







1 memcached简介
Memcached是一个自由开源的,高性能,分布式内存对象缓存系统。
Memcached是一种基于内存的key-value存储,用来存储小块的任意数据(字符串、对象)。这些数据可以是数据库调用、API调用或者是页面渲染的结果。
Memcached简洁而强大。它的简洁设计便于快速开发,减轻开发难度,解决了大数据量缓存的很多问题。它的API兼容大部分流行的开发语言。
本质上,它是一个简洁的key-value存储系统。
一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。
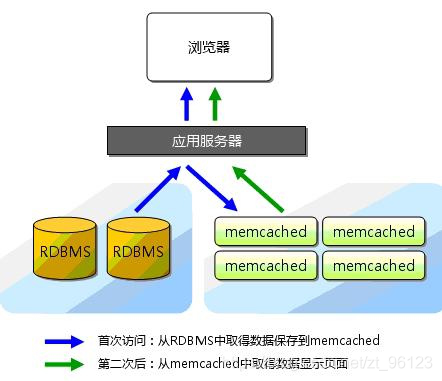
2 Memcached工作原理
2.1服务端缓存实现
Memcached使用了BSD许可的服务端缓存实现。与其它服务端缓存实现不同的是,其主要由两部分组成:独立运行的Memcached服务实例,以及用于访问这些服务实例的客户端。因此相较于普通服务端缓存实现中各个缓存都运行在服务实例之上的情况,Memcached服务实例则是在服务实例之外独立运行的:
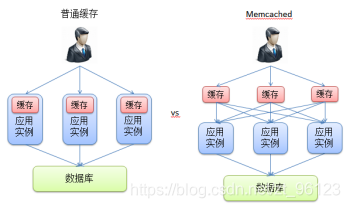
从上图中可以看出,由于Memcached缓存实例是独立于各个应用服务器实例运行的,因此应用服务实例可以访问任意的缓存实例。而传统的缓存则与特定的应用实例绑定,因此每个应用实例将只能访问特定的缓存。这种绑定一方面会导致整个应用所能够访问的缓存容量变得很小,另一方面也可能导致不同的缓存实例中存在着冗余的数据,从而降低了缓存系统的整体效率。
在运行时,Memcached服务实例只需要消耗非常少的CPU资源,却需要使用大量的内存。因此在决定如何组织您的服务端缓存结构之前,您首先需要搞清当前服务中各个服务实例的负载情况。如果一个服务器的CPU使用率非常高,却存在着非常多的空余内存,那么我们就完全可以在其上运行一个Memcached实例。而如果当前服务中的所有服务实例都没有过多的空余内存,那么我们就需要使用一系列独立的服务实例来搭建服务端缓存。一个大型服务常常拥有上百个Memcached实例。而在这上百个Memcached实例中所存储的数据则不尽相同。由于这种数据的异构性,我们需要在访问由Memcached所记录的信息之
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2743
2743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









