







 本文介绍了Impala的基础知识,包括Dremel理论背景,详细阐述了Impala的架构,如Daemon的组成部分及功能,特别是Statestore Server和Catalog Server的角色。此外,还列举了多种Impala的查询客户端,如Impala Shell、Hue、ODBC/JDBC以及Tableau等。
本文介绍了Impala的基础知识,包括Dremel理论背景,详细阐述了Impala的架构,如Daemon的组成部分及功能,特别是Statestore Server和Catalog Server的角色。此外,还列举了多种Impala的查询客户端,如Impala Shell、Hue、ODBC/JDBC以及Tableau等。
1、Impala的理论基础Dremel
(1)Dremel:基于GFS、MR和bigTable的分析引擎。在论文中,1PB数据3秒可以处理完。
2、Impala的架构
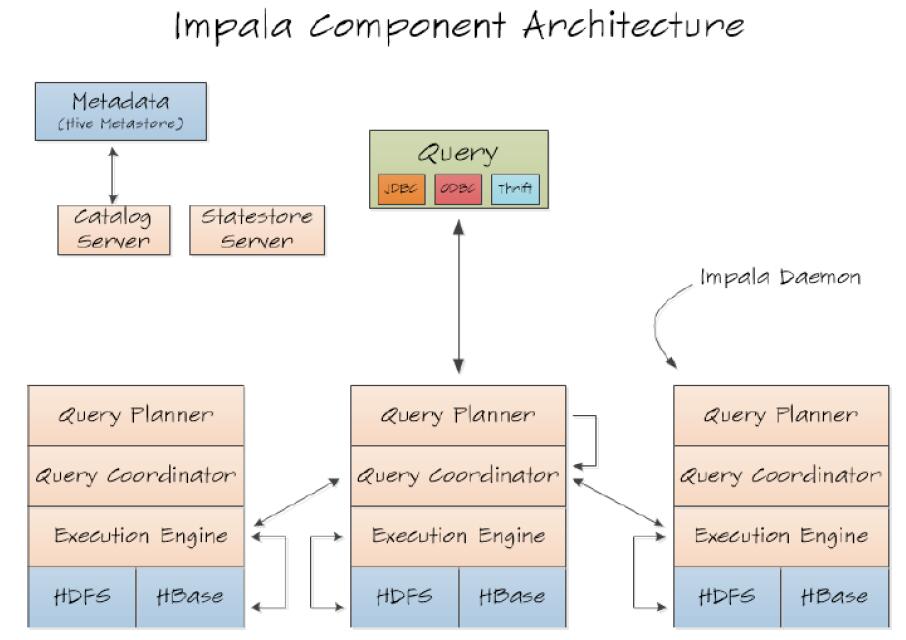
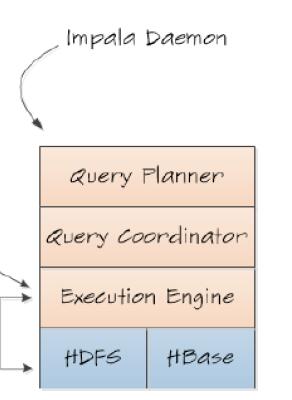
(1)Impala Daemon:包括Query Planner、Query Coordinator、Execution和HDFS和HBase。
也就如下图:
(2)Impala Daemon功能:Query Planner,SQL解析,生成语法树,由Java实现;Query Coordinator,协调本机和其它机器的执行计划;Execution Engine执行具体的操作。
(3)Satestore Server:监控impala Daemon的存活状态。管理真个集群的cluster。
(3)catastore Server:提供元数据存储的位置。向节点提供
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









