







前言
对于有视频转图片需求的小伙伴可以看过来,快捷指令同样有方式支持将视频转为图片,但对图片质量有高要求的可以忽略,快捷指令会对视频有压缩处理。
设计思路
- 支持分享视频提取长图和手动选取视频提取长图
- 分享视频提取长图:从相册视频选择分享打开 视频提取长图快捷指令
- 手动选取视频提取长图:手动执行快捷指令选取视频提取长图
- 使用制作GIF工具制作GIF
- 从GIF中获取帧
- 以水平或者垂直方向拼接长图
实现
1.处理视频
- 相册分享过来的视频通过【输入快捷指令的信息】获取
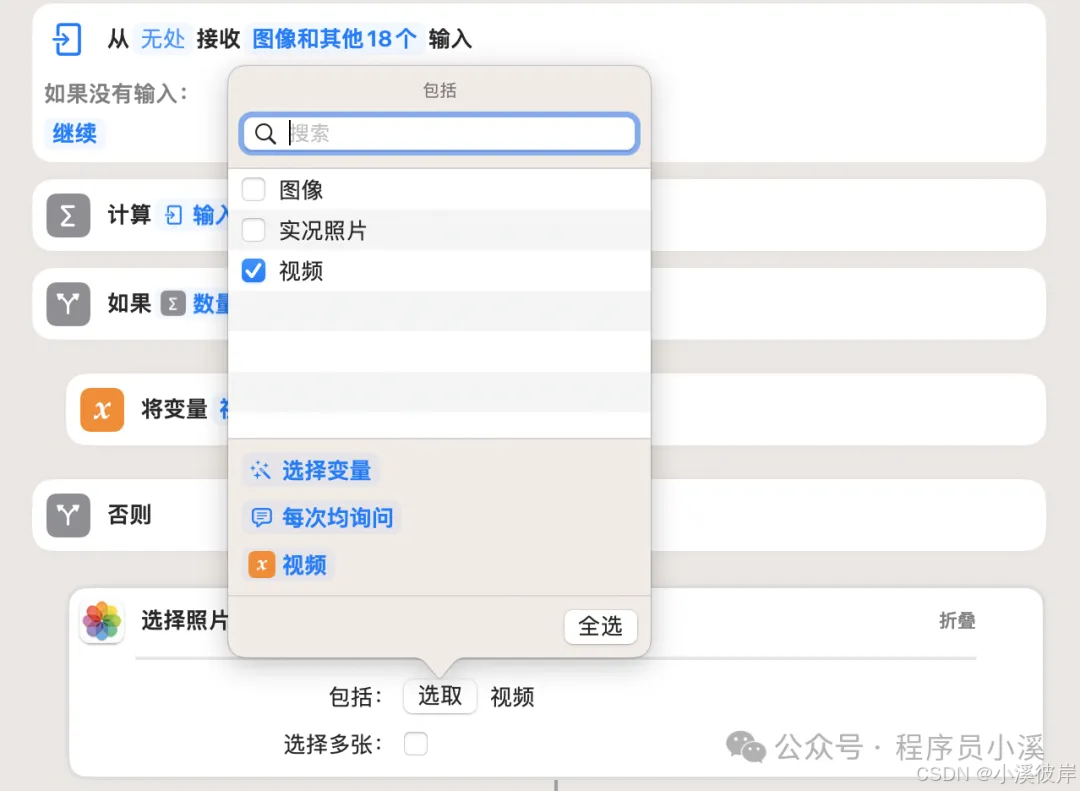
- 手动执行快捷指令通过【选择照片】手动选取视频

【选择照片】选取条件勾选视频,这样只会选择视频资源
2.获取视频帧
使用【制作GIF】将视频制作为GIF,通过【从图像中获取帧】获取GIF图片列表的帧图

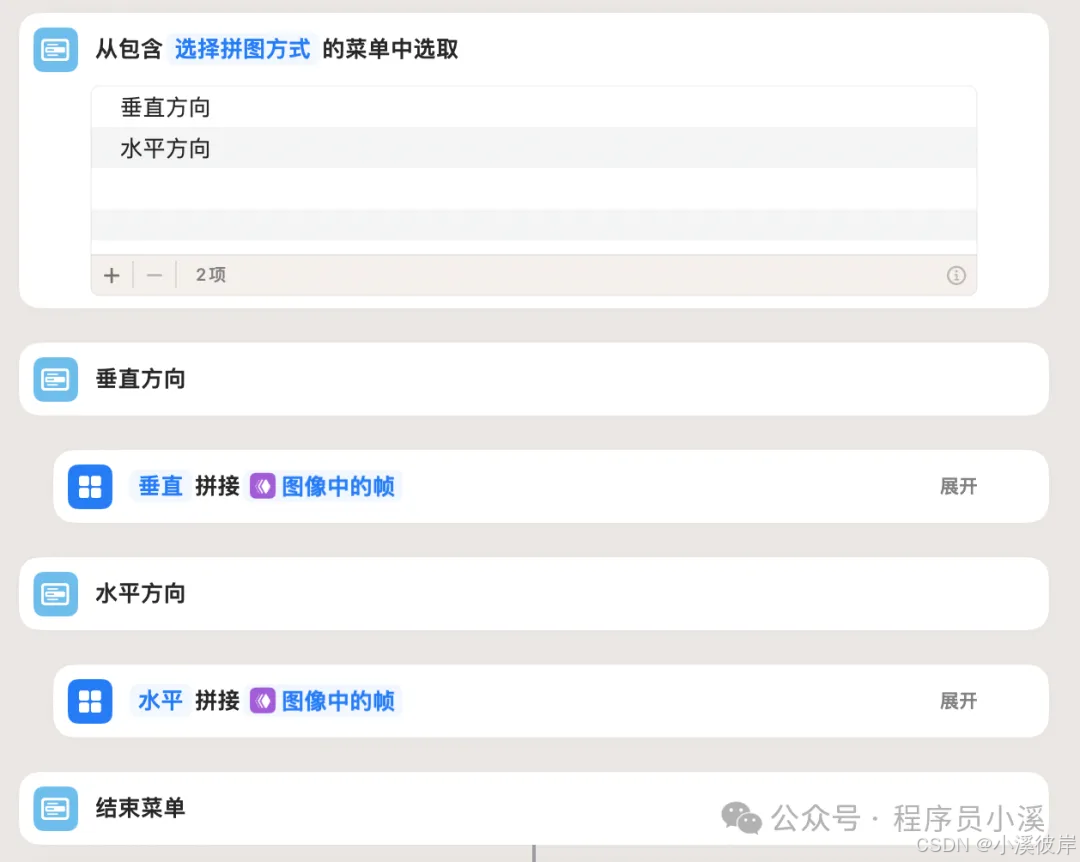
3.拼接长图
提供垂直和水平方式拼接图片,通过【拼接图像】对图片列表进行拼接
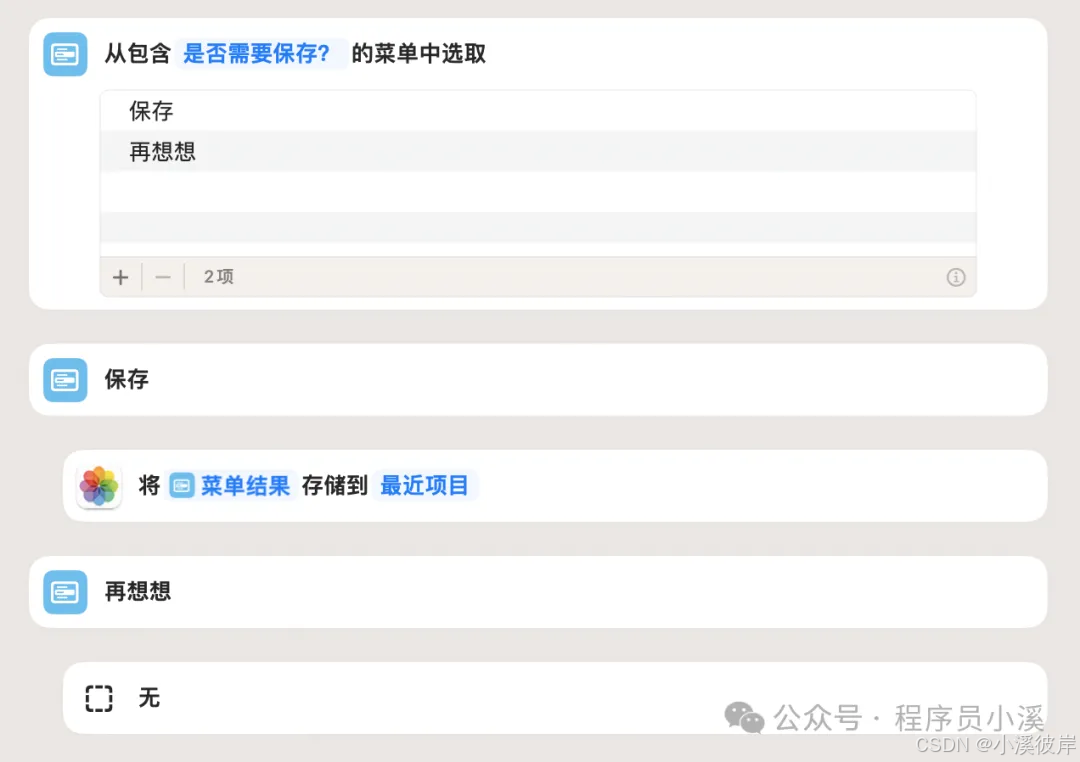
4.保存图片
使用【存储到相簿】将图片存储到【最近项目】
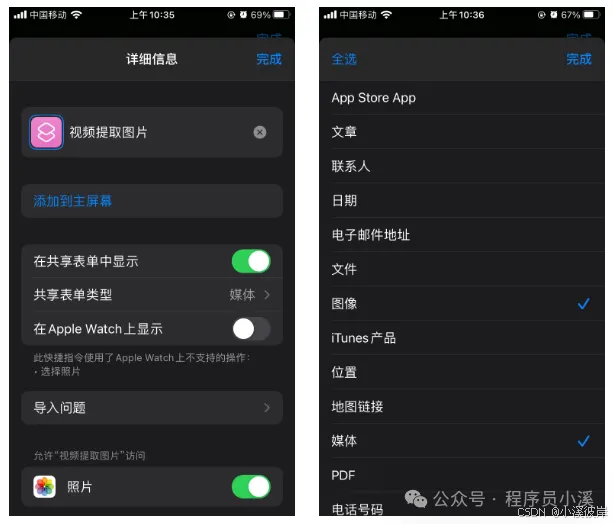
5.配置共享表单
MacOS上没有该步骤在手机端配置。
点击快捷指令右上角【…】-> 【在共享表单中显示】-> 【共享表单类型】选择【图片】和【媒体】
快捷指令口令
见原文:【快捷指令案例】视频提取长图
本文同步自微信公众号 “程序员小溪” ,这里只是同步,想看及时消息请移步我的公众号,不定时更新我的学习经验。

















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









