







机器学习基础知识
监督学习:监督学习从给定的数据中(已经确定了数据的类别)学习模型,之后利用学习的模型,得到目标变量的结果。简单来说,监督学习用来学习的数据,已经给定了类别(标签)、类别数等。是一种预先知道学习后,可能产生的目标变量的结果的学习方式。(例如,已经知道了,学习后用来对猫狗分类,而不是对其他类别分类)。
目标变量的两种类型:标称型和数值型。标称型指:结果在有限目标集中取值,如真与假,{婴儿、幼年、青年、成年、中年、老年}。数值型值:目标变量从无限数值集合中取值,这种类型的目标变量主要用于回归分析。
何谓机器学习:简单地说,机器学习就是把无序的数据转换成有用的信息。
训练集:为了训练算法所输入的,大量已分类数据。训练集包含多个训练样本,每个样本包含一个或多个特征、一个目标变量(结果)。对于分类算法(监督学习),训练样本集必须知道目标变量的值,才可以通过机器学习算法发现样本特征与目标变量之间的关系。对于分类问题,目标变量称为类别。
训练数据和测试数据:当机器学习算法开始运行时,训练样本集输入,训练完成后输入测试样本集。给算法输入的测试样本集,去掉样本的目标变量,有算法判别每个样本的目标变量。比较测试样本通过算法预测的变量和实际样本类别间的差异,评估算法的精确度。
分类与回归:分类主要的任务为,将实例数据划分到合适的类别中。回归主要用于预测数值型数据,如:通过给定数据点的最有拟合曲线,即数据拟合曲线。分类和回归同属于监督学习,这类学习算法知道要预测什么,即知道目标变量的分类信息。
无监督学习:用来训练的数据没有类别信息,没有目标值。无监督学习中,将数据集合分成由类似的对象组成的多个类的过程称为聚类;将寻找描述数据统计值的过程称为密度估计。无监督学习还可以减少数据特征的维度。
| 监督学习 | 无监督学习 |
|---|---|
| k近邻 | k均值 |
| 朴素贝叶斯分类 | 最大期望算法 |
| 支持向量机 | |
| 决策树 | |
| 回归 |
开发机器学习应用程序步骤:(1)收集数据。(2)准备输入数据。(3)分析输入数据。(4)训练算法。(5)测试算法。(6)使用算法。
K-近邻算法
1.算法概述
简单的说,K-近邻算法采用测量不同特征值之间的距离方法进行分类。
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
实用数据范围:数值型和标称型。
工作原理:存在一个训练样本集,样本集中每个样本都有标签,已经事先知道每个样本的所属分类。输入新样本后(无标签),将新样本的每个特征与样本集中样本对应的特征进行比较,提取样本集中特征最相似(最近邻)的前K个分类标签,取出现次数最多的标签,作为新样本所属的分类。
2.k-近邻算法的一般流程
(1)收集数据:使用任意方法收集。
(2)准备数据:用于计算距离,数据格式最好结构化。
(3)分析数据:任意方法。
(4)训练算法:K-近邻不需要训练算法。
(5)测试算法:计算错误率。
(6)使用算法:输入样本数据,运行K-近邻算法判别输入数据所属分类。
3.K-近邻算法代码(Python)
3.1 整体代码
# -*- coding: utf-8 -*-
'''
Input: inX: vector to compare to existing dataset (1xN)
dataSet: size m data set of known vectors (NxM)
labels: data set labels (1xM vector)
k: number of neighbors to use for comparison (should be an odd number)
Output: the most popular class label
'''
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
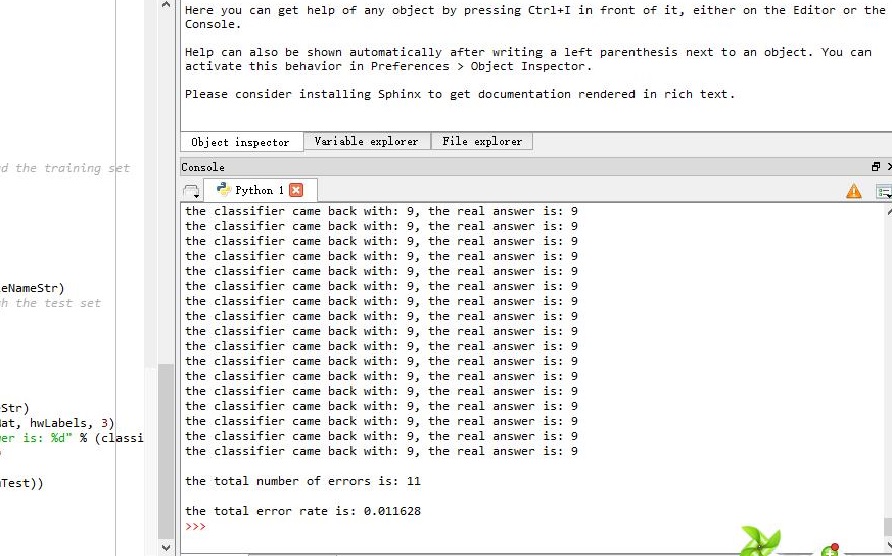
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
3.2各部分代码分析
(1)创建简单的数据集和标签:
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
(2)k-近邻算法
#输入参数:待分类向量、样本集、标签、k
def classify0(inX, dataSet, labels, k):
#计算待分类样本与样本集中各个样本距离
##样本集中样本个数
dataSetSize = dataSet.shape[0]
#待分类向量构成 样本集同形式(方便计算),作差
diffMat = tile(inX, (dataSetSize,1)) - dataSet
#两向量间距离(平方和开根号)
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#距离排序(升序)
sortedDistIndicies = distances.argsort()
#字典,用于存储 类别及其出现次数
classCount={}
for i in range(k):
#前K个类别标签
voteIlabel = labels[sortedDistIndicies[i]]
#对应类别标签+1
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#降序排列,对classCount第二个元素排序
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
#返回排名第一的类别
return sortedClassCount[0][0]
3.2.1约会网站上使用k-近邻算法
1.收集数据:文本文件。
2.准备数据:解析文本文件。
3.分析数据:二维扩展图。
4.训练算法:无
5.测试算法:使用测试样本进行测试。
6.使用算法:输入一些特征数据,判断对象是否为自己喜好的类型。
(1)从文本中解析数据
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #文本数据的行数
returnMat = zeros((numberOfLines,3)) #行数相同,列数为3的矩阵
classLabelVector = [] #类别标签
fr = open(filename) #打开文本
index = 0
for line in fr.readlines():
line = line.strip() #去掉前后空格
listFromLine = line.split('\t') #分割一句话为一个个单词
returnMat[index,:] = listFromLine[0:3] #填充矩阵
classLabelVector.append(int(listFromLine[-1])) #填充类别列表
index += 1
return returnMat,classLabelVector
(2)归一化特征值(在处理不同取值范围的特征值时,通常要归一化,以防止某个特征值过大造成距离计算完全取决于该特征值)
公式:newValue=(Value-min)/(max-min),max和min为特征最大和最小值,该公式将特征值转化到0~1区间。
def autoNorm(dataSet):
#列最小值
minVals = dataSet.min(0)
#列最大值
maxVals = dataSet.max(0)
ranges = maxVals - minVals
#初始化归一化数据
normDataSet = zeros(shape(dataSet))
#行数
m = dataSet.shape[0]
#value-minValue
normDataSet = dataSet - tile(minVals, (m,1))
# (value-minValue)/(maxVal-minVal)
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
(3)分类器关于约会网站的测试代码:
def datingClassTest():
hoRatio = 0.10 #10%的测试样本
#从文本文件加载 训练集和标签
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
#归一化
normMat, ranges, minVals = autoNorm(datingDataMat)
#行数,也就是训练样本数
m = normMat.shape[0]
#测试样本数(前10%的数据作为测试样本)
numTestVecs = int(m*hoRatio)
#初始化错误数
errorCount = 0.0
for i in range(numTestVecs):
#k-近邻分类 (归一化测试数据,归一化样本集,标签,k)
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
#如果分类错误,错误数+1
if (classifierResult != datingLabels[i]): errorCount += 1.0
#显示错误率
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
3.2.2 基于K-近邻的手写识别系统
(1):收集数据:文本文件。
(2):准备数据:转换为分类器使用的数据格式。
(3):分析数据。
(4):训练算法:无。
(5):测试算法:使用测试数据,如果算法分类与实际分类不一样,错误数+1。
(6):使用算法:
(1)图像转换为测试向量
每个图像数据已经转换成一个文本文件,每个文本文件为32x32的二进制数据。
def img2vector(filename):
#1x1024的向量
returnVect = zeros((1,1024))
fr = open(filename)
#每一行
for i in range(32):
lineStr = fr.readline()
#一个一个填充向量
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
(2)测试算法:使用k-近邻识别手写数字
def handwritingClassTest():
hwLabels = []
#加载样本集
trainingFileList = listdir('trainingDigits')
#样本集中的样本数
m = len(trainingFileList)
#Mx1024的矩阵
trainingMat = zeros((m,1024))
for i in range(m):
#文本名:类别_第x个.txt
fileNameStr = trainingFileList[i]
#分割 去掉 .txt
fileStr = fileNameStr.split('.')[0] #take off .txt
#分割 去掉 _第x个
classNumStr = int(fileStr.split('_')[0])
#加入标签(类别)
hwLabels.append(classNumStr)
#训练集转换为向量
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#遍历测试数据集
testFileList = listdir('testDigits') #iterate through the test set
#错误数字
errorCount = 0.0
#测试数据集 样本数
mTest = len(testFileList)
#对每个测试样本
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
#使用k-近邻分类
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
#如果算法预测类别与样本实际类别不一致
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
#输出错误率
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
利用K-近邻算法的手写识别错误率约为1.163%
4.K-近邻算法总结
k-近邻算法是分类数据最简单最有效的算法,它基于实例的学习,使用算法时必须有接近实际数据(能够反映实际数据)的训练样本集。使用K-近邻算法必须保存所有训练数据,如果数据很大,占用空间很大。而且,对一个样本分类,必须计算其与所有训练样本集中的样本的距离,这可能会非常耗时。k-近邻的改进算法为k决策树。















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











