







Linux进程、线程问题
2010年8月15日,今天研究的是Linux的进程管理,昨天是内存寻址,感慨颇深啊,《深入理解Linux内核》这本书真是浪得虚名,根本没有说到问题的本质,一些概念的由来、定义、区别以及联系,技术的原理,运行过程,整体结构,各部分衔接等等问题统统没有说明白,甚至根本没说,全书都是Linux的数据结构,及各种变量,接口函数,却根本没说是什么,为什么。对于新手来说简直是灾难,我看完之后发觉什么都不知道,跟他妈没看一样,根本不理解,没办法去差别的资料或者网上搜索,在网上Baidu、Google了一天,终于搞明白了Linux的进程、线程到底是怎么回事,现将网上的一些文章加以修改,加入我的理解。可能有些地方不准确,希望大家指正。其实以下基本都是摘自网上的文章,我只是负责整理,原作者不要告我侵权啊。
一.定义
关于进程、轻量级进程、线程、用户线程、内核线程的定义,这个很容易找到,但是看完之后你可以说你懂了,但实际上你真的明白了么?
在现代操作系统中,进程支持多线程。进程是资源管理的最小单元;而线程是程序执行的最小单元。一个进程的组成实体可以分为两大部分:线程集合和资源集合。进程中的线程是动态的对象;代表了进程指令的执行。资源,包括地址空间、打开的文件、用户信息等等,由进程内的线程共享。线程有自己的私有数据:程序计数器,栈空间以及寄存器。
传统进程的缺点
现实中有很多需要并发处理的任务,如数据库的服务器端、网络服务器、大容量计算等。一个任务是一个进程,传统的UNIX进程是单线程(执行流)的,单线程意味着程序必须是顺序执行,单个任务不能并发;既在一个时刻只能运行在一个处理器上,因此不能充分利用多处理器框架的计算机。如果采用多进程的方法,即把一个任务用多个进程解决,则有如下问题:
a. fork一个子进程的消耗是很大的,fork是一个昂贵的系统调用,即使使用现代的写时复制(copy-on-write)技术。
b. 各个进程拥有自己独立的地址空间,进程间的协作需要复杂的IPC技术,如消息传递和共享内存等。
多线程的优缺点
线程:其实可以先简单理解成cpu的一个执行流,指令序列。多支持多线程的程序(进程)可以取得真正的并行(parallelism),且由于共享进程的代码和全局数据,故线程间的通信是方便的。它的缺点也是由于线程共享进程的地址空间,因此可能会导致竞争,因此对某一块有多个线程要访问的数据需要一些同步技术。
轻量级进程LWP
既然称作轻量级进程,可见其本质仍然是进程,与普通进程相比,LWP与其它进程共享所有(或大部分)逻辑地址空间和系统资源,一个进程可以创建多个LWP,这样它们共享大部分资源;LWP有它自己的进程标识符,并和其他进程有着父子关系;这是和类Unix操作系统的系统调用vfork()生成的进程一样的。LWP由内核管理并像普通进程一样被调度。Linux内核是支持LWP的典型例子。Linux内核在 2.0.x版本就已经实现了轻量进程,应用程序可以通过一个统一的clone()系统调用接口,用不同的参数指定创建轻量进程还是普通进程,通过参数决定子进程和父进程共享的资源种类和数量,这样就有了轻重之分。在内核中, clone()调用经过参数传递和解释后会调用do_fork(),这个核内函数同时也是fork()、vfork()系统调用的最终实现。
在大多数系统中,LWP与普通进程的区别也在于它只有一个最小的执行上下文和调度程序所需的统计信息,而这也是它之所以被称为轻量级的原因。
因为LWP之间共享它们的大部分资源,所以它在某些应用程序就不适用了;这个时候就要使用多个普通的进程了。例如,为了避免内存泄漏(a process can be replaced by another one)和实现特权分隔(processes can run under other credentials and have other permissions)。
用户线程
这里的用户线程指的是完全建立在用户空间的线程库,用户线程的建立,同步,销毁,调度完全在用户空间完成,不需要内核的帮助。因此这种线程的操作是极其快速的且低消耗的。
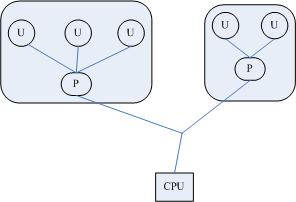
上图是最初的一个用户线程模型,从中可以看出,进程中包含线程,用户线程在用户空间中实现,内核并没有直接对用户线程进程调度,内核的调度对象和传统进程一样,还是进程本身,内核并不知道用户线程的存在。用户线程之间的调度由在用户空间实现的线程库实现。
这种模型对应着恐龙书中提到的多对一线程模型,其缺点是一个用户线程如果阻塞在系统调用中,则整个进程都将会阻塞。
内核线程
用户态线程和内核态线程;主要的区分就是“谁来管理”线程,用户态是用户管理,内核态是内核管理(但肯定要提供一些API,例如创建)。
简单对比两者优劣势:
1)可移植性:因为ULT完全在用户态实现线程,因此也就和具体的内核没有什么关系,可移植性方面ULT略胜一筹;
2)可扩展性:ULT是由用户控制的,因此扩展也就容易;相反,KLT扩展就很不容易,基本上只能受制于具体的操作系统内核;
3)性能:由于ULT的线程是在用户态,对应的内核部分还是一个进程,因此ULT就没有办法利用多处理器的优势,而KLT就可以通过调度将线程分布在多个处理上运行,这样KLT的性能高得多;另外,一个ULT的线程阻塞,所有的线程都阻塞,而KLT一个线程阻塞不会影响其它线程。
4)编程复杂度:ULT的所有管理工作都要由用户来完成,而KLT仅仅需要调用API接口,因此ULT要比KLT复杂的多。
小结
其实最初根本没有线程的概念,只有进程,一个任务一个进程一个执行流,多任务处理机就是多进程。后来提出线程的概念,但是要如何去实现,这里就有很多种实现方法了,文章看到这里,可以想到两种实现方法,一种就是上面所说的用户线程的方法,其优缺点上文以简述;再有就是用轻量级进程去模拟,即我们可以把LWP看成是一个线程。就应为这个使得线程和进程的概念混淆了,至少我觉得很多人其实根本就不知道,至少我以前不知道,有人说系统调度单位是进程,又有人说是线程,其实系统调度的单位一直就没有改变,只是后来部分线程和进程的界限模糊了,至少上文中的用户线程绝对不是调度对象,LWP模拟的线程却是调度对象。
二.Linux线程发展
这个对于理解Linux多线程很有帮助,可惜《深入理解Linux内核》这本书只字未提,根本没讲Linux多线程的机理,至少我没看懂。
一直以来, linux内核并没有线程的概念. 每一个执行实体都是一个task_struct结构, 通常称之为进程. Linux内核在2.0.x版本就已经实现了轻量进程,应用程序可以通过一个统一的clone()系统调用接口,用不同的参数指定创建轻量进程还是普通进程。在内核中, clone()调用经过参数传递和解释后会调用do_fork(),这个核内函数同时也是fork()、vfork()系统调用的最终实现。后来为了引入多线程,Linux2.0~2.4实现的是俗称LinuxThreads的多线程方式,到了2.6,基本上都是NPTL的方式了。下面我们分别介绍。
LinuxThreads
注:以下内容主要参考“杨沙洲 (mailto:pubb@163.net?subject=Linux 线程实现机制分析&cc=pubb@163.net)国防科技大学计算机学院”的“Linux 线程实现机制分析”。
linux 2.6以前, pthread线程库对应的实现是一个名叫linuxthreads的lib.这种实现本质上是一种LWP的实现方式,即通过轻量级进程来模拟线程,内核并不知道有线程这个概念,在内核看来,都是进程。
Linux采用的“一对一”的线程模型,即一个LWP对应一个线程。这个模型最大的好处是线程调度由内核完成了,而其他线程操作(同步、取消)等都是核外的线程库函数完成的。
linux上的线程就是基于轻量级进程, 由用户态的pthread库实现的.使用pthread以后, 在用户看来, 每一个task_struct就对应一个线程, 而一组线程以及它们所共同引用的一组资源就是一个进程.但是, 一组线程并不仅仅是引用同一组资源就够了, 它们还必须被视为一个整体.
对此, POSIX标准提出了如下要求:
1, 查看进程列表的时候, 相关的一组task_struct应当被展现为列表中的一个节点;
2, 发送给这个"进程"的信号(对应kill系统调用), 将被对应的这一组task_struct所共享, 并且被其中的任意一个"线程"处理;
3, 发送给某个"线程"的信号(对应pthread_kill), 将只被对应的一个task_struct接收, 并且由它自己来处理;
4, 当"进程"被停止或继续时(对应SIGSTOP/SIGCONT信号), 对应的这一组task_struct状态将改变;
5, 当"进程"收到一个致命信号(比如由于段错误收到SIGSEGV信号), 对应的这一组task_struct将全部退出;
6, 等等(以上可能不够全);
在LinuxThreads中,专门为每一个进程构造了一个管理线程,负责处理线程相关的管理工作。当进程第一次调用pthread_create()创建一个线程的时候就会创建并启动管理线程。然后管理线程再来创建用户请求的线程。也就是说,用户在调用pthread_create后,先是创建了管理线程,再由管理线程创建了用户的线程。
linuxthreads利用前面提到的轻量级进程来实现线程, 但是对于POSIX提出的那些要求, linuxthreads除了第5点以外, 都没有实现(实际上是无能为力):
1, 如果运行了A程序, A程序创建了10个线程, 那么在shell下执行ps命令时将看到11个A进程, 而不是1个(注意, 也不是10个, 下面会解释);
2, 不管是kill还是pthread_kill, 信号只能被一个对应的线程所接收;
3, SIGSTOP/SIGCONT信号只对一个线程起作用;
还好linuxthreads实现了第5点, 我认为这一点是最重要的. 如果某个线程"挂"了, 整个进程还在若无其事地运行着, 可能会出现很多的不一致状态. 进程将不是一个整体, 而线程也不能称为线程. 或许这也是为什么linuxthreads虽然与POSIX的要求差距甚远, 却能够存在, 并且还被使用了好几年的原因吧~
但是, linuxthreads为了实现这个"第5点", 还是付出了很多代价, 并且创造了linuxthreads本身的一大性能瓶颈.
接下来要说说, 为什么A程序创建了10个线程, 但是ps时却会出现11个A进程了. 因为linuxthreads自动创建了一个管理线程. 上面提到的"第5点"就是靠管理线程来实现的.
当程序开始运行时, 并没有管理线程存在(因为尽管程序已经链接了pthread库, 但是未必会使用多线程).
程序第一次调用pthread_create时, linuxthreads发现管理线程不存在, 于是创建这个管理线程. 这个管理线程是进程中的第一个线程(主线程)的儿子.
然后在pthread_create中, 会通过pipe向管理线程发送一个命令, 告诉它创建线程. 即是说, 除主线程外, 所有的线程都是由管理线程来创建的, 管理线程是它们的父亲.
于是, 当任何一个子线程退出时, 管理线程将收到SIGUSER1信号(这是在通过clone创建子线程时指定的). 管理线程在对应的sig_handler中会判断子线程是否正常退出, 如果不是, 则杀死所有线程, 然后自杀.
那么, 主线程怎么办呢? 主线程是管理线程的父亲, 其退出时并不会给管理线程发信号. 于是, 在管理线程的主循环中通过getppid检查父进程的ID号, 如果ID号是1, 说明父亲已经退出, 并把自己托管给了init进程(1号进程). 这时候, 管理线程也会杀掉所有子线程, 然后自杀.
可见, 线程的创建与销毁都是通过管理线程来完成的, 于是管理线程就成了linuxthreads的一个性能瓶颈.
创建与销毁需要一次进程间通信, 一次上下文切换之后才能被管理线程执行, 并且多个请求会被管理线程串行地执行.
这种通过LWP的方式来模拟线程的实现看起来还是比较巧妙的,但也存在一些比较严重的问题:
1)线程ID和进程ID的问题
按照POSIX的定义,同一进程的所有的线程应该共享同一个进程和父进程ID,而Linux的这种LWP方式显然不能满足这一点。
2)信号处理问题
异步信号是以进程为单位分发的,而Linux的线程本质上每个都是一个进程,且没有进程组的概念,所以某些缺省信号难以做到对所有线程有效,例如SIGSTOP和SIGCONT,就无法将整个进程挂起,而只能将某个线程挂起。
3)线程总数问题
LinuxThreads将每个进程的线程最大数目定义为1024,但实际上这个数值还受到整个系统的总进程数限制,这又是由于线程其实是核心进程。
4)管理线程问题
管理线程容易成为瓶颈,这是这种结构的通病;同时,管理线程又负责用户线程的清理工作,因此,尽管管理线程已经屏蔽了大部分的信号,但一旦管理线程死亡,用户线程就不得不手工清理了,而且用户线程并不知道管理线程的状态,之后的线程创建等请求将无人处理。
5)同步问题
LinuxThreads中的线程同步很大程度上是建立在信号基础上的,这种通过内核复杂的信号处理机制的同步方式,效率一直是个问题。
6)其他POSIX兼容性问题
Linux中很多系统调用,按照语义都是与进程相关的,比如nice、setuid、setrlimit等,在目前的LinuxThreads中,这些调用都仅仅影响调用者线程。
7)实时性问题
线程的引入有一定的实时性考虑,但LinuxThreads暂时不支持,比如调度选项,目前还没有实现。不仅LinuxThreads如此,标准的Linux在实时性上考虑都很少
NPTL
到了linux 2.6, glibc中有了一种新的pthread线程库--NPTL(Native POSIX Threading Library).
本质上来说,NPTL还是一个LWP的实现机制,但相对原有LinuxThreads来说,做了很多的改进。下面我们看一下NPTL如何解决原有LinuxThreads实现机制的缺陷
NPTL实现了前面提到的POSIX的全部5点要求. 但是, 实际上, 与其说是NPTL实现了, 不如说是linux内核实现了.
在linux 2.6中, 内核有了线程组的概念, task_struct结构中增加了一个tgid(thread group id)字段.
如果这个task是一个"主线程", 则它的tgid等于pid, 否则tgid等于进程的pid(即主线程的pid).
在clone系统调用中, 传递CLONE_THREAD参数就可以把新进程的tgid设置为父进程的tgid(否则新进程的tgid会设为其自身的pid).
类似的XXid在task_struct中还有两 个:task->signal->pgid保存进程组的打头进程的pid、task->signal->session保存会话 打头进程的pid。通过这两个id来关联进程组和会话。
有了tgid, 内核或相关的shell程序就知道某个tast_struct是代表一个进程还是代表一个线程, 也就知道在什么时候该展现它们, 什么时候不该展现(比如在ps的时候, 线程就不要展现了).
而getpid(获取进程ID)系统调用返回的也是tast_struct中的tgid, 而tast_struct中的pid则由gettid系统调用来返回.
在执行ps命令的时候不展现子线程,也是有一些问题的。比如程序a.out运行时,创建 了一个线程。假设主线程的pid是10001、子线程是10002(它们的tgid都是10001)。这时如果你kill 10002,是可以把10001和10002这两个线程一起杀死的,尽管执行ps命令的时候根本看不到10002这个进程。如果你不知道linux线程背 后的故事,肯定会觉得遇到灵异事件了。
为了应付"发送给进程的信号"和"发送给线程的信号", task_struct里面维护了两套signal_pending, 一套是线程组共享的, 一套是线程独有的.
通过kill发送的信号被放在线程组共享的signal_pending中, 可以由任意一个线程来处理; 通过pthread_kill发送的信号(pthread_kill是pthread库的接口, 对应的系统调用中tkill)被放在线程独有的signal_pending中, 只能由本线程来处理.
当线程停止/继续, 或者是收到一个致命信号时, 内核会将处理动作施加到整个线程组中.
NGPT
上面提到的两种线程库使用的都是内核级线程(每个线程都对应内核中的一个调度实体), 这种模型称为1:1模型(1个线程对应1个内核级线程);
而NGPT则打算实现M:N模型(M个线程对应N个内核级线程), 也就是说若干个线程可能是在同一个执行实体上实现的.
线程库需要在一个内核提供的执行实体上抽象出若干个执行实体, 并实现它们之间的调度. 这样被抽象出来的执行实体称为用户级线程.
大体上, 这可以通过为每个用户级线程分配一个栈, 然后通过longjmp的方式进行上下文切换. (百度一下"setjmp/longjmp", 你就知道.)
但是实际上要处理的细节问题非常之多. 目前的NGPT好像并没有实现所有预期的功能, 并且暂时也不准备去实现.
用户级线程的切换显然要比内核级线程的切换快一些, 前者可能只是一个简单的长跳转, 而后者则需要保存/装载寄存器, 进入然后退出内核态. (进程切换则还需要切换地址空间等.)
而用户级线程则不能享受多处理器, 因为多个用户级线程对应到一个内核级线程上, 一个内核级线程在同一时刻只能运行在一个处理器上.
不过, M:N的线程模型毕竟提供了这样一种手段, 可以让不需要并行执行的线程运行在一个内核级线程对应的若干个用户级线程上, 可以节省它们的切换开销.据说一些类UNIX系统(如Solaris)已经实现了比较成熟的M:N线程模型, 其性能比起linux的线程还是有着一定的优势.















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









