







背景
过几天工作需要用到Hadoop,于是就弄了本PDF看。看了半天也是晕晕乎乎的。干脆直接动手,这样还能掌握的快一点。于是我就在本地要搭建一个Hadoop的开发环境。
环境前提
Linux:CentOS release 6.7 (Final) x86_64
Java ,version:1.7.0_80 (x86_64)
Hadoop ,version:1.2.1
------------------------------
windows ,version:Windows 7 professional x86_64
eclipse ,version:Luna Service Release 2 (4.4.2)
------------------------------
4、其他需要使用的开源库
Apache Ant ,version:1.9.4
开始前准备
1、千万不要有中文路径!!!
2、如果Windows用户名是中文的,改掉它!!!变成英文的用户名!!!
Linux上的Hadoop安装
Java安装
2、首先去oracle官网下载对应的Java程序包,下载的时候需要登录,这个比较麻烦。Java下载页面
3、下载好之后是一个tar.gz文件,放到Linux下的某个目录(此处我放在了/opt下)
4、执行命令,解包
cd /opt
tar xvf 刚刚下载的tar.gz的文件名
// 示例
tar xvf jdk-7u80-linux-x64.tar.gz
// 解压出来的文件夹名称太长,这里我把文件夹重命名,这一步不是必须的
mv 解压出的文件名 新文件名
// 示例
mv jdk-7u80-linux-x64 jdk1.7.0_80vim /etc/profile
// 增加JAVA_HOEM
export JAVA_HOME=/opt/jdk1.7.0_80
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profilejava -versionHadoop安装
vim /etc/profileexport HADOOP_HOME=/opt/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/binsource /etc/profile<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hostname:9000</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>hdfs://hostname:9000hdfs://localhost:9000hdfs://Linux服务器的IP地址:9000找到这一行
# export JAVA_HOME=/usr/lib/j2sdk1.5-sunexport JAVA_HOME=/opt/jdk1.7.0_80(3)vim编辑hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>Linux的IP地址:9001</value>
</property>
</configuration>说明一下,dfs.permissions配置默认为true,由于是测试用,这里将其关闭,避免过多的麻烦
这里的配置是最简单的一个配置,目的是为了能让用户快速开始hadoop的使用。
IP:端口号中的端口号可以进行自定义,不一定非要9000和9001,自己能区分就ok
5、进入/opt/hadoop-1.2.1/bin下
./start-all.sh会出现让你输入root密码的选项,3次。输入就ok
之后格式化hdfs
hadoop fs -format
windows下的开发环境搭建
eclipse插件的安装
之前一般eclipse插件都是能在网上下载到的,这次出乎我的意料,很少有下载的,网上的教程几乎清一色都是要自己编译的。我偏不信。。下载了几个。。果然不能用,有几个能用的,但是各种出错。最好的办法还是自己编译一下。
编译很简单的。
首先将刚刚下载的hadoop的tar.gz解压出来,这里我解压到了D盘。
eclipse插件编译
eclipse.home=D:/eclipse
version=1.2.1<fileset dir="../../../">
<include name="hadoop*.jar"/>
</fileset> <path id="eclipse-sdk-jars">
<fileset dir="${eclipse.home}/plugins/">
<include name="org.eclipse.ui*.jar"/>
<include name="org.eclipse.jdt*.jar"/>
<include name="org.eclipse.core*.jar"/>
<include name="org.eclipse.equinox*.jar"/>
<include name="org.eclipse.debug*.jar"/>
<include name="org.eclipse.osgi*.jar"/>
<include name="org.eclipse.swt*.jar"/>
<include name="org.eclipse.jface*.jar"/>
<include name="org.eclipse.team.cvs.ssh2*.jar"/>
<include name="com.jcraft.jsch*.jar"/>
</fileset>
<fileset dir="../../../">
<include name="hadoop*.jar"/>
</fileset>
</path> <target name="jar" depends="compile" unless="skip.contrib">
<mkdir dir="${build.dir}/lib"/>
<!--
<copy file="${hadoop.root}/build/hadoop-core-${version}.jar" tofile="${build.dir}/lib/hadoop-core.jar" verbose="true"/>
<copy file="${hadoop.root}/build/ivy/lib/Hadoop/common/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
-->
<copy file="${hadoop.root}/hadoop-core-${version}.jar" tofile="${build.dir}/lib/hadoop-core.jar" verbose="true"/>
<copy file="${hadoop.root}/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<jar
jarfile="${build.dir}/hadoop-${name}-${version}.jar"
manifest="${root}/META-INF/MANIFEST.MF">
<fileset dir="${build.dir}" includes="classes/ lib/"/>
<fileset dir="${root}" includes="resources/ plugin.xml"/>
</jar>
</target>
eclipse插件配置
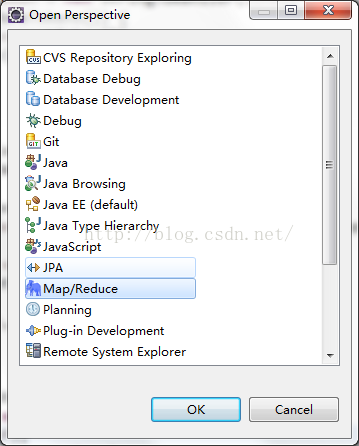


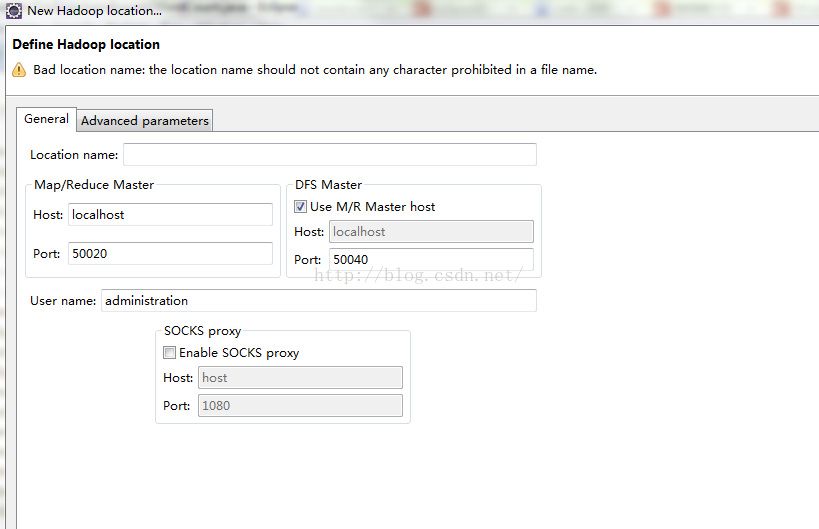
需要填写的地方有几个,
比如之前我们配置的hadoop.tmp.dir的值是/hadoop,而这里默认的值不是这个,需要改正过来。改好之后,点击完成即可。
eclipse插件使用
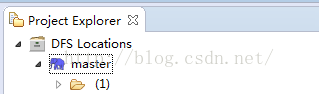
我们可以看见刚刚创建的location在左侧显示出来了,点击箭头,可以查看什么在HDFS中的目录结构,在对应目录上右键,可以进行创建,修改文件之类的操作。
遇到的问题
是不是感觉上边太容易了?没有什么坑嘛,是因为我都拿在这里说了。。。
(1)刚刚第一步编译的hadoop-eclipse-plugin-1.2.1.jar,直接使用的话,在配置location时会有各种错误,通过分析错误日志可以发现是由于缺少jar包导致的,我们先关闭eclipse,对这个jar处理一下。
(2)用压缩工具打开jar包,是打开,不是解压,然后进入lib文件夹下,右键添加文件,在D:\hadoop-1.2.1\lib路径下选择要增加的jar包,如图所示

添加这几个jar包之后,我们回到上级目录,进入META-INF,修改MANIFEST.MF文件。
在倒数第二行,将原来的Bundle-ClassPath值修改为
Bundle-ClassPath: classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-configuration-1.6.jar,lib/commons-httpclient-3.0.1.jar,lib/commons-lang-2.4.jar,lib/jackson-core-asl-1.8.8.jar,lib/jackson-mapper-asl-1.8.8.jar
弄好之后我们保存一下,替换原来的jar包即可。
第二个问题是关于权限问题的,由于在windows上和linux上的文件权限不尽相同,会带来不必要的麻烦,所以我们需要对D:\hadoop-1.2.1\hadoop-core-1.2.1.jar进行修改,不过我按照网上的教程,注释掉部分源码之后,在进行编译,还是会出现错误,不知道是不是我的操作不正确,后来我在网上找到一个修改过的hadoop-core-1.0.3.jar,经测试可以正常使用,我在下边给出连接,大家可以下载使用
hadoop实例
package xavier.hadoop.wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}要运行,需要先配置输入参数,选择run confignation
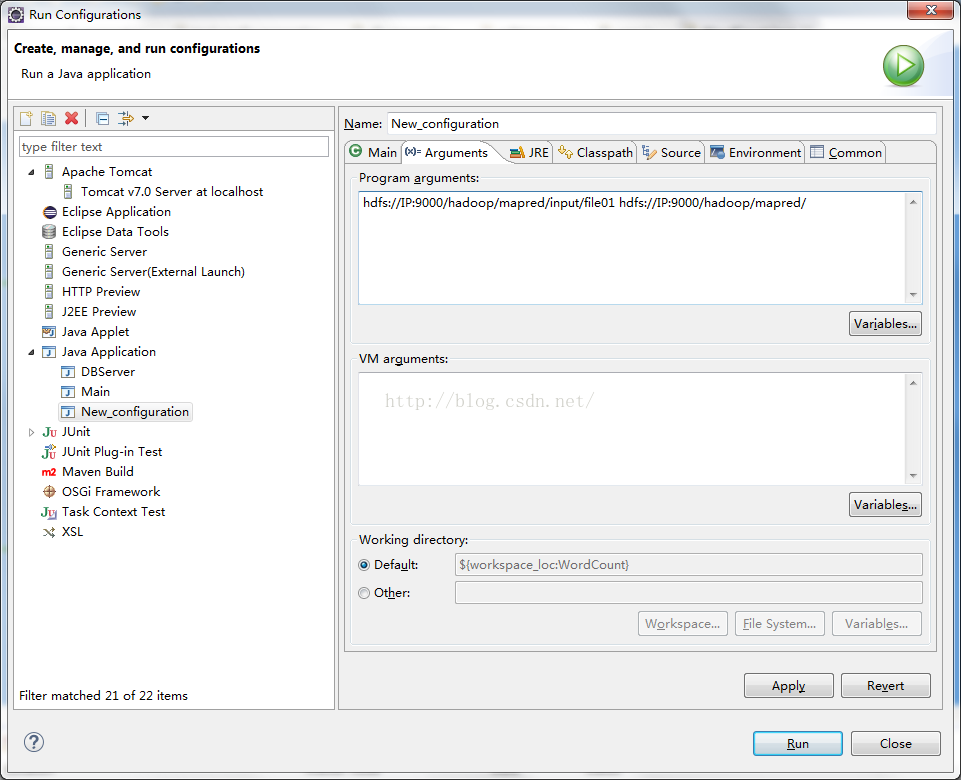
里边的IP换成自己的就ok。
需要注意的是,input/file01需要自己去创建的,file01随便写几个英文单词的句子就可以,最后会输出文件内每个单词出现的数量。
感觉最后叙述的有些混乱了。。。大家明白意思就好。不一定非要按我的配置来,可以灵活变动的。
以上是我首次配置hadoop的过程,其中花费我不少时间,希望这篇文章能帮更多的初学者少走一些弯路。
最后奉上连接
链接: http://pan.baidu.com/s/1qY3thZQ 密码: g53i















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









