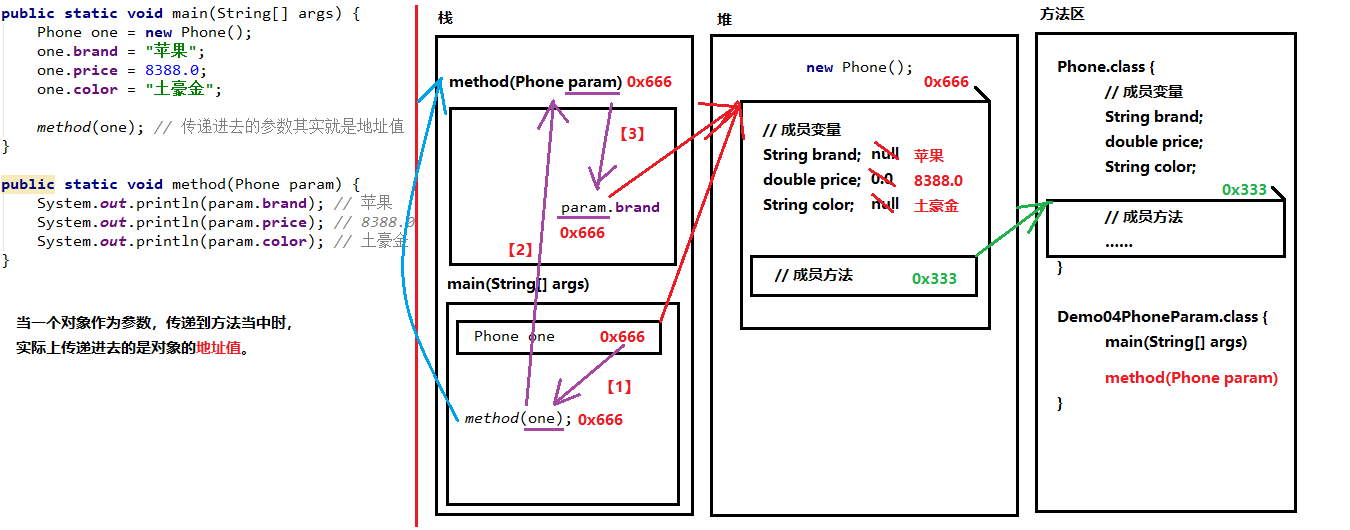
方法的参数为基本类型时,传递的是数据值. 方法的参数为引用类型时,传递的是地址值.
public static void main(String[] args) {
int a = 1;
int b = 2;
change(a, b);
System.out.println(a);//1
System.out.println(b);//2
}
public static void change(int a, int b) {
a = a + b;
b = b + a;
}public static void main(String[] args) {
int[] arr = {1,3,5};
change(arr);
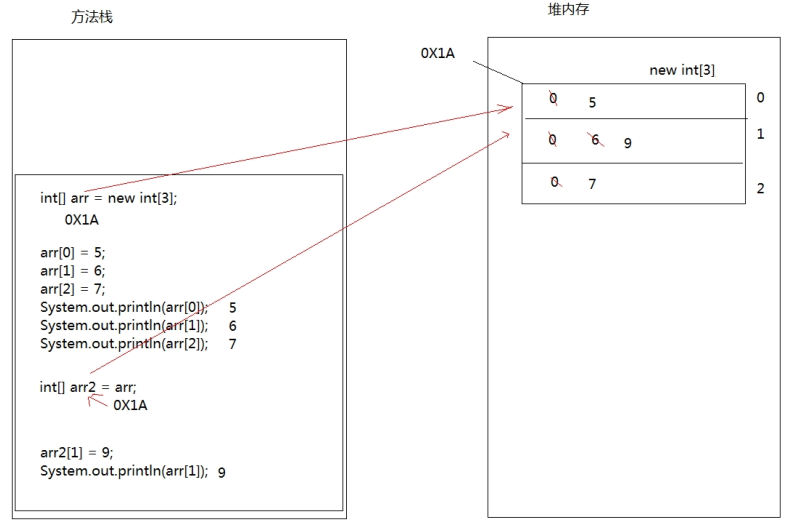
System.out.println(arr[0]);//{200,3,5}
}
public static void change(int[] arr) {
arr[0] = 200;
}递归
递归一定要有条件限定,保证递归能够停止下来,次数不要太多,否则会发生栈内存溢出。
01_递归导致栈内存溢出的原理

02_递归求和的原理
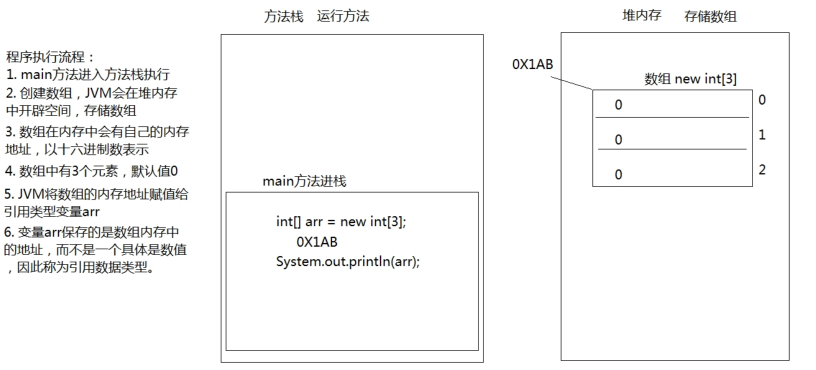
数组

面向对象
继承后构造子类顺序:先初始化父类,再初始化子类,先初始化属性在调用构造函数;static在涉及到继承的时候,会先初始化父类的static变量,然后是子类的。
封装

对象内存图
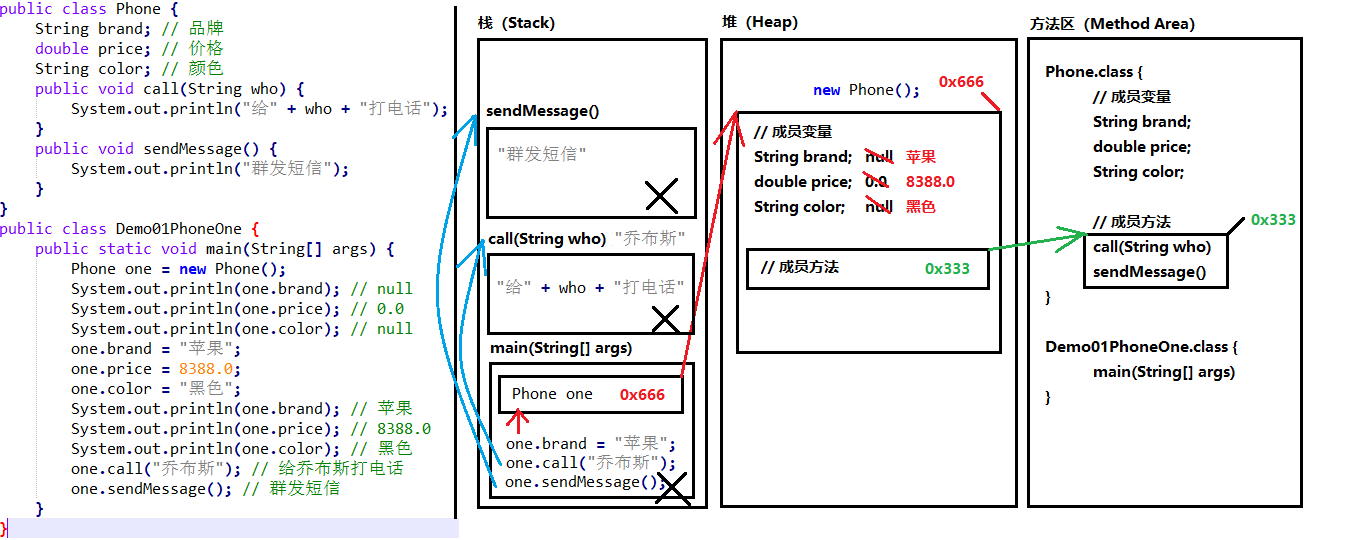
01-只有一个对象的内存图
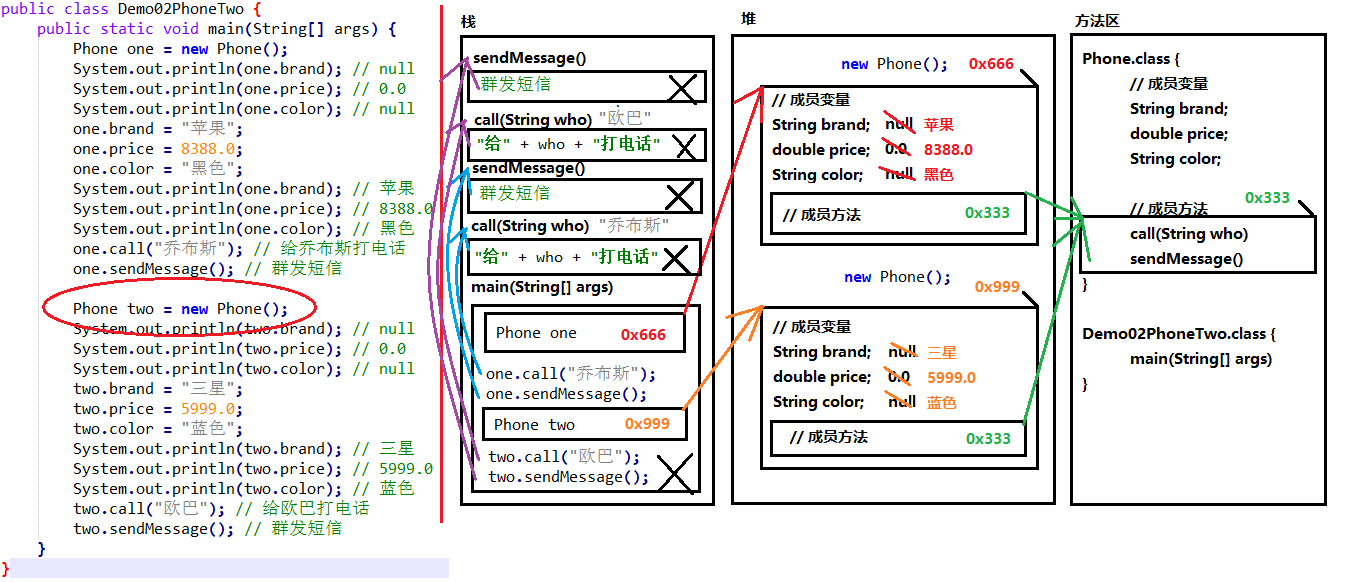
02-两个对象使用同一个方法的内存图
03-两个引用指向同一个对象的内存图

04-使用对象类型作为方法的参数
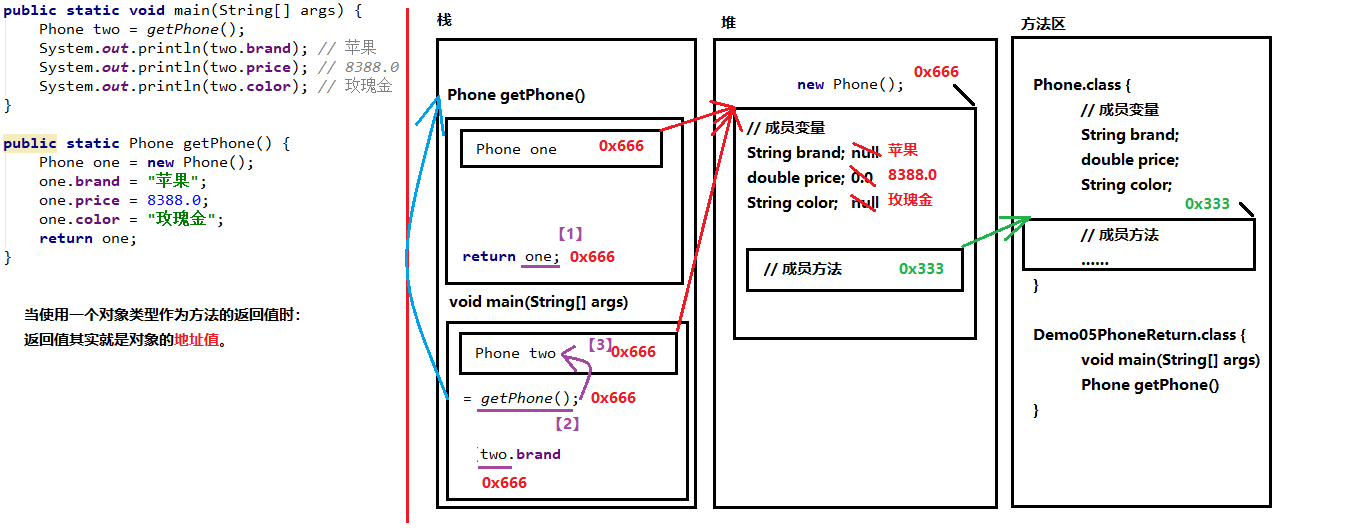
05-使用对象类型作为方法的返回值
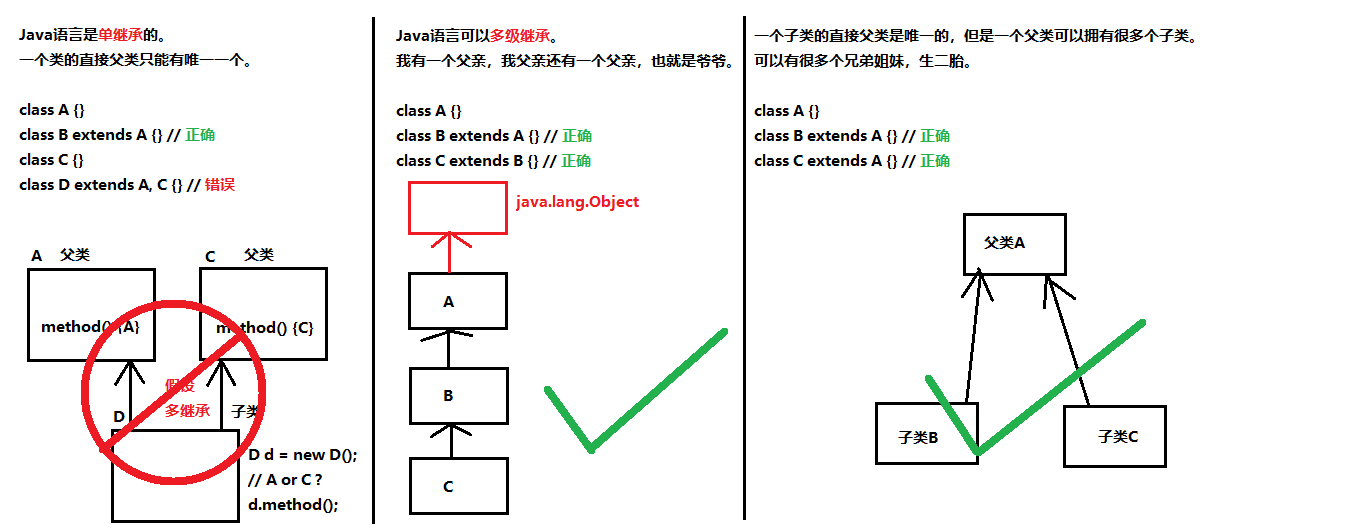
继承
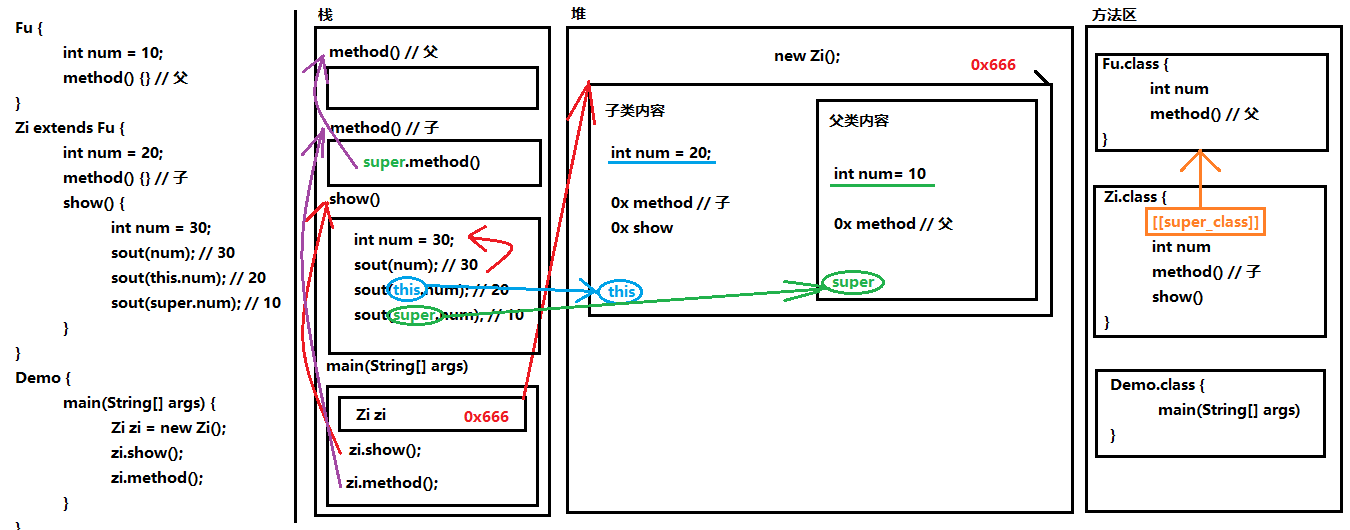
类似于this,子父类中出现了同名的成员变量时,在子类中需要访问父类中非私有成员变量时,需要使用 super 关键字,修饰父类成员变量
在每次创建子类对象时,先初始化父类空间,再创建其子类对象本身。
03-super与this的内存图
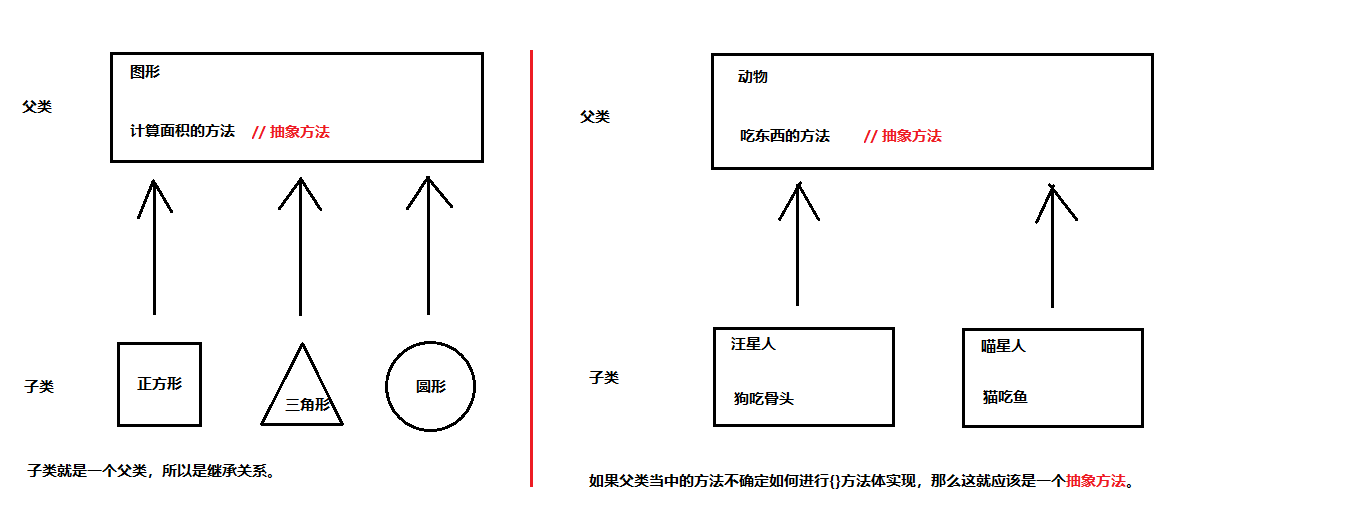
抽象
接口
接口的定义,与定义类方式相似,但是使用 interface 关键字。它也会被编译成.class文件,但一定要明确它并不是类,而是另外一种引用数据类型。(引用数据类型:数组,类,接口)
当一个类,既继承一个父类,又实现若干个接口时,父类中的成员方法与接口中的默认方法重名,子类就近选择执行父类的成员方法。如果父接口中的默认方法有重名的,那么子接口需要重写一次。代码如下:
interface A {
public default void methodA(){
System.out.println("AAAAAAAAAAAA");
}
}
class D {
public void methodA(){
System.out.println("DDDDDDDDDDDD");
}
}
class C extends D implements A {
// 未重写methodA方法
}
public class Test {
public static void main(String[] args) {
C c = new C();
c.methodA();
}
}
输出结果:
DDDDDDDDDDDD
// **如果父接口中的默认方法有重名的,那么子接口需要重写一次。**
interface A {
public default void method(){
System.out.println("AAAAAAAAAAAAAAAAAAA");
}
}
interface B {
public default void method(){
System.out.println("BBBBBBBBBBBBBBBBBBB");
}
}
interface D extends A,B{
@Override
public default void method() {
System.out.println("DDDDDDDDDDDDDD");
}
}接口作为成员变量时,对它进行赋值的操作,实际上,是赋给它该接口的一个子类对象。
接口作为参数时,传递它的子类对象。 接口作为返回值类型时,返回它的子类对象。
多态
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,执行的是子类重写 后方法。
04-使用多态的好处
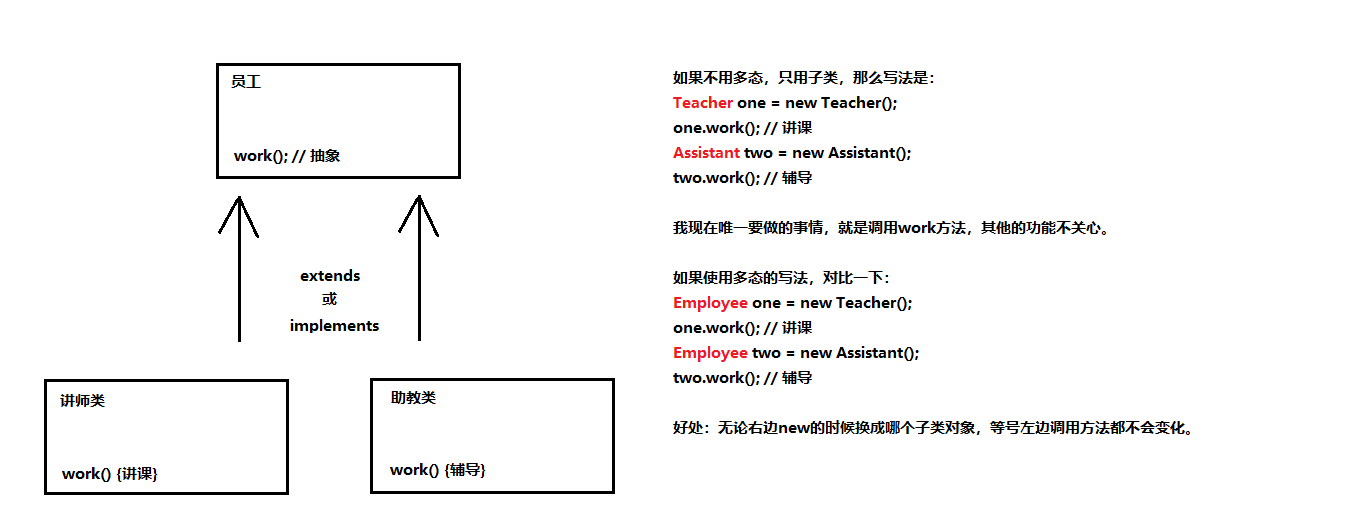
05-对象的上下转型
变量名 instanceof 数据类型
如果变量属于该数据类型,返回true。
如果变量不属于该数据类型,返回false。
final关键字
final : 不可改变。可以用于修饰类、方法和变量。 类:被修饰的类,不能被继承。 方法:被修饰的方法,不能被重写。 变量:被修饰的变量,不能被重新赋值。引用类型的局部变量,被final修饰后,只能指向一个对象,地址不能再更改。但是不影响对象内部的成员变量值的修改
内部类
内部类可以直接访问外部类的成员,包括私有成员。 外部类要访问内部类的成员,必须要建立内部类的对象。
外部类名.内部类名 对象名 = new 外部类型().new 内部类型();内部类仍然是一个独立的类,在编译之后会内部类会被编译成独立的 .class文件,但是前面冠以外部类的类名 和$符号 。比如,Person$Heart.class
类加载器初始化
类加载(先父后子,静态代码块(执行一次)---->非静态代码块(执行多次)---->成员变量---->构造函数)
static在涉及到继承的时候,会先初始化父类的static变量,然后是子类的,依次类推。
static块可以出现类中的任何地方(只要不是方法内部,记住,任何方法内部都不行),并且执行是按照static块的顺序执行的。
静态代码块,当第一次用到本类时,代码块执行唯一的一次,第二次使用的时候就不在执行了
非静态代码块,每次调用类都执行
静态内容总是优先于非静态,所以静态代码块比构造方法优先执行
常量在编译阶段会存入调用类的常量池,本质上并没有直接引用到定义常量的类,不会触发定义常量的类的初始化
对类的主动使用:
1. 创建类的实例
2. 访问某个类或者接口的静态变量,或者对该静态变量赋值。
3. 调用类的静态方法。
4. 反射(Class.forName)
5. 初始化类的子类
6. java虚拟机启动时被标明为启动类的类
public class Test {
Person person = new Person("Test");
static{
System.out.println("test static");
}
public Test() {
System.out.println("test constructor");
}
public static void main(String[] args) {
new MyClass();
}
}
class Person{
static{
System.out.println("person static");
}
public Person(String str) {
System.out.println("person "+str);
}
}
class MyClass extends Test {
Person person = new Person("MyClass");
static{
System.out.println("myclass static");
}
public MyClass() {
System.out.println("myclass constructor");
}
}
输出结果为:
test static
myclass static
person static
person Test
test constructor
person MyClass
myclass constructor
为什么输出结果是这样的?我们来分析下这段代码的执行过程:
找到main方法入口,main方法是程序入口,但在执行main方法之前,要先加载Test类
加载Test类的时候,发现Test类有static块,而是先执行static块,输出test static结果
然后执行new MyClass(),执行此代码之前,先加载MyClass类,发现MyClass类继承Test类,而是要先加载Test类,Test类之前已加载
加载MyClass类,发现MyClass类有static块,而是先执行static块,输出myclass static结果
然后调用MyClass类的构造器生成对象,在生成对象前,需要先初始化父类Test的成员变量,而是执行Person person = new Person("Test")代码,发现Person类没有加载
加载Person类,发现Person类有static块,而是先执行static块,输出person static结果
接着执行Person构造器,输出person Test结果
然后调用父类Test构造器,输出test constructor结果,这样就完成了父类Test的初始化了
再初始化MyClass类成员变量,执行Person构造器,输出person MyClass结果
最后调用MyClass类构造器,输出myclass constructor结果,这样就完成了MyClass类的初始化了//问以下程序运行后输出什么
//答案: 0, p, 5
//解析见以下注释,按序号顺序查看
class A {
A() {this.init(); }
public void init() {// 3.该函数被覆盖
System.out.println("q");
}
}
class B extends A {
public int i = 4;
B(int i) { // 2.A构造函数先于B构造函数运行
System.out.println("p");// 6.输出p
this.i = i; // 7. i被赋值为5
}
public void init() {// 4.实际执行的函数
// 5.此时 i 尚未初始化,为0
System.out.println(i);
}
public static void main(String[] args) {
// 1.程序开始运行
System.out.println(new B(5).i);
// 8.输出
}
}Java常见坑
中间缓存变量机制
int j=0;
for(int i=0;i<100;i++)
{
j=j++;
}
System.out.println(j);//j=0
/*
原因
temp=j;
j=j+1;
j=temp;
*/else问题
if(true)
{
A
}
else if(true)
{
B
}
B不会执行,因为有else应注意的问题
package javaSE;
import java.util.Random;
//一个单例模式
public class Singleton {
private Singleton() {}
static private Singleton s=new Singleton();
public static Singleton getSingleton ()
{
return s;
}
}
abstract class reStudy{
//可变参数列表
public void canParameterChange(int... n)
{
for(int i:n)
{
System.out.println(i);
}
}
//方法参数传递的是引用
//static 隶属于类,只会生成一份,其他都是引用
//java随机数,以当前时间毫秒数做种子
public void testRandom()
{
Random rand=new Random();
int j=rand.nextInt(100)+1;//1~100
System.out.println(rand.nextFloat());//0~1
System.out.println(rand.nextBoolean());
}
//==比较的是地址是否一样,equals比较的是值是否一样,需要在新类中重写equals方法
//如果定义了构造器,则默认构造器无效
//垃圾清理,自适应的,分代的,停止复制,标记清扫的垃圾回收器
//初始化顺序,先基类后子类,是static在有类就初始化了,之后不会再初始化,其他非static块每次构造都运行,先static后变量后构造器
//Arrays.toString(),返回数组的可打印版本,"12323".toCharArray(),返回字符数组
//默认同包,private自己,protected自己和继承类,public都能访问
//可以有多个main()方法,运行那个就是哪个
//finally 总会被执行
//@override可以确保被重载而不是覆写
//is-a用继承 has-a用组合 慎用继承
//常量的定义,final数据表示不可改变,对引用,表示引用的地址不可改变,值可能改变,final做参数表示无法更改,final方法和类也表示无法继承
//private无法继承,如果子类有一样的函数,看做新的函数
public static final int VALUEONE=6;
//静态方法没有多态行
//向上转型(向基类转型)不会出现错误,乡向下转型,会出现异常
//抽象方法,如果有抽象方法,则类一定为抽象类
public abstract void exampleAbstact(int i);
}常用API
String
public boolean equals (Object anObject) :将此字符串与指定对象进行比较。
public boolean equalsIgnoreCase (String anotherString) :将此字符串与指定对象进行比较,忽略大小写。
public int length () :返回此字符串的长度。
public String concat (String str) :将指定的字符串连接到该字符串的末尾。
public char charAt (int index) :返回指定索引处的 char值。
public int indexOf (String str) :返回指定子字符串第一次出现在该字符串内的索引。如果没有检索到字符串s,该方法返回-1
public String substring (int beginIndex) :返回一个子字符串,从beginIndex开始截取字符串到字符串结尾。
public String substring (int beginIndex, int endIndex) :返回一个子字符串,从beginIndex到endIndex截取字符串。含beginIndex,不含endIndex
public char[] toCharArray () :将此字符串转换为新的字符数组。
public byte[] getBytes () :使用平台的默认字符集将该 String编码转换为新的字节数组。
public String replace (CharSequence target, CharSequence replacement) :将与target匹配的字符串使用replacement字符串替换。
public String[] split(String regex) :将此字符串按照给定的regex(规则)拆分为字符串数组。“,|=”表示分割符分别为“,”和“=”
trim()方法返回字符串的副本,忽略前导空格和尾部空格。
startsWith()方法与endsWith()方法分别用于判断字符串是否以指定的内容开始或结束。这两个方法的返回值都为boolean类型。
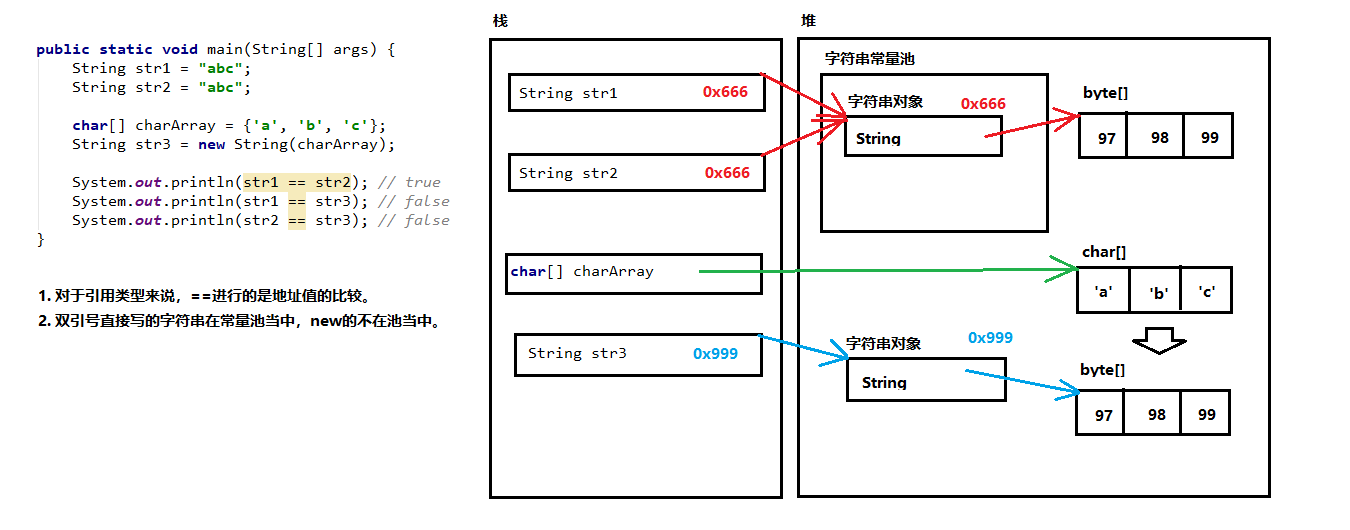
toLowerCase()方法可将字符串中的所有字符从大写字母改写为小写字母,而tuUpperCase()方法可将字符串中的小写字母改写为大写字母。1 字符串不变:字符串的值在创建后不能被更改。
String s1 = "abc";
s1 += "d";
System.out.println(s1); // "abcd"
// 内存中有"abc","abcd"两个对象,s1从指向"abc",改变指向,指向了"abcd"。2 因为String对象是不可变的,所以它们可以被共享。
String s1 = "abc";
String s2 = "abc";
// 内存中只有一个"abc"对象被创建,同时被s1和s2共享。3 "abc" 等效于 char[] data={ 'a' , 'b' , 'c' } 。
例如:
String str = "abc";
相当于:
char data[] = {'a', 'b', 'c'};
String str = new String(data);
// String底层是靠字符数组实现的。4 String对象做参数,s先拷贝一份,再把拷贝的地址作为参数,s一直没有动过,String只读,不可改变。
String q="abc";
String qq=upcase(q);
print(q);//abc01-字符串的常量池
Static
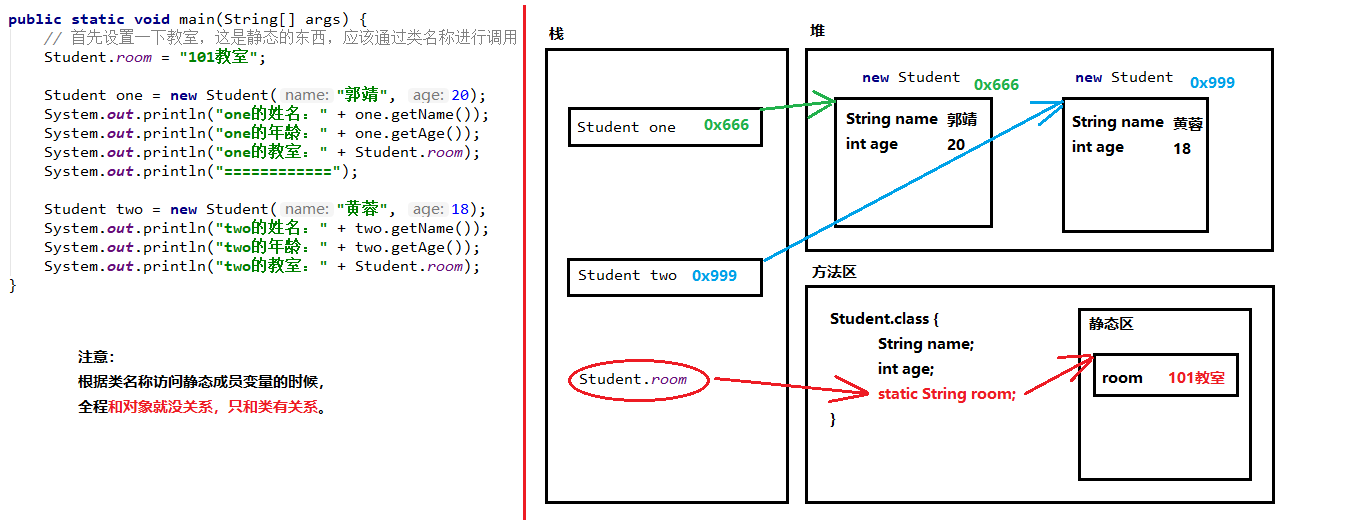
静态方法只能访问静态成员,不能直接访问普通成员变量或成员方法,不能使用 this关键字。
02-静态static关键字概述

03-静态的内存图
Arrays类
java.util.Arrays 此类包含用来操作数组的各种方法,比如排序和搜索等。其所有方法均为静态方法,调用起来 非常简单。
public static String toString(int[] a) :返回指定数组内容的字符串表示形式。
public static void sort(int[] a) :对指定的 int 型数组按数字升序进行排序。Collections类
java.utils.Collections是集合工具类,用来对集合进行操作。部分方法如下:public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素。public static void shuffle(List<?> list) 打乱顺序:打乱集合顺序。public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序。
在JAVA中提供了两种比较实现的方式,一种是比较死板的采用java.lang.Comparable接口去实现,一种是灵活的当我需要做排序的时候在去选择的java.util.Comparator接口完成。
public int compare(String o1, String o2):比较其两个参数的顺序。大于0,并按照o1在后面,来看升降顺序
public int compareTo(Student o) {//o是第一个参数(Student this,Student o)
return this.age‐o.age;//升序
}Comparable和Comparator两个接口的区别
Comparable:强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的compareTo方法被称为它的自然比较方法。只能在类中实现compareTo()一次,不能经常修改类的代码实现自己想要的排序。实现此接口的对象列表(和数组)可以通过Collections.sort(和Arrays.sort)进行自动排序,对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
Comparator强行对某个对象进行整体排序。可以将Comparator 传递给sort方法(如Collections.sort或 Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用Comparator来控制某些数据结构(如有序set或有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
Math类
java.lang.Math 类包含用于执行基本数学运算的方法,如初等指数、对数、平方根和三角函数。类似这样的工具 类,其所有方法均为静态方法,并且不会创建对象,调用起来非常简单。
public static double abs(double a) :返回 double 值的绝对值。
public static double ceil(double a) :返回大于等于参数的最小的整数。
public static double floor(double a) :返回小于等于参数最大的整数。
public static long round(double a) :返回最接近参数的 long。(相当于四舍五入方法)Object类
public String toString():返回该对象的字符串表示。对象的类型+@+内存地址值。public boolean equals(Object obj):指示其他某个对象是否与此对象“相等”。
Date类
// 创建日期对象,把当前的时间
System.out.println(new Date()); // Tue Jan 16 14:37:35 CST 2018
// 创建日期对象,把当前的毫秒值转成日期对象
System.out.println(new Date(0L)); // Thu Jan 01 08:00:00 CST 1970
public long getTime() 把日期对象转换成对应的时间毫秒值。DateFormat类
java.text.DateFormat 是日期/时间格式化子类的抽象类,我们通过这个类可以帮我们完成日期和文本之间的转换,也就是可以在Date对象与String对象之间进行来回转换。由于DateFormat为抽象类,不能直接使用,所以需要常用的子类java.text.SimpleDateFormat。这个类需要一个模式(格式)来指定格式化或解析的标准。构造方法为:
public SimpleDateFormat(String pattern):用给定的模式和默认语言环境的日期格式符号构造SimpleDateFormat。参数pattern是一个字符串,代表日期时间的自定义格式。"yyyy-MM-dd HH:mm:ss"格式化:
public String format(Date date):将Date对象格式化为字符串。解析:
public Date parse(String source):将字符串解析为Date对象。
Date date = new Date();
// 创建日期格式化对象,在获取格式化对象时可以指定风格
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = df.format(date);
System.out.println(str); // 2008年1月23日
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = "2018年12月11日";
Date date = df.parse(str);
System.out.println(date); // Tue Dec 11 00:00:00 CST 2018Calendar类
Calendar为抽象类,由于语言敏感性,Calendar类在创建对象时并非直接创建,而是通过静态方法创建,返回子类对象,如下:
public static Calendar getInstance():使用默认时区和语言环境获得一个日历public int get(int field):返回给定日历字段的值。public void set(int field, int value):将给定的日历字段设置为给定值。public abstract void add(int field, int amount):根据日历的规则,为给定的日历字段添加或减去指定的时间量。public Date getTime():返回一个表示此Calendar时间值(从历元到现在的毫秒偏移量)的Date对象。
| 字段值 | 含义 |
|---|---|
| YEAR | 年 |
| MONTH | 月(从0开始,可以+1使用) |
| DAY_OF_MONTH | 月中的天(几号) |
| HOUR | 时(12小时制) |
| HOUR_OF_DAY | 时(24小时制) |
| MINUTE | 分 |
| SECOND | 秒 |
| DAY_OF_WEEK | 周中的天(周几,周日为1,可以-1使用) |
Calendar cal = Calendar.getInstance();
System.out.println(cal.get(Calendar.YEAR));
cal.add(Calendar.YEAR,-3);
Date d=cal.getTime();
System.out.println(d);注意:
西方星期的开始为周日,中国为周一。
在Calendar类中,月份的表示是以0-11代表1-12月。
日期是有大小关系的,时间靠后,时间越大。System类
java.lang.System类中提供了大量的静态方法,可以获取与系统相关的信息或系统级操作,在System类的API文档中,常用的方法有:
public static long currentTimeMillis():返回以毫秒为单位的当前时间。public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length):将数组中指定的数据拷贝到另一个数组中。
int[] src = new int[]{1,2,3,4,5};
int[] dest = new int[]{6,7,8,9,10};
System.arraycopy( src, 0, dest, 0, 3);
/*代码运行后:两个数组中的元素发生了变化
src数组元素[1,2,3,4,5]
dest数组元素[1,2,3,9,10]*/StringBuilder类

public StringBuilder():构造一个空的StringBuilder容器。public StringBuilder(String str):构造一个StringBuilder容器,并将字符串添加进去。public StringBuilder append(...):添加任意类型数据的字符串形式,并返回当前对象自身。public String toString():将当前StringBuilder对象转换为String对象。
数据结构
红黑树
普通的二叉查找树在极端情况下可退化成链表,红黑树是一种自平衡的二叉查找树,可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。最长路径不会超过最短路径的两倍。

插入
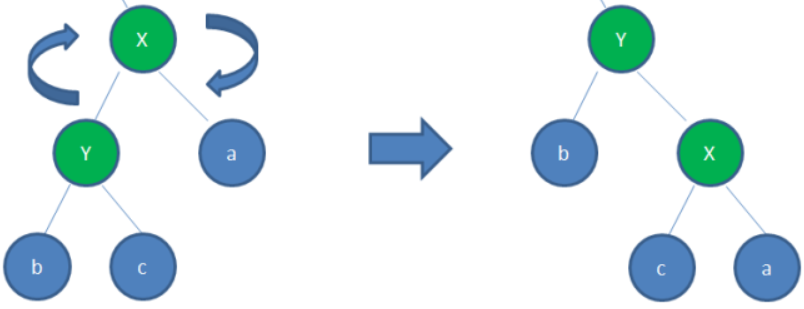
左旋:逆时针旋转红黑树的两个节点,使得父节点被自己的右孩子取代,而自己成为自己的左孩子
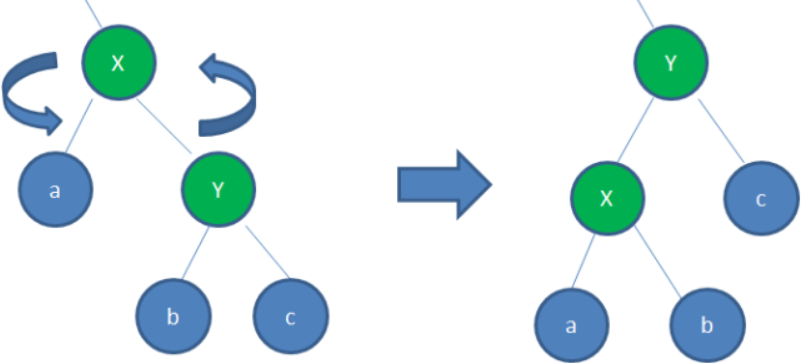
右旋:顺时针旋转红黑树的两个节点,使得父节点被自己的左孩子取代,而自己成为自己的右孩子。
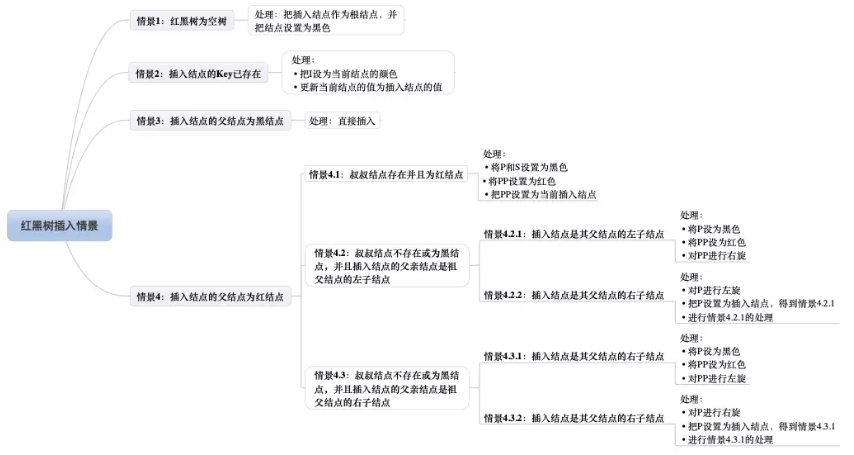
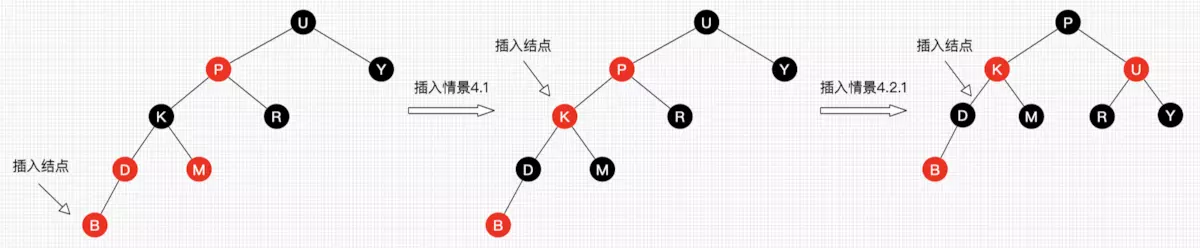
4.1

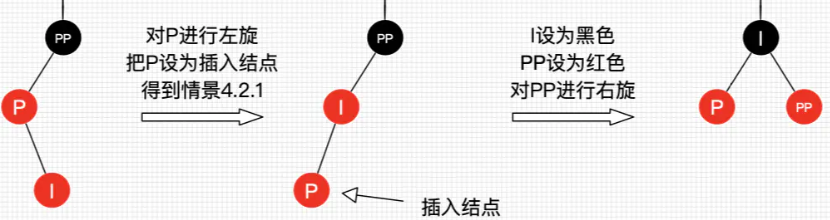
4.2.1

4.2.2
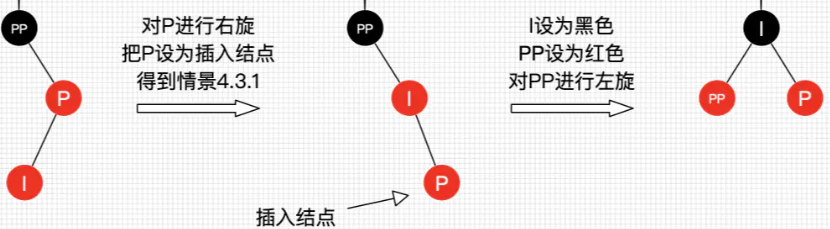
4.3.1

4.3.2
删除
- 情景1:若删除结点无子结点,直接删除
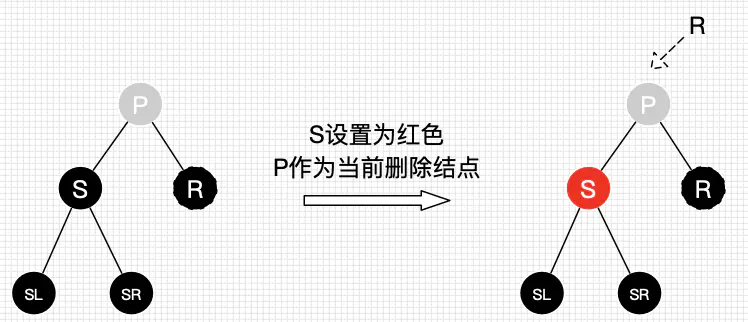
- 情景2:若删除结点只有一个子结点,用子结点替换删除结点
- 情景3:若删除结点有两个子结点,用后继结点(大于删除结点的最小结点)替换删除结点

上面所说的3种二叉树的删除情景可以相互转换并且最终都是转换为情景1!
- 情景2:删除结点用其唯一的子结点替换,子结点替换为删除结点后,可以认为删除的是子结点,若子结点又有两个子结点,那么相当于转换为情景3,一直自顶向下转换,总是能转换为情景1。(对于红黑树来说,根据性质5.1,只存在一个子结点的结点肯定在树末了)
- 情景3:删除结点用后继结点(肯定不存在左结点),如果后继结点有右子结点,那么相当于转换为情景2,否则转为为情景1。
综上所述,删除操作删除的结点可以看作删除替代结点,而替代结点最后总是在树末。有了这结论,我们讨论的删除红黑树的情景就少了很多,因为我们只考虑删除树末结点的情景了。
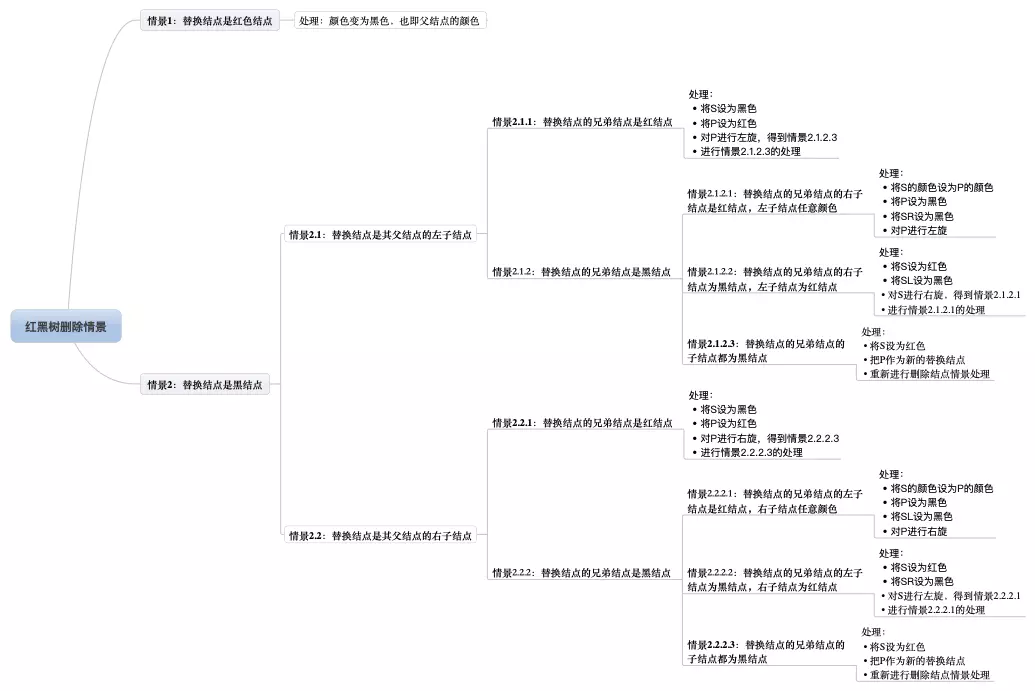
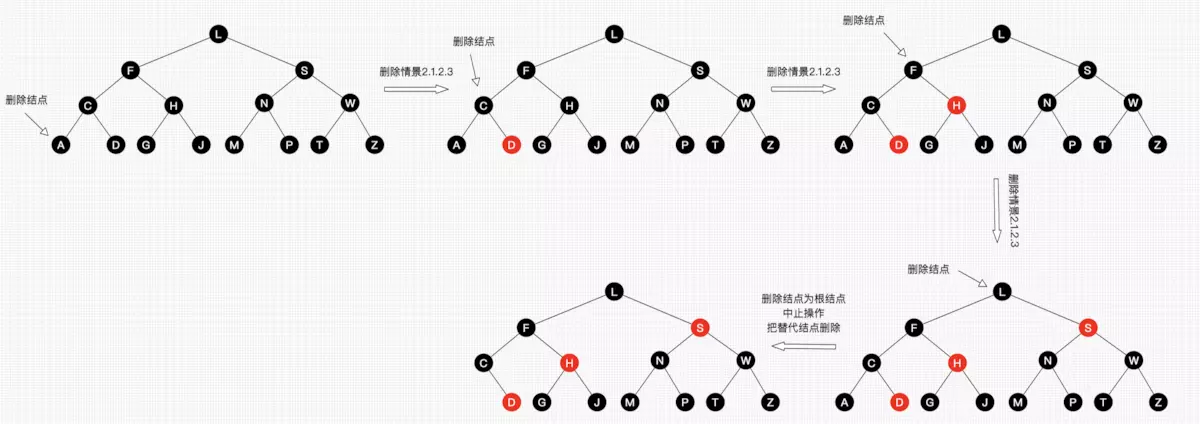
2.1.1

2.1.2.1

2.1.2.2
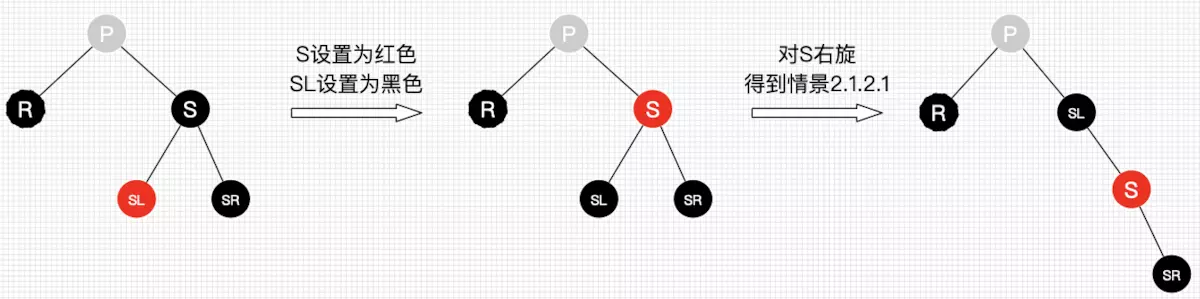
2.1.2.3

2.2.1

2.2.2.1

2.2.2.2
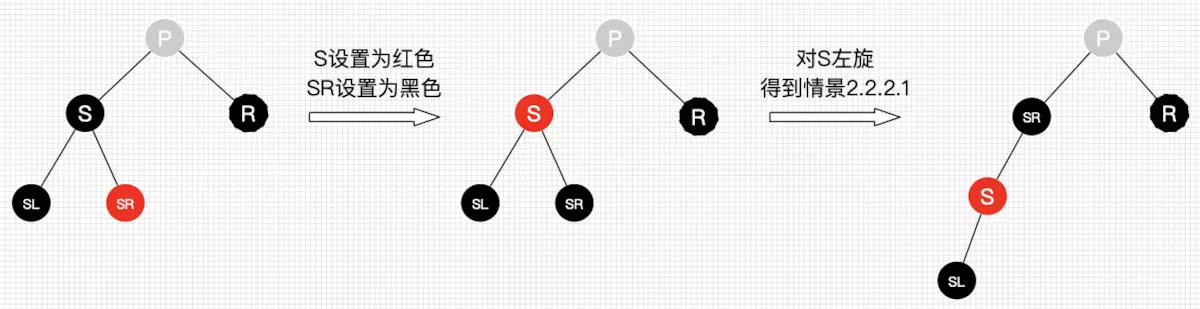
2.2.2.3
例题:
集合
简介:
arraylist数组实现,随机访问快;linklist链表实现,插入删除快
hashset使用hash散列,获取元素很快,Treeset使用红黑树,按照比较结果升序保存,linkedhashset用来链表按照被添加的顺序保存,用hash保留查找速度(set中元素不可重复)
hashmap没有顺序,查找快,Treemap按照比较结果升序保存key ,LinkedHashMap按照插入结果保存Key,保留查找速度
Vector ,Hashtable,Stack弃用
点框表示接口,实框表示具体类,空心箭头表示特定类实现接口,实心箭头表示某类可以生成箭头所指类的对象
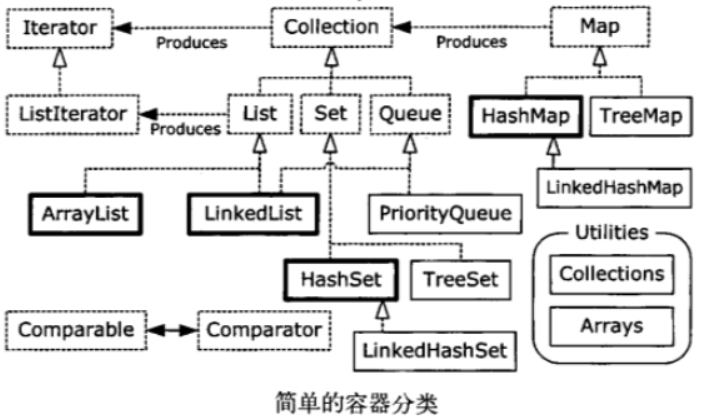
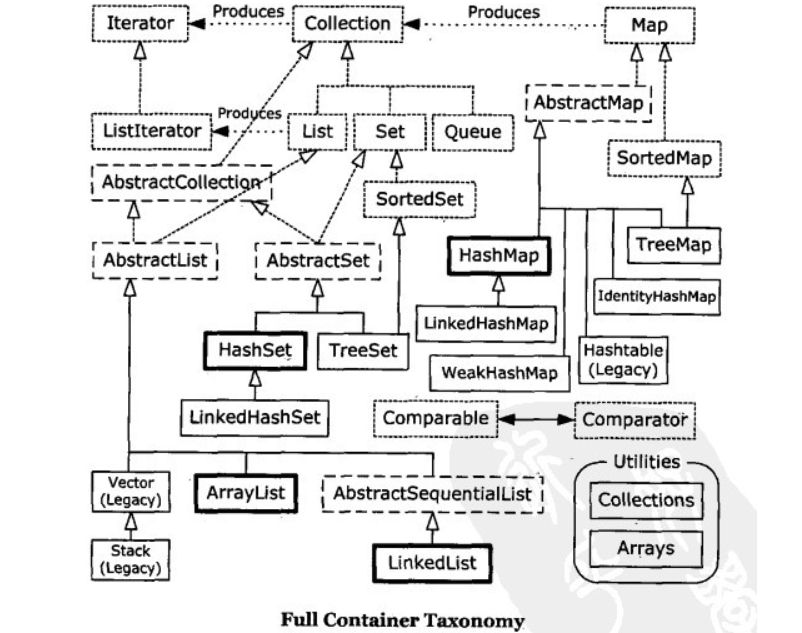
Collection
集合本身是一个工具,它存放在java.util包中。在Collection接口定义着单列集合框架中最最共性的内容。
public boolean add(E e): 把给定的对象添加到当前集合中 。public void clear():清空集合中所有的元素。public boolean remove(E e): 把给定的对象在当前集合中删除。public boolean contains(E e): 判断当前集合中是否包含给定的对象。public boolean isEmpty(): 判断当前集合是否为空。public int size(): 返回集合中元素的个数。public Object[] toArray(): 把集合中的元素,存储到数组中。
Iterator迭代器
迭代器统一了对容器的访问方式iterater() next() hasNext() remove(),listIterator 可双向移动
02_迭代器的实现原理
增强for
增强for循环(也称foreach循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
for(元素的数据类型 变量 : Collection集合or数组){
//写操作代码
}泛型
泛型:可以在类或方法中预支地使用未知的类型。当没有指定泛型时,默认类型为Object类型。
- 将运行时期的ClassCastException,转移到了编译时期变成了编译失败。
- 避免了类型强转的麻烦。
泛型的上限:
- 格式:
类型名称 <? extends 类 > 对象名称 - 意义:
只能接收该类型及其子类
泛型的下限:
- 格式:
类型名称 <? super 类 > 对象名称 - 意义:
只能接收该类型及其父类型
List
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法
常用:contains() , remove() , indexOf() , subList() , cantainsAll() ,Collections.sort() , Collections.shuffle()//打乱,retainAll()
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。public E get(int index):返回集合中指定位置的元素。public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
ArrayList
public boolean add(E e) :将指定的元素添加到此集合的尾部。
public E remove(int index) :移除此集合中指定位置上的元素。返回被删除的元素。
public E get(int index) :返回此集合中指定位置上的元素。返回获取的元素。
public int size() :返回此集合中的元素数。遍历集合时,可以控制索引范围,防止越界。LinkedList
LinkedList是List的子类,List中的方法LinkedList都是可以使用,LinkedList添加了可以作为栈,队列和双端队列的方法
getfirst(),element()返回第一个元素,空时抛出nosuchElementException,peek()空时返回null;
removeFirst()与remove()移除返回列表头,若空,抛出NoSuchElementsException,poll()空时返回null。
addFirst(),add(),addLast(),removelast()
Queue
offer()插入队尾,peek()和element()返回队头,poll()和remove()移除并返回队头
可变参数
在JDK1.5之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化成如下格式:
修饰符 返回值类型 方法名(参数类型... 形参名){ }同样是代表数组,但是在调用这个带有可变参数的方法时,不用创建数组(这就是简单之处),直接将数组中的元素作为实际参数进行传递,其实编译成的class文件,将这些元素先封装到一个数组中,在进行传递。这些动作都在编译.class文件时,自动完成了。
HashSet和LinkedHashSet
在HashSet下面有一个子类java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。能保证set有序。
HashSet 是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于: hashCode 与 equals 方法。
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
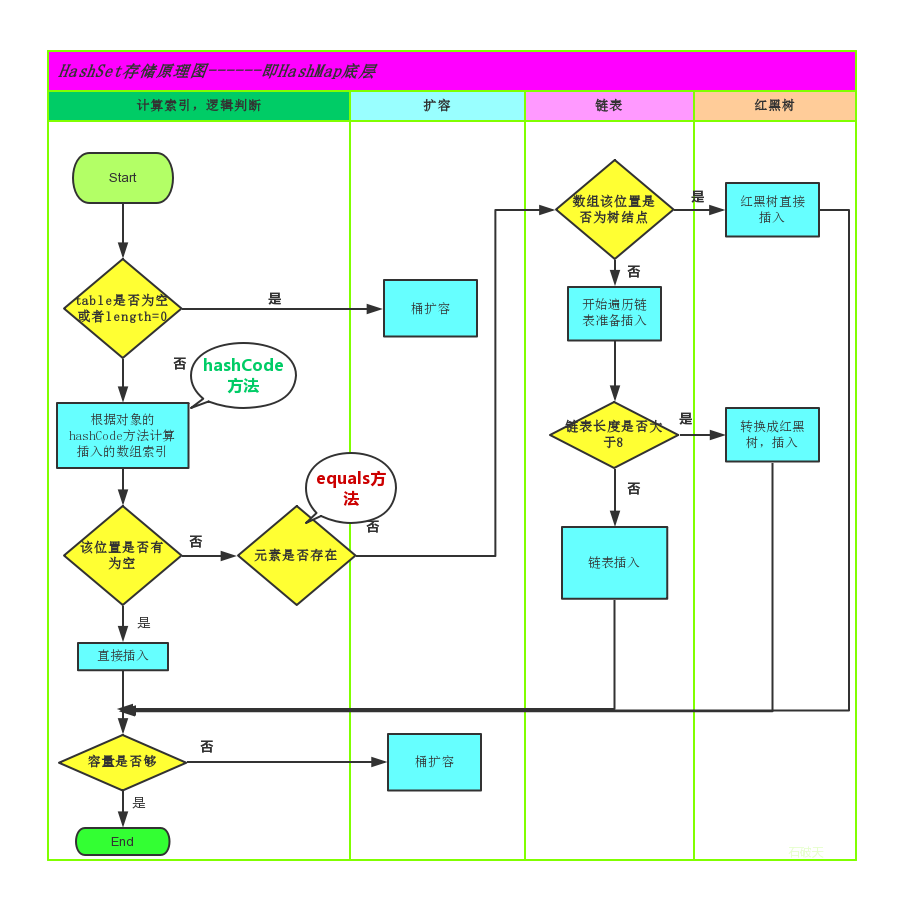
Map
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。Map接口中的集合都有两个泛型变量<K,V>,在使用时,要为两个泛型变量赋予数据类型。
- HashMap<K,V>:存储数据采用的哈希表结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
- LinkedHashMap<K,V>:HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
Map接口中定义了很多方法,常用的如下:
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。- void putAll(Map m):将m中的所有key-value对存放到当前map中
public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。public V get(Object key)根据指定的键,在Map集合中获取对应的值。- getOrDefault(Object key, V defaultValue)方法的作用是:有这个key时,使用key值;没有就默认值defaultValue。
boolean containsKey(Object key)判断集合中是否包含指定的键。- boolean containsValue(Object value):是否包含指定的value
public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。- Collection values():返回所有value构成的Collection集合
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
01_Map集合遍历键找值方式

02_Map集合遍历键值对方式
Map集合不能直接使用迭代器或者foreach进行遍历。但是转成Set之后就可以使用了。
HashMap
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
/**
* HashMap的默认初始容量大小 16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* HashMap的最大容量 2的30次方
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 负载因子,代表了table的填充度有多少,默认是0.75。当数组中的数据大于总长度的0.75倍时
* HashMap会自动扩容,默认扩容到原长度的两倍。为什么是两倍,而不是1.5倍,或是3倍。这个
* 2倍很睿智,后面会说到
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 默认阈值,当桶(bucket)上的链表长度大于这个值时会转成红黑树,put方法的代码里有用到
* 在jdk1.7中链表就是普通的单向链表,很多数据出现哈希碰撞导致这些数据集中在某一个哈希桶上,
* 因而导致链表很长,会出现效率问题,jdk1.8对此做了优化,默认当链表长度大于8时转化为红黑树
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 和上一个的阈值相对的阈值,当桶(bucket)上的链表长度小于这个值时红黑树退化成链表
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 用于快速失败,由于HashMap非线程安全,在对HashMap进行迭代时,如果期间其他线程的参与导致HashMap * 的结构发生变化了(比如put,remove等操作),需要抛出异常ConcurrentModificationException
*/
transient int modCount;
}计算hash
在使用HashMap时,我们希望这个HashMap里面的元素位置尽量的分布均匀些,最好使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表,这样就大大优化了查询的效率。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}计算索引位置:
最普遍的想法是把hash值对数组长度进行取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在HashMap中是这样做的:调用
indexFor(int h, int length)方法来计算该对象应该保存在table数组的哪个索引处。
static int indexFor(int h, int length) {
return h & (length-1);
}
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);这个方法很巧妙,它通过h & (table.length -1)来得到该对象的保存位置,而HashMap底层数组的length总是 2 的n次方(length-1为2^n-1,全一),这是HashMap在速度上的优化。
put
public V put(K key, V value) {
//调用putVal()方法完成
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断table是否初始化,否则初始化操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//计算存储的索引位置,如果没有元素,直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//节点若已经存在,执行赋值操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断链表是否是红黑树
else if (p instanceof TreeNode)
//红黑树对象操作
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//为链表,
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度8,将链表转化为红黑树存储
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key存在,直接覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//记录修改次数
++modCount;
//判断是否需要扩容
if (++size > threshold)
resize();
//空操作
afterNodeInsertion(evict);
return null;
}集合STL汇总
package site.syzhou.code.javaDataStructure;
import java.util.*;
public class STLUse {
public static void arrayList() {
System.out.println("================arraylist================");
ArrayList<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 5; i++) {
list.add(i);
}
System.out.println(list.contains(new Integer(2)));
// 遍历
for (Integer i : list) {
System.out.print(i + " ");
}
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + " ");
}
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + " ");
}
// ACID
list.add(0, 9);
System.out.println(list.indexOf(3));
System.out.println(list.lastIndexOf(3));
list.remove(2);
list.remove(new Integer(3));
System.out.println(list.toString());
list.set(0, 1000);
// 排序
Collections.sort(list);
System.out.println(list.toString());
Collections.sort(list, new Comparator<Integer>() {
@Override
// o1排在o2后面,返回值大于0 ,来查看升序还是降序
public int compare(Integer o1, Integer o2) {
// TODO Auto-generated method stub
return o2 - o1;
}
});
System.out.println(list.toString());
}
public static void linklist() {
System.out.println("================linklist================");
LinkedList<Integer> list = new LinkedList<Integer>();
for (int i = 0; i < 5; i++) {
list.add(i);
}
// 遍历
for (Integer i : list) {
System.out.print(i + " ");
}
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + " ");
}
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + " ");
}
// ACID
list.add(0, 9);
System.out.println(list.indexOf(3));
System.out.println(list.lastIndexOf(3));
list.remove(2);
list.remove(new Integer(3));
System.out.println(list.toString());
list.set(0, 1000);
// 排序
Collections.sort(list);
System.out.println(list.toString());
Collections.sort(list, new Comparator<Integer>() {
@Override
// o1排在o2后面,返回值大于0 ,来查看升序还是降序
public int compare(Integer o1, Integer o2) {
// TODO Auto-generated method stub
return o2 - o1;
}
});
System.out.println(list.toString());
list.addFirst(1);
list.addLast(9);
list.getFirst();
list.getLast();
System.out.println(list.toString());
}
public static void queue() {
System.out.println("================queue================");
Queue<Integer> q = new LinkedList<Integer>();
q.offer(1);
q.offer(2);
q.offer(3);
q.offer(4);
// q.element();//返回队头
System.out.println(q.peek());
// q.remove();//移除并返回队头
System.out.println(q.poll());
System.out.println(q.toString());
}
private static void stack() {
System.out.println("================stack================");
LinkedList<Integer> s = new LinkedList<Integer>();
for (int i = 0; i < 4; i++) {
s.push(i);
}
System.out.println(s.peek());
System.out.println(s.pop());
System.out.println(s.toString());
}
// 无序不可重复,非线程安全的
// 首先,hashCode()方法返回的是一个哈希值,这个哈希值是由对象在内存中的地址所形成的,
// 如果两个对象的哈希值不一样,那么这两个对象肯定是不相同的,如果哈希值一样,那么这还不能肯定这两个对象是否一样,
// 还需要通过equlas()方法比较一下两个对象是否一样,equals()返回true才能说明这两个对象是相同的
private static void hashset() {
System.out.println("================hashset================");
Set<String> set = new HashSet<String>();
set.add("123");
set.add("456");
set.add("zsy");
set.add("123");
System.out.println(set.size());
set.remove("zsy");
set.remove(new String("456"));
System.out.println(set.toString());
}
// 非线程安全的,排序规则是默认使用元素的自然排序,重不重复也是通过compareTo()方法来完成的,当compareTo()方法返回值为0时,两个对象是相同的。
// LinkedHashSet将会以元素的放入顺序来依次访问
private static void treeset() {
System.out.println("================treeset================");
Set<String> set = new TreeSet<String>();
set.add("123");
set.add("963");
set.add("125");
set.add("456");
set.add("zsy");
set.add("123");
System.out.println(set.size());
set.remove("zsy");
set.remove(new String("456"));
System.out.println(set.toString());
}
private static void hashmap() {
System.out.println("================hashmap================");
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("zsy", 93);
map.put("syz", 86);
map.put("ysz", 88);
// 1.通过遍历键的Set集合来遍历整个Map集合
System.out.println("foreach遍历");
for (String str : map.keySet()) {
System.out.println(str + ":" + map.get(str));
}
System.out.println("迭代器遍历");
Iterator<String> intertor = map.keySet().iterator();
while (intertor.hasNext()) {
String key = intertor.next();
System.out.println(key + ":" + map.get(key));
}
// 2.使用Map集合的关系遍历
System.out.println("Map关系遍历");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
map.remove("zsy");
System.out.println(map.toString());
}
private static void treemap() {
System.out.println("================treemap================");
Map<String, Integer> map = new TreeMap<String, Integer>();
map.put("zsy", 93);
map.put("syz", 86);
map.put("ysz", 88);
// 1.通过遍历键的Set集合来遍历整个Map集合
System.out.println("foreach遍历");
for (String str : map.keySet()) {
System.out.println(str + ":" + map.get(str));
}
System.out.println("迭代器遍历");
Iterator<String> intertor = map.keySet().iterator();
while (intertor.hasNext()) {
String key = intertor.next();
System.out.println(key + ":" + map.get(key));
}
// 2.使用Map集合的关系遍历
System.out.println("Map关系遍历");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
map.remove("zsy");
System.out.println(map.toString());
}
public static void main(String[] args) {
arrayList();
linklist();
queue();
stack();
hashset();
treeset();
hashmap();
treemap();
}
}
//优先队列PriorityQueue 默认最小值拥有最高的优先级,可以提供自己的comparator对象来改变排序如Collection.reverseOrder()
public class PriorityQueueDemo {
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue =
new PriorityQueue<Integer>();
Random rand = new Random(47);
for(int i = 0; i < 10; i++)
priorityQueue.offer(rand.nextInt(i + 10));
QueueDemo.printQ(priorityQueue);
List<Integer> ints = Arrays.asList(25, 22, 20,
18, 14, 9, 3, 1, 1, 2, 3, 9, 14, 18, 21, 23, 25);
priorityQueue = new PriorityQueue<Integer>(ints);
QueueDemo.printQ(priorityQueue);
priorityQueue = new PriorityQueue<Integer>(
ints.size(), Collections.reverseOrder());
priorityQueue.addAll(ints);
QueueDemo.printQ(priorityQueue);
String fact = "EDUCATION SHOULD ESCHEW OBFUSCATION";
List<String> strings = Arrays.asList(fact.split(""));
PriorityQueue<String> stringPQ =
new PriorityQueue<String>(strings);
QueueDemo.printQ(stringPQ);
stringPQ = new PriorityQueue<String>(
strings.size(), Collections.reverseOrder());
stringPQ.addAll(strings);
QueueDemo.printQ(stringPQ);
Set<Character> charSet = new HashSet<Character>();
for(char c : fact.toCharArray())
charSet.add(c); // Autoboxing
PriorityQueue<Character> characterPQ =
new PriorityQueue<Character>(charSet);
QueueDemo.printQ(characterPQ);
}
} /* Output:
0 1 1 1 1 1 3 5 8 14
1 1 2 3 3 9 9 14 14 18 18 20 21 22 23 25 25
25 25 23 22 21 20 18 18 14 14 9 9 3 3 2 1 1
A A B C C C D D E E E F H H I I L N N O O O O S S S T T U U U W
W U U U T T S S S O O O O N N L I I H H F E E E D D C C C B A A
A B C D E F H I L N O S T U W
*///:~JDK9对集合优化
Java 9,添加了几种集合工厂方法,更方便创建少量元素的集合、map实例。新的List、Set、Map的静态工厂方法可以更方便地创建集合的不可变实例。
public class HelloJDK9 {
public static void main(String[] args) {
Set<String> str1=Set.of("a","b","c");
//str1.add("c");这里编译的时候不会错,但是执行的时候会报错,因为是不可变的集合
System.out.println(str1);
Map<String,Integer> str2=Map.of("a",1,"b",2);
System.out.println(str2);
List<String> str3=List.of("a","b");
System.out.println(str3);
}
} of()方法只是Map,List,Set这三个接口的静态方法,其父类接口和子类实现并没有这类方法,比如 HashSet,ArrayList等等;
异常
在Java等面向对象的编程语言中,异常本身是一个类,产生异常就是创建异常对象并抛出了一个异常对象。Java处理异常的方式是中断处理。
- 编译时期异常:checked异常。在编译时期,就会检查,如果没有处理异常,则编译失败。(如日期格式化异常)
- 运行时期异常:runtime异常。在运行时期,检查异常.在编译时期,运行异常不会编译器检测(不报错)。(如数学异常)
异常的分类
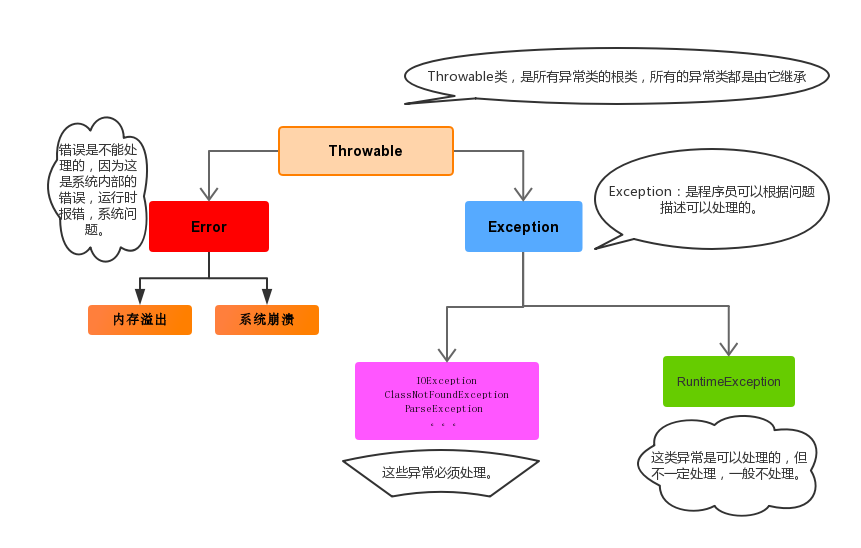
异常产生过程

throw用在方法内,用来抛出一个异常对象,将这个异常对象传递到调用者处,并结束当前方法的执行
throw new NullPointerException("要访问的arr数组不存在");
throw new ArrayIndexOutOfBoundsException("该索引在数组中不存在,已超出范围");关键字throws运用于方法声明之上,用于表示当前方法不处理异常,而是提醒该方法的调用者来处理异常(抛出异常).
修饰符 返回值类型 方法名(参数) throws 异常类名1,异常类名2…{ }
public static void read(String path)throws FileNotFoundException, IOException {}自定义异常
自定义异常,在开发中根据自己业务的异常情况来定义异常类.
- 自定义一个编译期异常: 自定义类 并继承于
java.lang.Exception。 - 自定义一个运行时期的异常类:自定义类 并继承于
java.lang.RuntimeException。
多线程
并发与并行
进程与线程
进程:是指一个内存中运行的应用程序,每个进程都有一个独立的内存空间,一个应用程序可以同时运行多个进程;进程也是程序的一次执行过程,是系统运行程序的基本单位;系统运行一个程序即是一个进程从创建、运行到消亡的过程。
线程:线程是进程中的一个执行单元,负责当前进程中程序的执行,一个进程中至少有一个线程。一个进程中是可以有多个线程的,这个应用程序也可以称之为多线程程序。
简而言之:进程是资源分配的最小单位,线程是程序执行的最小单位(资源调度的最小单位)。一个程序运行后至少有一个进程,一个进程中可以包含多个线程
区别
1、进程是资源分配的最小单位,线程是程序执行的最小单位(资源调度的最小单位)
2、进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。
而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
3、线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
4、但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
5、同步方式不同:进程:无名管道、有名管道、信号、共享内存、消息队列、信号量、sockets
线程:互斥量、读写锁、自旋锁、线程信号、条件变量
6、进程对资源保护要求高,开销大,效率相对较低,线程资源保护要求不高,但开销小,效率高,可频繁切换;堆与栈
堆: 是大家共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是记得用完了要还给操作系统,要不然就是内存泄漏。 栈:是个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是 thread safe的。操作系统在切换线程的时候会自动的切换栈,就是切换SS/ESP寄存器。栈空间不需要在高级语言里面显式的分配和释放
多线程
在java中,每次程序运行至少启动2个线程。一个是main线程,一个是垃圾收集线程。因为每当使用java命令执行一个类的时候,实际上都会启动一个JVM,每一个JVM其实在就是在操作系统中启动了一个进程。
01_多线程随机性打印结果
多线程执行时,在栈内存中,其实每一个执行线程都有一片自己所属的栈内存空间。进行方法的压栈和弹栈。
02_多线程内存图解
线程创建
Java使用java.lang.Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例。程序启动运行 main时候,jvm启动一个进程,主线程main在main()调用时候被创建。
public Thread() :分配一个新的线程对象。
public Thread(String name) :分配一个指定名字的新的线程对象。
public Thread(Runnable target) :分配一个带有指定目标新的线程对象。
public Thread(Runnable target,String name) :分配一个带有指定目标新的线程对象并指定名字
public String getName() :获取当前线程名称。
public void start() :导致此线程开始执行; Java虚拟机调用此线程的run方法。
public void run() :此线程要执行的任务在此处定义代码。
public static void sleep(long millis) :使当前正在执行的线程以指定的毫秒数暂停(暂时停止执行)。
public static Thread currentThread() :返回对当前正在执行的线程对象的引用创建线程的方式总共有两种,一种是继承Thread类方式,一种是实现Runnable接口方式。
继承Thread类方式
1. 定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程需要完成的任务,因此把run()方法称为线程执行体。
2. 创建Thread子类的实例,即创建了线程对象
3. 调用线程对象的start()方法来启动该线程实现Runnable接口方式
1. 定义Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
2. 创建Runnable实现类的实例,并以此实例作为Thread的target来创建Thread对象,该Thread对象才是真正
的线程对象。
3. 调用线程对象的start()方法来启动线程。实现Runnable接口比继承Thread类所具有的优势:
1. 适合多个相同的程序代码的线程去共享同一个资源。
2. 可以避免java中的单继承的局限性。
3. 增加程序的健壮性,实现解耦操作,代码可以被多个线程共享,代码和线程独立。
4. 线程池只能放入实现Runable或Callable类线程,不能直接放入继承Thread的类。线程安全
如果有多个线程在同时运行,而这些线程可能会同时运行这段代码。程序每次运行结果和单线程运行的结果是一样 的,而且其他的变量的值也和预期的是一样的,就是线程安全的。线程安全问题都是由全局变量及静态变量引起的。
03_线程安全问题的概述
04_线程安全问题产生的原理

线程同步
当我们使用多个线程访问同一资源的时候,且多个线程中对资源有写的操作,就容易出现线程安全问题。为了保证每个线程都能正常执行原子操作,Java引入了线程同步机制。有三种方式完成同步操作:
同步代码块
synchronized 关键字可以用于方法中的某个区块中,表示只对这个区块的资源实行互斥访问。
synchronized(同步锁){
需要同步操作的代码
}同步锁:对象的同步锁只是一个概念,可以想象为在对象上标记了一个锁.在任何时候,最多允许一个线程拥有同步锁,谁拿到锁就进入代码块,其他的线程只能在外等着(BLOCKED)。
1. 锁对象 可以是任意类型。
2. 多个线程对象 要使用同一把锁。05_同步的原理
同步方法
同步方法 :使用synchronized修饰的方法,就叫做同步方法,保证A线程执行该方法的时候,其他线程只能在方法外 等着。同步锁是谁?对于非static方法,同步锁就是this。对于static方法,我们使用当前方法所在类的字节码对象(类名.class)。
public synchronized void method(){
可能会产生线程安全问题的代码
}Lock 锁
java.util.concurrent.locks.Lock 机制提供了比synchronized代码块和synchronized方法更广泛的锁定操作,同步代码块/同步方法具有的功能Lock都有,除此之外更强大,更体现面向对象。 Lock锁也称同步锁,加锁与释放锁方法化了,如下:
public void lock() :加同步锁。
public void unlock() :释放同步锁。线程状态
线程的状态图
等待唤醒机制(生产消费者)
线程间通信:多个线程在处理同一个资源,但是处理的动作(线程的任务)却不相同。

1. wait方法与notify方法必须要由同一个锁对象调用。因为:对应的锁对象可以通过notify唤醒使用同一个锁对象调用的wait方法后的线程。
2. wait方法与notify方法是属于Object类的方法的。因为:锁对象可以是任意对象,而任意对象的所属类都是继承了Object类的。
3. wait方法与notify方法必须要在同步代码块或者是同步函数中使用。因为:必须要通过锁对象调用这2个方法。线程池
线程池:其实就是一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作,无需反复创建线程而消耗过多资源。
1. 降低资源消耗。减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
2. 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
3. 提高线程的可管理性。可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。public class ThreadPoolDemo {
public static void main(String[] args) {
// 创建线程池对象,真正的线程池接口是`java.util.concurrent.ExecutorService`。
ExecutorService service = Executors.newFixedThreadPool(2);//包含2个线程对象
// 创建Runnable实例对象
MyRunnable r = new MyRunnable();
// 从线程池中获取线程对象,然后调用MyRunnable中的run()
service.submit(r);
// 再获取个线程对象,调用MyRunnable中的run()
service.submit(r);
service.submit(r);
// 注意:submit方法调用结束后,程序并不终止,是因为线程池控制了线程的关闭。
// 将使用完的线程又归还到了线程池中
// 关闭线程池
//service.shutdown();
}
}文件与IO
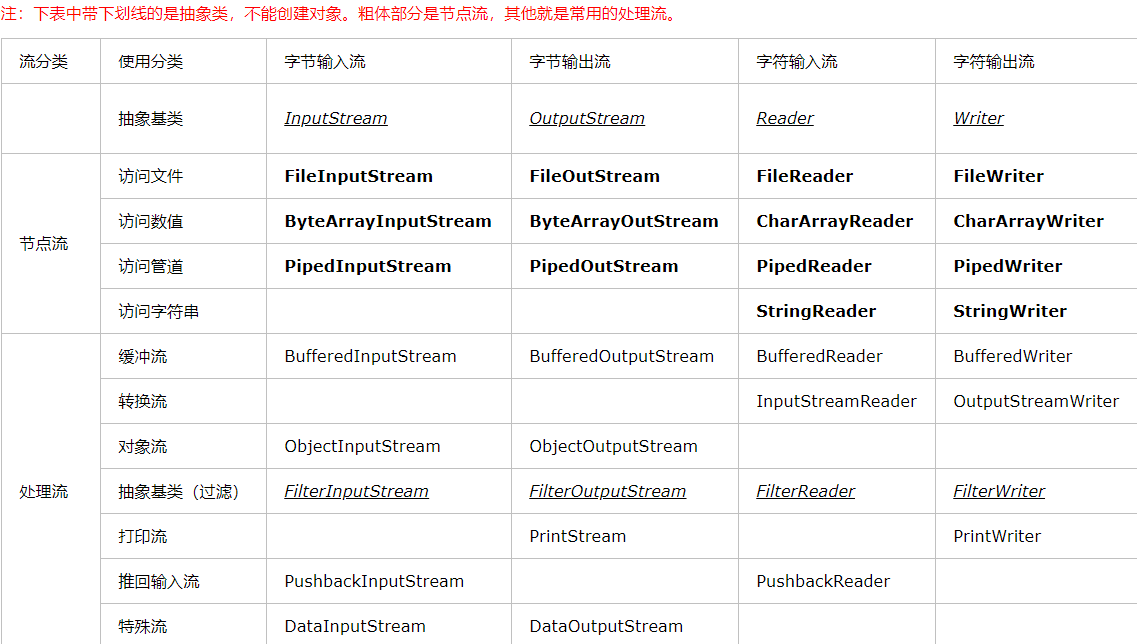
1.Java IO是采用的是装饰模式,即采用处理流来包装节点流的方式,来达到代码通用性。
2.处理流和节点流的区分方法,节点流在新建时需要一个数据源(文件、网络)作为参数,而处理流需要一个节点流作为参数。
3.处理流的作用就是提高代码通用性,编写代码的便捷性,提高性能。
4.节点流都是对应抽象基类的实现类,它们都实现了抽象基类的基础读写方法。其中read()方法如果返回-1,代表已经读到数据源末尾。
标准输入输出重定向
在Java中输入输出数据一般(图形化界面例外)要用到标准输入输出流System.in,System.out,默认指向控制台,但有时程序从文件中输入数据并将结果输送到文件中,这是就需要用到流的重定向,若想重定向之后恢复流的原始指向,就需要保存下最原始的标准输入输出流。
//保存最原始的输入输出流
InputStream in = System.in;
PrintStream out = System.out;
//将标准输入流重定向至 in.txt
System.setIn(new FileInputStream("in.txt"));
Scanner scanner = new Scanner(System.in);
//将标准输出流重定向至 out.txt
System.setOut(new PrintStream("out.txt"));
//将 in.txt中的数据输出到 out.txt中
while (scanner.hasNextLine()) {
String str = scanner.nextLine();
System.out.println(str);
}
//将标准输出流重定向至控制台
System.setIn(in);
//将标准输出流重定向至控制台
System.setOut(out);
scanner = new Scanner(System.in);
String string = scanner.nextLine();
System.out.println("输入输出流已经恢复 " + string);File类
java.io.File 类是文件和目录路径名的抽象表示,主要用于文件和目录的创建、查找和删除等操作。无论该路径下是否存在文件或者目录,都不影响File对象的创建。
public String getAbsolutePath() :返回此File的绝对路径名字符串。
public String getPath() :将此File转换为路径名字符串。
public String getName() :返回由此File表示的文件或目录的名称。
public long length() :返回由此File表示的文件的长度。
public boolean exists()`:此File表示的文件或目录是否实际存在。
public boolean isDirectory() :此File表示的是否为目录。
public boolean isFile() :此File表示的是否为文件。
public boolean createNewFile() :当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。
public boolean delete() :删除由此File表示的文件或目录。目录必须为空才能删除。
public boolean mkdir() :创建由此File表示的目录。
public boolean mkdirs() :创建由此File表示的目录,包括任何必需但不存在的父目录。
public String[] list() :返回一个String数组,表示该File目录中的所有子文件或目录。
public File[] listFiles() :返回一个File数组,表示该File目录中的所有的子文件或目录。 文件过滤器
java.io.FileFilter是一个接口,是File的过滤器。 该接口的对象可以传递给File类的listFiles(FileFilter) 作为参数, 接口中只有一个方法。
boolean accept(File pathname) :测试pathname是否应该包含在当前File目录中,符合则返回true。
FileFilter过滤器的原理

OutputStream 抽象类
流的关闭原则:先开后关,后开先关。
java.io.OutputStream抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。定义了字节输出流的基本共性功能方法
public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
public void write(byte[] b) :将 b.length字节从指定的字节数组写入此输出流。
public void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。
public abstract void write(int b) :将指定的字节输出流FileOutputStream类
java.io.FileOutputStream类是文件输出流,用于将数据写出到文件。
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。后加参数 `true` 表示追加数据,`false` 表示清空原有数据。
public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。
write(byte[] b),write(int b),write(byte[] b, int off, int len)写出数据系统中的换行:
- Windows系统里,每行结尾是
回车+换行,即\r\n; - Unix系统里,每行结尾只有
换行,即\n; - Mac系统里,每行结尾是
回车,即\r。从 Mac OS X开始与Linux统一
02_文件存储的原理和记事本打开文件的原理
InputStream 抽象类
java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
public void close() :关闭此输入流并释放与此流相关联的任何系统资源。
public abstract int read() : 从输入流读取数据的下一个字节。
public int read(byte[] b) : 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。
int available():返回值为流中尚未读取的字节的数量。
long skip(long n):读指针跳过n个字节不读,返回值为实际跳过的字节数量
boolean markSupported():当前的流是否支持读指针的记录功能
void mark(int readlimit):记录当前指针的所在位置。readlimit表示读指针读出的readlimit个字节后,所标记的指针位置才失效。使用这个函数前请用前一个函数判断流是否支持
void reset():把读指针重新指向用mark方法所记录的位置FileInputStream类
FileInputStream(File file) : 通过打开与实际文件的连接来创建一个 FileInputStream ,如果没有该文件,会抛出`FileNotFoundException`
FileInputStream(String name) : 通过打开与实际文件的连接来创建一个 FileInputStream
read()方法,每次可以读取一个字节的数据,提升为int类型,读取到文件末尾,返回-1
read(byte[] b),每次读取b的长度个字节到数组中,返回读取到的有效字节个数,读取到末尾时,返回-103_字节流读取文件的原理

Reader抽象类
java.io.Reader抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。字符流,只能操作文本文件,不能操作图片,视频等非文本文件。
public void close() :关闭此流并释放与此流相关联的任何系统资源。
public int read(): 从输入流读取一个字符。
public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。FileReader类
java.io.FileReader类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。
FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
read():每次可以读取一个字符的数据,提升为int类型,读取到文件末尾,返回`-1`
read(char[] cbuf),每次读取b的长度个字符到数组中,返回读取到的有效字符个数,读取到末尾时,返回`-1`Writer 抽象类
java.io.Writer抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
- `void write(int c)` 写入单个字符。
- `void write(char[] cbuf) `写入字符数组。
- `abstract void write(char[] cbuf, int off, int len) `写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
- `void write(String str) `写入字符串。
- `void write(String str, int off, int len)` 写入字符串的某一部分,off字符串的开始索引,len写的字符个数。
- `void flush() `刷新该流的缓冲。
- `void close()` 关闭此流,但要先刷新它。FileWriter类
- `FileWriter(File file)`: 创建一个新的 FileWriter,给定要读取的File对象。
- `FileWriter(String fileName)`: 创建一个新的 FileWriter,给定要读取的文件的名称。 Properties类
java.util.Properties 继承于Hashtable ,来表示一个持久的属性集。它使用键值结构存储数据,每个键及其对应值都是一个字符串。
- `public Properties()` :创建一个空的属性列表。
- `public Object setProperty(String key, String value)` : 保存一对属性。
- `public String getProperty(String key) ` :使用此属性列表中指定的键搜索属性值。
- `public Set<String> stringPropertyNames() ` :所有键的名称的集合。
public void load(InputStream inStream)`: 从字节输入流中读取键值对。可以使用空格、等号、冒号分割
eg:Properties pro=new Properties().load(new FileInputStream("read.txt"));缓冲流
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。01_缓冲流的原理如下:
- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter
BufferedReader:`public String readLine()`: 读一行文字。
BufferedWriter:`public void newLine()`: 写一行行分隔符,由系统属性定义符号。 转换流
编码:字符(能看懂的)--字节(看不懂的)
解码:字节(看不懂的)-->字符(能看懂的)
02_转换流的原理
转换流java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。
InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。转换流java.io.OutputStreamWriter ,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。
OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。序列化
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的数据、对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。
04_序列号冲突异常的原理和解决方案
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。writeObject (Object obj) : 将指定的对象写出。
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。readObject () : 读取一个对象
一个对象要想序列化,必须满足两个条件:
- 该类必须实现
java.io.Serializable接口,Serializable是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出NotSerializableException。 - 该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用
transient关键字修饰。
对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个 ClassNotFoundException 异常。若class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。
Serializable 接口给需要序列化的类,提供了一个序列版本号。serialVersionUID 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
网络编程
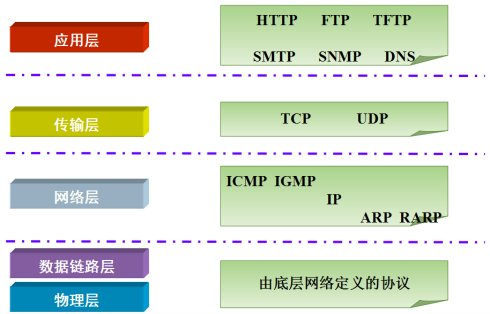
如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程(应用程序)了。利用协议+IP地址+端口号 三元组合,就可以标识网络中的进程了,那么进程间的通信就可以利用这个标识与其它进程进行交互。
- 端口号:用两个字节表示的整数,它的取值范围是0~65535。其中,0~1023之间的端口号用于一些知名的网络服务和应用,普通的应用程序需要使用1024以上的端口号。

在Java中,提供了两个类用于实现TCP通信程序:
- 客户端:
java.net.Socket类表示。创建Socket对象,向服务端发出连接请求,服务端响应请求,两者建立连接开始通信。 - 服务端:
java.net.ServerSocket类表示。创建ServerSocket对象,相当于开启一个服务,并等待客户端的连接。
文件上传
03_文件上传的原理
04_文件上传案例的阻塞问题
模拟B\S服务器

public class ServerDemo {
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(8888);
while(true){
Socket socket = server.accept();
new Thread(new Web(socket)).start();
}
}
static class Web implements Runnable{
private Socket socket;
public Web(Socket socket){
this.socket=socket;
}
public void run() {
try{
//转换流,读取浏览器请求第一行
BufferedReader readWb = new
BufferedReader(new InputStreamReader(socket.getInputStream()));
String requst = readWb.readLine();
//取出请求资源的路径
String[] strArr = requst.split(" ");
System.out.println(Arrays.toString(strArr));
String path = strArr[1].substring(1);
System.out.println(path);
FileInputStream fis = new FileInputStream(path);
System.out.println(fis);
byte[] bytes= new byte[1024];
int len = 0 ;
//向浏览器 回写数据
OutputStream out = socket.getOutputStream();
out.write("HTTP/1.1 200 OK\r\n".getBytes());
out.write("Content-Type:text/html\r\n".getBytes());
out.write("\r\n".getBytes());
while((len = fis.read(bytes))!=-1){
out.write(bytes,0,len);
}
fis.close();
out.close();
readWb.close();
socket.close();
}catch(Exception ex){
}
}
}
}测试
* 测试分类:
1. 黑盒测试:不需要写代码,给输入值,看程序是否能够输出期望的值。
2. 白盒测试:需要写代码的。关注程序具体的执行流程。
* Junit使用:白盒测试
* 步骤:
1. 定义一个测试类(测试用例)
* 建议:
* 测试类名:被测试的类名Test CalculatorTest
* 包名:xxx.xxx.xx.test cn.itcast.test
2. 定义测试方法:可以独立运行
* 建议:
* 方法名:test测试的方法名 testAdd()
* 返回值:void
* 参数列表:空参
3. 给方法加@Test
4. 导入junit依赖环境
* 判定结果:
* 红色:失败
* 绿色:成功
* 一般我们会使用断言操作来处理结果
* Assert.assertEquals(期望的结果,运算的结果);
* 补充:
* @Before:
* 修饰的方法会在测试方法之前被自动执行
* @After:
* 修饰的方法会在测试方法执行之后自动被执行反射:框架设计的灵魂
反射
框架:半成品软件。可以在框架的基础上进行软件开发,简化编码
将类的各个组成部分封装为其他对象,这就是反射机制
- 可以在程序运行过程中,操作这些对象。
- 可以解耦,提高程序的可扩展性。
获取Class对象的方式:
1. Class.forName("全类名"):将字节码文件加载进内存,返回Class对象
* 多用于配置文件,将类名定义在配置文件中。读取文件,加载类
2. 类名.class:通过类名的属性class获取
* 多用于参数的传递
3. 对象.getClass():getClass()方法在Object类中定义着。
* 多用于对象的获取字节码的方式
* 结论:
同一个字节码文件(*.class)在一次程序运行过程中,只会被加载一次,不论通过哪一种方式获取的Class对象都是同一个。- Class对象功能:
* 获取功能:
1. 获取成员变量们
* Field[] getFields() :获取所有public修饰的成员变量
* Field getField(String name) 获取指定名称的 public修饰的成员变量
* Field[] getDeclaredFields() 获取所有的成员变量,不考虑修饰符
* Field getDeclaredField(String name)
2. 获取构造方法们
* Constructor<?>[] getConstructors()
* Constructor<T> getConstructor(类<?>... parameterTypes)
* Constructor<T> getDeclaredConstructor(类<?>... parameterTypes)
* Constructor<?>[] getDeclaredConstructors()
3. 获取成员方法们:
* Method[] getMethods()
* Method getMethod(String name, 类<?>... parameterTypes)
* Method[] getDeclaredMethods()
* Method getDeclaredMethod(String name, 类<?>... parameterTypes)
4. 获取全类名
* String getName() - Field:成员变量
1. 设置值
* void set(Object obj, Object value)
2. 获取值
* get(Object obj)
3. 忽略访问权限修饰符的安全检查
* setAccessible(true):暴力反射- Field:成员变量
* 创建对象:
* T newInstance(Object... initargs)
* 如果使用空参数构造方法创建对象,操作可以简化:Class对象的newInstance方法- Method:方法对象
* 执行方法:
* Object invoke(Object obj, Object... args)
* 获取方法名称:
* String getName:获取方法名* 案例:
* 需求:写一个"框架",不能改变该类的任何代码的前提下,可以帮我们创建任意类的对象,并且执行其中任意方法
* 实现:1. 配置文件 2. 反射
public static void main(String[] args) throws Exception {
//可以创建任意类的对象,可以执行任意方法
//1.加载配置文件
//1.1创建Properties对象
Properties pro = new Properties();
//1.2加载配置文件,转换为一个集合
//1.2.1获取class目录下的配置文件
ClassLoader classLoader = ReflectTest.class.getClassLoader();
InputStream is = classLoader.getResourceAsStream("pro.properties");
pro.load(is);
//2.获取配置文件中定义的数据
String className = pro.getProperty("className");
String methodName = pro.getProperty("methodName");
//3.加载该类进内存
Class cls = Class.forName(className);
//4.创建对象
Object obj = cls.newInstance();
//5.获取方法对象
Method method = cls.getMethod(methodName);
//6.执行方法
method.invoke(obj);
}注解
* 概念:说明程序的。给计算机看的
* 注释:用文字描述程序的。给程序员看的
* 定义:注解(Annotation),也叫元数据。一种代码级别的说明。它是JDK1.5及以后版本引入的一个特性,与类、接口、枚举是在同一个层次。它可以声明在包、类、字段、方法、局部变量、方法参数等的前面,用来对这些元素进行说明,注释。
* 概念描述:
* JDK1.5之后的新特性
* 说明程序的
* 使用注解:@注解名称
* 作用分类:
①编写文档:通过代码里标识的注解生成文档【生成文档doc文档】
②代码分析:通过代码里标识的注解对代码进行分析【使用反射】
③编译检查:通过代码里标识的注解让编译器能够实现基本的编译检查【Override】* JDK中预定义的一些注解
* @Override :检测被该注解标注的方法是否是继承自父类(接口)的
* @Deprecated:该注解标注的内容,表示已过时
* @SuppressWarnings:压制警告
* 一般传递参数all @SuppressWarnings("all")
* 自定义注解
* 格式:
元注解
public @interface 注解名称{
属性列表;
}
* 本质:注解本质上就是一个接口,该接口默认继承Annotation接口
* public interface MyAnno extends java.lang.annotation.Annotation {}
* 属性:接口中的抽象方法
* 要求:
1. 属性的返回值类型有下列取值
* 基本数据类型
* String
* 枚举
* 注解
* 以上类型的数组
2. 定义了属性,在使用时需要给属性赋值
1. 如果定义属性时,使用default关键字给属性默认初始化值,则使用注解时,可以不进行属性的赋值。
2. 如果只有一个属性需要赋值,并且属性的名称是value,则value可以省略,直接定义值即可。
3. 数组赋值时,值使用{}包裹。如果数组中只有一个值,则{}可以省略
* 元注解:用于描述注解的注解
* @Target:描述注解能够作用的位置
* ElementType取值:
* TYPE:可以作用于类上
* METHOD:可以作用于方法上
* FIELD:可以作用于成员变量上
* @Retention:描述注解被保留的阶段
* @Retention(RetentionPolicy.RUNTIME):当前被描述的注解,会保留到class字节码文件中,并被JVM读取到
* @Documented:描述注解是否被抽取到api文档中
* @Inherited:描述注解是否被子类继承* 在程序使用(解析)注解:获取注解中定义的属性值
1. 获取注解定义的位置的对象 (Class,Method,Field)
2. 获取指定的注解
* getAnnotation(Class)
//其实就是在内存中生成了一个该注解接口的子类实现对象
public class ProImpl implements Pro{
public String className(){
return "cn.itcast.annotation.Demo1";
}
public String methodName(){
return "show";
}
}
3. 调用注解中的抽象方法获取配置的属性值* 案例:简单的测试框架
* 小结:
1. 以后大多数时候,我们会使用注解,而不是自定义注解
2. 注解给谁用?
1. 编译器
2. 给解析程序用
3. 注解不是程序的一部分,可以理解为注解就是一个标签Java8优化
函数式接口(Lamda)
函数式接口在Java中是指:有且仅有一个抽象方法的接口。Java 8中专门为函数式接口引入了一个新的注解: @FunctionalInterface,一旦使用该注解来定义接口,编译器将会强制检查该接口是否确实有且仅有一个抽象方法,否则将会报错。函数式接口可以作为方法的参数和返回值。
(参数类型 参数名称) -> { 代码语句 }
例子:
new Thread(() -> System.out.println(Thread.currentThread().getName()+"多线程任务执行!")).start(); // 启动线程
Arrays.sort(array, (Person a, Person b) -> {
return a.getAge() - b.getAge();
});
函数式接口作为方法返回值
private static Comparator<String> newComparator(){
//函数式接口作为返回值,等价于下面的代码
// return new Comparator<String>() {
// @Override
// public int compare(String o1, String o2) {
// return o1.length()-o2.length();
// }
// };
return (o1,o2)->{
return o1.length()-o2.length();
};
}省略规则:
1. 小括号内参数的类型可以省略;
2. 如果小括号内有且仅有一个参,则小括号可以省略;
3. 如果大括号内有且仅有一个语句,则无论是否有返回值,都可以省略大括号、return关键字及语句分号。常用函数式接口
Supplier接口
java.util.function.Supplier 接口仅包含一个无参的方法: T get() 。用来获取一个泛型参数指定类型的对象数据。
Consumer接口
java.util.function.Consumer 接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据, 其数据类型由泛型决定。Consumer 接口中包含抽象方法 void accept(T t) ,意为消费一个指定泛型的数据。消费数据的时候,首先做一个操作,然后再做一个操作,实现组合。而这个方法就是 Consumer 接口中的default方法 andThen。
Predicate接口
Predicate 接口中包含一个抽象方法: boolean test(T t) 。用于条件判断的场景.既然是条件判断,就会存在与、或、非三种常见的逻辑关系。分别使用and(),or(),negate()方法。
Function接口
java.util.function.Function<T,R> 接口用来根据一个类型的数据T得到另一个类型的数据R,前者称为前置条件, 后者称为后置条件。抽象方法为 R apply(T t),根据类型T的参数获取类型R的结果。默认的 andThen 方法,用来进行组合操作。
public static int supplierTest(Supplier<Integer> sup) {
return sup.get();
}
public static void consumerTest(String name, Consumer<String> con) {
con.accept(name);
}
public static void consumerTest(String str, Consumer<String> con1, Consumer<String> con2) {
// con1.accept(str);con2.accept(str);
con1.andThen(con2).accept(str);
}
public static boolean predicateTest(String s, Predicate<String> pre) {
return pre.test(s);
}
//第一个操作是将字符串解析成为int数字,第二个操作是+10
public static int functionTest(String s, Function<String, Integer> fun1, Function<Integer, Integer> fun2) {
return fun1.andThen(fun2).apply(s);
}
public static void main(String[] args) {
System.out.println(supplierTest(() -> 123));
consumerTest("赵丽颖", (String name) -> System.out.println(name));
consumerTest("asdfg", (s) -> System.out.println(s.toUpperCase()), (s) -> System.out.println(s.toLowerCase()));
System.out.println(predicateTest("123456", (s) -> s.length() > 5));
System.out.println(functionTest("10", (s) -> Integer.parseInt(s), (a) -> a + 10));
}Stream流
在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。
Stream(流)是一个来自数据源的元素队列,流的来源。 可以是集合,数组 等。 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。 Stream操作还有两个基础的特征: Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluentstyle)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。 内部迭代: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
ArrayList<String> list = new ArrayList<>();
list.add("张无忌");list.add("周芷若");list.add("赵敏");
list.add("张强");list.add("张三丰");
list.stream().filter((s) -> s.startsWith("张")).filter((s) -> s.length() == 3).forEach((s) -> System.out.println(s));
Stream<String> stream=Stream.of("1","2","3","4");
stream.map(s -> Integer.parseInt(s)).forEach(s-> System.out.println(s));这里的 filter 都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法 forEach执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda的延迟执行特性。 备注:“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何 元素(或其地址值)
其次,stream只能使用一次,有后面的流后前面的就关闭了。
常用方法
void forEach(Consumer<? super T> action); 逐一处理
Stream<T> filter(Predicate<? super T> predicate); 将一个流按照条件转换成另一个子集流。
<R> Stream<R> map(Function<? super T, ? extends R> mapper); 将流中的元素映射到另一个流中
long count(); 统计个数
Stream<T> limit(long maxSize); 对流进行截取,只取用前n个
Stream<T> skip(long n); 跳过前几个元素
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b); 两个流合并成为一个流方法引用
可以用方法引用来代替Lamda的调用。双冒号 :: 为引用运算符,而它所在的表达式被称为方法引用。如果Lambda要表达的函数方案已经存在于某个方法的实现中,那么则可以通过双冒号来引用该方法作为Lambda的替代者。
@FunctionalInterface
public interface Printable {
void print(String str);
}
private static void printString(Printable data) {
data.print("Hello, World!");
}
public static void main(String[] args) {
printString(s ‐> System.out.println(s));
}类的构造器引用
printName("赵丽颖", Person::new);
数组的构造器引用
int[] array = initArray(10, int[]::new); 














 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









