







概述
1. 简介
针对Hadoop 1.x中NameNode的单点故障(SPOF)问题,Hadoop2.0的HA(High Avalability,高可用性)机制通过使用两个NameNode(NN)实现对NameNode 的热备来解决这一问题。一个Active NameNode(ANN),状态是active;另一个是Standby NameNode(SNN),状态是standby。两者的状态可以切换,但有且只能有1个是active状态,而且只有ANN提供对外服务。如果ANN出现故障或是机器需要升级维护,这时可将NameNode 很快的切换到SNN,保证集群继续正常工作。为了保持ANN和SNN的数据同步,两个节点通过NFS(Network File System)或者一组JN(JournalNode,数量为奇数,可以是3,5,7…,2n+1)来共享数据。在一个典型的Hadoop HA 集群中,ANN和SNN一般布置在两台单独的机器上,由Zookeeper通过主备选举机制来确定。
2. 软、硬件配置
- NameNode: ANN和SNN 应该具有相同的硬件
- JournalNode:不需要额外的机器专门来启动journalnode,可以和其它节点部署在一起,如NameNode或DataNode等,需要至少3个且为奇数
- DataNode: 所需数量最多,且分布在较多的机器上
- 在ZooKeeper中注册两个NameNode,当active状态的NameNode出现故障时,ZooKeeper能检测到这种情况,并自动把standby状态的NameNode切换为active状态
- 本次实验使用了2台物理机,其中一台安装2个虚拟机做NameNode,整个集群的规划如下:
| 物理机IP | hostname | 系统 | 启动进程 |
|---|---|---|---|
| 192.168.10.101 | namenode1 | VM CentOS | NN/ZKFC/JN/ResourceManager/QuoqumPeerMain |
| 192.168.10.102 | namenode2 | VM CentOS | NN/ZKFC/JN/ResourceManager |
| 192.168.10.103 | datanode | Ubuntu | DN/JN/NodeManager/QuoqumPeerMain |
安装
1. 设置集群用户
首先要在所有节点上设置相同的用户,这个可以在安装系统的时候设置,或者使用useradd命令增加新用户。本实验就使用root用户。使用$sudo gedit /etc/hosts 添加IP地址和主机名映射
192.168.10.101 namenode1
192.168.10.102 namenode2
192.168.10.103 datanode
2. ssh免密登录
在namenode1节点上生成密钥
$ ssh-keygen -t rsa
将公钥复制到所有节点上
$ssh-copy-id namenode1
$ssh-copy-id namenode2
$ssh-copy-id datanode
通过ssh登录各节点测试是否免密码登录成功
$ssh 节点名
3. 安装配置Zookeeper
解压并移动Zookeeper压缩包到~/apache/zookeeper目录下,修改zookeeper的配置文件
$cd ~/apache/zookeeper/conf
$cp zoo_sample.cfg zoo.cfg
$sudo gedit zoo.cfg
设置如下:
dataDir=/home/root/apache/zookeeper/data
dataLogDir=/home/root/apache/zookeeper/data/log
clientPort=2181
server.1=namenode1:2888:3888
server.2=namenode2:2888:3888
server.3=datanode:2888:3888
创建zookeeper的数据存储目录和日志存储目录
$cd ..
$sudo mkdir -p data/log
在data目录下创建文件myid,输入内容为1
$echo “1” >> data/myid
将zookeeper工作目录同步到集群其它节点
$scp -r zookeeper root@namenode2:/home/root/apache/
$scp -r zookeeper root@datanode:/home/hadoop/apache/
分别修改myid的值为2和3,并配置所有节点的环境变量
$sudo gedit ~/.bashrc // 如果是CentOS这里改为~/.bash_profile
添加如下内容:
export ZOOKEEPER_HOME=/home/root/apache/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
使环境变量及时生效
$source ~/.bashrc
4. Hadoop的安装与配置
解压并移动Hadoop压缩包到~/apache/hadoop目录下,编辑相关文件
$cd ~/apache/hadoop/etc/hadoop
$gedit hadoop-env.sh
按如下内容进行配置:
export JAVA_HOME=自己Java的安装目录
export HADOOP_PID_DIR=/home/root/apache/hadoop/pids
export HADOOP_LOG_DIR=/home/root/apache/hadoop/data/logs
保存后,创建刚才设定的目录
$cd ~/apache/hadoop
$mkdir pids
$mkdir -p data/logs
配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 设置zookeeper集群的配置和端口 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>namenode1:2181,namenode2:2181,datanode:2181</value>
</property>
<!-- 指定缓存文件存储的路径和大小 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/root/apache/hadoop/data/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 配置hdfs文件被永久删除前保留的时间 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>配置hdfs-site.xml
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/root/apache/hadoop/data/namenode</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/root/apache/hadoop/data/datanode</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //以下为HDFS HA的配置// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 指定mycluster的两个namenode的名称分别为nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置nn1,nn2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>namenode1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>namenode2:8020</value>
</property>
<!-- 配置nn1,nn2的http通信端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>namenode1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>namenode2:50070</value>
</property>
<!-- 指定namenode元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://namenode1:8485;namenode2:8485;datanode:8485/mycluster</value>
</property>
<!-- 指定HDFS客户端连接active namenode的java类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/root/.ssh/id_rsa</value>
</property>
<!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/root/apache/hadoop/data/journal</value>
</property>
<!-- 开启自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>配置mapred-site.xml
<configuration>
<!-- 指定MapReduce计算框架使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定jobhistory server的rpc地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>namenode1:10020</value>
</property>
<!-- 指定jobhistory server的http地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>namenode1:19888</value>
</property>
<!-- 开启uber模式(针对小作业的优化) -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 配置启动uber模式的最大map数 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>3</value>
</property>
<!-- 配置启动uber模式的最大reduce数 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
</configuration>配置yarn-site.xml
<configuration>
<!-- NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置Web Application Proxy安全代理(防止yarn被攻击) -->
<property>
<name>yarn.web-proxy.address</name>
<value>namenode2:8888</value>
</property>
<!-- 开启日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志删除时间为7天,-1为禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 修改日志目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/logs</value>
</property>
<!-- 配置nodemanager可用的资源内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<!-- 配置nodemanager可用的资源CPU -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<!-- //以下为YARN HA的配置// -->
<!-- 开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 启用自动故障转移 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定YARN HA的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<!-- 指定两个resourcemanager的名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1,rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>namenode1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>namenode2</value>
</property>
<!-- 配置YARN的http端口 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>namenode1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>namenode2:8088</value>
</property>
<!-- 配置zookeeper的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>datanode:2181</value>
</property>
<!-- 配置zookeeper的存储位置 -->
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<!-- 开启yarn resourcemanager restart -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置resourcemanager的状态存储到zookeeper中 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 开启yarn nodemanager restart -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置nodemanager IPC的通信端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
</configuration>配置slaves文件
$gedit slaves
内容如下:
datanode
创建配置文件中涉及到的目录
$cd ~/apache/hadoop
$mkdir -p data/tmp
$mkdir -p data/journal
$mkdir -p data/namenode
$mkdir -p data/datanode
将hadoop工作目录同步到集群其它节点
$scp -r hadoop root@namenode2:/home/root/apache/
$scp -r hadoop root@datanode:/home/root/apache/
在所有节点上编辑环境变量
$gedit ~/.bashrc
配置如下:
export HADOOP_HOME=/home/root/apache/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使修改后的环境变量生效
$source ~/.bashrc
初始化和启动Hadoop集群
1. 启动zookeeper集群
在每个节点上启动zookeeper server
$zkServer.sh start
在namenode1上格式化ZKFC
$hdfs zkfc -formatZK
在所有节点上启动journalnode
daemon.sh start journalnode
在namenode1上格式化HDFS
hadoop namenode -format
将namenode1节点格式化后hadoop工作目录中的元数据目录复制到namenode2节点
$scp-r /home/root/apache/hadoop/data/namenode/* root@namenode2:/home/root/apache/hadoop/data/namenode/
2. 启动Hadoop集群
在namenode1上启动dfs
$start-dfs.sh
在namenode1上启动YARN(如果namenode2是active就在namenode2上启动)
$start-yarn.sh
在namenode2上启动用于容灾的另一个ResourceManager
$yarn-daemon.sh start resourcemanager
在namenode1上启动YARN的安全代理
$yarn-daemon.sh start proxyserver
在namenode2上启动YARN的历史任务服务
$mr-jobhistory-daemon.sh start historyserver
3. 查看Web UI
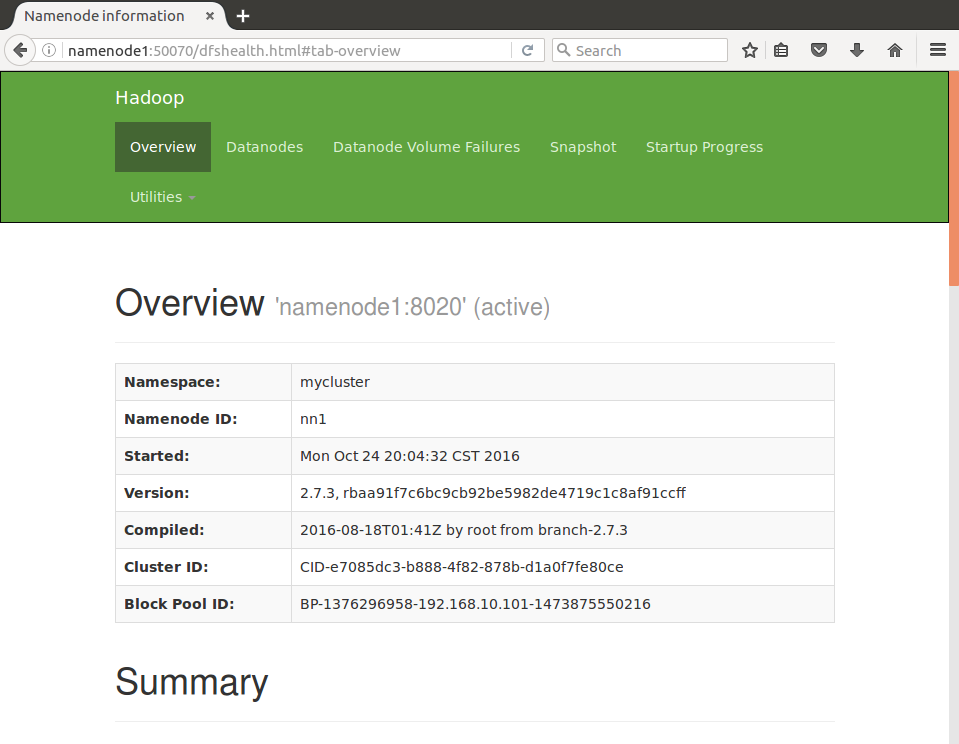
在浏览器中打开http://namenode1:50070,查看节点状态(namenode1是active)
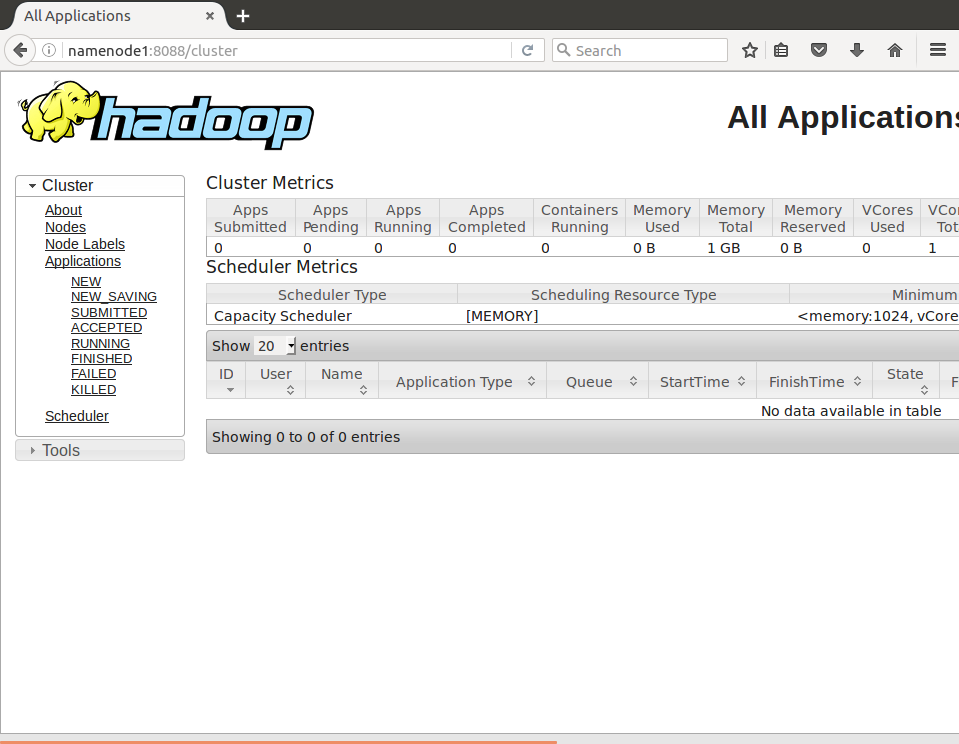
在浏览器中打开http://namenode1:8088,查看ResourceManager状态
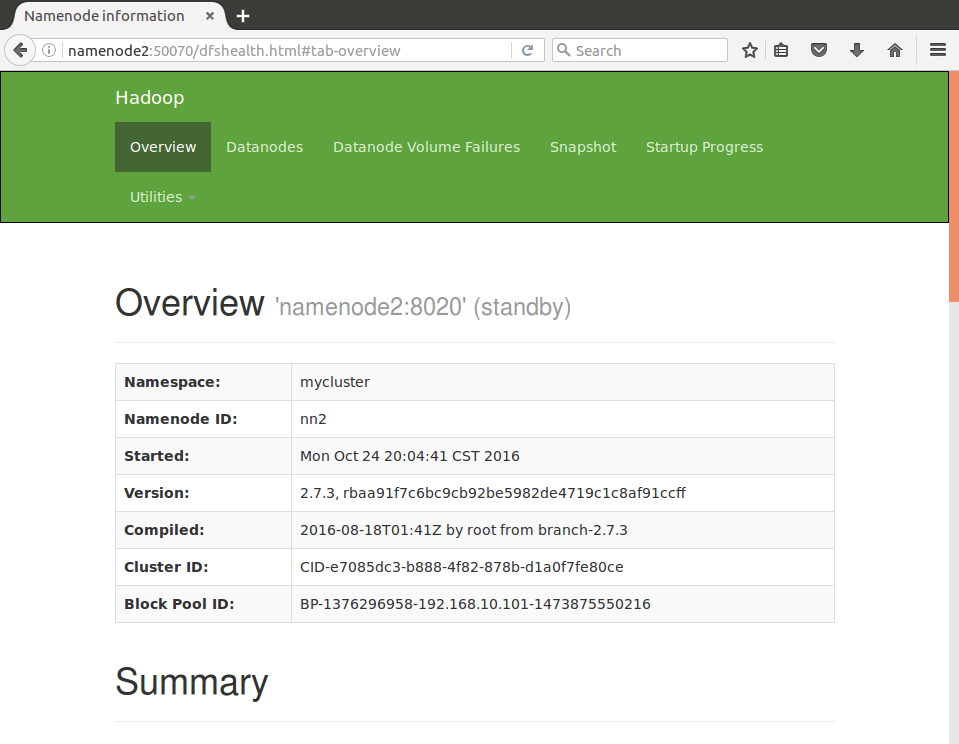
在浏览器中打开http://namenode2:50070,查看节点状态(namenode2是standby)
在浏览器中打开http://namenode2:8088,查看ResourceManager状态,这时页面会自动跳转到namenode1的RM界面。
4. 关闭退出
Hadoop HA不再支持stop-all.sh,使用stoap-yarn.sh或者stop-dfs.sh退出Hadoop。使用zkServer.sh stop退出zookeeper。















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









