






文章目录
前言
面对复杂的链表复制无法下手?这篇文章给你新的思路
一、什么是带随机指针的链表?
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
下面的图可以更加生动的体现出来

复制这个链表的数据域和next是很容易的,但是问题在于如何复制链表中的random指向的部分。没关系,下面的方法可以很好的解决这个问题。
二、解决方法
1.题目展示

题目出自:https://leetcode.cn/problems/copy-list-with-random-pointer/description/
我相信很多人看到这个题目的时候就没有想做下去的欲望,没关系,题目简单来说就是复制出一个一模一样的链表。下面来看这题的思路
2.常规思路
对于这链表很显然我们可以轻松的复制data值和next的指向,用到的代码也很简单,但是对于random的复制很多人有一个误区,如果直接将新链表的random的值等于原来链表的值,那么就会出现这样子的情况

这并不是题目要求的链表,复制出来的链表的random指向是不对的。
对于这个情况,我们可以在复制的时候记下random指向的结点和该结点相对位置,比如:data=13的结点和它random所指向的结点(也就是data=7)的结点的相对位置是-1。然后在复制的时候就可以根据相对位置确定新链表中random的指向。
但是这个方法的缺点是代码复杂,并且时间复杂度为O(N的平方)。所以在这里我就不展开描述,大家有兴趣可以尝试去写。
3.思路2(推荐)
针对上面的情况,有一种方法可以更好的解决
我们在原来链表的每个结点之间插入新的结点,并且将其链接起来,如图所示

对于这样子的结构来说,我们就可以很容易的确定复制出来的链表的random的指向。
比如:对于data=13的新结点的random的指向,就可以等于data=13的旧结点的random指向的结点的next值。
即:Newnode->random = Oldnode->random->next(Newnode就是新插入的结点,Oldnode就是原来链表中data值一样的结点)
并且由图可知,旧结点其实就是新结点的前一个结点,所以这就需要我们在遍历链表的时候要把前一个链表记录下来
如果random指向的是NULL,则我们就可以直接把它置为NULL
确认完random的指向,图就会变成这样子。
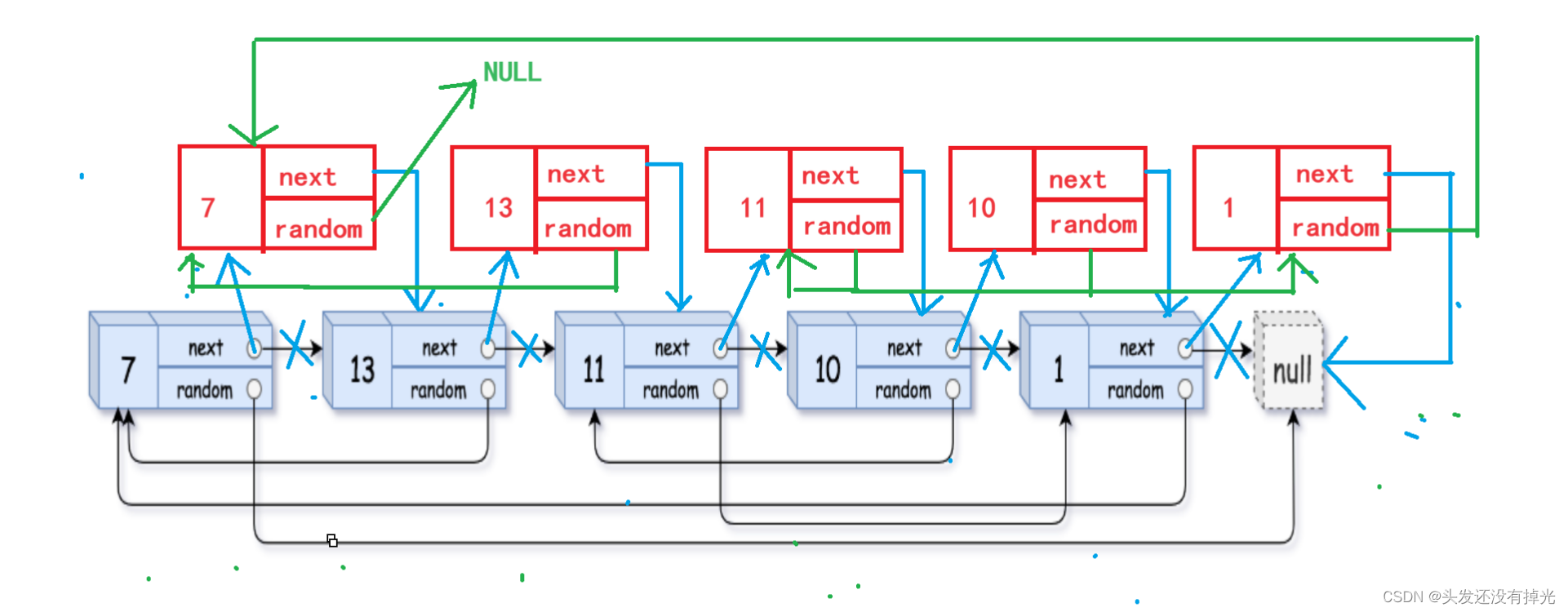
但是到这里并没有完成,下一步我们需要做的是把复制出来的链表从旧链表中剪下来,并且还原本来的链表。这里只要改变每个结点的next指向就可以完成
我们设2个指针一个是oldcur = head。另一个是newcur = head->next
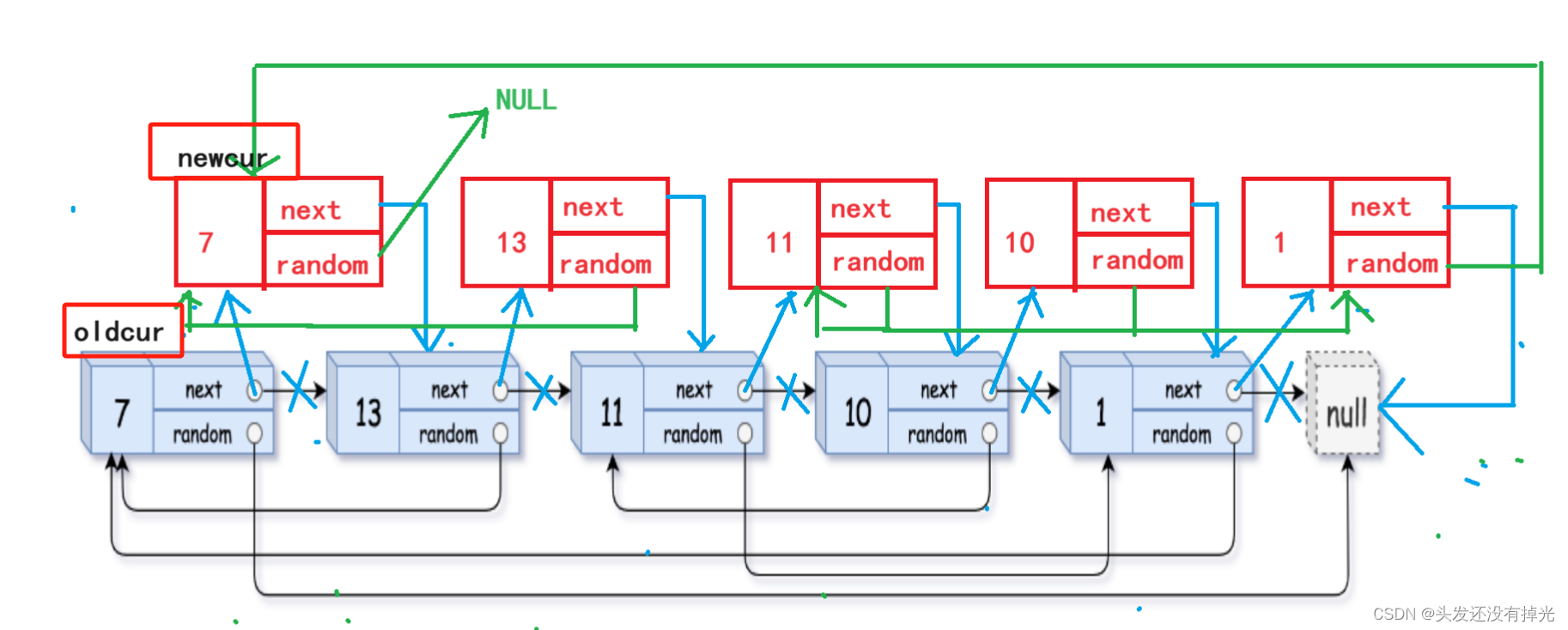
然后我们只要循环执行下面的代码就可以分开2个链表
while (1) {
//复原原来的链表
oldcur->next = newcur->next;
oldcur = oldcur->next;
if (oldcur == NULL)
break;
//链接复制的链表
newcur->next = oldcur->next;
newcur= newcur->next;
}
newcur->next = NULL;这个方法的时间复杂度是O(N),相较于第一个方法有明显的优势。
具体的代码如下:
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if (head == NULL)
return NULL;
Node* oldcur = head;
//在原来链表的每个结点之间插入新结点
while (oldcur != NULL) {
Node* next = oldcur->next;
Node* newnode = (Node*)malloc(sizeof(Node)); //开辟新结点
newnode->val = oldcur->val;
oldcur->next = newnode;
newnode->next = next;
oldcur = next;
}
//设置新结点中的random指向
oldcur = head;
Node* oldcurNext = head->next;
while (oldcur != NULL) {
if (oldcur->random == NULL)
oldcurNext->random = NULL;
else {
oldcurNext->random = oldcur->random->next; //链接复制结点的random
}
oldcur = oldcurNext->next;
if (oldcur != NULL) //因为oldcur会先变成NULL
oldcurNext = oldcur->next;
}
//分离新链表,并且复原原链表
Node* Copyhead = head->next; //把头结点存下来
oldcur = head;
Node* Copucur = head->next;
while (1) {
//复原原来的链表
oldcur->next = Copucur->next;
oldcur = oldcur->next;
if (oldcur == NULL)
break;
//链接复制的链表
Copucur->next = oldcur->next;
Copucur = Copucur->next;
}
Copucur->next = NULL;
return Copyhead;
}
};思路其实是很清晰的:插入新结点->设置新结点random->分开链接并且还原原链表。
三、总结
大家看完了之后如果理解了可以自己动手写出来,一共就3个循环就可以解决这个问题。
















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











