






因为工作的原因,需要根据一些关键词来爬取新闻。爬取频率为一周一次,关键词的个数也不多,在100个左右。
感觉selenium可以很好的满足我的需求,虽然慢一点,但是胜在稳定,跑一次程序大概在半个小时左右。
爬取的网站为:搜狗微信
第一步:配置chromedriver
根据自己的google版本下载对应的driver,网址在这里:ChromeDriver - WebDriver for Chrome https://chromedriver.chromium.org
https://chromedriver.chromium.org
为提升效率,这里选择不加载图片。有窗口运行,目的是在网站检测到爬虫程序需要输入验证码时,手动输入。
#不加载图片
options = Options()
prefs = {"profile.managed_default_content_settings.images": 2,
'permissions.default.stylesheet': 2}
options.add_experimental_option("prefs", prefs)
# 声明调用哪个浏览器,本文使用的是Chrome,其他浏览器同理
#指定Chromedriver的路径
service = Service(executable_path=r'C:\Users\DELL\Desktop\chromedriver.exe')
driver = webdriver.Chrome(service=service, options=options)第二步:将爬取到的文章搜集起来
文章爬取的逻辑是:利用外部excel文件中的关键词进行搜索,之后选定符合特定日期的文章。
1、用字典来存储每一篇文章的信息
字典的格式为:
{'product_name': 'XXX', 'product_spyder_content': [article_title,article_text,article_url]}'article_title'代表文章的标题;article_text代表与搜索关键词相符合的部分内容;article_url代表文章的链接。
2、创建一个空列表
将所有的文章存储起来,循环所有的关键词进行搜索,最后的输出结果为一个列表中嵌套多个字典,每个字典里面又嵌套一个列表。
#创建一个空列表,用来存储所有原材料爬取的文章内容
all_product_content_list = []
input_text = 'y'
#创建一个空字典,用来存储每个原材料的爬取文章内容
product_spyder_content = {}第三步:分析目标网站
1、打开搜狗微信
#打开浏览器
driver.get("https://weixin.sogou.com/")
driver.page_source
print("已打开浏览器")
driver.implicitly_wait(60)2、在搜索框中输入需要查询的关键词
首先需要定位到搜索框,根据唯一的class name可以定位。
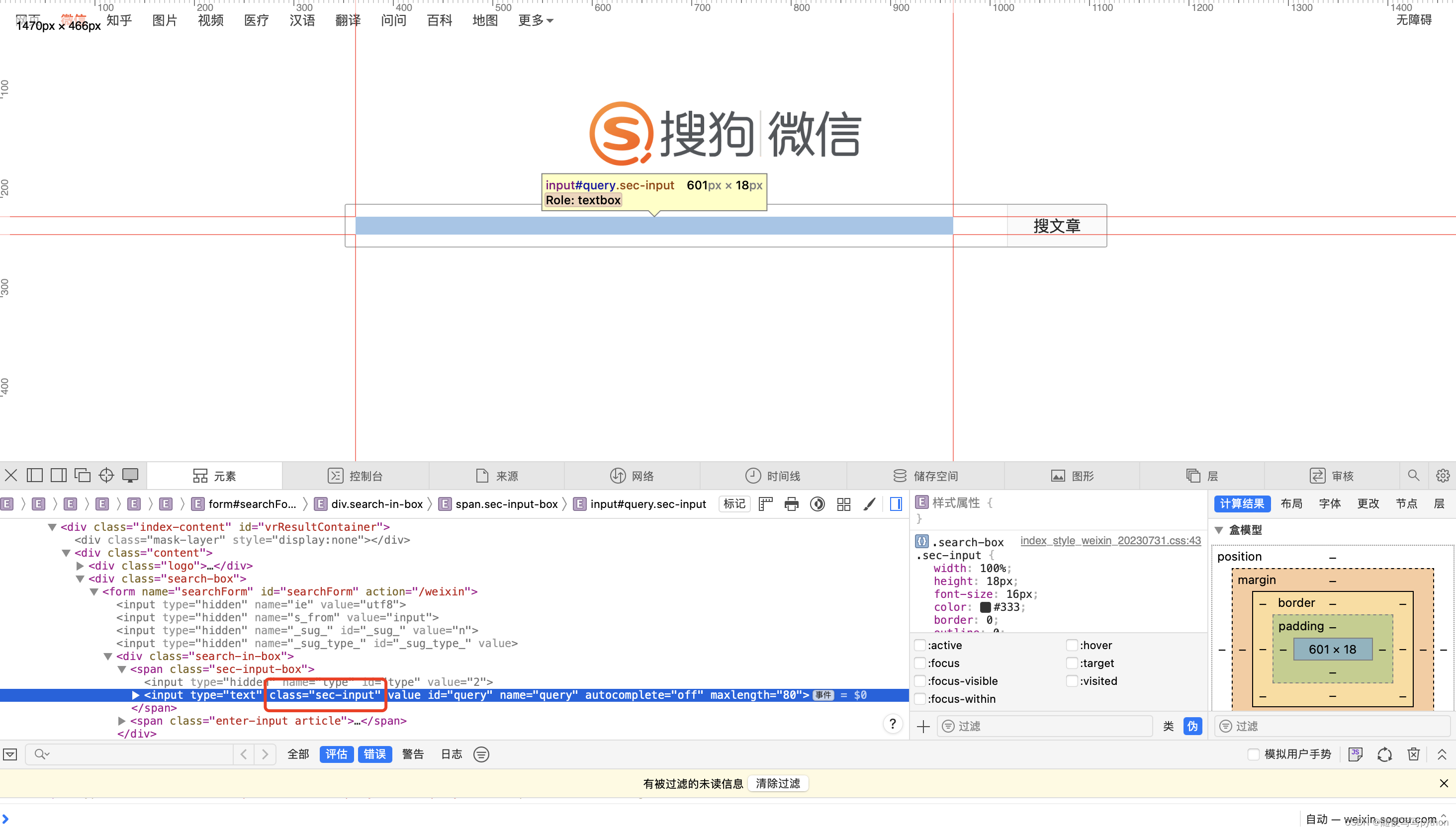
find_elements()的到的是一个列表,所以需要用[数字]的形式来指定其在列表中的位置;find_element()则是直接返回搜索到的第一个结果。具体要使用哪种形式,可以根据自己的实际需要来选择。
By.的方法有很多,网上的教程有很多,有兴趣的同学可以自己搜索下。
# 搜索框输入
driver.find_elements(By.CLASS_NAME, "sec-input")[0].clear() #在每次输入关键词之前先清空之前输入的内容
driver.find_elements(By.CLASS_NAME, "sec-input")[0].send_keys(search_text)
print(str(search_text)+'已输入')3、模拟点击【搜文章】按钮
输入关键词后点击搜索才能返回结果。跟上面一样,也需要定位到该按钮,找到class name。
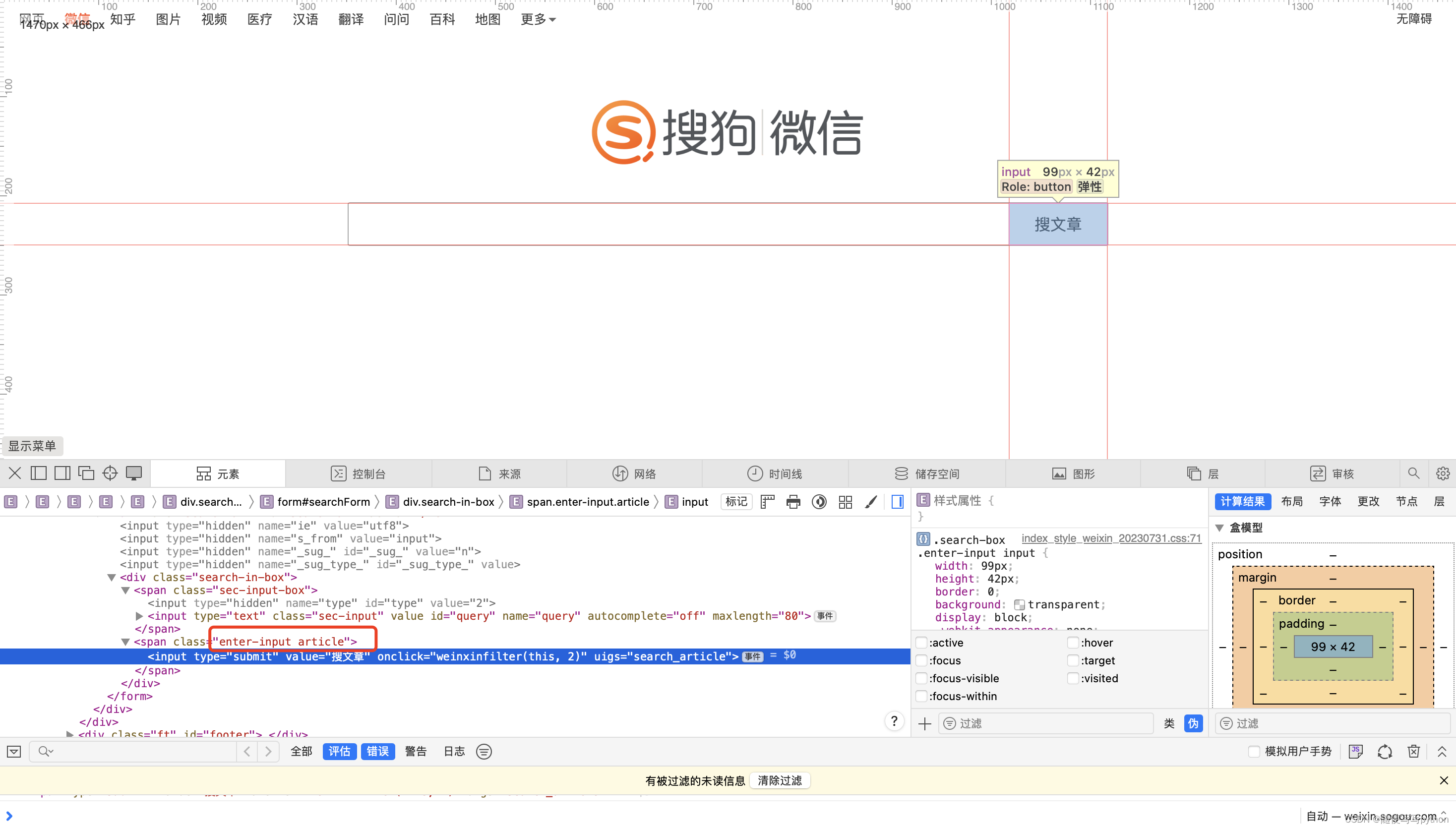
#模拟输入回车按键
driver.find_element(By.CLASS_NAME, "enter-input.article").click()
driver.implicitly_wait(3)
print('已获取搜索结果')4、判断搜索结果的页码数
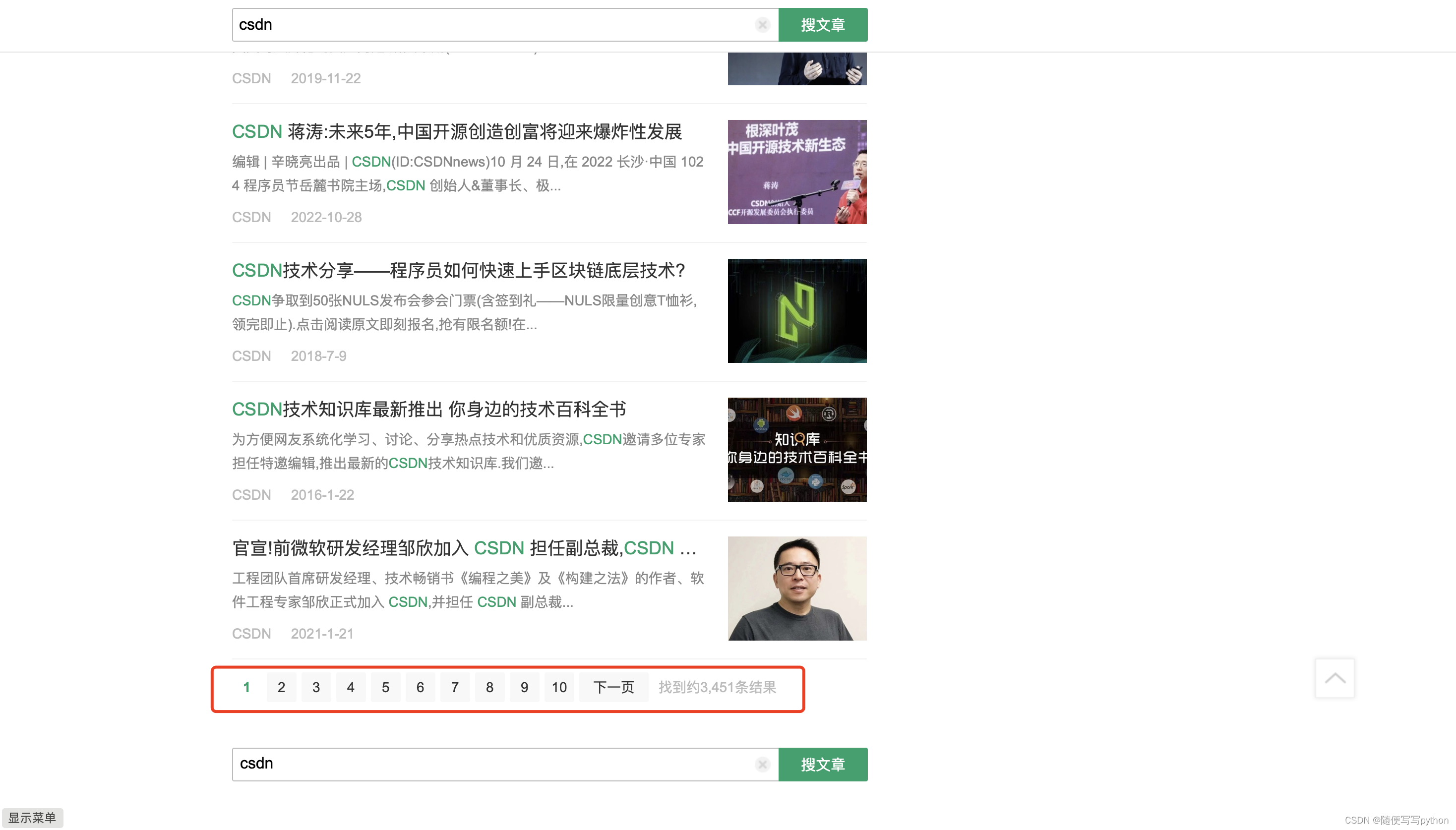
比如我们搜索csdn,可以看到每页有10篇文章,一共有10页的搜索结果,那我们就需要点击9次【下一页】按钮,将所有的搜索结果都拿到。但是有的时候会出现搜索结果没有10页,甚至只有1页。而且实战中发现每页显示的搜索结果也并不总是10个,有时会少于10个。
为方便后续的操作,需要判断搜索结果的页数。
我们打开网页检查器看一下,在p-fy下面刚好有10个分支,刚好对应10页,所以我们可以以此来判断页码数。
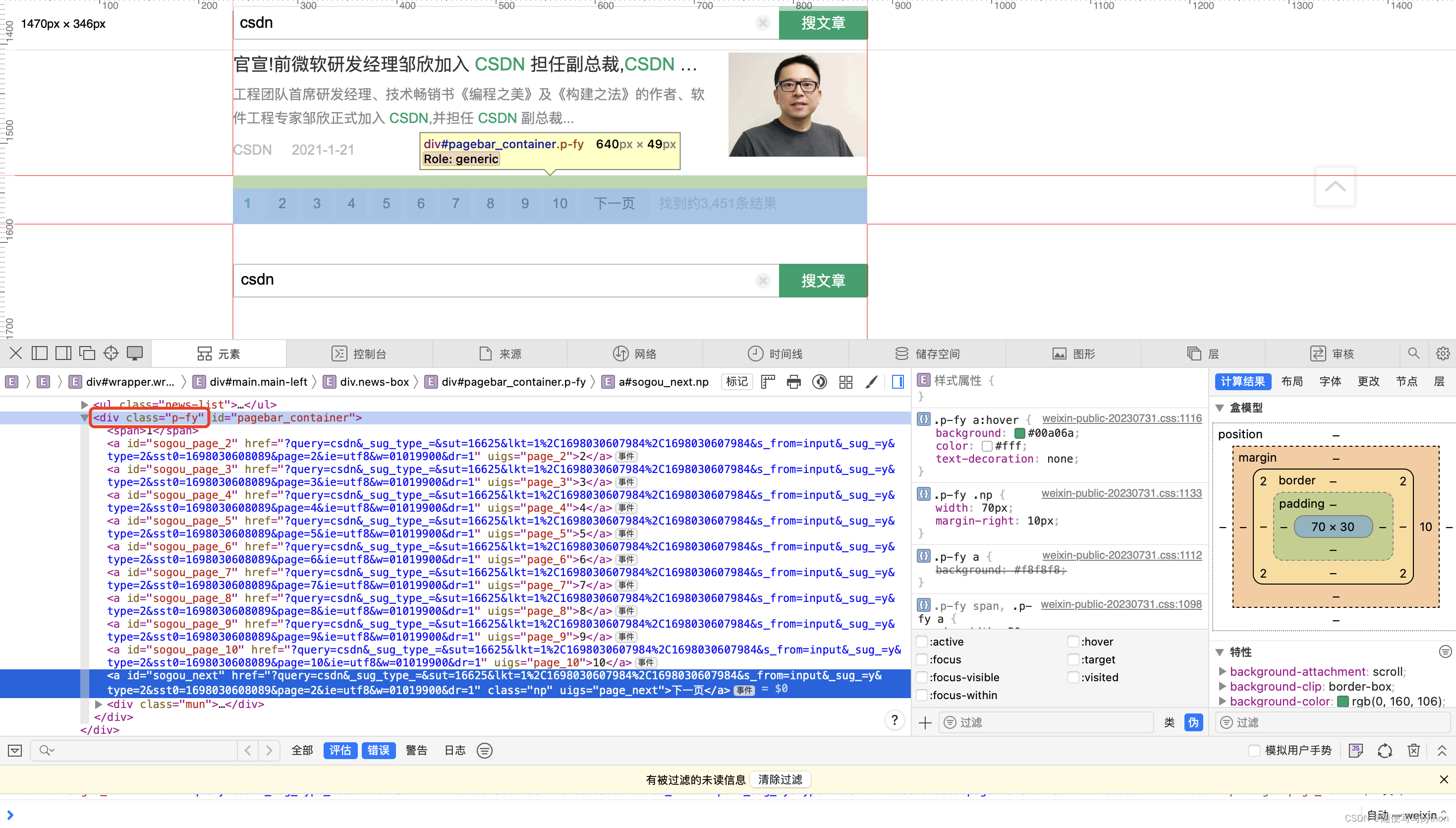
当然有的时候可能没有搜索结果,或者只有1页,这时是没有【下一页】的按钮的,这时就需要我们特别处理下。
#判断搜索结果一共多少页
try:
page = len(driver.find_element(By.CLASS_NAME, 'p-fy').find_elements(By.XPATH, 'a'))
except Exception as e:
page = 15、判断每一页有多少篇文章
new-list下面包含了所有的文章,可以通过查询 <li 来判断文章的篇数。
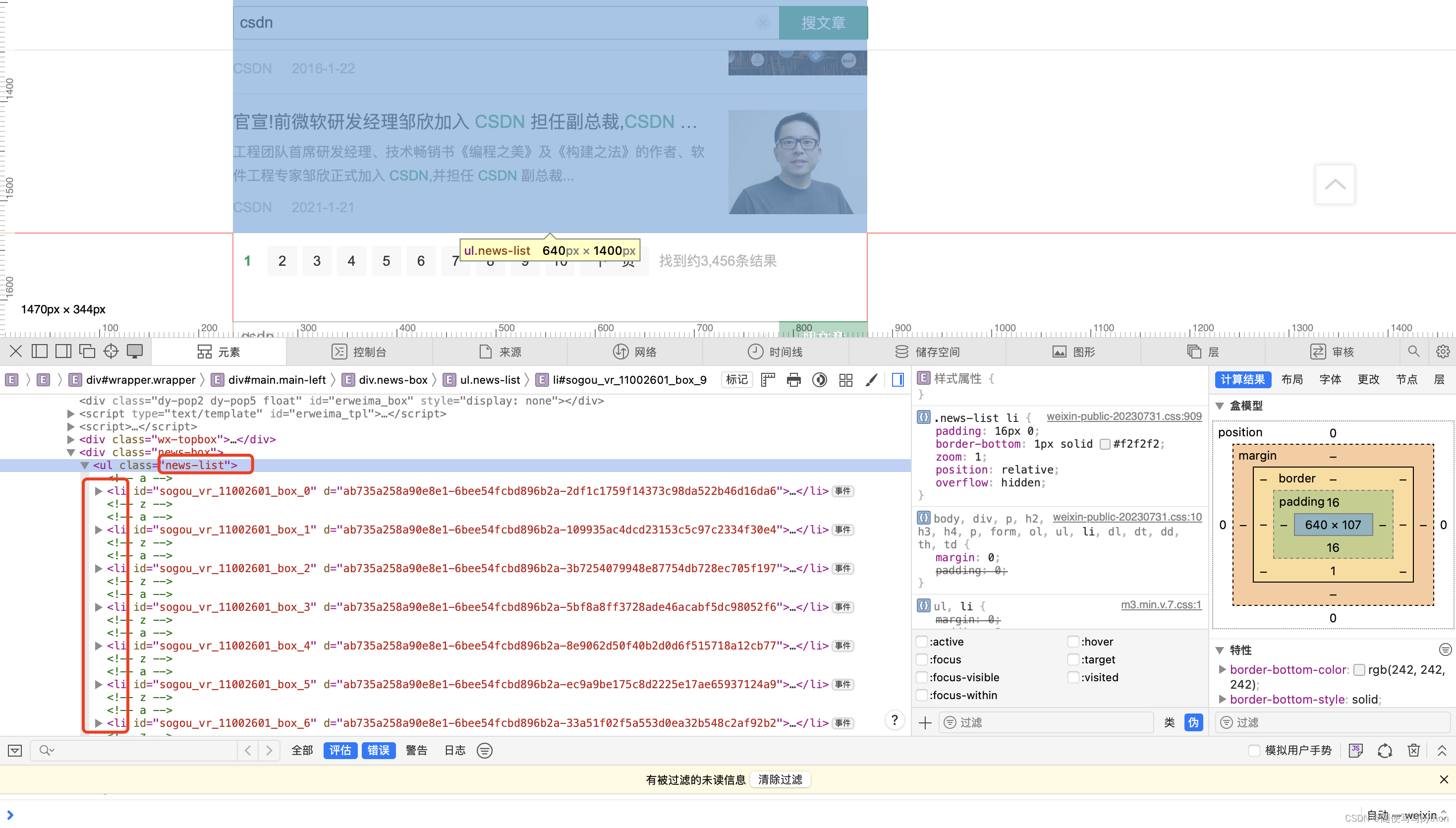
each_page_result_num = driver.find_element(By.CLASS_NAME, 'news-list').find_elements(By.XPATH, 'li')6、找到发布日期符合条件文章的内容
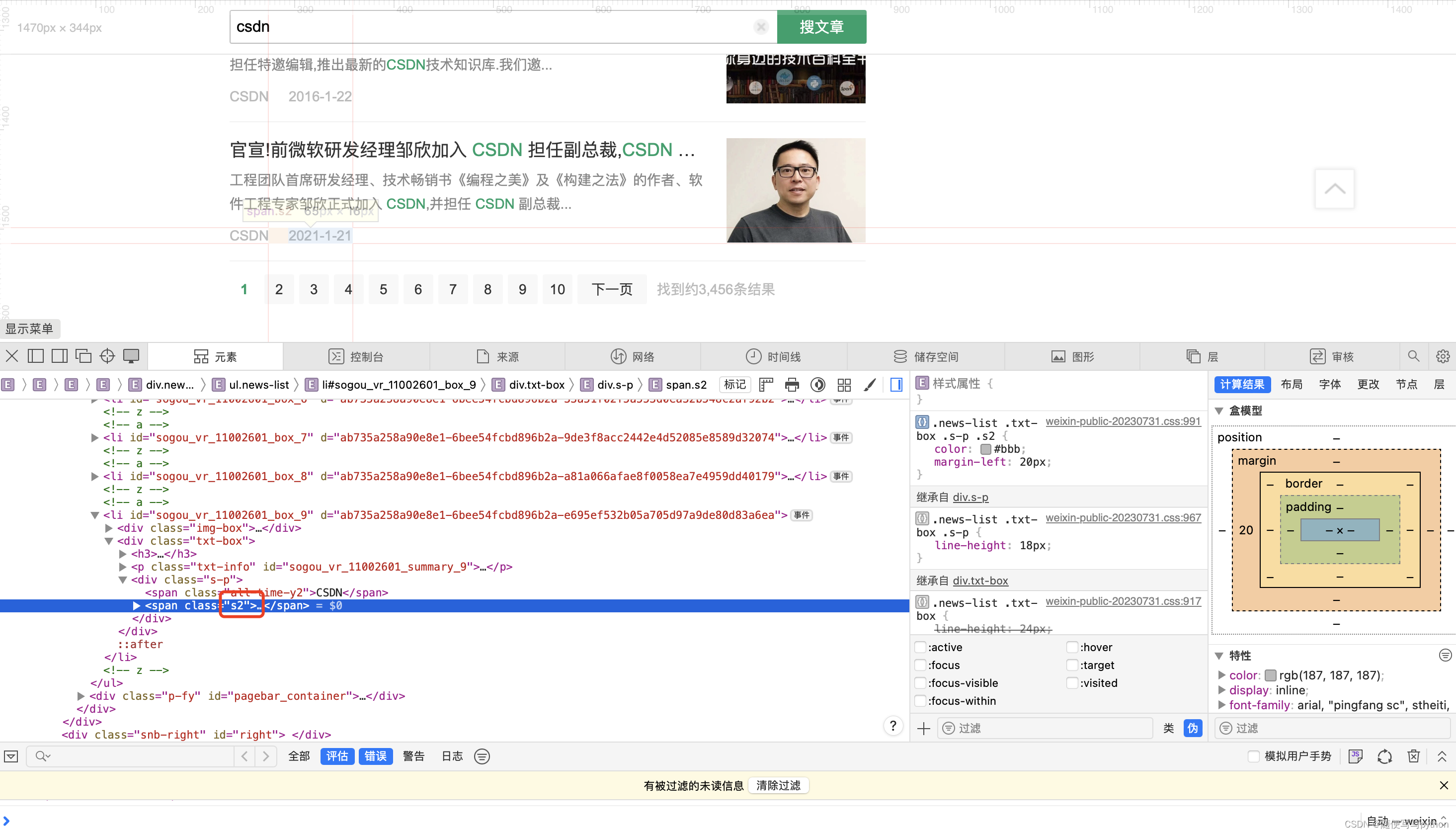
#找到文章的发布日期
one_page_each_article_date = txt_box.find_element(By.CLASS_NAME, "s2")如果文章的日期符合条件,则提取内容:
#如果日期匹配,则抓取数据
if one_page_each_article_date.text in spyder_article_date:
#创建一个空列表,用来储存爬取到的文章信息,只有日期匹配才新建列表存储信息
article_content = []
dict_key_num += 1
dict_key = 'article_' + str(dict_key_num)
print('日期匹配')
article_title = txt_box.find_element(By.XPATH, 'h3').get_attribute('textContent')
print(article_title)
article_text = txt_box.find_element(By.CLASS_NAME, 'txt-info').get_attribute('textContent')
print(article_text)
article_url = txt_box.find_element(By.TAG_NAME, 'a').get_attribute('href')
print(article_url)第四部分:关键词存储和爬取信息处理
我把要搜索的关键词放在了excel文件【sheet1】里面,如果需要更改的话比较方便。在程序运行的时候会逐行由左至右逐渐搜索,输入的关键词依次为:金属钠产能、金属钠供需、金属钠市场、金属钠价格、金属钠、六氟丙烯产能.....
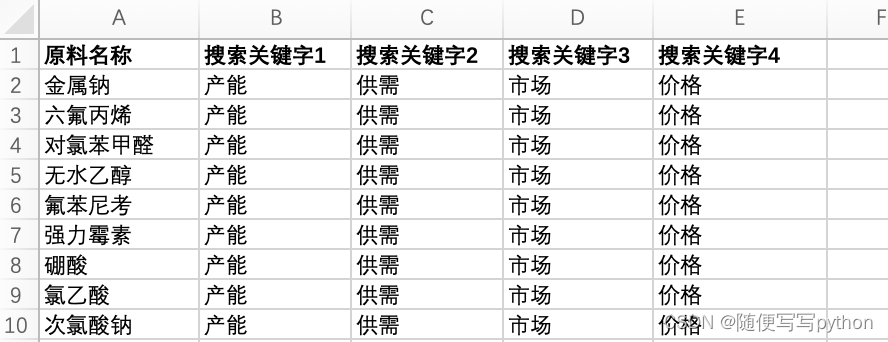
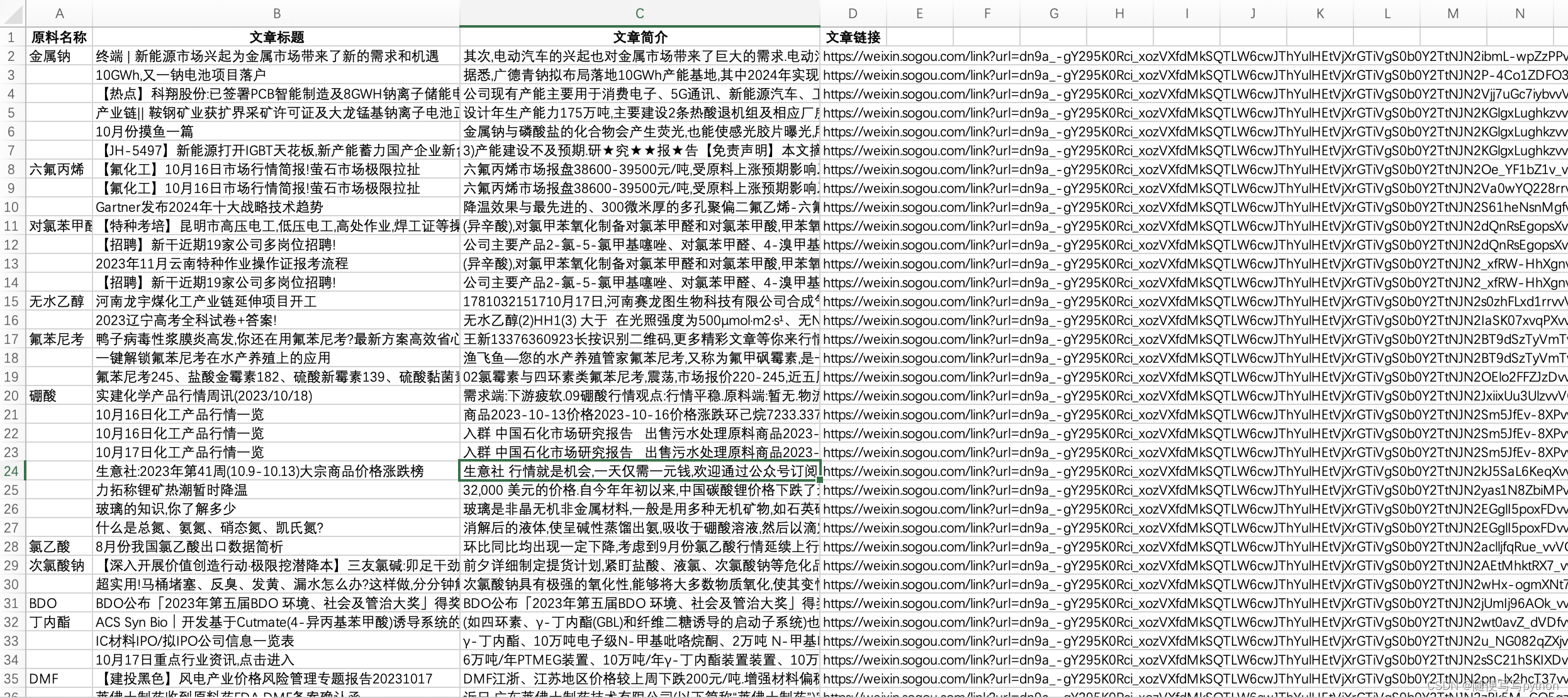
获取的文章信息放在了同一个excel的【sheet2】中,最终的结果如下:
第五部分:总结
文章的爬取过程比较简单,只要定位到对应的位置就可以了。在写循环的时候需要先确定搜索结构的页码数和每页的文章数目。在循环出现意外的时候,需要暂停程序,手动输入验证码后继续。最后在将结果处理完成后可以将文章发在钉钉工作群中,完整的代码会贴在后面。
附:完整代码
function.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.chrome.options import Options
import time
import numpy as np
import re
from settings import spyder_article_date
def spyder_function(search_input):
#不加载图片
options = Options()
prefs = {"profile.managed_default_content_settings.images": 2,
'permissions.default.stylesheet': 2}
options.add_experimental_option("prefs", prefs)
# 声明调用哪个浏览器,本文使用的是Chrome,其他浏览器同理
#没有把Chromedriver放到python安装路径
service = Service(executable_path=r'C:\Users\DELL\Desktop\chromedriver.exe')
driver = webdriver.Chrome(service=service, options=options)
#创建一个空列表,用来存储所有原材料爬取的文章内容
all_product_content_list = []
input_text = 'y'
#创建一个空字典,用来存储每个原材料的爬取文章内容
product_spyder_content = {}
dict_key_num = 0
cycle_time = 0
while input_text == 'y' or 'Y':
try:
#打开浏览器
driver.get("https://weixin.sogou.com/")
driver.page_source
print("已打开浏览器")
driver.implicitly_wait(60)
print("等待加载完成")
print('开始主程序')
time_start = time.time()
search_text = search_input
# 搜索框输入
driver.find_elements(By.CLASS_NAME, "sec-input")[0].clear()
driver.find_elements(By.CLASS_NAME, "sec-input")[0].send_keys(search_text)
print(str(search_text)+'已输入')
#模拟输入回车按键
driver.find_element(By.CLASS_NAME, "enter-input.article").click()
driver.implicitly_wait(3)
#time.sleep(1)
print('已获取搜索结果')
#判断搜索结果一共多少页
try:
page = len(driver.find_element(By.CLASS_NAME, 'p-fy').find_elements(By.XPATH, 'a'))
except Exception as e:
page = 1
product_spyder_content['product_name'] = search_text
#找到指定日期发布的文章
#点击【下一页按钮】一直到最后一页,点击次数为页码数(page)-1
for p in range(page-1):
#判断每一页有多少个搜索结果
each_page_result_num = driver.find_element(By.CLASS_NAME, 'news-list').find_elements(By.XPATH, 'li')
#print(len(each_page_result_num))
for p_2 in range(len(each_page_result_num)):
#找到每一篇文章
txt_box = driver.find_elements(By.CLASS_NAME, 'txt-box')[p_2]
cycle_time += 1
print('第' + str(cycle_time) + '篇文章检查完毕')
#找到文章的日期
one_page_each_article_date = txt_box.find_element(By.CLASS_NAME, "s2")
#如果日期匹配,则抓取数据
if one_page_each_article_date.text in spyder_article_date:
#创建一个空列表,用来储存爬取到的文章信息,只有日期匹配才新建列表存储信息
article_content = []
dict_key_num += 1
dict_key = 'article_' + str(dict_key_num)
print('日期匹配')
article_title = txt_box.find_element(By.XPATH, 'h3').get_attribute('textContent')
print(article_title)
article_text = txt_box.find_element(By.CLASS_NAME, 'txt-info').get_attribute('textContent')
print(article_text)
article_url = txt_box.find_element(By.TAG_NAME, 'a').get_attribute('href')
print(article_url)
article_content.append(article_title)
article_content.append(article_text)
article_content.append(article_url)
product_spyder_content[dict_key] = article_content
all_product_content_list.append(product_spyder_content)
else:
continue
#点击下一页
try:
driver.find_element(By.CLASS_NAME, 'np').click()
time.sleep(np.random.random())
except Exception as e:
continue
print('==============='+str(search_text)+'爬取完成==================')
#print(product_spyder_content)
break
except Exception as e:
print(e)
print('请在drive中输入验证码,并确定')
#如果报错,暂停
#product_spyder_content.pop(dict_key)
#picture = driver.find_element(By.CLASS_NAME, 'p4').find_element(By.XPATH, 'a').get_attribute('scr')
#print(picture)
input_text = input('是否继续(y/n)')
continue
driver.close()
time_end = time.time()
print('用时:'+str('%.2f' % (time_end - time_start))+'秒')
#print(all_product_content_list)
return all_product_content_listsettings.py
import openpyxl as op
from openpyxl import load_workbook
#设定需要爬取的日期(一周)
spyder_article_date = ['2023-10-16', '2023-10-17', '2023-10-18', '2023-10-19', '2023-10-20', '2023-10-21', '2023-10-22']
#获取需要爬取的产品关键词
spyder_product_keyword_file = op.load_workbook(r'C:\Users\DELL\Desktop\python\sogou_wechat\原材料新闻微信搜索.xlsx')
ws_1 = spyder_product_keyword_file['Sheet1']
ws_2 = spyder_product_keyword_file['Sheet2']
name_list = []
spyder_product_keyword_max_row = ws_1.max_row
for j in range(spyder_product_keyword_max_row-1):
name_list.append(ws_1.cell(j+2, 1).value)
all_spyder_product_keyword_list = []
#所有产品分为一组进行爬取
for i in range(spyder_product_keyword_max_row-1):
spyder_product_keyword_list = []
key_word_1 = ws_1.cell(i+2, 1).value
key_word_2 = ws_1.cell(i+2, 1).value + ws_1.cell(i+2, 2).value
key_word_3 = ws_1.cell(i+2, 1).value + ws_1.cell(i+2, 3).value
key_word_4 = ws_1.cell(i+2, 1).value + ws_1.cell(i+2, 4).value
key_word_5 = ws_1.cell(i+2, 1).value + ws_1.cell(i+2, 5).value
spyder_product_keyword_list.append(key_word_1)
spyder_product_keyword_list.append(key_word_2)
spyder_product_keyword_list.append(key_word_4)
spyder_product_keyword_list.append(key_word_4)
spyder_product_keyword_list.append(key_word_5)
all_spyder_product_keyword_list.append(spyder_product_keyword_list)
main_process.py
from settings import all_spyder_product_keyword_list
from function import spyder_function
def pro_group_spyder():
group_product_article_list = []
for i in range(len(all_spyder_product_keyword_list)):
each_product_article_result_list = []
for j in range(5):
each_product_article_result = spyder_function(search_input=all_spyder_product_keyword_list[i][j])
each_product_article_result_list.append(each_product_article_result)
group_product_article_list.append(each_product_article_result_list)
return group_product_article_list
print(all_spyder_product_keyword_list)product_group.py
import time
from main_process import pro_group_spyder
from settings import ws_2, name_list, spyder_product_keyword_file, spyder_product_keyword_max_row
def main():
main_start_time = time.time()
#所有产品:
a = pro_group_spyder()
for m in range(len(a)):
b = []
ws_2.cell(m*30+10, 1).value = name_list[m]
for li in a[m]:
if li != []:
b.append(li)
#print(b)
#print(len(b))
for each_list in b:
article_num = 0
for each_dict in each_list:
article_num += 1
art = str('article_') + str(article_num)
for j in range(3):
ws_2.cell(m*30+10+article_num-1, 2+j).value = each_dict[art][j]
spyder_product_keyword_file.save(r'C:\Users\DELL\Desktop\python\sogou_wechat\原材料新闻微信搜索.xlsx')
main_end_time = time.time()
print('程序运行完成,总用时:' + str('%.2f' % (main_end_time - main_start_time)) + '秒')
if __name__ == '__main__':
main()钉钉发送文章.py
以下代码来自他人,我只在基础上根据自己的需求稍做了些修改
import time
import hmac
import hashlib
import base64
import json
import urllib.parse
import urllib.request
import openpyxl as op
from openpyxl import load_workbook
#===============需要修改的参数设置===================
news_title = '一周新闻回顾'
picture_url = 'https://s2.loli.net/2023/10/23/1dXB52JurTomKfL.png'
news_file_dic = 'XXXX.xlsx'
class DingDingWebHook(object):
def __init__(self, secret=None, url=None):
"""
:param secret: 安全设置的加签秘钥
:param url: 机器人没有加签的WebHook_url
"""
if secret is not None:
secret = secret
else:
secret = 'xxxxxxx' # 加签秘钥
if url is not None:
url = url
else:
url = 'xxxxxxxx' # 无加密的url
timestamp = round(time.time() * 1000) # 时间戳
secret_enc = secret.encode('utf-8')
string_to_sign = '{}\n{}'.format(timestamp, secret)
string_to_sign_enc = string_to_sign.encode('utf-8')
hmac_code = hmac.new(secret_enc, string_to_sign_enc, digestmod=hashlib.sha256).digest()
sign = urllib.parse.quote_plus(base64.b64encode(hmac_code)) # 最终签名
self.webhook_url = url + '×tamp={}&sign={}'.format(timestamp, sign) # 最终url,url+时间戳+签名
def send_meassage(self, data):
"""
发送消息至机器人对应的群
:param data: 发送的内容
:return:
"""
header = {
"Content-Type": "application/json",
"Charset": "UTF-8"
}
send_data = json.dumps(data) # 将字典类型数据转化为json格式
send_data = send_data.encode("utf-8") # 编码为UTF-8格式
request = urllib.request.Request(url=self.webhook_url, data=send_data, headers=header) # 发送请求
opener = urllib.request.urlopen(request) # 将请求发回的数据构建成为文件格式
print(opener.read()) # 打印返回的结果
#9个新闻的函数
def get_news(num):
wb = op.load_workbook(news_file_dic)
ws = wb['Sheet2']
links = []
a = {'title': news_title, 'picURL': picture_url}
links.append(a)
for i in range(9):
dict = {}
dict['title'] = ws.cell(2 + i + num*9, 2).value # 文章标题
dict['messageURL'] = ws.cell(2 + i + num*9, 4).value # 文章链接
links.append(dict)
return links
#剩下的不足9个新闻的函数
def get_news_2(num, mod):
wb = op.load_workbook(news_file_dic)
ws = wb['Sheet2']
links = []
a = {'title': news_title, 'picURL': picture_url}
links.append(a)
for i in range(mod):
dict = {}
dict['title'] = ws.cell(2 + i + num*9, 2).value # 文章标题
dict['messageURL'] = ws.cell(2 + i + num*9, 4).value # 文章链接
links.append(dict)
return links
if __name__ == '__main__':
n = 0
my_secret = 'xxxxxx'
my_url = 'xxxxxxx'
wb = op.load_workbook(news_file_dic)
ws = wb['Sheet2']
news_num = ws.max_row - 1
if news_num > 9:
div = news_num // 9 #取模
mod = news_num % 9 #取余数
for i in range(div):
links = get_news(num=n)
my_data = {
"msgtype": "feedCard",
"feedCard": {
"links": links
}
}
dingding = DingDingWebHook(secret=my_secret, url=my_url)
dingding.send_meassage(my_data)
n += 1
for j in range(mod):
links = get_news_2(num=n, mod=mod)
my_data = {
"msgtype": "feedCard",
"feedCard": {
"links": links
}
}
dingding = DingDingWebHook(secret=my_secret, url=my_url)
dingding.send_meassage(my_data)
webhook = 'xxxxx'
secrets = 'xxxxx'

















 579
579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









