






集合
集合—>容器
数组:同一种类型,长度固定不可变,每一个元素都有索引,索引从0开始
数组在实际使用时有哪些不方便?
长度不可变
现实中程序运行时数据量是可以改变的,需要能够满足可变的需求,
有时想存储不可重复的数据,有时想对元素进行排序
所以在Java中为我们提供了许多不同特征的容器类
本章主体就是学习java给我们提供的不同的容器类,来实现更为丰富的数据存储
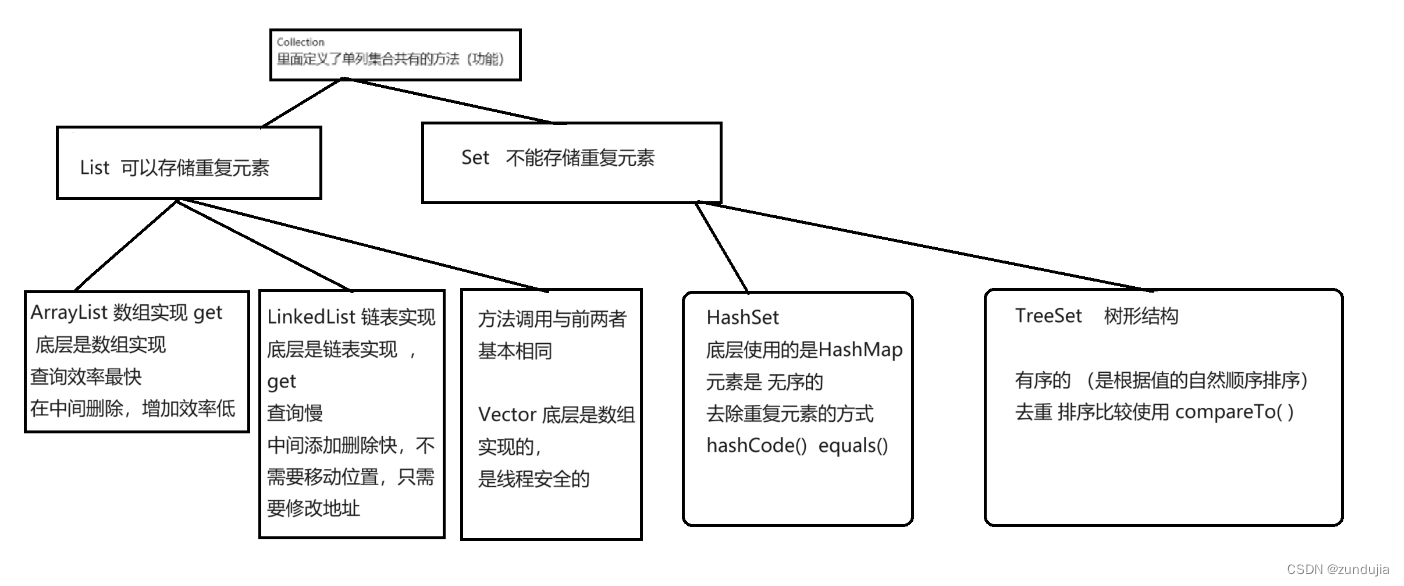
List接口及实现类
ArrayList 可以保存重复元素,底层是数组实现,添加元素的类型是可以任意的
虽然集合中默认是可以添加任意数据类型,但是后续处理时,会出现类型转换问题
所以Java中的集合类都支持自定义类型(泛型,把类型当作参数传递)
底层是一个数组,默认长度是10,当数组装满时,会自动扩容到原来的1.5倍
arrayList.add(“a”);//向末尾添加元素,会自动扩容
arrataList.add( 1, “x”);//向指定的位置添加元素,位置从0开始 到第size(实际装入的元素的个数)
arrayList.remove(“b”);//根据元素的内容删除数据,只删除匹配的第一个元素
String s = arrayList.remove(index:2); //删除并返回指定位置上的元素
ArrayList<String>arrayList = new ArrayList<>();
//定义时,为集合中可以存储的数据设定一个类型,必须是类类型
//好处:一个集合中只能存储一种相同数据类型,后续处理方便了
arrayList.add(); //只能存储String 类型
ArrayList alist = new ArrayList();
alist.add(1);
alist.clear(); //清空所有元素
~.contains(“x”);//是否包含该元素
~.get(3);//底层是从数组中获取元素,速度最快
~.indexOf(“b”);//返回元素首次出现的索引
~.lastIndexOf(“b”);
~.isEmpty();//判断集合中的元素是否为空,若为空—true;否则—false;
~.set( 1, “A”); //替换指定位置的元素
~.size(); //获得集合中实际元素的个数,也可以说是集合的长度
1、for循环
for(int I = 0; i<arrayList.size();i++){
sout(“arrayList.get(i)”);
}
.
For(int I = 0 ; i<arrayList.size();i++){
If(arrrayList.gei(i).equals(“a”)){
arrayList.remove(i);
i--;}}
//for循环的时候,是支持从集合中删除元素的,但是删除后,
后面的元素会向前移动,需要控制索引
2、增强for循环
For(String s :arrayList){
Sout(s);
}
//增强for循环在删除元素的过程中不允许删除元素
3、使用迭代器进行遍历
迭代器1
Iterator<String>iterator = arrayList.iterator();
While (iterator.hasNext()){
String s = iterator.next();
Sout(s);
}
//迭代器删除元素
Iterator<String> it = arrayList1.iterator();
While(it.hasNext()){
String e = it.next();
If(e.equals(“a”)){
It.remove();//迭代器中的删除方法 底层有一个计数器,删除元素时,计数器会自动回退
}
}
迭代器2
.listIterator();默认是从第0个位置开始遍历,只是从前向后遍历
.listIterator(int index) 从指定的位置开始向前/向后遍历
ListIterator<String> listiterator = arrayList1.listIterator( index: ___ );
While(listIterator.hasPrevious(){
String e = listIterator.previous();
Sout(e);
}
LinkedList类
//List接口实现类
底层是链表实现,每一个数据封装在一个Node对象中
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add(“a”);
~.add(“b”);//向链表末尾添加元素
Sout(~.get(1));
//从链表中获取指定位置的元素(从头或者从尾开始查找,效率低于ArraryList)
~.add(index:2,element:”x”);//向指定的位置添加元素
~.clear();
~.contains(“a”);
~.remove(“b”);/~remove(2);
~.remove();//删除并返回第一个节点内容
~.removeLast();//删除并返回最后一个元素
Vector 接口及实现类
//底层也是用数组实现
是多线程安全的
Set 接口及实现类
不包含重复元素的集合,是无序的,set中的元素是没有索引的
HashSet
元素是无序的(既不是添加的顺序,也不是按元素的的自然顺序)
向HashSet中添加元素时,是如何判断元素是否重复的?
添加元素时 调用equals() 判断,效率低(一个一个字符判断)
底层用到HashCode () 和equals() 方法
“xxxxxxxxx” 用内容计算一个hash值(整数),用hash值比较速度快
但是hash 是不安全的,有可能内容不同,计算的hash值相同,
当hash 值相同时,调用equals() 方法判断内容是否相等
这样既效率提高了 也保证安全
HashSet<String> set = new HashSet<>();
Set.addd(“a”);
Set.add(“x”);
Set.add(“h”);
Set.add(“b”);
Set.add(“a”);

Set..clear();//清空元素
.isEmpty();
~.remove()//删除没有返回值

//添加时,判断会调用hashCode()计算hash值,没有hashCode(), 会调用父类中的hashCode()方法,Object类中的public native int hashCode();Native本地方法(操作系统提供的)
所以只要是new出来的,调用Object类中的hash值,是内存地址,肯定不相同
如果我们想要对象中的内容相等就判定为重复元素,
就必须在我们的类中重写hashCode() equals() 用对象中的内容来计算hash值
TreeSet
底层是树型结构
添加进来的元素可以排序(有序的 不是添加的顺序,是元素的自然顺序)
Set.first()//删除并返回第一个元素
~.pool
双列集合()
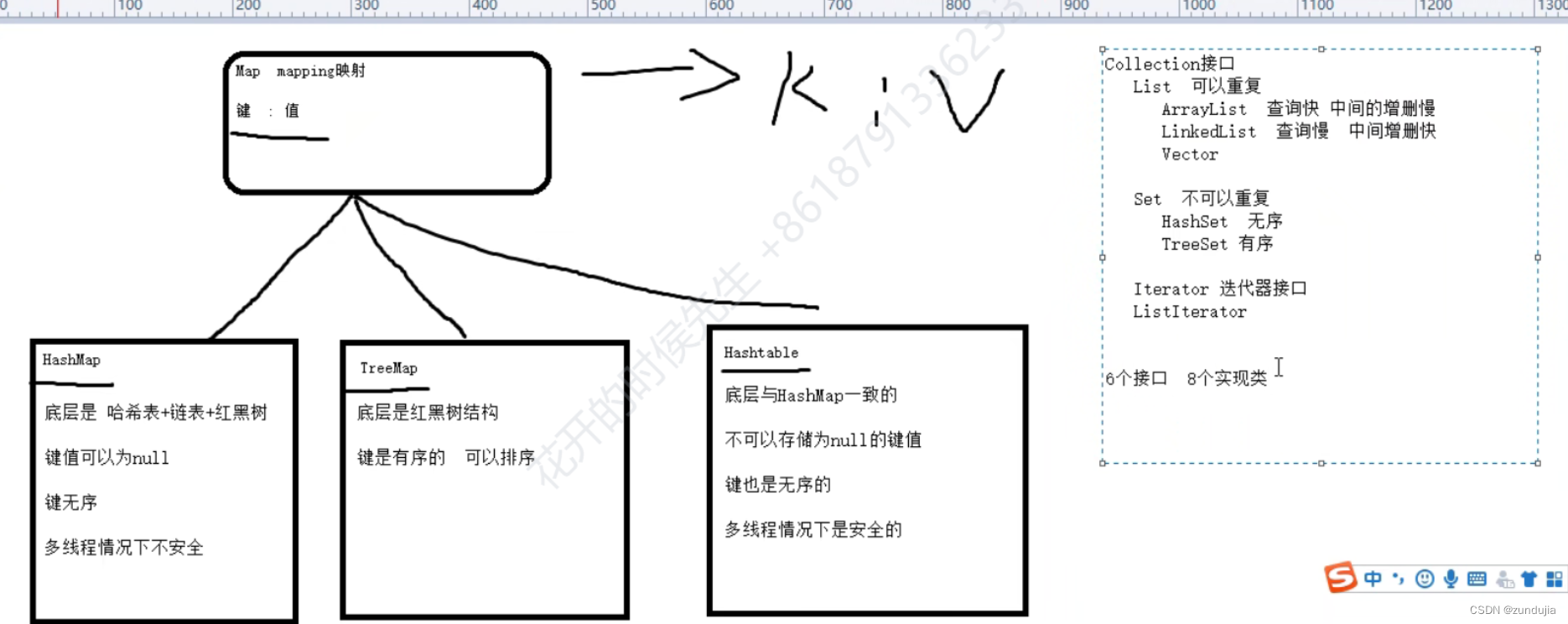
Map mapping 映射
键 : 值
Map
键 值对
键不能重复 值可以重复
一个键映射到一个值
HashMap<String,String>mao = new HashMap<>();
Map.put( key:”c” , value: “cc”);
Map.put( key:”x” , value: “xx”);
Map.put( key:”a” , value: “aa”);
Map.put( key:”s” , value: “ss”);
Map.put( key:”c” , value: “CC”);

Sout(map.get(“x”)); //通过key获取到key对应的value
Map.clear(); //删除所有的键值映射
~.Remove(“x“);//删除键值映射并返回键所对应的值
~.containsValue(“hh”);//判断值是否存在
~.~key(“xx“);//判断键是否存在
~.isEmpty();判断是否是空的
~.size();
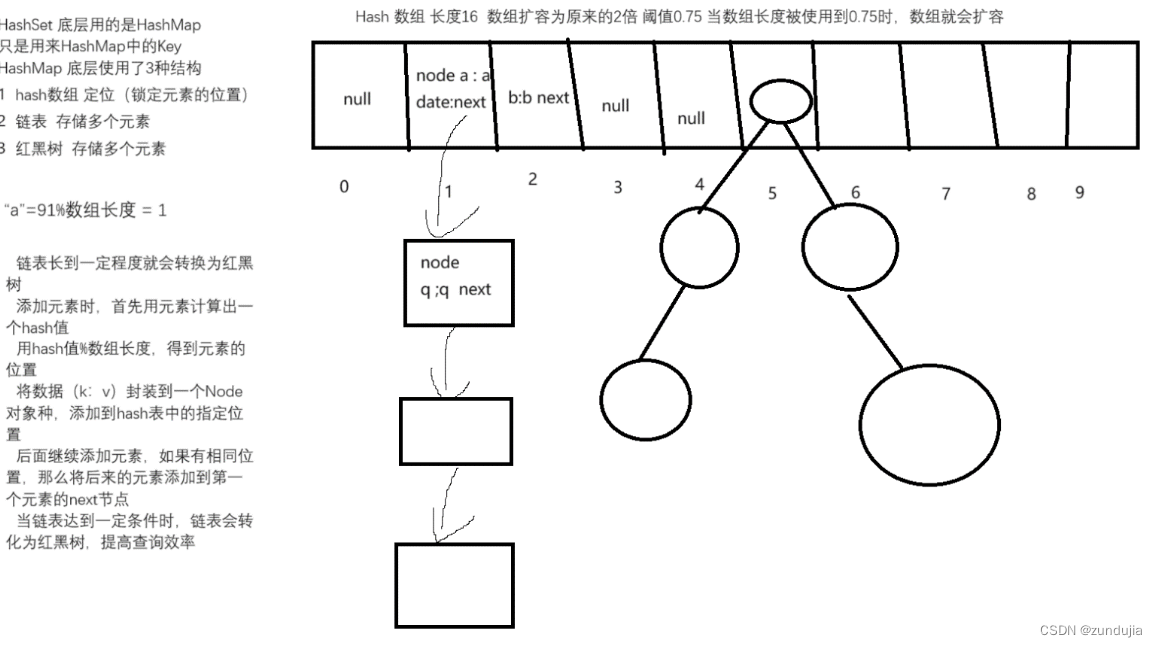
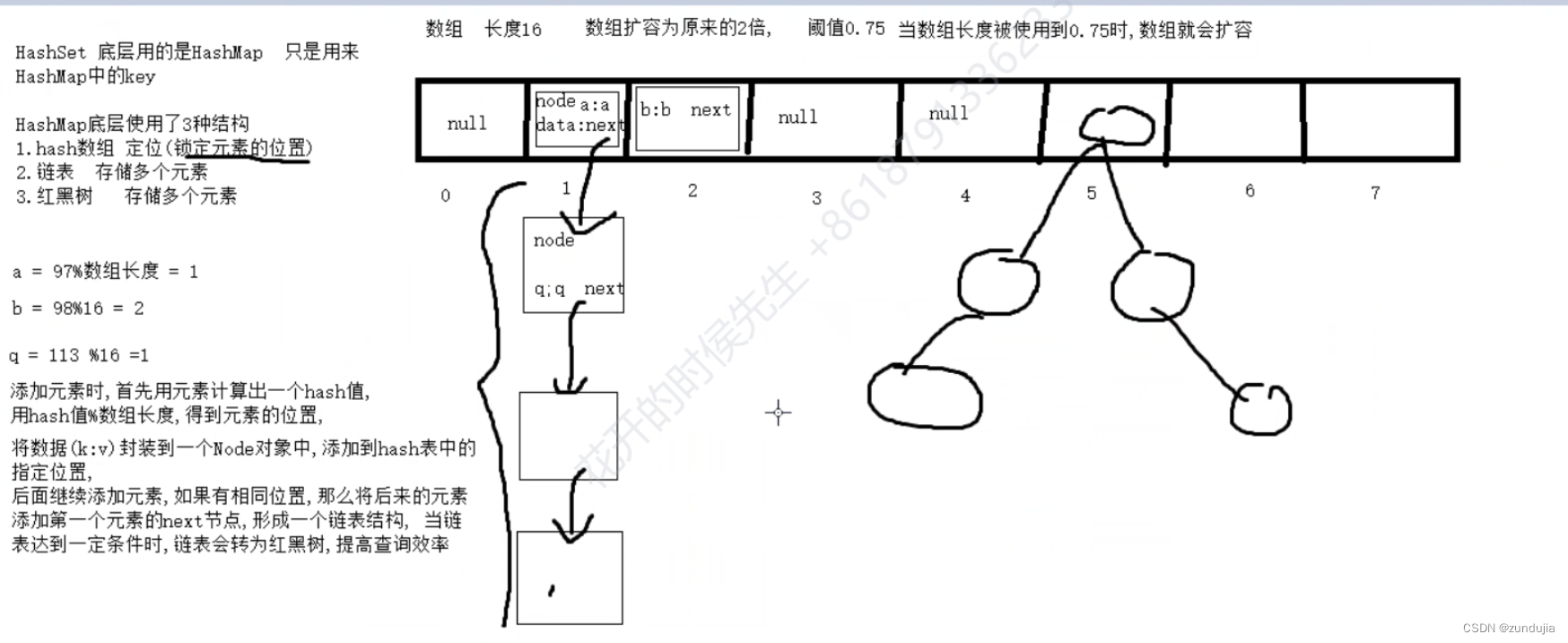
HashSet 底层用的是HashMap 只是用来HashMap中的Key
HashMap 底层使用了3种结构
hash数组 定位(锁定元素的位置)
链表 存储多个元素
红黑树 存储多个元素
Hash 数组 长度16 数组扩容为原来的2倍 阈值0.75 当数组长度被使用到0.75时,数组就会扩容
“a”=91%数组长度 = 1
链表长到一定程度就会转换为红黑树
添加元素时,首先用元素计算出一个hash值
用hash值%数组长度,得到元素的位置
将数据(k:v)封装到一个Node对象种,添加到hash表中的指定位置
后面继续添加元素,如果有相同位置,那么将后来的元素添加到第一个元素的next节点
当链表达到一定条件时,链表会转化为红黑树,提高查询效率
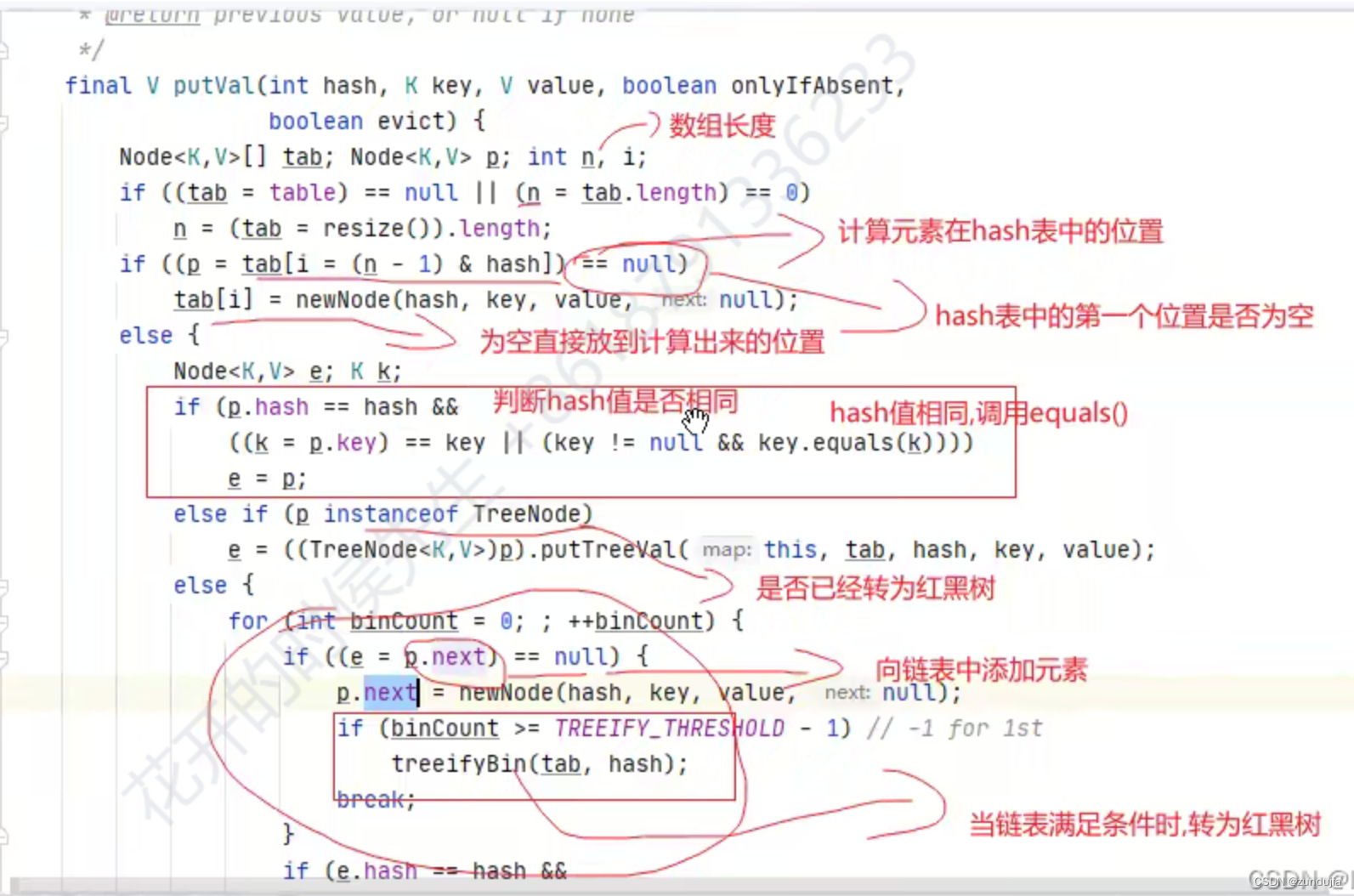
Map
键值对
键不能重复 值可以重复
TreeMap
底层使用的是树形结构
键可以排序(有序),键的类型必须实现Comparable接口
TreeMap<String , String > tmap = new TreeMap<>();
tmap.put(“c”,”c”);
tmap.put(“a”,”a”);
Hashtable
底层结构与HashMap 相同,但是是线程安全的 方法都添加了synchronized关键字
Hashtable 不允许存储为null的键和值
HashMap 可以存储一个为null的键,值也可以为null
Hashtable<String , String > hmap = new Hashtable<>();
hmap.put(“x”,”x”);
hmap.put(“a”,”a”);
hmap.put(“g”,”g”);
hmap.put(“r”,”r”);
hmap.put(“x”,”x”);
sout(hmap);
Map 遍历的两种方式
//方式1: KeySet() 获取到所有的键 遍历键的集合
Set<String> keyset = map.keySet();
for(String key:keyset){
sout(key+”:”+map.get(key));
}
//方式2:通过entrtSet() 获取到一个Entry类型的集合,Entry中放有键值
Set<Map.Entry<String,String>> entries = map.entrySet();
for(Map.Entry entry: entries){
sout(entry.getKey()+”:”+entry.getValue());
}
Collections类
Collections 是集合类的工具类 ,与数组的工具类Arrays 类似

// 类型…… 参数名 可变长度的参数,本质是数组
一个参数列表中,只能有一个可变长度的参数 ,而且必须放在参数列表的末尾
泛型
在定义时,为类指定类型 在编译期间添加数据时 进行类型校验
泛型的类型参数只能是类类型
泛型的类型参数可以有多个
如果没有定义具体的类型,默认为Object
//<A> 可以是任意的标识符,可以定义多个泛型
类型不确定,可以把类型当作参数传进来
Public class Demo<T>{
<T> account; //1022861 rewur29832
//getter / setter方法
Main{
Demo<String> demo1 = new Demo<>();
demo1setAccount(“123asd”);
demo1.getAccount();
}
}
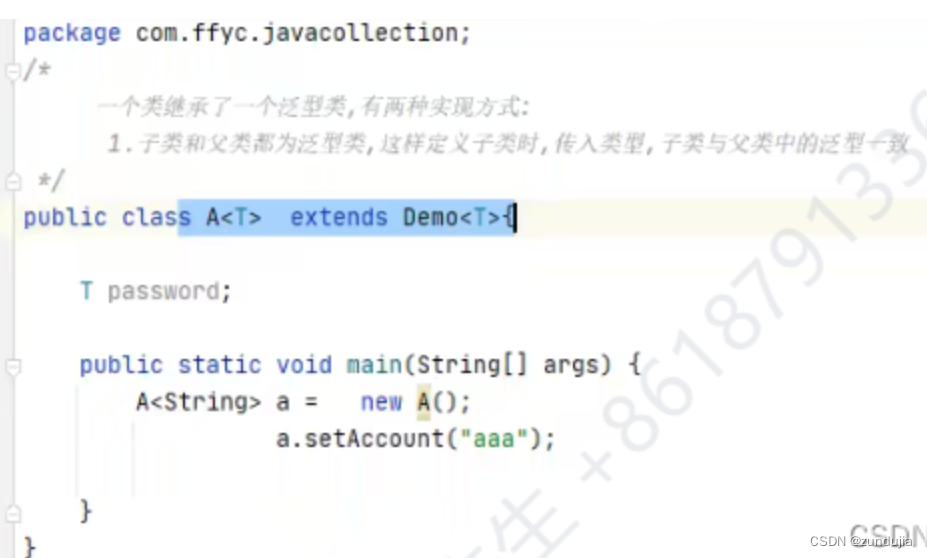
一个类继承了一个泛型类,有两种实现方式:
子类和父类都为泛型类,这样定义子类时,传入类型,子类与父类中的泛型一致
子类不是泛型类,这时候父类的泛型类型必须是确定的

泛型擦除:
虽然我们定义时,定义了明确的类型,但是实际底层处理时,统一都转为Object类型
与之前的代码兼容,泛型的意义在于,编译期间添加获取元素时,类型都是统一的















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









