






大致情况
最近master重启时间被我弄好了,我正准备大干一场给HBase升级一个版本,没想到危机都藏在水底,当我准备一个分组一个分组的升级的时候,突然看到了RIT告警...
我心里一慌,什么情况,master的瓶颈应该已经没有了才是,为什么还会有RIT,为什么,他NN滴!差点儿变身穿山甲的我带着小紧张的心情打开了log,看到了这样一副画面
我没来得及追查问题,我先直接将RS进行紧急关闭,让region强制移动出去并中断一切操作,然后RS会被自动拉起,基本会被分配到这个节点(因为这个节点压根一个节点都没有)
move的时候,如果没有指定目标,那么规矩和balance差不多,百分百会被分配到原来的节点上
可怜我的dest节点都做好了接收region的准备,结果你说不去就不去了?!不行!不过去不准停!所以现在RS如果不重启也许会一直卡在这里,然后等待某个事件的发生,但我必不可能让这件事情发生,因为这样的话可能就会有电话要来找我了
region mover频繁失败,这里是因为正在RIT,所以直接不算online了
INFO [Ruby-0-Thread-35: /home/hbase/software/hbase/bin/thread-pool.rb:28] client.RpcRetryingCaller: Call exception, tries=10, retries=100, started=191286 ms ago, cancelled=false, msg=org.apache.hadoop.hbase.HBaseIOException: moving region not onlined:
compaction触目惊心
纳尼,居然有24小时还没做完的compaction,我也没看到网络有堆积的情况,这样子根本不可能到300M,compaction你故意找茬是吧

看到log有很多这样的地方,说明region move会造成compaction不正常终止,到这一步都很正常
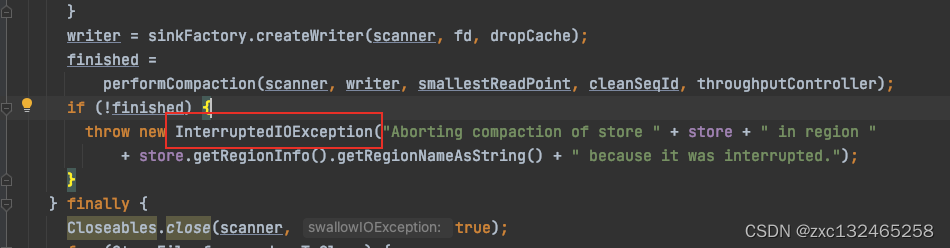 那么我大胆猜测RIT的节点正是那些compaction还没有抛出这个异常的地方,一直卡在pending_close
那么我大胆猜测RIT的节点正是那些compaction还没有抛出这个异常的地方,一直卡在pending_close
于是我又求证了几次,发现RIT的region都是在compaction抛出这个异常之后就正常移动了,那么compaction究竟是什么时候接收到的Interrupted?
目前有2个问题:
1.为什么compaction执行了如此久,compaction队列没阻塞,同时也没有到达限流300M
2.compaction什么时候才会抛出这个异常?
第一个问题暂且不追究,既然compaction能做完并且对集群没有影响那么就先放着吧(绝不是因为找了半天啥也没找到所以不找了,然后为了自己的面子才这么说的)
第二个问题:
很快啊,我就在REGION doClose里面发现了这个玩意
在region关闭之前,一定需要等待flush和compaction都安全的关闭才行喔~
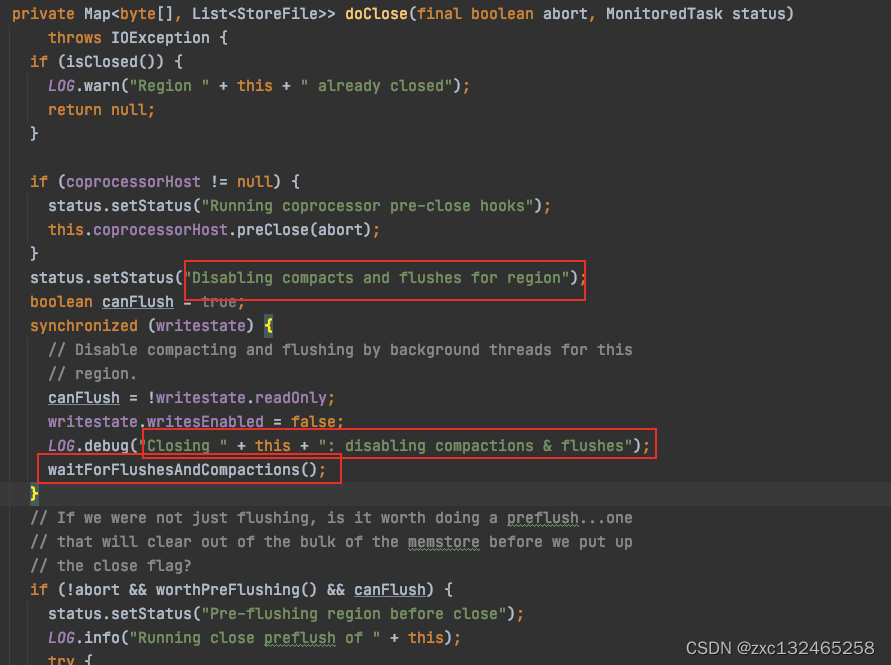
然后不出我所料的出现了interrupt,中断这些线程吧!👴🏻要去别的地方安家咯~
(别急,优雅升级完了你还会回来的,现在放这些狠话)
(您这不是因为bug结果导致我没能回来嘛)
(不,我解释过了,出问题的region会原封不动的待在原地,所以..你只能出去一下下)
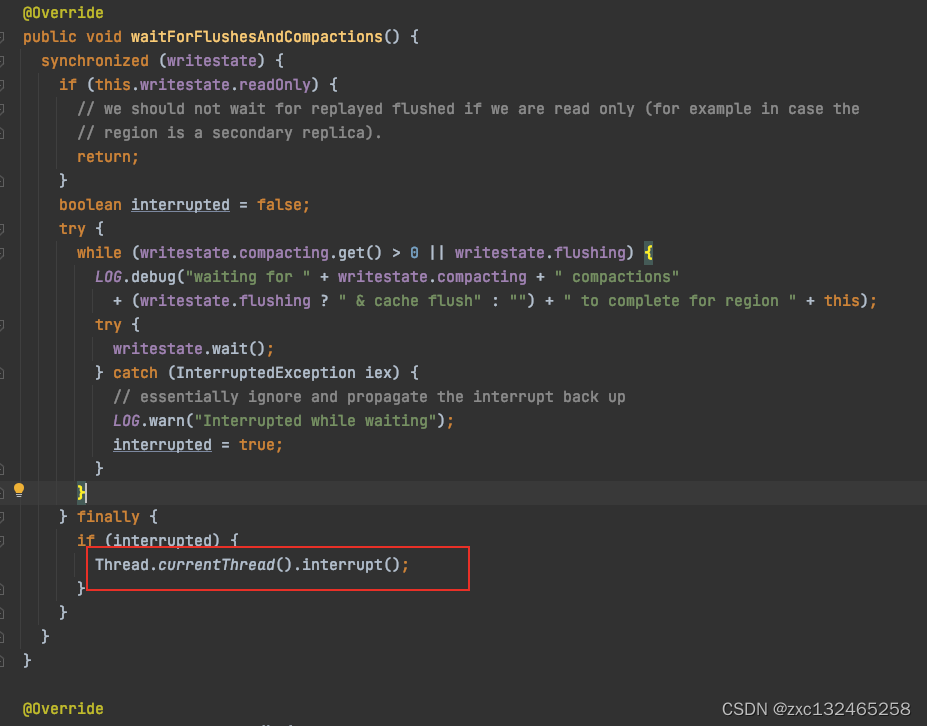
其中的writeState是一个非常神奇的变量~ 会追踪compaction的进度,可以自行查看哦,就是一个原子类而已啦实际上!
所以region move会卡主,并且造成RIT的原因就是compaction的状态无法获取,无法优雅的关闭,那么只能我手动kill了
解决办法:如果发现RS在做compaction多个心眼,后面再重启吧0.0















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









