







Together AI的新研究MoA,文章论文。
论文:《Mixture-of-Agents Enhances Large Language Model Capabilities》
论文链接:https://arxiv.org/html/2406.04692v1
这篇文章的标题是《Mixture-of-Agents Enhances Large Language Model Capabilities》,作者们来自 Duke University 和 Together AI,以及 University of Chicago 和 Stanford University。
摘要:
文章提出了一种新的方法,称为 Mixture-of-Agents(MoA),利用多个大型语言模型(LLMs)的集体优势来提高自然语言理解和生成任务的性能。MoA 方法通过构建分层的 MoA 架构,每层包含多个 LLM Agents,每个Agent使用前一层所有Agents的输出作为辅助信息来生成其响应。MoA 模型在 AlpacaEval 2.0、MT-Bench 和 FLASK 等基准测试中取得了最先进的性能,超越了 GPT-4 Omni。
解决的问题:
文章解决的问题是如何有效地结合多个大型语言模型(LLMs)的专长,以创建一个更加强大和稳健的模型。尽管存在许多 LLMs 并在多个任务上取得了令人印象深刻的成就,但它们仍然面临着模型大小和训练数据的固有限制。此外,不同的 LLMs 具有不同的优势和专门化的任务方面,如何利用这些多样化的技能集是一个挑战。
1、项目介绍
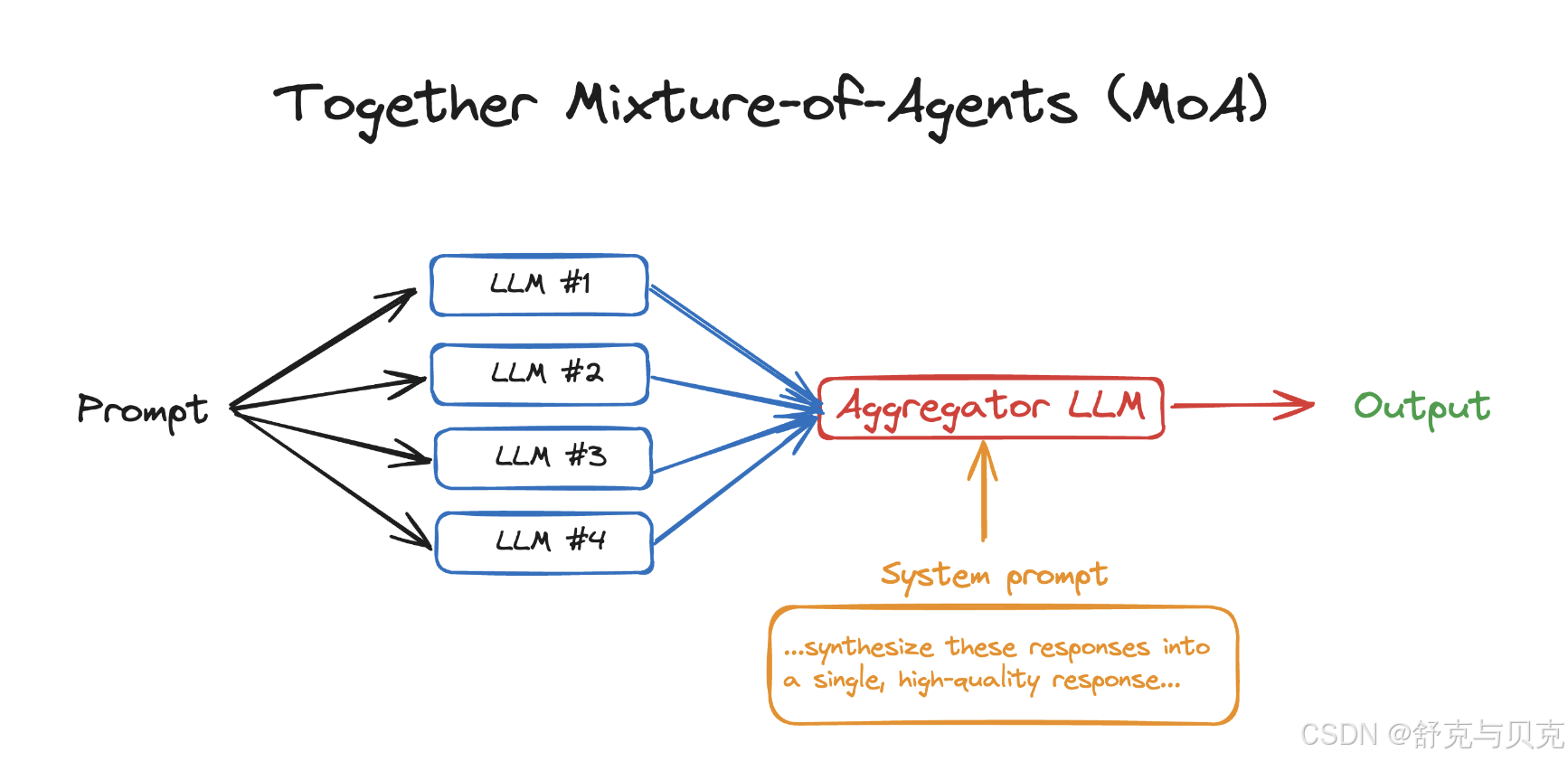
MoA是一种创新方法,它通过整合多个LLMs的长处,实现性能的显著飞跃,达到了业界领先水平。这个项目不仅在理论上构建了多智能体协作的新框架,更在实践中证明了它的价值,特别是在AlpacaEval 2.0评测上,以65.1%的分数超越了GPT-4 Omni的57.5%,且这一成果完全基于开放源代码模型。
2、项目技术分析
MoA的核心在于其层次化的架构,每一层都包含了多个独立的LLM“代理”。通过精心设计的聚合策略,这些代理的输出被综合成更加精准和复杂的回答。这种“集体智能”方法不仅增强了模型的泛化能力,还提升了处理复杂语境问题的能力。技术上,MoA通过并行执行机制优化处理速度,允许配置不同的参数如温度、最大响应长度等,以适应不同场景下对创造性与确定性的需求。
3、项目及技术应用场景
MoA的潜力无限,它为多种应用场景带来了革新。从多轮对话系统到定制化咨询服务,再到高效的内容创作辅助,每个需要理解和生成自然语言的场景都是它的舞台。例如,客户服务中的智能助手可以利用MoA提供更为个性化和准确的回答;教育领域,则可用来创建能够动态适应学习者需求的教学机器人。此外,在科研和创意写作中,MoA能够提供多样化的视角和深度的信息整合,激发新的思考方向。
4、项目特点
协同增效:多个LLM的协作远超单个模型的表现,实现了质的飞越。
灵活性高:用户可根据任务需求调整代理模型组合,以及交互过程中的参数设置。
开源友好:基于Apache 2.0许可证,鼓励社区参与和模型的持续迭代。
标准化评估:集成多种评价标准和工具,使得性能透明,易于比较。
广泛兼容:能够与现有评价基准无缝对接,如AlpacaEval、MT-Bench和FLASK,便于验证和比较。
通过MoA,我们看到了未来语言处理技术的曙光——一个由多智体共同编织的智能未来。对于开发者、研究人员乃至每一位对语言技术抱有热忱的使用者来说,MoA无疑是探索语言智能深水区的一艘强大航船。立即加入,体验由集体智慧推动的语言革命,让您的应用拥抱前所未有的力量。不要忘了,这一切的奇妙旅程只需简单的几步配置,即可在自己的环境中启动这股强大的交流之流。让我们共同见证,大型语言模型如何在MoA的引领下,焕发新的生机。
5、项目特点
官方代码: (不支持ollama)
(支持ollama版本)

# from llama_index.core.llama_pack import download_llama_pack
#
# # download and install dependencies
# MixtureOfAgentsPack = download_llama_pack(
# "MixtureOfAgentsPack", "./mixture_of_agents_pack"
# )
from llama_index.packs.mixture_of_agents import MixtureOfAgentsPack
from llama_index.llms.ollama import Ollama
OLLAMA_API_URL = "http://localhost:11434"
OLLAMA_MODEL1 = "glm4" # 使用的Ollama模型名称
OLLAMA_MODEL2 = "qwen2:7b" # 使用的Ollama模型名称
question = "LlamaIndex是什么?"
# question = "如何写一篇专利?"
llm1 = Ollama(model=OLLAMA_MODEL1, base_url=OLLAMA_API_URL)
response = llm1.complete(question, temperature=0.5)
print(response)
print("*" * 25)
llm2 = Ollama(model=OLLAMA_MODEL2, base_url=OLLAMA_API_URL)
response = llm2.complete(question, temperature=0.5)
print(response)
print("*" * 25)
mixture_of_agents_pack = MixtureOfAgentsPack(
llm=llm1, # Aggregator
reference_llms=[
llm1,
llm2,
], # Proposers
num_layers=3,
temperature=0.5,
)
response = mixture_of_agents_pack.run(question)
print(response)
print("*" * 25)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









