







Prometheus Operator简介
Prometheus Operator 是 CoreOS 开发的基于 Prometheus 的 Kubernetes 监控方案,也是目前功能最全面的开源方案。
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
Prometheus operator官网
架构图如下:

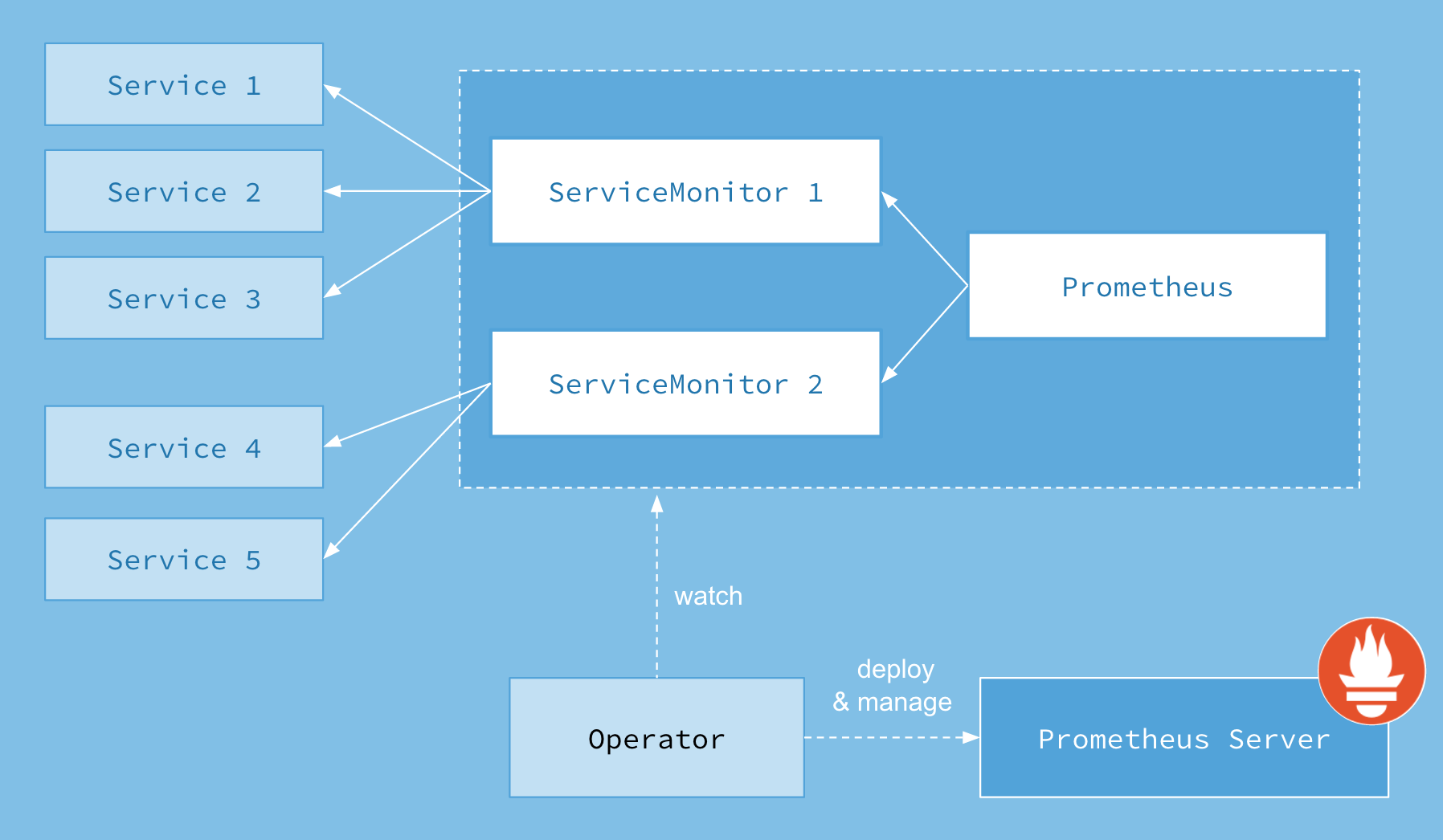
Prometheus Oprator组件
根据上述架构图,我们可以知道,组件主要包括以下内容:
- Operator: 根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus:声明 Prometheus deployment 期望的状态,Operator 确保这个 deployment 运行时一直与定义保持一致。
- PrometheusServer: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor:声明指定监控的服务,描述了一组被 Prometheus 监控的目标列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics信息。
- Service:简单的说就是 Prometheus 监控的对象。
- Alertmanager:定义 AlertManager deployment 期望的状态,Operator 确保这个 deployment 运行时一直与定义保持一致。
Operator
Operator在Kubernetes中以Deployment运行,其职责是根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
Prometheus
Prometheus 自定义资源(CRD)声明了在 Kubernetes 集群中运行的 Prometheus 的期望设置。包含了副本数量,持久化存储,以及 Prometheus 实例发送警告到的 Alertmanagers等配置选项。
Prometeus 自定义资源在Kubernetes中以StatefulSet运行由Operator创建和Operator同一namespace。
Prometheus Pod 都会挂载一个名为 的 Secret,该Secret是 Prometheus 的相关配置。Operator 根据包含的 ServiceMonitor 生成配置,并且更新相关 Secret。无论是对 ServiceMonitors 或者 Prometheus 的修改,Operator 都会实时更新在Secret里。
Prometheus Server
Prometheus Server会作为Kubernetes pod 应用部署到集群中, Prometheus Server主要负责数据的收集,存储并且对外提供数据查询支持。而实际的监控样本数据的收集则是由Exporter完成。Exporter可以是一个独立运行的进程,对外暴露一个用于获取监控数据的HTTP服务。 Prometheus Server只需要定时从这些Exporter暴露的HTTP服务获取监控数据即可。
ServiceMonitor
ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
Operator 能够动态更新 Prometheus 的 Target 列表,ServiceMonitor 就是 Target 的抽象。比如想监控 Kubernetes Scheduler,用户可以创建一个与 Scheduler Service 相映射的 ServiceMonitor 对象。Operator 则会发现这个新的 ServiceMonitor,并将 Scheduler 的 Target 添加到 Prometheus 的监控列表中。
要想使用 Prometheus Operator 监控 Kubernetes 集群中的应用,Endpoints 对象必须存在。Endpoints 对象本质是一个 IP 地址列表。通常,Endpoints 对象由 Service 构建。Service 对象通过对象选择器发现 Pod 并将它们添加到 Endpoints 对象中。
一个 Service 可以公开一个或多个服务端口,通常情况下,这些端口由指向一个 Pod 的多个 Endpoints 支持。这也反映在各自的 Endpoints 对象中。
Prometheus Operator 引入 ServiceMonitor 对象,它发现 Endpoints 对象并配置 Prometheus 去监控这些 Pods。
ServiceMonitorSpec 的 endpoints 部分用于配置需要收集 metrics 的 Endpoints 的端口和其他参数。在一些用例中会直接监控不在服务 endpoints 中的 pods 的端口。因此,在 endpoints 部分指定 endpoint 时,请严格使用,不要混淆。
注意:endpoints(小写)是 ServiceMonitor CRD 中的一个字段,而 Endpoints(大写)是 Kubernetes 资源类型。
ServiceMonitor 和发现的目标可能来自任何 namespace。这对于跨 namespace 的监控十分重要,比如 meta-monitoring。使用 PrometheusSpec 下 ServiceMonitorNamespaceSelector, 通过各自 Prometheus server 限制 ServiceMonitors 作用 namespece。使用 ServiceMonitorSpec 下的 namespaceSelector 可以现在允许发现 Endpoints 对象的命名空间。要发现所有命名空间下的目标,namespaceSelector 必须为空。
Alertmanager
Alertmanager 自定义资源(CRD)声明在 Kubernetes 集群中运行的 Alertmanager 的期望设置。它也提供了配置副本集和持久化存储的选项。
Alertmanager自定义资源在Kubernetes中以StatefulSet运行由Operator创建和Operator同一namespace。
Alertmanager Pod 都会挂载一个名为 的 Secret,该Secret是 Alertmanager 的相关配置,Operator 根据相关配置会实时更新相关Secret。
PrometheusRule
PrometheusRule CRD 声明一个或多个 Prometheus 实例需要的 Prometheus rule。
Alerts 和 recording rules 可以保存并应用为 yaml 文件,可以被动态加载而不需要重启。
Service
这里的 Service 就是 k8s Cluster 中的 Service 资源,也是 Prometheus 要监控的对象,在 Prometheus 中叫做 Target。每个监控对象都有一个对应的 Service。比如要监控 Kubernetes Scheduler,就得有一个与 Scheduler 对应的 Service。当然,Kubernetes 集群默认是没有这个 Service 的,Prometheus Operator 会负责创建。
Service 资源主要用来对应 Kubernetes 集群中的 Metrics Server Pod,来提供给 ServiceMonitor 选取让 Prometheus Server 来获取信息。简单的说就是 Prometheus 监控的对象,例如之前了解的 Node Exporter Service、Mysql Exporter Service 等等。
Exporter
Exporter是服务器端agent,负责采集主机的运行指标,典型的包括CPU、内存,磁盘、网络等等监控样本。exporter组件负责收集节点上的metrics监控数据,并将数据推送给prometheus server, 比如node-export,mysql-export,blackbox-export 等等。查看更多
Grafana
Grafana是可视化数据统计和监控平台。
MetricServer
MetricServer是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如kubectl,hpa,scheduler等。
KubeStateMetrics
KubeStateMetrics收集kubernetes集群内资源对象数据,制定告警规则。
Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule 4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的prometheus这种资源对象就是作为Prometheus Server存在,而ServiceMonitor就是exporter的各种抽象,exporter是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











