







1.原始数据
a.txt
hello tom
hello jerry
hello kitty
hello world
hello tomb.txt
hello jerry
hello tom
hello world过程模拟
Map阶段
<0,"hello tom">
....
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
--------------------------------------------------------
combiner阶段
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->b.txt",1>
<"hello->b.txt",1>
<"hello->b.txt",1>
context.write("hello","a.txt->5");
context.write("hello","b.txt->3");
--------------------------------------------------------
Reducer阶段
<"hello",{"a.txt->5","b.txt->3"}>
context.write("hello","a.txt->5 b.txt->3");
-------------------------------------------------------
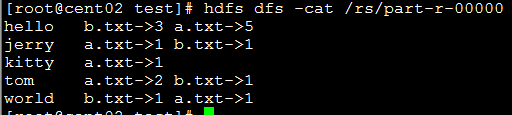
hello "a.txt->5 b.txt->3"
tom "a.txt->2 b.txt->1"
kitty "a.txt->1"
.......2.实现代码
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReverseSort {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJobName("reverseSort");
job.setJarByClass(ReverseSort.class);
job.setMapperClass(RSMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setReducerClass(RSReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setCombinerClass(RSCombiner.class);
//设置ruducer数量,即分区数,默认为1
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.waitForCompletion(true);
}
public static class RSMapper extends Mapper<LongWritable, Text, Text, Text>{
private Text k2=new Text();
private Text v2=new Text();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[]words = line.split(" ");
FileSplit fileSplit = (FileSplit)context.getInputSplit();
Path path = fileSplit.getPath();
String name=path.getName();
for (String word : words) {
k2.set(word+"->"+name);
v2.set("1");
context.write(k2, v2); // ("hello->b.txt",1)
}
}
}
public static class RSCombiner extends Reducer<Text, Text, Text, Text>{
private Text k=new Text();
private Text v=new Text();
@Override
protected void reduce(Text k2, Iterable<Text> v2s,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String[] fields=k2.toString().split("->");
k.set(fields[0]);
long sum=0;
for (Text v : v2s) {
sum+=Long.parseLong(v.toString());
}
v.set(fields[1]+"->"+sum);
context.write(k, v); // ("hello","a.txt->5")
}
}
public static class RSReducer extends Reducer<Text, Text, Text, Text>{
private Text k=new Text();
private Text v=new Text();
@Override
protected void reduce(Text key, Iterable<Text> v2s,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
k.set(key.toString());
StringBuilder sb = new StringBuilder("");
for (Text text : v2s) {
sb.append(text.toString()+" ");
}
v.set(sb.toString());
context.write(k, v);
}
}
}3.倒排索引输出结果
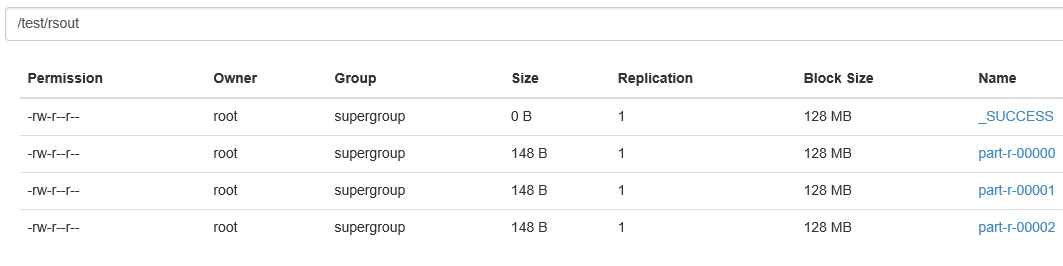
执行:
hadoop jar rsort.jar cn.zx.hadoop.mr.Rsort.ReverseSort /test/rs /test/rsout 3结果:
















 3003
3003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











