







MapReduce 计算框架
MapReduce是一种分布式计算框架,非常适合于解决并行计算问题,比如TopN、贝叶斯分类等。这是一种两阶段的计算模型,主要分为Map和Reduce两个步骤。Map即数据的映射,用于把一组键值对映射成另一组新的键值对,而Reduce以Map阶段的输出结果作为输入,对数据做化简、合并等操作。在具体的JVM实现上,MapReduce模型对方法进行了高阶抽象。Map阶段由对应的map函数的逻辑实现,Reduce阶段则由reduce函数的逻辑实现,他们构成MapReduce处理过程的整个核心。在Main函数入口之处,申请对应的Job,指定相应的Mapper和Reducer继承类,以及其输入输出类型等相关信息,即可运行一个完整的MapReduce任务。
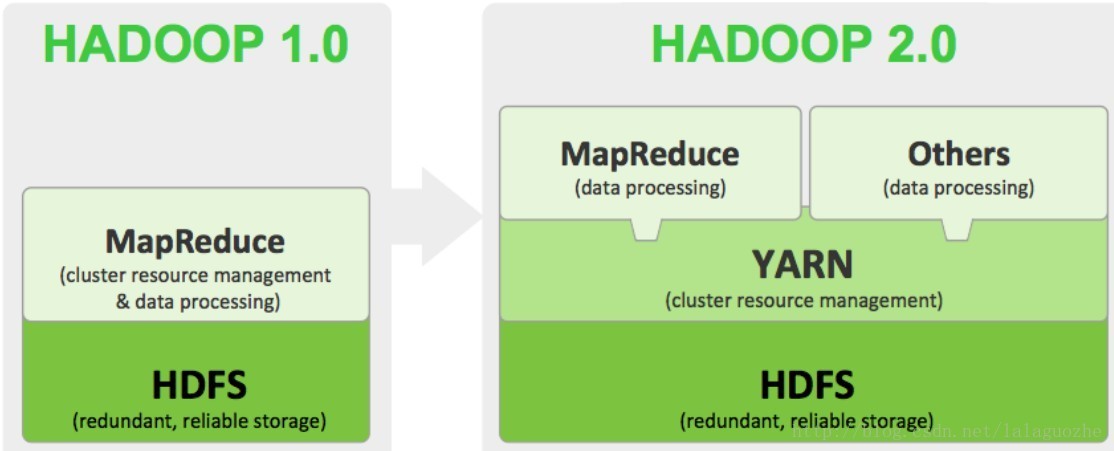
在Hadoop生态系统中,MapReduce是基于底层HDFS的一个计算框架,而它的上层又可以是Hive、Pig等数据仓库框架,或者是Mahout这样的数据挖掘工具。第一代Hadoop生态以MapReduce为核心,但是随着不断的发展,其扩展性差、资源利用率低、可靠性等问题都暴露出来。于是第二代MapReduce架构就引入了YARN,用来专门负责底层的资源管理。在YARN之上可以运行多种计算框架,除了MapReduce,还可以是Gigraph图计算、Spark迭代计算和Storm实时流计算模型等等。二代MapReduce与一代相比,具有相同的编程模型和数据处理引擎,区别就是运行时环境发生了改变。从用户端来看,程序开发调用的 API 及接口大部分保持兼容,这样就不需要对原有代码做大的修改。
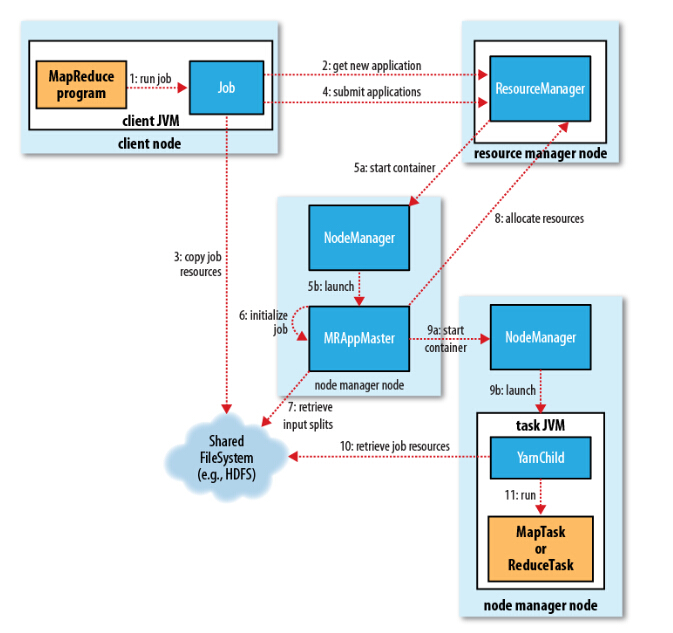
在YARN平台上,用户提交的一个MapReduce应用称作一个job。以下是一个job详细的运行过程(内容节选自博客[1],由于写的太好就几乎照搬了):
Job 提交过程
1、向ResourceManager申请application ID,此ID为该MapReduce的jobId。
2、检查output的路径是否正确,是否已经被创建。
3、计算input的splits。
4、拷贝运行job 需要的jar包、配置文件以及计算input的split 到各个节点。
5、在ResourceManager中调用submitAppliction()方法,执行jobJob 的初始化过程
1、当ResourceManager收到了submitApplication()方法的调用通知后,Scheduler开始分配Container,随之ResouceManager发送ApplicationMaster进程,告知每个NodeManager管理器。
2、由ApplicationMaster决定如何运行tasks,如果job数据量比较小,ApplicationMaster便选择将tasks运行在一个JVM中。job大小的判别标准可以是job的mappers数量小于10个,或者只有一个reducer,或者读取的文件大小要小于一个HDFS block等,这些可通过修改配置项mapreduce.job.ubertask.maxmaps, mapreduce.job.ubertask.maxreduces 以及 mapreduce.job.ubertask.maxbytes 进行调整。
3、在运行tasks之前,ApplicationMaster将会调用setupJob()方法,随之创建output的输出路径Task 任务分配
1、接下来ApplicationMaster向ResourceManager请求Containers用于执行map与reduce的tasks,这里map task的优先级要高于reduce task,当所有的map tasks结束后,随之进行sort,最后进行reduce task的开始。
2、运行tasks是需要消耗内存与CPU资源的,默认情况下,map和reduce的task资源分配为1024MB与一个核,(可修改运行的最小与最大参数配置mapreduce.map.memory.mb, mapreduce.reduce.memory.mb, mapreduce.map.cpu.vcores, mapreduce.reduce.reduce.cpu.vcores.)Task 任务执行
1、这时一个task已经被ResourceManager分配到一个Container中,由ApplicationMaster告知NodeManager启动Container,这个task将会被一个主函数为YarnChild的java application运行,但在运行task之前,首先定位task需要的jar包、配置文件以及加载在缓存中的文件。
2、YarnChild运行于一个专属的JVM中,所以任何一个map或reduce任务出现问题,都不会影响整个NodeManager的crash或者hang。
3、每个task都可以在相同的JVM task中完成,随之将完成的处理数据写入临时文件中。运行进度与状态更新
1、每个job以及每个task都有一个包含job(running,successfully completed,failed)的状态,以及value的计数器,状态信息及描述信息。
2、当一个task开始执行,它将会保持运行记录,记录task完成的比例,对于map的任务,将会记录其运行的百分比,对于reduce来说可能复杂点,但系统依旧会估计reduce的完成比例。当一个map或reduce任务执行时,子进程会持续每三秒钟与ApplicationMaster进行交互。Job 完成
最终,ApplicationMaster会收到一个job完成的通知,随后改变job的状态为successful。最终,ApplicationMaster与task Containers被清空。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









