







1、MapReduce编程模型
(1)Record reader:读取hdfs文件;
(2)Map:把hdfs的结果映射成另一种结果,比如WordCount这个例子而言,就是把读进来的文本,映射成一个<字符,1>这样逻辑;
(3)Combiner:很重要的一个功能,很多MR可以没有,但是性能会下降。实现数据减少的操作,在MAP端做一个局部的Reduce;
(4)Partitioner:实现把m个map变成n个reduce,比如hash;
(5)Shuffle and sort:数据交换,用于排序;
(6)Reduce:同样的可以做关联操作等;
(7)Output format:输出;
【1】一个常见WordCount执行逻辑示例图如下:
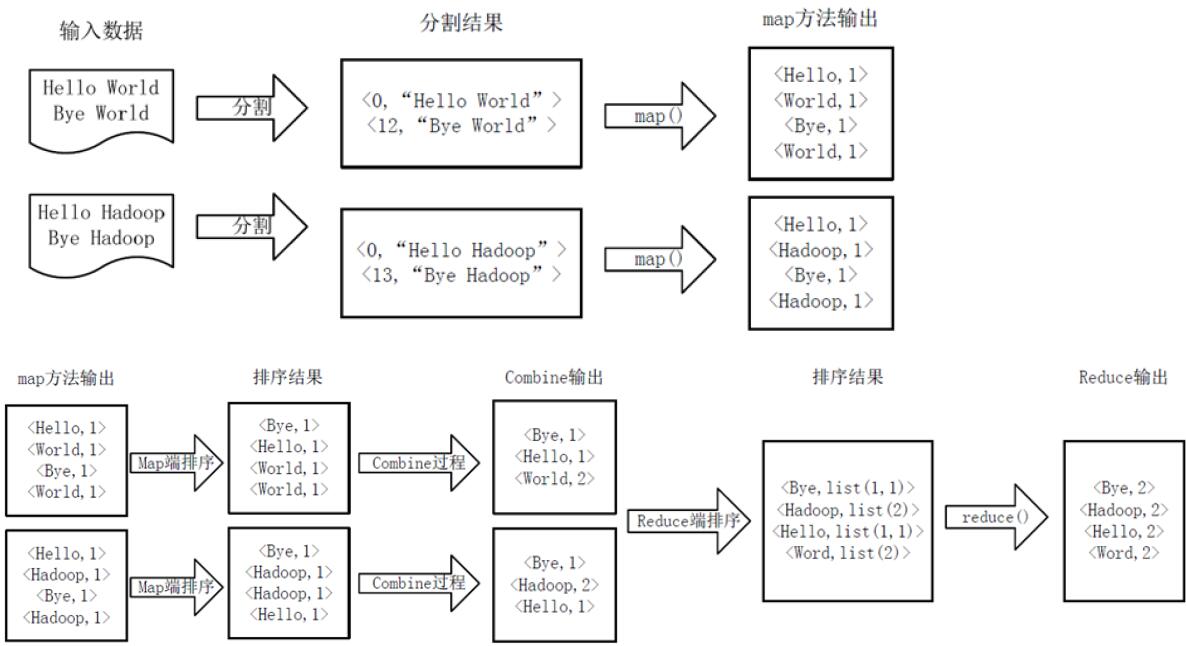
**主要的过程是:**Record reader完成对原始hdfs中(部分)数据进行分割过程;分割结果为键值对形式的(key, value)形式,key可以任何形式,一般在文本中使用偏移量,比如说起始为0,然后value“Hello World”占据12字符;所以“Bye World”从12开始;紧接着就是map()函数处理,得到此时以单词为key,出现次数的value的键值对,同时在Map端进行一个排序,按照key,这里是字母表;接着就是Combine过程,等价于一个局部的Reduce过程,再是编程实现,也是复用Reduce类,主要是实现相同key值的键值对进行排序,相对于数据量大文件来说,提高了相率;经过Combine处理,得到的结果到Shuffle过程,主要是排序后的键值对中value值是list,是迭代器,这点需要注意;最后就是reduce过程。
【2】WordCount实例代码解释如下:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount
{
//Map和Reduce类中类,继承各自的父类。
//输入的key是Object可以任何任性(偏移量);输入的value 第一个text,一行的字符串;
// 接着就是输出key,第二个Text,输出的value是IntWritable
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//不用太关心Context,是上下文,获取一些并行环境的信息。比如说jobid
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken()); //默认是空格
context.write(word, one); //输出
}
}
}
//!Combiner过程是局部reucde,就可以直接用这个reduce复用
//此处的前两个参数是map后两个参数值,对应的。
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable(); //出现的次数
//注意value不是IntWritable,而是迭代器,在写自己的reduce时,这是值得注意的。
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
//Map一般是由文件大小指定,多少个block,有多少个tack;Reduce默认是1,如果只有map,则是设置为0
public static void main(String[] args) throws Exception
{
//通用逻辑
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2)
{
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









