







目录
1.1 什么是Spark(官网:http://spark.apache.org)
4.2.2 在spark shell中编写WordCount程序
1 Spark概述
hadoop(hdfs,mapreduce,yarn) 框架 分布式 大量数据的分析处理
hive(sql à mapreduce)
spark 框架 分布式(分而治之) 大量数据的分析处理 数据处理引擎
spark(sparkcore spark sql spark streaming mllib graphx)
1.1 什么是Spark(官网:http://spark.apache.org)
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
分布式 框架 基于内存 计算引擎
spark2.2.1
spark1.0 14
spark 1.3 1.4 1.5 1.6 spark2.0
为什么要有集群: 多台机器组成集群
硬件 非常廉价
1.2 为什么要学习Spark
mapreduce 链: 多个mapredue任务 第一个任务的输出结果 是第一个任务的输入
mapreduce 读 – 处理 - 写磁盘 - 读 - 处理 - 写
spark 读 -- 处理 -- 处理 xxx - 写
中间结果输出:基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。出于任务管道承接的考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果
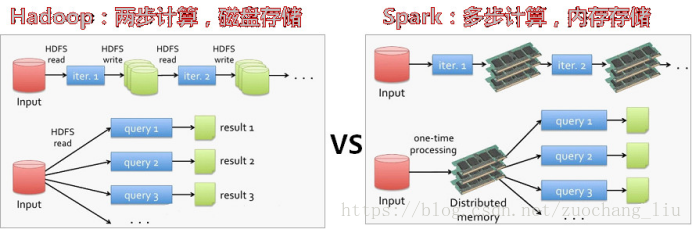
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,(spark与hadoop的差异)具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)
其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错。
hadoop 两个阶段 map reduce
最后,Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。
支持的运算平台,支持的开发语言更多。
spark 4 种开发语言:
scala,java,python,R
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
hdfs,yarn
1.3 Spark特点
1.3.1 快
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。

1.3.2 易用
Spark支持Java、Python和Scala和R的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。

1.3.3 通用
一站式解决方案
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。

1.3.4 兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。

2 Spark集群安装
2.1 安装
注意:安装spark时,无需安装scala
jdk 必须要 jdk1.8+
2.1.1 下载Spark安装包
上传spark-安装包到Linux上
解压安装包到指定位置
# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C apps/
Spark安装包目录结构:
| bin 可执行脚本 conf 配置文件 data 示例程序使用数据 examples 示例程序 jars 依赖jar包 LICENSE licenses NOTICE python pythonAPI R R语言API README.md RELEASE sbin 集群管理命令 |
2.1.2 机器部署
准备4台Linux服务器,安装好JDK,最低要求2台
hdp-01 192.168.8.11
hdp-02 192.168.8.12
hdp-03 192.168.8.13
hdp-04 192.168.8.14
master:hpd-01
workers: hdp-02 hdp-03 hdp-04
2.1.3 部署standalone集群
确保集群中各节点的防火墙是关闭的。
| 查看防火墙状态 # service iptables status 关闭防火墙 # service iptables stop 永久关闭防火墙 # chkconfig iptables off |
确保主节点到各从节点的免密登录配置好了
从Master节点到worker节点的免密登录
| 在master机器上执行: # ssh-keygen # for i in 2 3 4; do ssh-copy-id hdp-0$i; done |
进入到Spark安装目录
# cd apps/ spark-2.2.0-bin-hadoop2.7
进入conf目录并重命名并修改spark-env.sh.template文件
# cd conf/
# mv spark-env.sh.template spark-env.sh
# vim spark-env.sh
在该配置文件中添加如下配置
| export JAVA_HOME=/usr/local/jdk export SPARK_MASTER_HOST=hdp-01 export SPARK_MASTER_PORT=7077 |
保存退出
重命名并修改slaves.template文件
# mv slaves.template slaves
# vim slaves
在该文件中添加子节点所在的位置(Worker节点)
| hdp-02 hdp-03 hdp-04 |
保存退出
将配置好的Spark文件夹拷贝到其他节点上
单独拷贝:
# scp -r /root/apps/spark-2.2.0-bin-hadoop2.7/ hdp-02:/root/apps/
批量拷贝:
| # cd /root/apps # for i in {2..4};do scp -r spark-2.2.0-bin-hadoop2.7 hdp-0$i:$PWD ;done |
Spark集群配置完毕,目前是1个Master,3个Worker,在Master(hdp-01)上启动Spark集群
2.1.4 启停操作
单独启动master(在master安装节点上):
# start-master.sh
单独启动worker:
在每一台worker节点上执行:
start-slave.sh spark://hdp-01:7077
启动众worker(在Master所在节点上执行)
# start-slaves.sh
这里获取的是是slaves文件中的主机名
分别停止:
# stop-slaves.sh
# stop-master.sh
批量脚本启动:
# start-all.sh
停止:
# stop-all.sh
为了能方便使用,配置一下环境变量:
export SPARK_HOME=/root/apps/spark-2.2.0-bin-hadoop2.7

配置环境变量的注意事项:
hadoop/sbin的目录和spark/sbin可能会有命令冲突:
start-all.sh stop-all.sh
启动后执行jps命令,主节点上有Master进程,其他子节点上有Worker进程,
登录Spark管理界面查看集群状态(主节点):http://hdp-01:8080/

查看机器内存的命令: free -m
默认情况下:spark会占用机器上的所有cores,
memory呢,会默认的使用ram – 1G
默认配置:
http://spark.apache.org/docs/latest/spark-standalone.html

3 spark的部署模式
1,local模式 解压一个spark即可 测试 ,自己练习 –master local 不指定master的时候,就是local模式 local[2] local[*]
2,spark standalone 集群模式 master worker --master spark://hdp-01:7077
3, sprak on yarn 把任务提交给yarn集群 --master yarn
4,spark on mesos 把任务提交给mesos集群
4 执行Spark程序
4.1 执行第一个spark示例程序
spark-submit \
--class org.apache.spark.examples.SparkPi \
/root/apps/spark/examples/jars/spark-examples_2.11-2.2.0.jar 100
该算法是利用蒙特·卡罗算法求PI(圆周率)
当执行测试程序,使用spark-shell,spark的交互式命令行
提交spark程序到spark集群中运行时,spark-submit
4.2 启动Spark Shell
spark-shell 用命令行的方式提交任务到集群的一个客户端。spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
4.2.1 启动spark shell
直接启动spark-shell默认使用的是local模式,和spark集群无关
只要把spark安装包解压了,就可以运行local模式
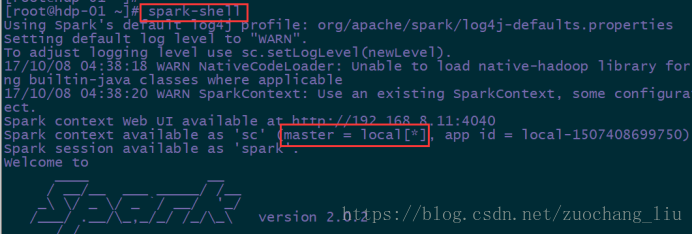
local模式没有指定master地址,仅在本机启动一个进程(SparkSubmit),没有与集群建立联系。但是也可以正常启动spark shell和执行spark shell中的程序
指定集群模式启动:
hdfs://hdp-01:9000
spark的协议URI:spark://hdp-01:7077
# spark-shell --master
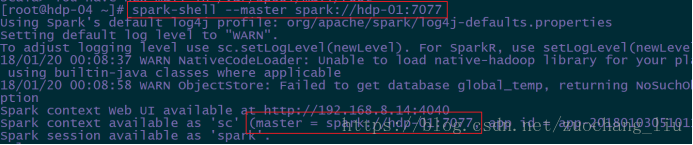
在webUI界面,可以查看到正在运行的程序:

Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
4.2.2 在spark shell中编写WordCount程序
- 首先启动hdfs
- 向hdfs上传一个文件到hdfs://hdp-01:9000/wordcount/input/a.txt
- 在spark shell中用scala语言编写spark程序
scala> sc.textFile("hdfs://hdp-01:9000/wordcount/input/")
spark是懒加载的,所以这里并没有真正执行任务。可使用collect方法快速查看数据。
lazy执行的,只有调用了action方法,才正式开始运行。
scala>sc.textFile("hdfs://hdp-01:9000/wordcount/input/").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
注意:这些flatMap,map等方法是RDD上的方法,要区分于原生的scala方法。
和原生scala的方法名称有的相同,但属于不通的类的方法,底层实现完全不一致。
原生的方法: 对单机的数组或集合进行操作。
RDD上的方法:
RDD是spark的计算模型,RDD上有很多的方法,这些方法通常称为算子,主要有两类算子,一类是transform,一类是action,transform是懒加载的。
scala>sc.textFile("hdfs://hdp-01:9000/wordcount/input/").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://hdp-01:9000/wordcount/outspark1")
- 使用hdfs命令查看结果
# hadoop fs -ls /wordcount/outspark1
说明:
sc是SparkContext对象,该对象是提交spark程序的入口
textFile(hdfs://hdp-01:9000/wordcount/intput/a.txt)是hdfs中读取数据
flatMap(_.split(" "))先map再压平
map((_,1))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile("hdfs://hdp-01:9000/outspark1")将结果写入到hdfs中
spark中的方法很多,这些方法统称为算子。一共有两类算子(transform,action)
spark是懒加载的,transform方法并不会立即执行,只有当程序遇到action的时候才会被执行。collect算子是一个action
collect: 收集数据到本地
4.3 在IDEA中编写WordCount程序
spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中开发程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包的依赖。
4.3.1 scalaAPI的wordcount
1.创建一个项目

2.选择Maven项目,然后点击next
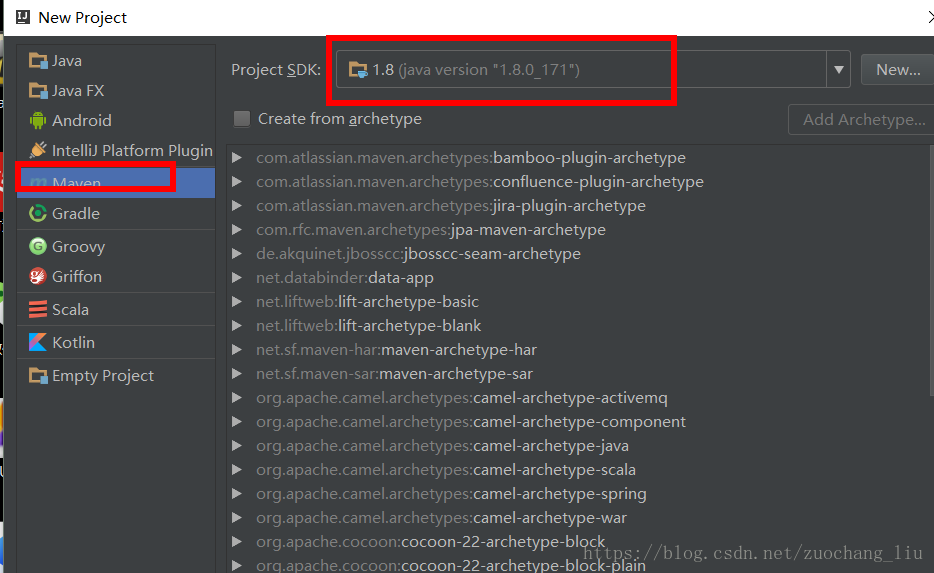
3.填写maven的GAV,然后点击next
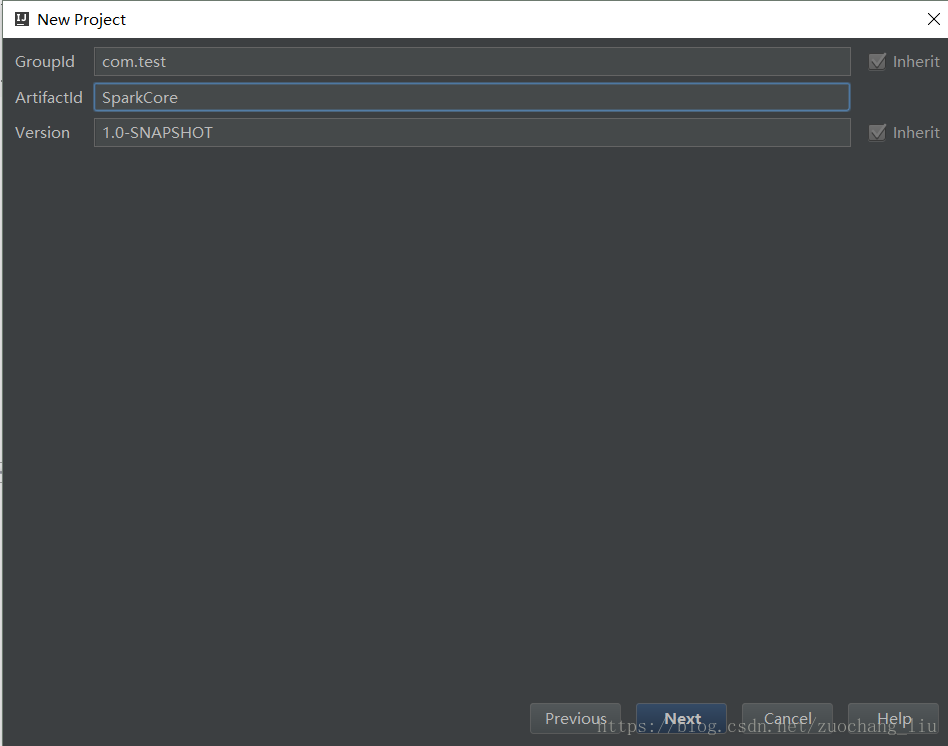
4.填写项目名称,然后点击finish
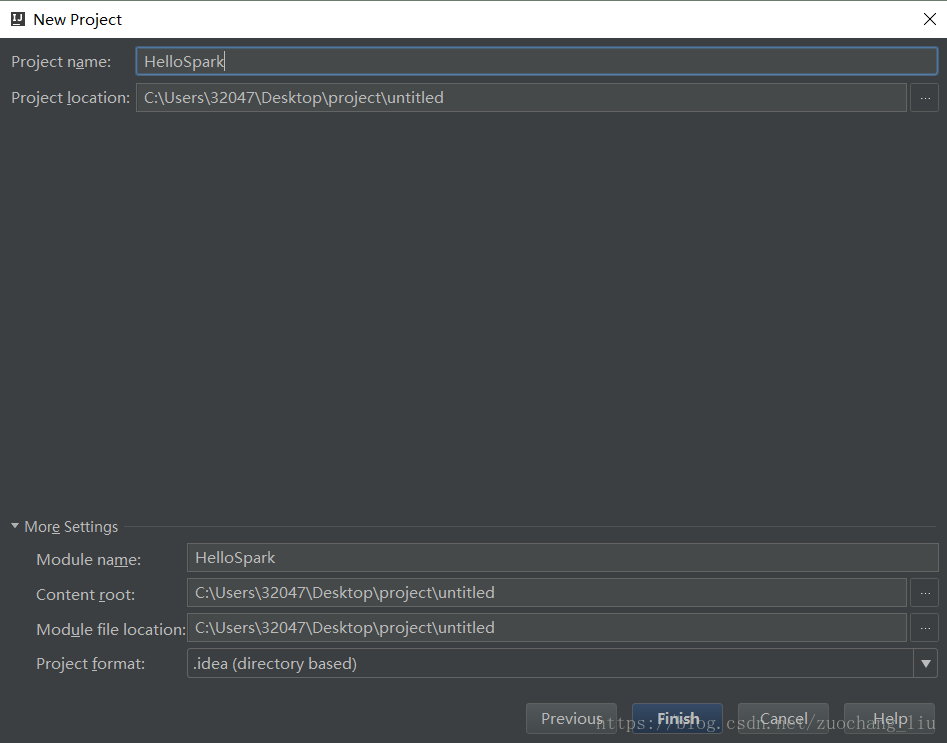
5.创建好maven项目后,点击Import Changes 手动导入,点击Enable Auto-Import 可自动导入
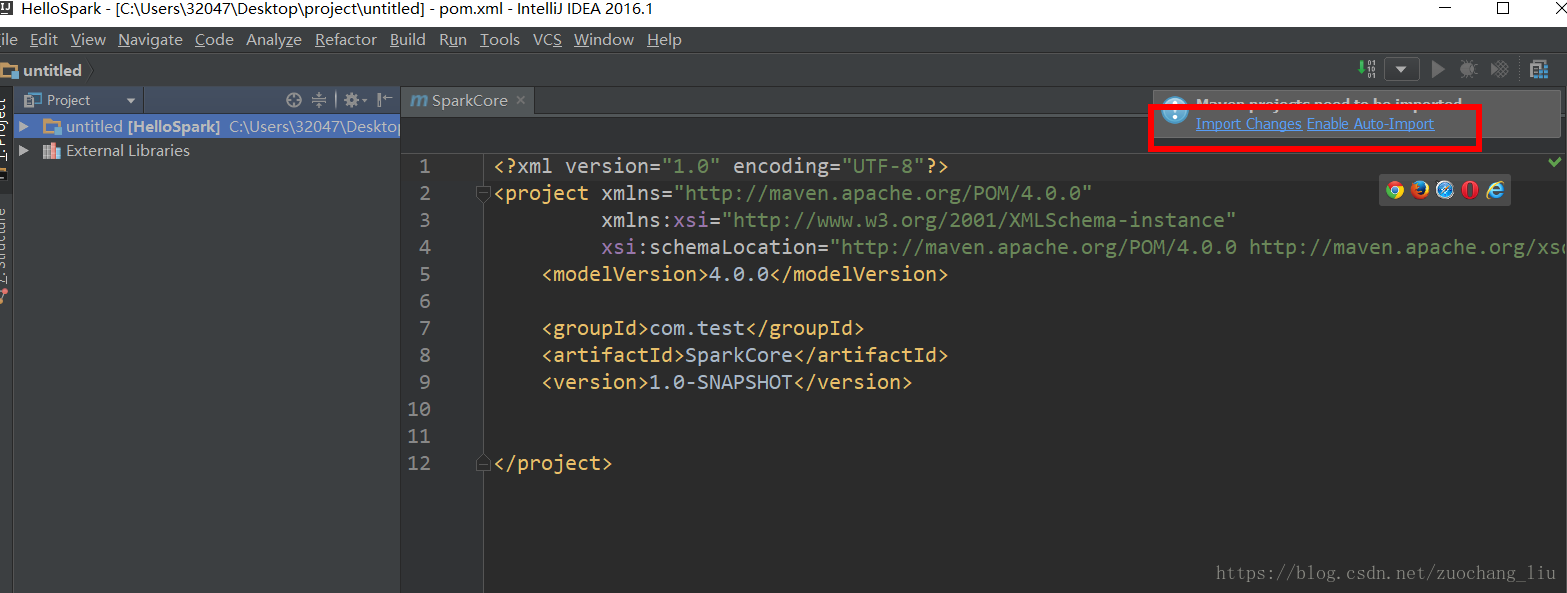
6.配置Maven的pom.xml
详见pom.xml文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.itcast.spark</groupId> <artifactId>hello-spark</artifactId> <version>1.0</version> <properties> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.10.6</scala.version> <spark.version>2.2.0</spark.version> <hadoop.version>2.6.4</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-flume_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version> </dependency> <!-- <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.6.1</version> </dependency>--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-make:transitive</arg> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
maven的编译jdk版本设置:
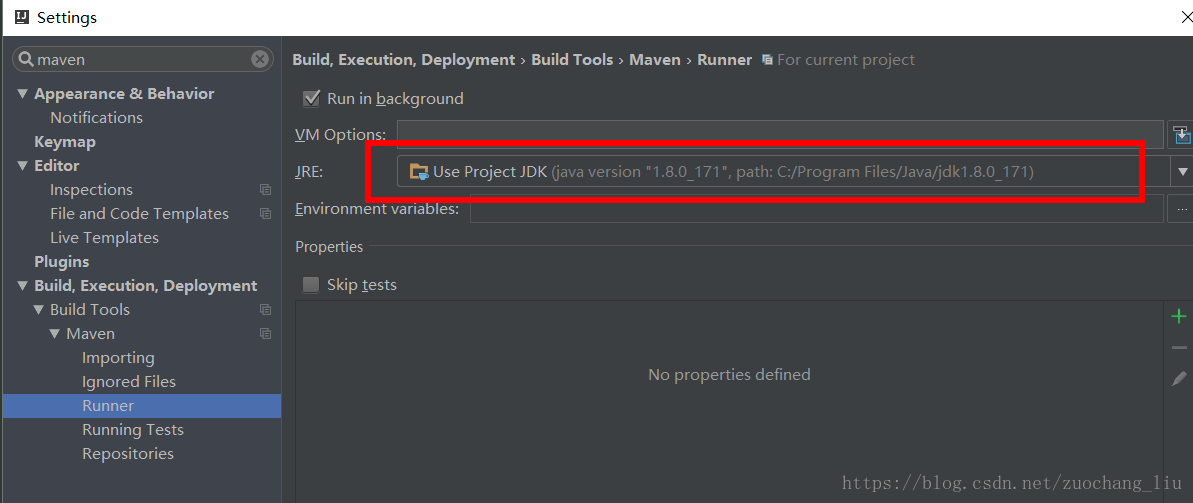
7.新建一个scala object
8.编写spark程序
| object WordCount { // 释放资源 sc.stop() |
4.3.2 javaAPI的wordcount
| public class JavaWordCount { // 释放资源 sc.stop(); |
4.3.3 JAVALambda的wordcount
| public class JavaLambdaWC { |
4.3.4 local模式运行spark程序
| // 配置参数 |
4.4 打包并上传到集群
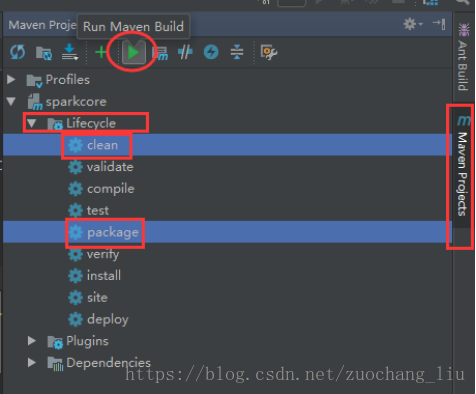
点击idea右侧的Maven Project选项
点击Lifecycle,选择clean和package,然后点击Run Maven Build
9.选择编译成功的jar包,并将该jar上传到Spark集群中的某个节点上(任意节点即可)
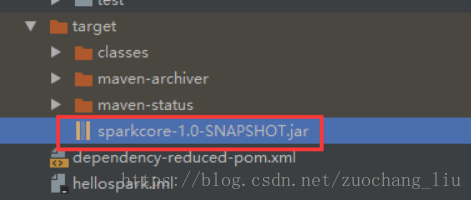

确保启动了hdfs集群和spark集群
| # hdfs启动(在namenode节点上) # /root/apps/hadoop/sbin/start-dfs.sh # spark启动(在master节点上) # start-all.sh |
4.5 提交任务
使用spark-submit命令提交Spark应用(注意参数的顺序)
| spark-submit --master spark://hdp-01:7077 --class com.test.spark.WordCount sparkcore-1.0-SNAPSHOT.jar hdfs://hdp-01:9000/wordcount/input hdfs://hdp-01:9000/wordcount/output |
可以分多行写:
spark-submit \
--class com.test.spark.WordCount \
--master spark://hdp-01:7077 \
/root/sparkcore-1.0-SNAPSHOT.jar \
hdfs://hdp-01:9000/wordcount/input \
hdfs://hdp-01:9000/wordcount/output
任务执行命令的基本套路:
# spark-submit 任务提交参数 --class 程序的main方法 jar包 main的参数列表
查看程序执行过程:
在web页面查看程序运行状态:http://hdp-01:8080
使用jps命令查看进程信息
查看hdfs文件结果
hdfs dfs -cat hdfs://hdp-01:9000/output/part-00000
可以直接通过spark-submit查看所有的参数配置:
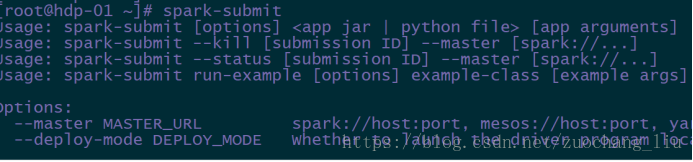
4.6 spark任务常用参数说明
当我们启动一个spark 的任务(application)时,默认使用所有的cores,每一个worker只使用1024m的内存。
当然这些参数都是可以自定义的。
默认配置的目录:http://spark.apache.org/docs/latest/configuration.html

--master spark://hdp-01:7077 指定Master的地址
--executor-memory 2g 指定每个executor可用内存为2G( 512m) 默认是1024mb
--total-executor-cores 2 指定运行任务使用的所有的cup核数为2个
--name “appName” 指定程序运行的名称
--executor-cores 1 指定每一个executor可用的内存
--jars xx.jar 程序额外使用的jar包
注意:如果worker节点的内存不足,那么在启动spark-shell的时候,就不能为executor分配超出worker可用的内存容量,大家根据自己worker的容量进行分配任务资源。
如果使用配置—executor-cores,超过了每个worker可以的cores,任务处于等待状态。
如果使用—total-executor-cores ,即使超过可以的cores,默认使用所有的。以后当集群其他的资源释放之后,就会被该程序所使用。
如果内存或单个executor的cores不足,启动spark-submit就会报错,任务处于等待状态,不能正常执行。


可以通过spark-submit命令来指定参数配置:
4.7 spark集群各角色简介
常驻进程:Master进程 Worker进程
当我们提交spark任务的时候(spark-shell ,spark-submit)
会生成了一个Applications,默认会占用所有Worker的cores,每一个默认占用了1g内存。
可在启动时指定参数。
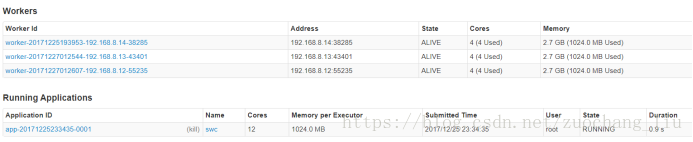
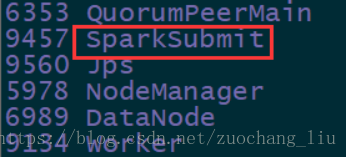
通过jps命令,可以查看到
在执行spark-submit的节点上,有spark-submit(dirver)进程,
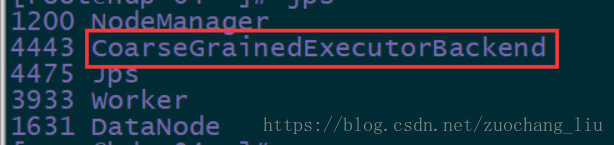
在任务执行的节点上(worker节点上),有 CoarseGrainedExecutorBackend(executor) 进程。
然后,当我们的任务执行完毕之后,这两个进程都会退出了。
Worker的功能: 定时和master通信;调度并管理自身的executor
executor: 由Worker启动的,程序最终在executor中运行,(程序运行的一个容器)
spark-submit命令执行时,会根据master地址去向 Master发送请求,
Master接收到Dirver端的任务请求之后,根据任务的请求资源进行调度,(打散的策略),尽可能的把任务资源平均分配,然后向WOrker发送指令
Worker收到Master的指令之后,就根据相应的资源,启动executor(cores,memory)
executor会向dirver端建立请求,通知driver,任务已经可以运行了
driver运行任务的时候,会把任务发送到executor中去运行。















 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











