







本文是论文《Networks for Joint Affine and Non-parametric Image Registration》的阅读笔记。
文章提出了一个名为AVSM(Affine-vSVF-Mapping)的端到端3D医学图像配准模型,该模型结合了仿射配准和矢量动量参数化静态速度场模型( a vector momentum-parameterized stationary velocity field(vSVF) model)。模型有三个阶段(stage),在第一阶段,通过多步的仿射网络来预测一个仿射变换参数;在第二阶段,使用类UNet网络生成一个动量,从而可以通过平滑计算出一个速度场;在第三阶段,使用一个独立的基于图的vSVF组件来基于当前转换映射做无参的微调。
一、相关工作
当图像具有相似的灰度值分布时,通常采用MSE来评估灰度值的相似性;而在多模配准中,NCC和MI指标会更合适。
微分同胚转换可以通过优化足够平滑的速度场来实现,此时,空间转换可以通过积分来恢复(通过积分得到逆转换)。这样的方法包括LDDMM和Diffeomorphic Demons等。
由于空间转换网络(STN)在配准模型中的使用,实现了模型的端到端的训练。
现有的基于深度学习的配准模型存在诸多局限:
- 这些方法通常会假定图像已经实现预配准过,即进行过刚性或仿射配准。这种预对齐可以通过特定的网络或标准数值优化的方式来进行,在前一种方法中,配准方法不再是端到端的,在后一种方法中,预配准成为了计算的瓶颈;
- 很多方法受限于内存/显存的大小,通常可以通过改为对2D图像会对3D patch进行配准以减少资源开销;
- 这些方法没有进行迭代的改进(refinement)。
本文的贡献有:
- 提出了一个新颖的矢量动量参数化的静态速度场配准模型,矢量动量长允许将平滑和转换参数的预测解构,因此可以得到足够平滑的速度场以及适用于大位移的微分同胚;
- 模型是端到端的,并且结合了仿射配准和vSVF配准;
- 在仿射配准和vSVF配准组件中都采用了多步配准的方法,从而改善了配准的效果;
- 结果只经过一次配准映射得到,避免了多次插值而带来的误差;
- 在仿射配准和vSVF配准组件中都采用了逆一致性损失,从而让模型忽略输入图像的顺序,即从A配准到B和从B配准到A的结果相似。

AVSM的网络架构如上图所示,在仿射配准阶段,采用多步的仿射网络来预测仿射变换参数;在vSVF配准阶段,使用类UNet网络产生一个动量,并由此计算一个速度场,然后初始映射和动量被喂到vSVF组件中来产生最终的转换映射。在以上过程中源图像只做一次插值,由此也避免了图像模糊。
在处理3D图像时,如果图像的大小只有原图的一半,则需要的计算和内存/显存只有原来的 1 8 \frac{1}{8} 81。
二、方法
1. 多步仿射网络
现有的大多数无参数配准方法由于有正则项惩罚,所以对仿射变换不是不变的,因此在无参配准之前通常会先进行预配准,即仿射配准,以考虑全局的大位移和旋转。
模型应该足够灵活以同时适应小的和大的仿射变形。所以采用多步的方法得到最终的仿射变换,这种策略显著的提高了模型精度和稳定性。
上图是多步仿射配准的网络结构。多步仿射配准网络是一个多次出现的网络,以逐渐的改进仿射变换。为了避免多次三线性插值带来的数值不稳定性和数值消散,文章采用的是直接更新仿射参数而不是在中间步骤对图像进行重采样。用
Γ
=
(
A
b
)
\Gamma=(A \quad b)
Γ=(Ab)来表示仿射参数,其中
A
∈
R
d
×
d
A\in\R^{d\times d}
A∈Rd×d表示线性转换矩阵,
b
∈
R
d
b\in\R^{d}
b∈Rd表示位移,
d
d
d是图像的维度。仿射参数更新的规则如下:
A
(
t
)
=
A
~
(
t
)
A
(
t
−
1
)
,
b
(
t
)
=
A
~
(
t
)
b
(
t
−
1
)
+
b
~
(
t
)
s.t.
A
(
0
)
=
I
,
b
(
0
)
=
0
\begin{array}{l} A_{(t)}=\tilde{A}_{(t)} A_{(t-1)}, b_{(t)}=\tilde{A}_{(t)} b_{(t-1)}+\tilde{b}_{(t)} \\ \text {s.t.} \quad A_{(0)}=I, b_{(0)}=0 \end{array}
A(t)=A~(t)A(t−1),b(t)=A~(t)b(t−1)+b~(t)s.t.A(0)=I,b(0)=0
其中,
A
~
(
t
)
,
A
(
t
)
\tilde A_{(t)},A_{(t)}
A~(t),A(t)表示第
t
t
t步的线性变换矩阵输出和合成结果。相似的,$ \tilde b_{(t)},b_{(t)}
表
示
第
表示第
表示第t
步
的
仿
射
变
换
参
数
输
出
和
合
成
结
果
。
仿
射
映
射
可
以
通
过
下
式
得
到
:
步的仿射变换参数输出和合成结果。仿射映射可以通过下式得到:
步的仿射变换参数输出和合成结果。仿射映射可以通过下式得到:\Phi_{a}^{-1}(x, \Gamma)=A_{\left(t_{\text {last}}\right)} x+b_{\left(t_{\text {last}}\right)}$。
2. 多步仿射网络的损失
损失包括三部分:图像相似性损失 L a − s i m L_{a-sim} La−sim,正则项 L a − r e g L_{a-reg} La−reg和鼓励变换对称的损失 L a − s y m L_{a-sym} La−sym。让 I 0 I_0 I0和 I 1 I_1 I1分别表示源图像和目标图像,上标 s t ^{st} st和 t s ^{ts} ts分别表示从 I 0 I_0 I0到 I 1 I_1 I1的配准和从 I 1 I_1 I1到 I 0 I_0 I0的配准。
1)图像相似性损失 L a − s i m ( I 0 , I 1 , Φ a − 1 ) L_{a-s i m}\left(I_{0}, I_{1}, \Phi_{a}^{-1}\right) La−sim(I0,I1,Φa−1)
可以是NCC、LNCC(localized NCC)、MSE等。本文使用的是mk-LNCC(multi-kernel LNCC)。让
V
V
V 表示图像的体积,
x
i
,
y
i
x_i,y_i
xi,yi表示配准后的源图像和目标图像中的第
i
i
i个体素,
N
s
N_s
Ns表示大小为
s
×
s
×
s
s\times s\times s
s×s×s的滑动窗口的个数,
ζ
j
s
\zeta_{j}^{s}
ζjs表示中心点在第
j
j
j个体素的窗口,
x
j
ˉ
,
y
j
ˉ
\bar{x_j},\bar{y_j}
xjˉ,yjˉ表示配准后源图像和目标图像在窗口
ζ
j
8
\zeta^8_j
ζj8内的灰度值的平均值。窗口大小为
s
s
s的LNCC记为
k
s
k_s
ks,其定义如下:
κ
s
(
x
,
y
)
=
1
N
s
∑
j
∑
i
∈
ζ
j
s
(
x
i
−
x
ˉ
j
)
(
y
i
−
y
ˉ
j
)
∑
i
∈
ζ
j
s
(
x
i
−
x
ˉ
j
)
2
∑
i
∈
ζ
j
s
(
y
i
−
y
ˉ
j
)
2
\kappa_{s}(x, y)=\frac{1}{N_{s}} \sum_{j} \frac{\sum_{i \in \zeta_{j}^{s}}\left(x_{i}-\bar{x}_{j}\right)\left(y_{i}-\bar{y}_{j}\right)}{\sqrt{\sum_{i \in \zeta_{j}^{s}}\left(x_{i}-\bar{x}_{j}\right)^{2} \sum_{i \in \zeta_{j}^{s}}\left(y_{i}-\bar{y}_{j}\right)^{2}}}
κs(x,y)=Ns1j∑∑i∈ζjs(xi−xˉj)2∑i∈ζjs(yi−yˉj)2∑i∈ζjs(xi−xˉj)(yi−yˉj)
定义mk-LNCC为具有不同窗口大小的LNCC的加权和。
图像相似性损失为:
L
a
−
s
i
m
(
I
0
,
I
1
,
Γ
)
=
∑
i
ω
i
κ
s
i
(
I
0
∘
Φ
a
−
1
,
I
1
)
s.t.
Φ
a
−
1
(
x
,
Γ
)
=
A
x
+
b
and
∑
i
ω
i
=
1
,
w
i
≥
0
\begin{array}{l} L_{a-s i m}\left(I_{0}, I_{1}, \Gamma\right)=\sum_{i} \omega_{i} \kappa_{s_{i}}\left(I_{0} \circ \Phi_{a}^{-1}, I_{1}\right) \\ \text { s.t. } \Phi_{a}^{-1}(x, \Gamma)=A x+b \text { and } \sum_{i} \omega_{i}=1, w_{i} \geq 0 \end{array}
La−sim(I0,I1,Γ)=∑iωiκsi(I0∘Φa−1,I1) s.t. Φa−1(x,Γ)=Ax+b and ∑iωi=1,wi≥0
2)正则项损失 L a − r e g ( Γ ) L_{a-reg}(\Gamma) La−reg(Γ)
惩罚合成仿射变换与恒等变换的偏差:
L
a
−
r
e
g
(
Γ
)
=
λ
a
r
(
∥
A
−
I
∥
F
2
+
∥
b
∥
2
2
)
L_{a-r e g}(\Gamma)=\lambda_{a r}\left(\|A-I\|_{F}^{2}+\|b\|_{2}^{2}\right)
La−reg(Γ)=λar(∥A−I∥F2+∥b∥22)
其中
∥
⋅
∥
F
\|\cdot\|_F
∥⋅∥F表示Frobenius正则,
λ
a
r
≥
0
\lambda_{ar}\geq0
λar≥0是依赖于epoch的权重系数,在训练开始时较大,以限制大的形变,然后逐渐衰减到0。
3)对称损失 L a − s y m ( Γ , Γ t s ) L_{a-sym}(\Gamma,\Gamma^{ts}) La−sym(Γ,Γts)
鼓励配准的逆一致性,即鼓励从源图像到目标图像的变换是从目标图像到源图像变换的逆变换,用公式表示为: A t s ( A x + b ) + b t s = x ) : L a − s y m ( Γ , Γ t s ) = λ a s ( ∥ A t s A − I ∥ F 2 + ∥ A t s b + b t s ∥ 2 2 ) \left.A^{t s}(A x+b)+b^{t s}=x\right):L_{a-s y m}\left(\Gamma, \Gamma^{t s}\right)=\lambda_{a s}\left(\left\|A^{t s} A-I\right\|_{F}^{2}+\left\|A^{t s} b+b^{t s}\right\|_{2}^{2}\right) Ats(Ax+b)+bts=x):La−sym(Γ,Γts)=λas(∥AtsA−I∥F2+∥Atsb+bts∥22),其中 λ a s ≥ 0 \lambda_{as}\geq0 λas≥0。
总损失为:
L
a
(
I
0
,
I
1
,
Γ
,
Γ
t
s
)
=
ℓ
a
(
I
0
,
I
1
,
Γ
)
+
ℓ
a
(
I
1
,
I
0
,
Γ
t
s
)
+
L
a
−
s
y
m
(
Γ
,
Γ
t
s
)
\begin{aligned} \mathcal{L}_{a}\left(I_{0}, I_{1}, \Gamma, \Gamma^{t s}\right)=& \ell_{a}\left(I_{0}, I_{1}, \Gamma\right)+\ell_{a}\left(I_{1}, I_{0}, \Gamma^{t s}\right) \\ &+L_{a-s y m}\left(\Gamma, \Gamma^{t s}\right) \end{aligned}
La(I0,I1,Γ,Γts)=ℓa(I0,I1,Γ)+ℓa(I1,I0,Γts)+La−sym(Γ,Γts)
其中
ℓ
a
(
I
0
,
I
1
,
Γ
)
=
L
a
−
s
i
m
(
I
0
,
I
1
,
Γ
)
+
L
a
−
r
e
g
(
Γ
)
\ell_{a}\left(I_{0}, I_{1}, \Gamma\right)=L_{a-s i m}\left(I_{0}, I_{1}, \Gamma\right)+L_{a-r e g}(\Gamma)
ℓa(I0,I1,Γ)=La−sim(I0,I1,Γ)+La−reg(Γ)。
3. 矢量动量参数化SVF
1)vSVF方法
为了捕获大的变形并保证微分同胚变换,通常使用流体机制的配准算法。此时,转换映射
ϕ
3
\phi^3
ϕ3可以通过速度场
v
(
x
,
t
)
v(x,t)
v(x,t)对时间积分来得到。控制微分方程为:
Φ
t
(
x
,
t
)
=
v
(
Φ
(
x
,
t
)
,
t
)
,
Φ
(
x
,
0
)
=
Φ
(
0
)
(
x
)
\Phi_{t}(x, t)=v(\Phi(x, t), t), \Phi(x, 0)=\Phi_{(0)}(x)
Φt(x,t)=v(Φ(x,t),t),Φ(x,0)=Φ(0)(x),其中
Φ
(
0
)
\Phi_{(0)}
Φ(0)是初始映射。对于足够平滑的速度场来说,可以获得一个微分同胚变换,通过对不平衡进行惩罚而保证速度场的平滑性,即:
v
∗
=
argmin
v
λ
v
r
∫
0
1
∥
v
∥
L
2
d
t
+
sim
[
I
0
∘
Φ
−
1
(
1
)
,
I
1
]
s.t.
Φ
t
−
1
+
D
Φ
−
1
v
=
0
and
Φ
−
1
(
0
)
=
Φ
(
0
)
−
1
\begin{array}{l} v^{*}=\underset{v}{\operatorname{argmin}} \lambda_{v r} \int_{0}^{1}\|v\|_{L}^{2} \mathrm{d} t+\operatorname{sim}\left[I_{0} \circ \Phi^{-1}(1), I_{1}\right] \\ \text { s.t. } \quad \Phi_{t}^{-1}+D \Phi^{-1} v=0 \quad \text { and } \quad \Phi^{-1}(0)=\Phi_{(0)}^{-1} \end{array}
v∗=vargminλvr∫01∥v∥L2dt+sim[I0∘Φ−1(1),I1] s.t. Φt−1+DΦ−1v=0 and Φ−1(0)=Φ(0)−1
其中
D
D
D表示雅克比行列式,
∥
v
∥
L
2
=
⟨
L
†
L
v
,
v
⟩
\|v\|^2_L=\left\langle L^{\dagger} L v, v\right\rangle
∥v∥L2=⟨L†Lv,v⟩是通过微分操作
L
L
L和其共轭
L
†
L^\dagger
L†所定义的空间正则。由于动量
m
=
L
†
L
v
m=L^\dagger Lv
m=L†Lv,正则又可以表示为:
∥
v
∥
L
2
=
⟨
m
,
v
⟩
\|v\|_{L}^{2}=\langle m, v\rangle
∥v∥L2=⟨m,v⟩。SVF配准算法是直接优化速度场
v
v
v,而本文提出一个矢量动量SVF(vSVF)方程,其表达式如下:
m
∗
=
argmin
m
0
λ
v
r
⟨
m
0
,
v
0
⟩
+
Sim
[
I
0
∘
Φ
−
1
(
1
)
,
I
1
]
,
s.t.
Φ
t
−
1
+
D
Φ
−
1
v
=
0
,
Φ
−
1
(
0
)
=
Φ
(
∩
)
−
1
,
v
0
=
(
L
†
L
)
−
1
m
0
\begin{array}{l} m^{*}=\underset{m_{0}}{\operatorname{argmin}} \lambda_{v r}\left\langle m_{0}, v_{0}\right\rangle+\operatorname{Sim}\left[I_{0} \circ \Phi^{-1}(1), I_{1}\right], \text { s.t. } \\ \Phi_{t}^{-1}+D \Phi^{-1} v=0, \Phi^{-1}(0)=\Phi_{(\cap)}^{-1}, v_{0}=\left(L^{\dagger} L\right)^{-1} m_{0} \end{array}
m∗=m0argminλvr⟨m0,v0⟩+Sim[I0∘Φ−1(1),I1], s.t. Φt−1+DΦ−1v=0,Φ−1(0)=Φ(∩)−1,v0=(L†L)−1m0
其中,
m
0
m_0
m0表示矢量动量,
λ
v
r
>
0
\lambda_{vr}>0
λvr>0是常数,该方程可以看作是简化的矢量动量参数化的LDDMM方程。该方程的有点事它允许我们通过深度网络来预测动量而显式的控制空间平滑,进而产生平滑的速度场,而不是直接预测速平滑的度场。
2)vSVF配准网络
上图是vSVF配准网络框架,分为两部分:一是动量生成网络,以配准后的源图像和目标图像作为输入,输出低分辨率的动量;二是vSVF配准部分。预测的动量和下采样的初始化映射被输入到vSVF单元,然后输出最后经过上采样得到全分辨率的转换映射。在vSVF单元中,通过对动量进行平滑而得到速度场,然后用它来解对流方程 Φ ( τ ) t − 1 + D Φ ( τ ) − 1 v = 0 \Phi_{(\tau) t}^{-1}+D \Phi_{(\tau)}^{-1} v=0 Φ(τ)t−1+DΦ(τ)−1v=0,然后得到最终的变换映射。初始映射可以是仿射映射,也可以是通过之前的vSVF步骤得到的映射。
动量生成网络
使用四阶Runge-Kutta方法来对时间积分并将所有具有中心差分的空间导数离散化。因此,减少了内存的需要,网络输出的是低分辨率的动量。在实操时,移除了UNet中解码器的最后一层,以产生低分辨率的动量。
vSVF的损失
损失也分为三部分,相似性损失和仿射网络中的相同,正则项损失用来乘法速度场,即:
L
v
−
r
e
g
(
m
0
)
=
λ
v
r
∥
v
∥
L
2
=
λ
v
r
⟨
m
0
,
v
0
⟩
L_{v-r e g}\left(m_{0}\right)=\lambda_{v r}\|v\|_{L}^{2}=\lambda_{v r}\left\langle m_{0}, v_{0}\right\rangle
Lv−reg(m0)=λvr∥v∥L2=λvr⟨m0,v0⟩
其中,
v
0
=
(
L
†
L
)
−
1
m
0
v_0=(L^\dagger L)^{-1}m_0
v0=(L†L)−1m0,把
(
L
†
L
)
−
1
(L^\dagger L)^{-1}
(L†L)−1看作是具有多高斯核的卷积。
对称性损失
L
v
−
s
y
m
(
Φ
−
1
,
(
Φ
t
s
)
−
1
)
=
λ
v
s
∥
Φ
−
1
∘
(
Φ
t
s
)
−
1
−
i
d
∥
2
2
L_{v-s y m}\left(\Phi^{-1},\left(\Phi^{t s}\right)^{-1}\right)=\lambda_{v s}\left\|\Phi^{-1} \circ\left(\Phi^{t s}\right)^{-1}-i d\right\|_{2}^{2}
Lv−sym(Φ−1,(Φts)−1)=λvs∥∥∥Φ−1∘(Φts)−1−id∥∥∥22
其中
i
d
id
id表示恒等映射,
λ
v
s
≥
0
\lambda_{vs}\geq0
λvs≥0表示对称权重,
(
Φ
t
s
)
−
1
(\Phi^{ts})^{-1}
(Φts)−1表示从目标图像到源图像的配准映射,
Φ
−
1
\Phi^{-1}
Φ−1表示从源图像到目标图像的配准映射。
总损失:
L
v
(
I
0
,
I
1
,
Φ
−
1
,
(
Φ
t
s
)
−
1
,
m
0
,
m
0
t
s
)
=
ℓ
v
(
I
0
,
I
1
,
Φ
−
1
,
m
0
)
+
ℓ
v
(
I
1
,
I
0
,
(
Φ
t
s
)
−
1
,
m
0
t
s
)
+
L
v
−
s
y
m
(
Φ
−
1
,
(
Φ
t
s
)
−
1
)
\begin{aligned} \mathcal{L}_{v}\left(I_{0}, I_{1}, \Phi^{-1},\left(\Phi^{t s}\right)^{-1}, m_{0}, m_{0}^{t s}\right)=\ell_{v}\left(I_{0}, I_{1}, \Phi^{-1}, m_{0}\right) \\ +\ell_{v}\left(I_{1}, I_{0},\left(\Phi^{t s}\right)^{-1}, m_{0}^{t s}\right) \\ +L_{v-s y m}\left(\Phi^{-1},\left(\Phi^{t s}\right)^{-1}\right) \end{aligned}
Lv(I0,I1,Φ−1,(Φts)−1,m0,m0ts)=ℓv(I0,I1,Φ−1,m0)+ℓv(I1,I0,(Φts)−1,m0ts)+Lv−sym(Φ−1,(Φts)−1)
其中,
ℓ
v
(
I
0
,
I
1
,
Φ
−
1
,
m
0
)
=
L
v
−
sim
(
I
0
,
I
1
,
Φ
−
1
)
+
L
v
−
r
e
g
(
m
0
)
\ell_{v}\left(I_{0}, I_{1}, \Phi^{-1}, m_{0}\right)=L_{v-\operatorname{sim}}\left(I_{0}, I_{1}, \Phi^{-1}\right)+L_{v-r e g}\left(m_{0}\right)
ℓv(I0,I1,Φ−1,m0)=Lv−sim(I0,I1,Φ−1)+Lv−reg(m0)
具有T步的vSVF模型,其总损失为:
∑
τ
=
1
T
L
v
(
I
0
,
I
1
,
Φ
(
τ
)
−
1
,
Φ
(
τ
)
t
s
,
m
0
(
τ
)
,
m
0
(
τ
)
t
s
)
s.t.t.
Φ
(
τ
)
−
1
(
x
,
0
)
=
Φ
(
τ
−
1
)
−
1
(
x
,
1
)
(
Φ
(
τ
)
t
s
)
−
1
(
x
,
0
)
=
(
Φ
(
τ
−
1
)
t
s
)
−
1
(
x
,
1
)
\begin{array}{c} \sum_{\tau=1}^{T} \mathcal{L}_{v}\left(I_{0}, I_{1}, \Phi_{(\tau)}^{-1}, \Phi_{(\tau)}^{t s}, m_{0}(\tau), m_{0(\tau)}^{t s}\right) \quad \text { s.t.t. } \\ \Phi_{(\tau)}^{-1}(x, 0)=\Phi_{(\tau-1)}^{-1}(x, 1) \\ \left(\Phi_{(\tau)}^{t s}\right)^{-1}(x, 0)=\left(\Phi_{(\tau-1)}^{t s}\right)^{-1}(x, 1) \end{array}
∑τ=1TLv(I0,I1,Φ(τ)−1,Φ(τ)ts,m0(τ),m0(τ)ts) s.t.t. Φ(τ)−1(x,0)=Φ(τ−1)−1(x,1)(Φ(τ)ts)−1(x,0)=(Φ(τ−1)ts)−1(x,1)
三、训练
1. 多步仿射网络的训练
首先训练一个单步的网络,然后用它的参数来初始化多步的网络。在纵向的配准中,训练一个3步的仿射网络,而在测试的时候使用七步的网络;在跨物体配准中,训练一个5步的仿射网络,在测试的时候使用七步的网络。仿射对称因子
λ
a
s
\lambda_{as}
λas设为10。仿射正则因子是依赖于epoch的,其定义为:
λ
a
r
:
=
C
a
r
K
a
r
K
a
r
+
e
n
/
K
a
r
\lambda_{a r}:=\frac{C_{a r} K_{a r}}{K_{a r}+e^{n / K_{a r}}}
λar:=Kar+en/KarCarKar
其中,
C
a
r
C_{ar}
Car是常数,
K
a
r
K_{ar}
Kar用来控制衰减率,
n
n
n是epoch数,
K
a
r
K_{ar}
Kar设为4,
C
a
r
C_{ar}
Car设为10。
2. 动量生成网络的训练
使用10步和多高斯核(标准差为{0.05, 0.1, 0.15, 0.2, 0.25})以及相关权重{j0.067, 0.133, 0.2, 0.267, 0.333}。在训练时都是训练两步,正则化因子 λ v r \lambda_{vr} λvr设为10,对称因子 λ v s \lambda_{vs} λvs设为 1 e − 4 1e^{-4} 1e−4。每个实验有200个epoch,每个epoch有400个batch,一个batch包括一对图像。学习率为 5 e − 4 5e^{-4} 5e−4,没60个epoch衰减为原来的0.5。使用mk-LNCC作为图像相似性指标, ( w , w ) = { ( 0 , 3 , S / 4 ) , ( 0.7 , S / 2 ) } (w,w)=\{(0,3, S/4),(0.7, S/2)\} (w,w)={(0,3,S/4),(0.7,S/2)},其中 S S S表示最小的图像维度,滑动窗口的步长设为 S / 4 S/4 S/4,采用因子为2的空洞卷积。
四、实验
1. 实验设置
数据集选用的是OAI(Osteoarthritis Initiative)MR数据集,预处理时将灰度值归一化,然后去除小于0.1%和大于99.9%的灰度值。所有图像重采样到 192 × 192 × 80 192\times192\times80 192×192×80大小。将无标签的数据按7:3划分为训练集和验证集。使用Dice值来评价配准的结果。选用SyN,Demons,NiftyReg和VoxelMorph作为baseline。
2. 基于优化的多尺度仿射配准
开始时,对低分辨率的图像预测一个粗略的仿射参数,然后使用它作为更高分辨率的初始化参数。使用学习率为 1 e − 4 1e^{-4} 1e−4的随机梯度下降优化器,三个图像尺寸分别为原图大小的 k ∈ { 0.25 , 0.5 , 1.0 } k\in\{0.25, 0.5, 1.0\} k∈{0.25,0.5,1.0},每个迭代200,200,50次。使用mk-LNCC作为相似性准则。在尺寸为1.0时,参数设为 ( w , s ) = { ( 0.3 , S k / 4 ) , ( 0.7 , S k / 2 ) } (w,s)=\{(0.3, S_k/4),(0.7, S_k/2)\} (w,s)={(0.3,Sk/4),(0.7,Sk/2)},在尺寸为0.5和0.25时,参数为 ( w , s ) = { ( 1.0 , S k / 2 ) } (w,s)=\{(1.0, S_k/2)\} (w,s)={(1.0,Sk/2)}。
3. 基于优化的多尺度vSVF配准
采用仿射映射作为初始映射,采用和多尺度仿射配准相同的多尺度策略。采用LBGFS优化器,尺度为 { 0.25 , 0.5 , 1.0 } \{0.25, 0.5, 1.0\} {0.25,0.5,1.0},每个尺度迭代60次,使用mk-LNCC作为相似性指标。
4. 实验结果

上图是AVSM的结果图,前五行分别为源图像、目标图像、配准后的图像、具有变形网格的配准后图像和多步仿射配准的图像。后三行为源标签、目标标签、AVSM配准后的标签。
上图是不同配准方法的效果对比表,Affine-opt和vSVF-opt表示基于优化的多尺度仿射和vSVF配准。实验结果显示本文的AVSM模型在跨物体配准中的表现超过了其他方法,在纵向配准中,AVSM的效果也足够好,但是略差于基于优化的方法。这可能是因为形变是微妙的,或者源图像和目标图像非常相似,所以数值优化方法可能更好的对齐。

上图是更直观的表示,越高的越好。
当没有初始的仿射对齐时,VoxelMorph的效果不佳,只有进行了仿射对齐时,VoxelMorph才会达到很好的效果。
为了衡量变化映射的平滑性,使用雅克比行列式来估计: J ϕ ( x ) : = ∣ D ϕ − 1 ( x ) ∣ J_{\phi}(x):=\mid D \phi^{-1}(x)| Jϕ(x):=∣Dϕ−1(x)∣,当 { x : J ϕ ( x ) < 0 } \{x:J_\phi(x)<0\} {x:Jϕ(x)<0}时,表示重叠。
上图是消融实验的结果表,在消融实验部分,发现引入多步和逆一致性提升了仿射配准的性能,相比于使用NCC,本文使用的mk-LNCC效果更好。

使用 ln ( 1 ∣ V ∣ ∥ Φ − 1 ∘ ( Φ t s ) − 1 − i d ∥ 2 2 \ln(\frac{1}{|V|}\|\Phi^{-1}\circ(\Phi^{ts})^{-1}-id\|^2_2 ln(∣V∣1∥Φ−1∘(Φts)−1−id∥22来衡量对称性,其中 V V V表示图像体积大小, Φ \Phi Φ表示通过仿射变换和可变形变换合成的映射。上图显示了有对称损失和无对称损失时的配准结果。
由于不同的方法对边界的处理不同,所以本文只对离边界10体素远的图像进行衡量。
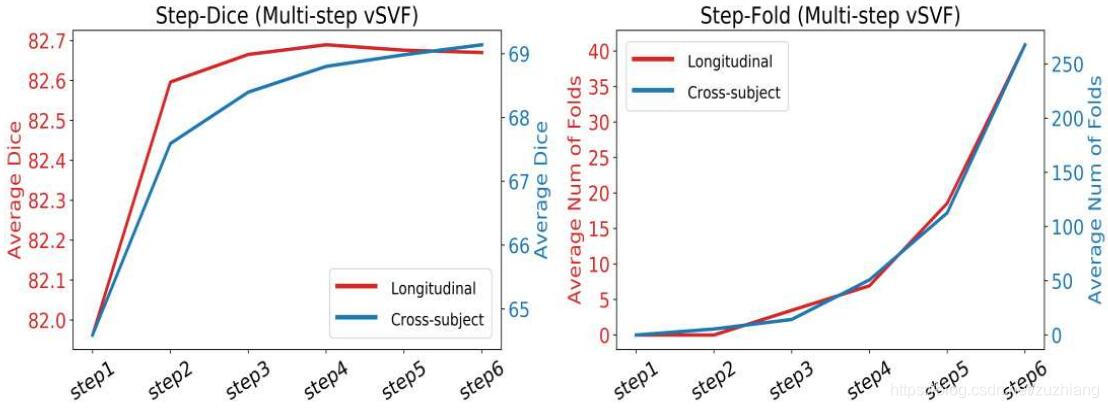
具有2步训练的多步vSVF配准结果,从左图可以看出效果随着step的增加而提升,右图显示同时重叠也增加。















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









