







一.提出背景
在基于CNN的方法提升到一个很高的准确度之后,效率又成为人们所关注的话题,目前兼备准确度和效率的方法包括 SSD、YOLO v2,其检测效率通常能到达 30-100FPS,而这里面的代价就是上万块的显卡,这个代价是相当高的。当下视频获取设备(CCTV摄像头)成本通常是几百块,而采用上述分类算法,其成本可能是几千,这就是视频获取和视频分析之间的巨大鸿沟。
基于此,斯坦福大学提出了一种系统 NoScope,将视频分析的速度提升上千倍,我们接下来就看看这个牛逼吹的很大的系统到底是什么?
论文:NoScope: Optimizing Neural Network Queries over Video at Scale 【点击下载】
TensorFlow代码:【Github】
核心思想:由于视频目标是连续的,里面包含了大量时间局部性(temporal locality,即在不同的时间是相似的)和空间局部性(spatial locality,即在不同场景中看起来是相似的)。通过以下两点来进行优化:
1)通过跳帧减少目标检测的实际执行开销,跳帧方法包括按照时间、按照相邻帧之间的相似性;
2)针对不同场景(对应不同视角和特定目标),通过训练轻量级CNN来加速单帧检测开销;
在揭开神秘面纱之后,是不是发现被忽悠了?和我一起喊出来吧:有必要吹的这么凶么?
二.算法框架
算法实际上是分成三个部分:
1)Model Specialization
针对特定场景训练的轻量级CNN模型,层数和Channel都降到最低。
2)Difference Detection
差异性检测,用于跳过与前面帧变化不大的帧,速度更快。
3)Cost-based Model Search
基于代价的模型选择,确定合适的模型进行检测。
来看系统架构图:
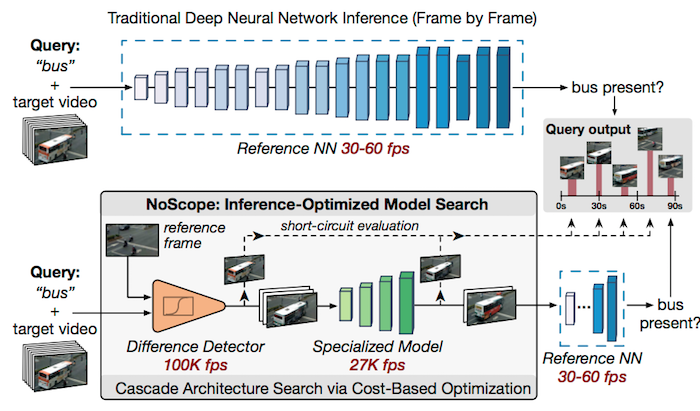
2.1 训练特定模型
针对不同场景,首先采用参考的CNN模型进行检测,参见上图中的 Reference NN,这种通用检测器的检测准确度很高,需要借助其一段时间内检测到的目标标签来进行 Specialized Model 的训练(上图中绿色的4层网络)。
这里基于这样一个假设,在特点场景下,目标种类有限(比如行人、公交、汽车),视角固定对应特征相对简单,因此轻量级的网络在这种情况下是有效的。
2.2 差异检测器
差异检测比较简单,有很多方法,基于像素的差分、GMM,即计算和已知场景的差异。
这里要注意一个问题,论文里提到的是一个二分类问题,比如场景有没有公交车,因此只要差异不太大,都可以直接跳过。

2.3 基于代价的模型搜索
文中提出了一个优化器,用来平衡准确度和效率,通过调整置信度阈值来实现。
当特定检测器检测的置信度比较高,直接输出,置信度比较低时,退回到原始的CNN网络进行检测,这一步将带来较大的计算量。
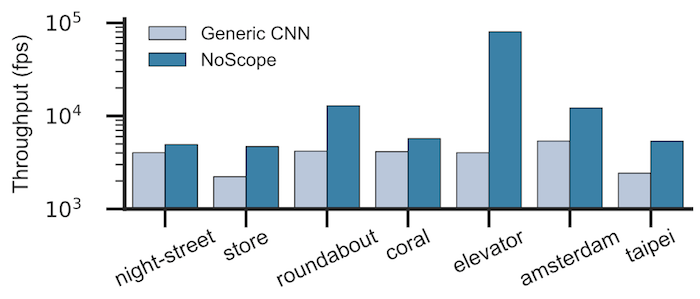
三.实验结果
吹过之后,拿实验填坑,和 Generic CNN 相比,果然提升巨大,不过比的方式有点讽刺,你跳帧了和别人全帧检测来比,我也是醉了,啥也不说了,洗洗睡吧!
http://blog.csdn.net/linolzhang/article/details/77688964
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









