







爬虫日记之urllib包初体验附爬虫工作构建流程
2021-3-3
一、获取一个get请求:
import urllib.request
response=urllib.request.urlopen("https://www.baidu.com")
print(response)#此时的response中包含了百度网站的所有信息,成功读取。
运行结果为
<http.client.HTTPResponse object at 0x00000228C3E4DDA0>
print(response.read())
#通过.read()对于网站的内容进行读取
#我们把访问网站的源码封装到了一个对象中。
print(response.read().decode('utf-8'))
#由于read默认是二进制,所以我们不妨进行一下解码
运行结果为:
二、获取一个post请求
我们可以打开浏览器,访问测试网站,可以测试请求是否能得到响应,网站中可以展示真实浏览器环境请求时得到的响应。
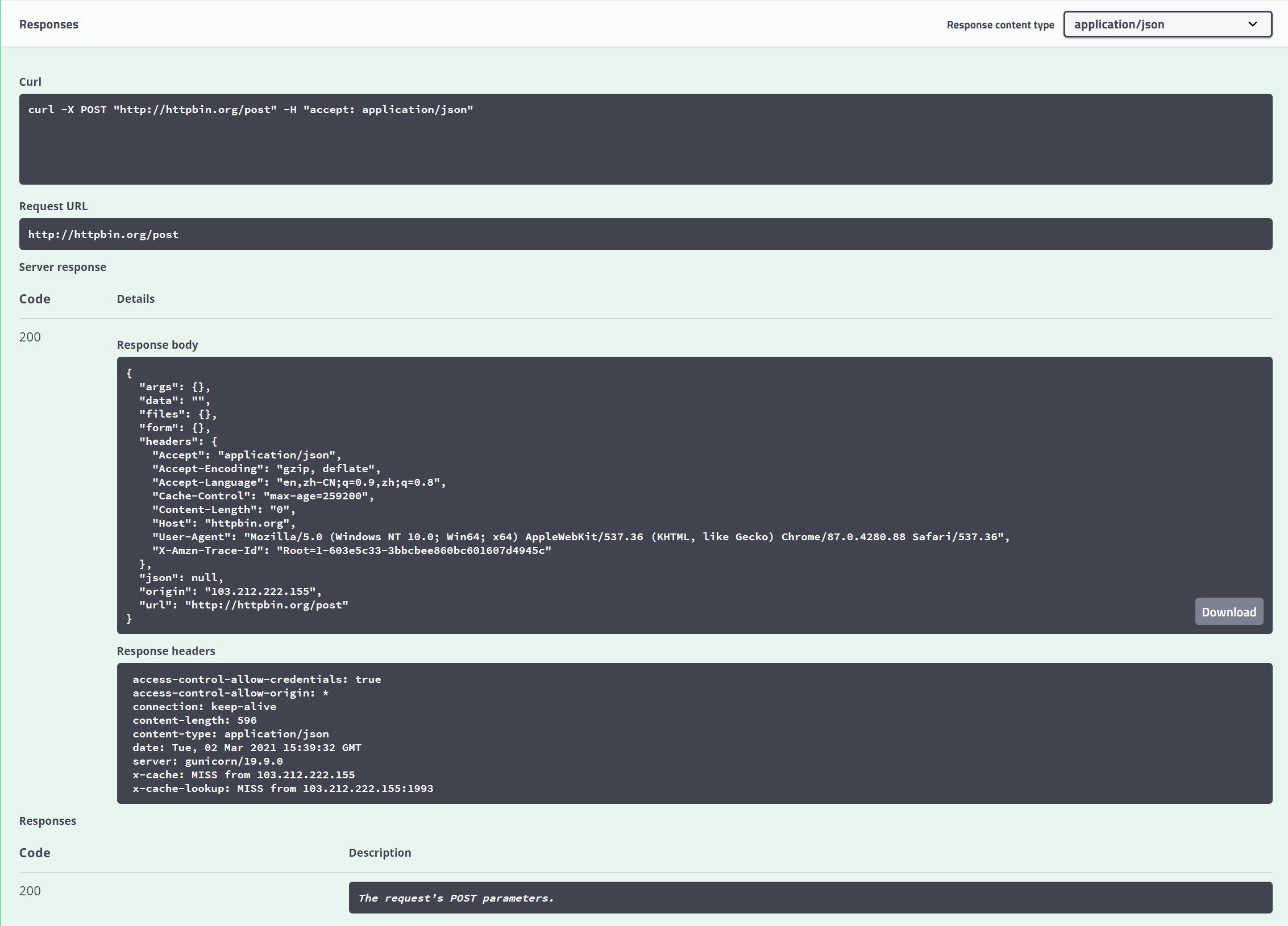
response=urllib.request.urlopen("http://httpbin.org/post")
print(response.read())
这时发现报错:

思考一下得知不能直接通过post访问,还需要传送一些post的表单信息,通过表单的封装,再进行访问。
import urllib.parse
#bytes方法可以把内部所有信息转化为一个二进制的数据包。可以往里放键值对、编码解码的数值。
#这时我们就还需要import urllib.parse进行解析,可以将键值对进行解析,最后统一变成二进制方式的字节文件封装到data包里。
data=bytes(urllib.parse.urlencode({"hello":"world"}),encoding="utf-8")
#data作为传给post的内容
response=urllib.request.urlopen("http://httpbin.org/post",data=data)
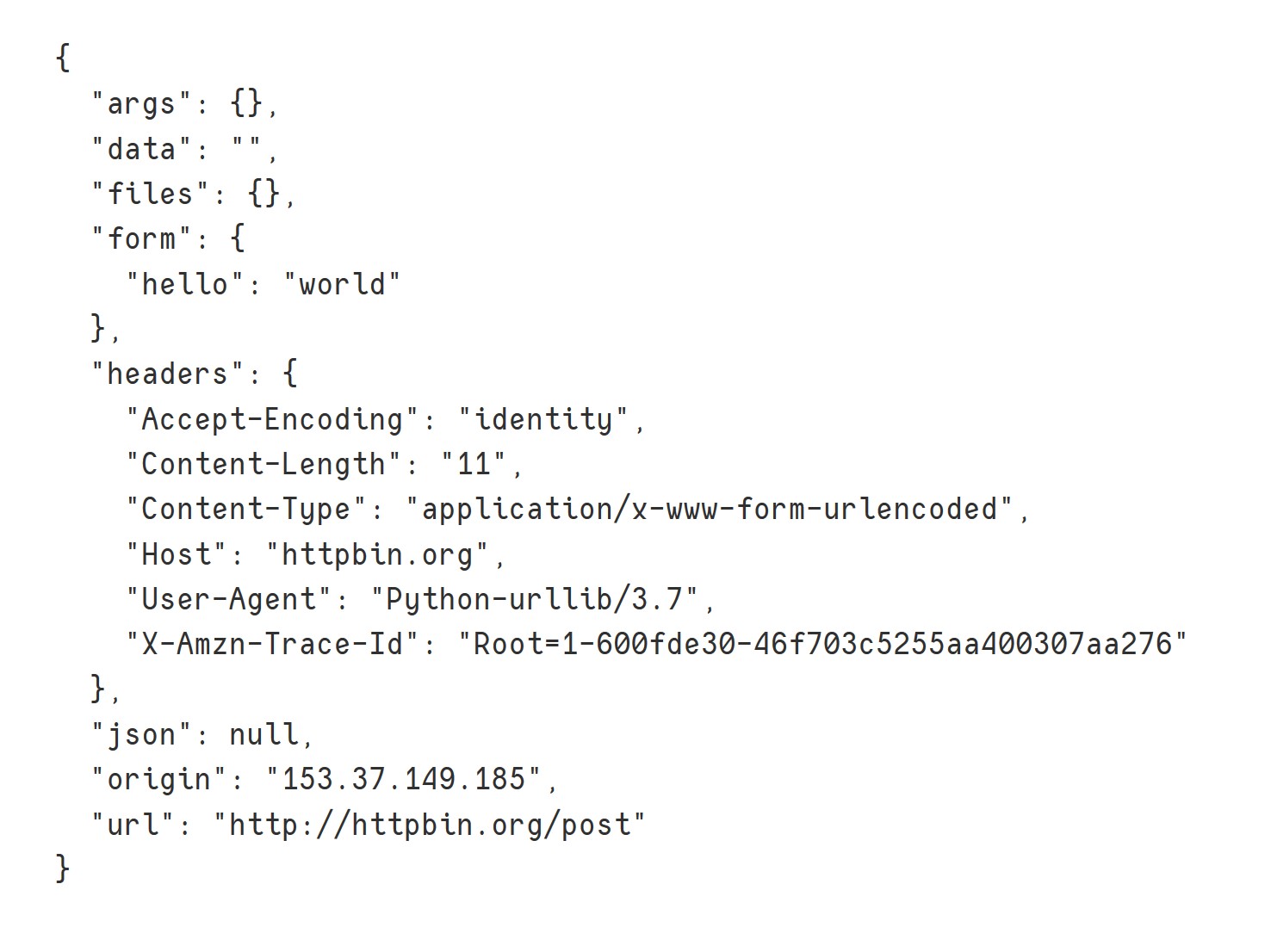
print(response.read().decode('utf-8'))
运行结果如下,发现和测试网页中对比发现基本一致
三、超时处理
我们再来测试一下get请求:
response=urllib.request.urlopen("http://httpbin.org/get)
print(response.read().decode("utf-8"))
如下图,当timeout时间过小时,就会报错:
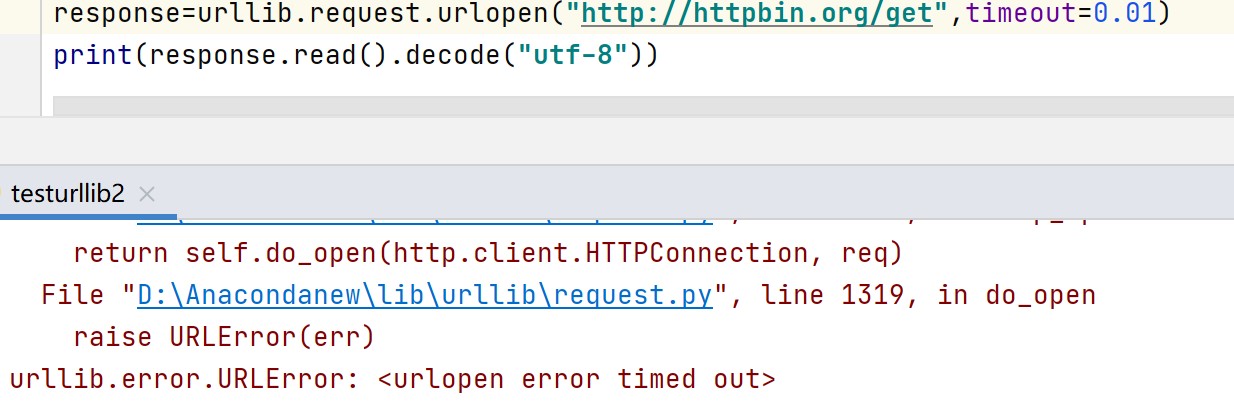
所以我们可以利用异常捕获对超时有一个计划性的准备:
try:
response=urllib.request.urlopen("http://httpbin.org/get",timeout=0.01)
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
print("Time out!Please reset!")
运行结果为: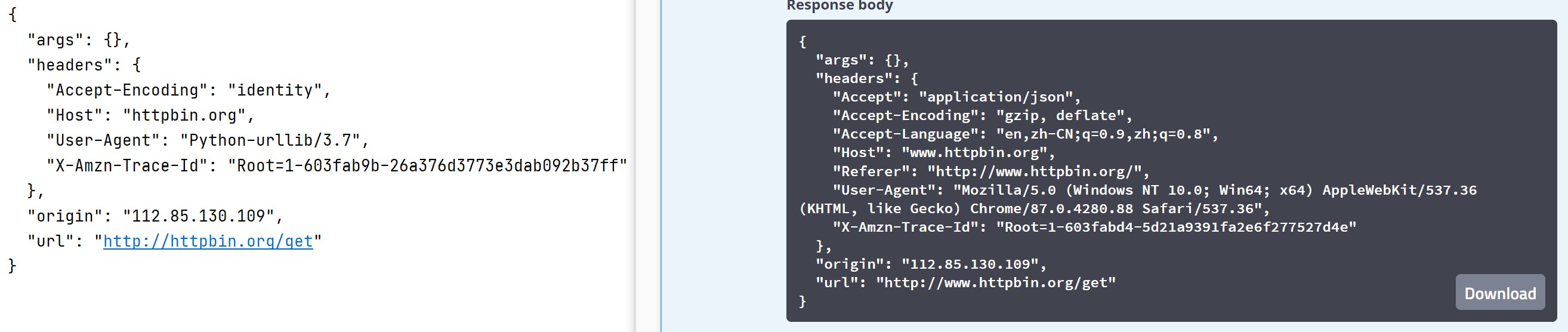
四、418问题
如上图的对比,虽然运行成功,但在与测试网站中对比不难发现区别,“User-Agent”这一行中在pycharm中会被发现不是浏览器环境,有些网站识破之后会拒绝被爬取。
所以需要把请求对象封装一下,模拟成浏览器:
1、以测试网站为例
url="http://httpbin.org/post"
#我们需要把请求对象封装一下:
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
data=bytes(urllib.parse.urlencode({"name":"tianyumyum"}))
#req此时为一个请求对象,不是响应对象
req=urllib.request.Request(url=url,data=data,headers=headers,method="POST")
#我们可以通过urlopen来发出请求
response=urllib.request(req)
print(response.read().decode("utf-8"))
2、以豆瓣网为例:
url="https://www.douban.com"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
req=urllib.request.urlopen(req)
print(response.read.decode("utf-8"))
写在后面:
我们还可以访问网站的状态码、headers等多种信息:
response =urllib.request.urlopen("http://httpbin.org/get")
print(response.status)
print(response.getheaders())
#可以读出某一项的具体内容
print(response.getheader("Server"))















 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









