







一、运算符的优先级
1.如果代码行中的运算符比较多,要用括号确定表达式的操作顺序。以防止产生歧义并提高可读性。
2.即使掌握了各个运算符的运算规则(顺序,结合性等)仍可能写出一个不能确定唯一计算路径的表达式。(我们不能确定不相邻的最高优先级运算的运算顺序)因此,我们在编程中要尽量避免这样的问题表达式,将其拆分为简单,结果明确且唯一的表达式。
3.一些问题表达式

//如果abcdef不是单一变量,而是表达式,或者当后面计算的变量影响到前面计算的内容时可能两种顺序计算的的结果是不同的。

//4-2*3? 2-3*4?
//我们只能确定对函数调用结果的运算顺序,不能确定三个函数那个先调用。
c + --c
我们并没有办法得知+的左操作数的获取在右操作数之前还是之后,使得结果不可预测

vc/linux: 这俩个是这样处理的,在进行加法运算时,求出了左值和右值后,就求出他们的和,再进行下一步运算。
(i=1,运行++i之后,i=2;运行++i后,i=3;在求出了+所需的俩个操作数之后,计算出俩个数的和放到寄存器中,这俩个操作数的位置就是当前的位置,所以3+3=6,放到寄存器中;现在对最后一个+,有了左值,右值还不确定,++i,i=4;6+4=10;)
vs:在多个式子相加时,先求出各个因式的值,最后一起执行加法操作。
( 也就是++i,++i,++i全部执行完,再求和。++i,i=2;++i,i=3;++i,i=4;然后4+4+4=12;)
二、复合表达式
1.如 a = b = c = 0这样的表达式称为复合表达式。复合表达式可以(1)使书写简洁(2)可以提高编译效率。但要防止滥用复合表达式
2.不要编写太过复杂的复合表达式
![]()
3.不要有多种用途的复合表达式

三、If 语句
bool类型与零值比较
1.C99之前没有布尔类型,C99引入了_Bool类型。为了保证C/C++的兼容性,在新增的头文件stdbool.h中,被重新用宏写成了bool。
2.bool类型的数据占一个字节,true,false都为小写
3.BOOL类型(全大写)是微软定义的标准。实际上是int类型的重命名占4字节,只能在微软VS系列的编译环境中通过,不具备可移植性,不建议使用。
4.不可以将布尔类型直接与true,false 或者1、0进行比较。根据布尔类型的语义,零值为“假”(记FALSE ),任何非零值都是“真”(记为TRUE )。TRUE 的值究竟是什么并没有统一的标准,不同的编译环境可能有不同的定义。
5.结论:bool类型推荐使用 if(flag) 或 If(!flag) 的形式直接判定,不用操作符和特定值比较
整型与零值比较
整型变量与零值比较应当将整型变量用“ == ”或“!= ”直接与数字比较。
浮点型与零值比较
1.浮点数在内存中存储可能并不是完整存储的。在十进制转为二进制的过程中可能有精度损失。在计算不尽的时候,会“四舍五入”造成数据减小或增大。
2.所以浮点数在进行比较的时候,绝对不能直接使用"=="来比较。浮点数本身有精度损失,进而导致各种结果可能有细微的差别。
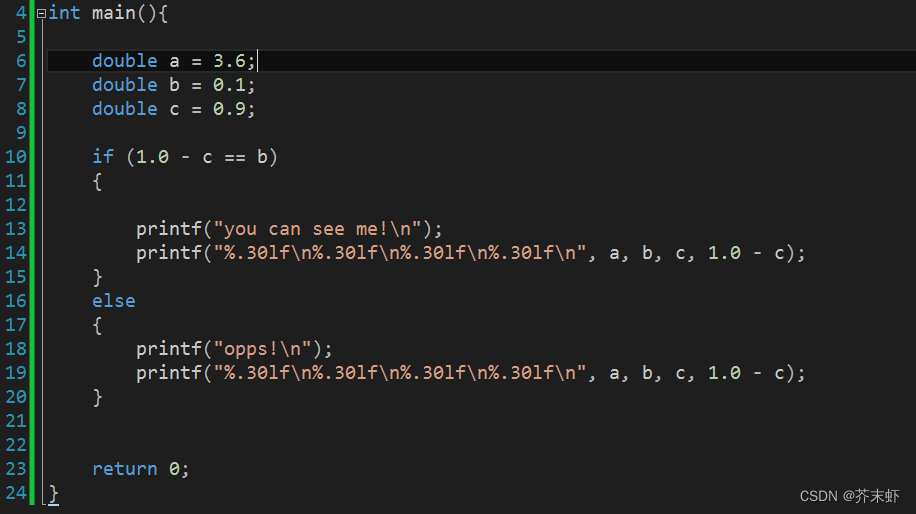

3.如何判断两个浮点数是否相等?
将两数相减看差是否在规定的精度范围内。排除细微差别的影响
Double x,y;
If (x == y)//错误的写法
If (fabs(x-y) < DBL_EPSILON)//正确的写法
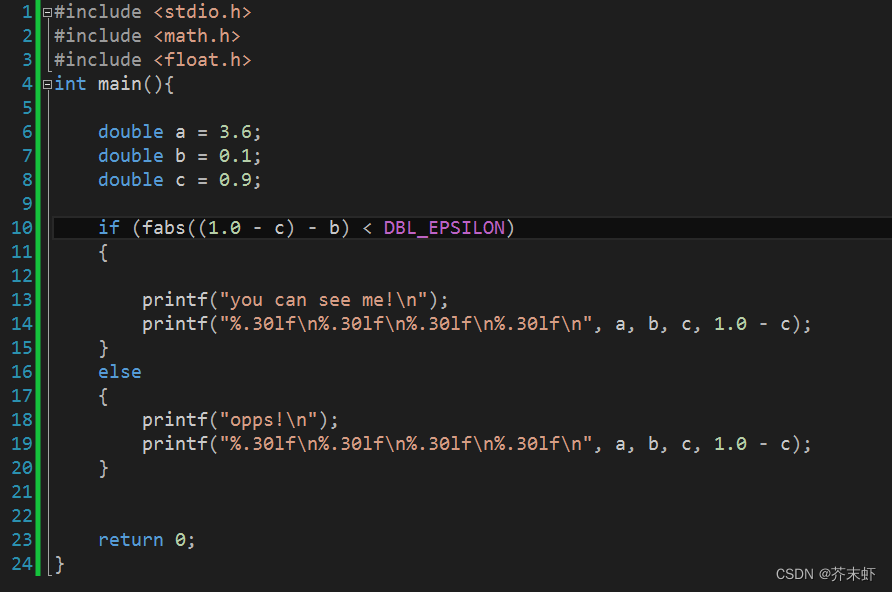
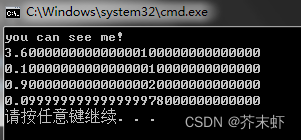
4.其中DBL_EPSILON(FLT_EPSILON)是头文件float.h定义的精度范围,头文件中的解释为:smallest such that 1.0 + DBL_EPSILON !=1.0,也就是说,DBL_EPSILON是使两浮点数数相加与原值不相等的最小值。因此判断条件应该为 "<" 而不是 "<="
5.If (fabs(x) < DBL_EPSILON)//浮点类型和零比较的正确方法
指针变量与零值比较
应当将指针变量用“==”或“!=”与 NULL 比较。与其他数据类型的比较方式区别开来。直观的反应出变量为指针变量
If/else/return组合

四、Switch 语句
1.If 比较判断的数据种类更丰富,而switch-case 语句只能用于判断整型变量,常量和表达式。
2.Case 语句后面的值不能是const修饰的只读变量,必须是真常量或常量表达式
3.If( ) 具有判断和分支功能;在switch-case 语句中 case具有判断功能,break具有分支功能(只执行相应条件下的代码块)。
4.最后必须使用 default 分支。即使程序真的不需要 defalut 处理,也因该保留default : break;
5.Case 和 break 之间不能定义变量;要定义变量需要在case 和 break 之间加上{ }大括号
6.按字母或数字顺序排列各条 case 语句。这样做的话,可以很容易的找到某条case语句
7.把正常情况放在前面,异常情况放在后面,加注释解释。
8.将执行频率较高的 case语句放在前面
9.简化每种情况对应的操作,case语句后面的代码越精炼,case语句的结果就会越清晰。如果执行的操作过多,可以将这些操作封装成一个或多个函数。
10.default子句只用于处理真正的默认情况。不要因为只剩下最后一种情况需要处理,就决定用default子句处理。这样会失去 case 语句的标号所提供的自说明功能,而且也丧失了使用 default 语句处理错误情况的能力
五、for循环
1.不可在for循环体内修改循环变量,防止for循环失去控制
2.建议for语句的循环控制变量的取值采用“半开半闭区间”的写法,原因有三:

1>>当循环初始值为0时,循环条件既是循环次数
2>>当循环初始值不为0时,方便计算循环次数(直接用初始值和条件相减即可),例如for( I = 6; I < 10; i++),循环次数10-6=4次。
3>>方便进行下标计算。
3.不要随意省略for循环中的三组条件,可能出现意想不到的结果。
如下图省略初识化条件后只输出三次hehe,因为 j 不会重新初始化为0

六、while循环
在do循环和while循环中,continue会直接跳转到条件判定处。而在for循环中,continue会跳转到循环调整(更新)处。
1.continue跳过for循环,会跳转到循环调整(更新)处;
continue跳过do循环或while循环,会直接跳转到条件判定处。可能跳过循环调整,直接进行条件判断而造成死循环;
因此在while循环中使用continue时要注意循环调整语句应放在continue之前。
2.While(a==b && a && b)---->While(a==b && a)
//判断a和b时证明a==b为真,因此只需判断a,b中的任意一个即可
3.控制循环次数
while(n)n--;//循坏n次,循环结束后n=0
While(n--)//循坏n次,循环结束后n=-1
While(--n)//循环n-1次,循环结束后n=0
4.控制指针移动
while(*dest++);
//当*dest==0时循环停止,但dest会移动到下一位置
while(*dest)dest++;
//当*dest==0时循环停止,dest不会移动到下一位置
while(*dest++ = *src++)
//当*src==0时循环停止,0被赋给了*dest,但dest和src会移动到下一位置
while(*dest=*src){dest++;src++}
//当*src==0时循环停止,0被赋给了*dest,dest和src不会移动到下一位置
while(*src){*dest=*src;dest++;src++}
//当*src==0时循环停止,0不会被赋给*dest,dest和src不会移动到下一位置
七、循环语句的效率
1.在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少CPU 跨切循环层的次数。

2.如果循环体内存在逻辑判断,并且循环次数很大,宜将逻辑判断移到循环体的外面。否则逻辑判断老是打断循环“流水线”作业,使得编译器不能对循环进行优化处理,降低了效率。

七、goto语句
1.主要用于从多层循环体中直接跳出。
2.goto语句只能在一个函数范围内跳转,不能跨函数使用。
返回专栏目录![]() https://blog.csdn.net/zty857016148/article/details/127068555
https://blog.csdn.net/zty857016148/article/details/127068555

















 3234
3234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











