










获取JS传入参数及其数量
【规则】 当传入napi_get_cb_info的argv不为nullptr时,argv的长度必须大于等于传入argc声明的大小。
当argv不为nullptr时,napi_get_cb_info会根据argc声明的数量将JS实际传入的参数写入argv。如果argc小于等于实际JS传入参数的数量,该接口仅会将声明的argc数量的参数写入argv;而当argc大于实际参数数量时,该接口会在argv的尾部填充undefined。
错误示例
static napi_value IncorrectDemo1(napi_env env, napi_callback_info info) {
// argc 未正确的初始化,其值为不确定的随机值,导致 argv 的长度可能小于 argc 声明的数量,数据越界。
size_t argc;
napi_value argv[10] = {nullptr};
napi_get_cb_info(env, info, &argc, argv, nullptr, nullptr);
return nullptr;
}
static napi_value IncorrectDemo2(napi_env env, napi_callback_info info) {
// argc 声明的数量大于 argv 实际初始化的长度,导致 napi_get_cb_info 接口在写入 argv 时数据越界。
size_t argc = 5;
napi_value argv[3] = {nullptr};
napi_get_cb_info(env, info, &argc, argv, nullptr, nullptr);
return nullptr;
}正确示例
static napi_value GetArgvDemo1(napi_env env, napi_callback_info info) {
size_t argc = 0;
// argv 传入 nullptr 来获取传入参数真实数量
napi_get_cb_info(env, info, &argc, nullptr, nullptr, nullptr);
// JS 传入参数为0,不执行后续逻辑
if (argc == 0) {
return nullptr;
}
// 创建数组用以获取JS传入的参数
napi_value* argv = new napi_value[argc];
napi_get_cb_info(env, info, &argc, argv, nullptr, nullptr);
// 业务代码
// ... ...
// argv 为 new 创建的对象,在使用完成后手动释放
delete argv;
return nullptr;
}
static napi_value GetArgvDemo2(napi_env env, napi_callback_info info) {
size_t argc = 2;
napi_value argv[2] = {nullptr};
// napi_get_cb_info 会向 argv 中写入 argc 个 JS 传入参数或 undefined
napi_get_cb_info(env, info, &argc, nullptr, nullptr, nullptr);
// 业务代码
// ... ...
return nullptr;
}生命周期管理
【规则】 合理使用napi_open_handle_scope和napi_close_handle_scope管理napi_value的生命周期,做到生命周期最小化,避免发生内存泄漏问题。
每个napi_value属于特定的HandleScope,HandleScope通过napi_open_handle_scope和napi_close_handle_scope来建立和关闭,HandleScope关闭后,所属的napi_value就会自动释放。
正确示例:
// 在for循环中频繁调用napi接口创建js对象时,要加handle_scope及时释放不再使用的资源。
// 下面例子中,每次循环结束局部变量res的生命周期已结束,因此加scope及时释放其持有的js对象,防止内存泄漏
for (int i = 0; i < 100000; i++) {
napi_handle_scope scope = nullptr;
napi_open_handle_scope(env, &scope);
if (scope == nullptr) {
return;
}
napi_value res;
napi_create_object(env, &res);
napi_close_handle_scope(env, scope);
}上下文敏感
【规则】 多引擎实例场景下,禁止通过Node-API跨引擎实例访问JS对象。
引擎实例是一个独立运行环境,JS对象创建访问等操作必须在同一个引擎实例中进行。若在不同引擎实例中操作同一个对象,可能会引发程序崩溃。引擎实例在接口中体现为napi_env。
错误示例:
// 线程1执行,在env1创建string对象,值为"bar"、
napi_create_string_utf8(env1, "bar", NAPI_AUTO_LENGTH, &string);
// 线程2执行,在env2创建object对象,并将上述的string对象设置到object对象中
napi_status status = napi_create_object(env2, &object);
if (status != napi_ok) {
napi_throw_error(env, ...);
return;
}
status = napi_set_named_property(env2, object, "foo", string);
if (status != napi_ok) {
napi_throw_error(env, ...);
return;
}所有的JS对象都隶属于具体的某一napi_env,不可将env1的对象,设置到env2中的对象中。在env2中一旦访问到env1的对象,程序可能会发生崩溃。
异常处理
【建议】 Node-API接口调用发生异常需要及时处理,不能遗漏异常到后续逻辑,否则程序可能发生不可预期行为。
正确示例:
// 1.创建对象
napi_status status = napi_create_object(env, &object);
if (status != napi_ok) {
napi_throw_error(env, ...);
return;
}
// 2.创建属性值
status = napi_create_string_utf8(env, "bar", NAPI_AUTO_LENGTH, &string);
if (status != napi_ok) {
napi_throw_error(env, ...);
return;
}
// 3.将步骤2的结果设置为对象object属性foo的值
status = napi_set_named_property(env, object, "foo", string);
if (status != napi_ok) {
napi_throw_error(env, ...);
return;
}如上示例中,步骤1或者步骤2出现异常时,步骤3都不会正常进行。只有当方法的返回值是napi_ok时,才能保持继续正常运行;否则后续流程可能会出现不可预期的行为。
异步任务
【规则】 当使用uv_queue_work方法将任务抛到JS线程上面执行的时候,对JS线程的回调方法,一般情况下需要加上napi_handle_scope来管理回调方法创建的napi_value的生命周期。
使用uv_queue_work方法,不会走Node-API框架,此时需要开发者自己合理使用napi_handle_scope来管理napi_value的生命周期。
正确示例:
void callbackTest(CallbackContext* context)
{
uv_loop_s* loop = nullptr;
napi_get_uv_event_loop(context->env, &loop);
uv_work_t* work = new uv_work_t;
context->retData = 1;
work->data = (void*)context;
uv_queue_work(
loop, work, [](uv_work_t* work) {},
// using callback function back to JS thread
[](uv_work_t* work, int status) {
CallbackContext* context = (CallbackContext*)work->data;
napi_handle_scope scope = nullptr;
napi_open_handle_scope(context->env, &scope);
if (scope == nullptr) {
if (work != nullptr) {
delete work;
}
delete context;
return;
}
napi_value callback = nullptr;
napi_get_reference_value(context->env, context->callbackRef, &callback);
napi_value retArg;
napi_create_int32(context->env, context->retData, &retArg);
napi_value ret;
napi_call_function(context->env, nullptr, callback, 1, &retArg, &ret);
napi_delete_reference(context->env, context->callbackRef);
napi_close_handle_scope(context->env, scope);
if (work != nullptr) {
delete work;
}
delete context;
}
);
}对象绑定
【规则】 使用napi_wrap接口,如果最后一个参数result传递不为nullptr,需要开发者在合适的时机调用napi_remove_wrap函数主动删除创建的napi_ref。
napi_wrap接口定义如下:
napi_wrap(napi_env env, napi_value js_object, void* native_object, napi_finalize finalize_cb, void* finalize_hint, napi_ref* result)当最后一个参数result不为空时,框架会创建一个napi_ref对象,指向js_object。此时开发者需要自己管理js_object的生命周期,即需要在合适的时机调用napi_remove_wrap删除napi_ref,这样GC才能正常释放js_object,从而触发绑定C++对象native_object的析构函数finalize_cb。
一般情况下,根据业务情况最后一个参数result可以直接传递为nullptr。
正确示例:
// 用法1:napi_wrap不需要接收创建的napi_ref,最后一个参数传递nullptr,创建的napi_ref是弱引用,由系统管理,不需要用户手动释放
napi_wrap(env, jsobject, nativeObject, cb, nullptr, nullptr);
// 用法2:napi_wrap需要接收创建的napi_ref,最后一个参数不为nullptr,返回的napi_ref是强引用,需要用户手动释放,否则会内存泄漏
napi_ref result;
napi_wrap(env, jsobject, nativeObject, cb, nullptr, &result);
// 当js_object和result后续不再使用时,及时调用napi_remove_wrap释放result
void* nativeObjectResult = nullptr;
napi_remove_wrap(env, jsobject, &nativeObjectResult);高性能数组
【建议】 存储值类型数据时,使用ArrayBuffer代替JSArray来提高应用性能。
使用JSArray作为容器储存数据,支持几乎所有的JS数据类型。
使用napi_set_element方法对JSArray存储值类型数据(如int32)时,同样会涉及到与运行时的交互,造成不必要的开销。
ArrayBuffer进行增改是直接对缓冲区进行更改,具有远优于使用napi_set_element操作JSArray的性能表现。
因此此种场景下,更推荐使用napi_create_arraybuffer接口创建的ArrayBuffer对象。
示例:
// 以下代码使用常规JSArray作为容器,但其仅存储int32类型数据。
// 但因为是JS对象,因此只能使用napi方法对其进行增改,性能较低。
static napi_value ArrayDemo(napi_env env, napi_callback_info info)
{
constexpr size_t arrSize = 1000;
napi_value jsArr = nullptr;
napi_create_array(env, &jsArr);
for (int i = 0; i < arrSize; i++) {
napi_value arrValue = nullptr;
napi_create_int32(env, i, &arrValue);
// 常规JSArray使用napi方法对array进行读写,性能较差。
napi_set_element(env, jsArr, i, arrValue);
}
return jsArr;
}
// 推荐写法:
// 同样以int32类型数据为例,但以下代码使用ArrayBuffer作为容器。
// 因此可以使用C/C++的方法直接对缓冲区进行增改。
static napi_value ArrayBufferDemo(napi_env env, napi_callback_info info)
{
constexpr size_t arrSize = 1000;
napi_value arrBuffer = nullptr;
void* data = nullptr;
napi_create_arraybuffer(env, arrSize * sizeof(int32_t), &data, &arrBuffer);
int32_t* i32Buffer = reinterpret_cast<int32_t*>(data);
for (int i = 0; i < arrSize; i++) {
// arrayBuffer直接对缓冲区进行修改,跳过运行时,
// 与操作原生C/C++对象性能相当
i32Buffer[i] = i;
}
return arrBuffer;
}napi_create_arraybuffer等同于JS代码中的new ArrayBuffer(size),其生成的对象不可直接在TS/JS中进行读取,需要将其包装为TyppedArray或DataView后方可进行读写。
基准性能测试结果如下:
说明
以下数据为千次循环写入累计数据,为更好的体现出差异,已对设备核心频率进行限制。
| 容器类型 | Benchmark数据(us) |
|---|---|
| JSArray | 1566.174 |
| ArrayBuffer | 3.609 |
数据转换
【建议】 尽可能的减少数据转换次数,避免不必要的复制。
- 减少数据转换次数: 频繁的数据转换可能会导致性能下降,可以通过批量处理数据或者使用更高效的数据结构来优化性能;
- 避免不必要的数据复制: 在进行数据转换时,可以使用Node-API提供的接口来直接访问原始数据,而不是创建新的副本;
- 使用缓存: 如果某些数据在多次转换中都会被使用到,可以考虑使用缓存来避免重复的数据转换。缓存可以减少不必要的计算,提高性能。
模块注册与模块命名
【规则】
nm_register_func对应的函数需要加上修饰符static,防止与其他so里的符号冲突。
模块注册的入口,即使用__attribute__((constructor))修饰函数的函数名需要确保与其他模块不同。
模块实现中.nm_modname字段需要与模块名完全匹配,区分大小写。
错误示例
以下代码为模块名为nativerender时的错误示例
EXTERN_C_START
napi_value Init(napi_env env, napi_value exports)
{
// ...
return exports;
}
EXTERN_C_END
static napi_module nativeModule = {
.nm_version = 1,
.nm_flags = 0,
.nm_filename = nullptr,
//没有在nm_register_func对应的函数加上static
.nm_register_func = Init,
// 模块实现中.nm_modname字段没有与模块名完全匹配,会导致多线程场景模块加载失败
.nm_modname = "entry",
.nm_priv = nullptr,
.reserved = { 0 },
};
//模块注册的入口函数名为RegisterModule,容易与其他模块重复。
extern "C" __attribute__((constructor)) void RegisterModule()
{
napi_module_register(&nativeModule);
}正确示例:
以下代码为模块名为nativerender时的正确示例
EXTERN_C_START
static napi_value Init(napi_env env, napi_value exports)
{
// ...
return exports;
}
EXTERN_C_END
static napi_module nativeModule = {
.nm_version = 1,
.nm_flags = 0,
.nm_filename = nullptr,
.nm_register_func = Init,
.nm_modname = "nativerender",
.nm_priv = nullptr,
.reserved = { 0 },
};
extern "C" __attribute__((constructor)) void RegisterNativeRenderModule()
{
napi_module_register(&nativeModule);
}正确的使用napi_create_external系列接口创建的JS Object
【规则】 napi_create_external系列接口创建出来的JS对象仅允许在当前线程传递和使用,跨线程传递(如使用worker的post_message)将会导致应用crash。若需跨线程传递绑定有Native对象的JS对象,请使用napi_coerce_to_native_binding_object接口绑定JS对象和Native对象。
错误示例
static void MyFinalizeCB(napi_env env, void *finalize_data, void *finalize_hint) { return; };
static napi_value CreateMyExternal(napi_env env, napi_callback_info info) {
napi_value result = nullptr;
napi_create_external(env, nullptr, MyFinalizeCB, nullptr, &result);
return result;
}
// 此处已省略模块注册的代码, 你可能需要自行注册 CreateMyExternal 方法// index.d.ts
export const createMyExternal: () => Object;
// 应用代码
import testNapi from 'libentry.so';
import worker from '@ohos.worker';
const mWorker = new worker.ThreadWorker('../workers/Worker');
{
const mExternalObj = testNapi.createMyExternal();
mWorker.postMessage(mExternalObj);
}
// 关闭worker线程
// 应用可能在此步骤崩溃, 或在后续引擎进行GC的时候崩溃
mWorker.terminate();
// Worker的实现为默认模板,此处省略其它
【规则】 使用napi_get_arraybuffer_info接口,第三个参数data资源开发者不允许释放,data的生命周期受引擎管理。
napi_get_arraybuffer_info接口定义如下:
napi_get_arraybuffer_info(napi_env env, napi_value arraybuffer, void** data, size_t* byte_length)data获取的是ArrayBuffer的Buffer头指针,开发者只可以在范围内读写该Buffer区域,不可以进行释放操作。该段内存由引擎内部的ArrayBuffer Allocator管理,随JS对象ArrayBuffer的生命周期释放。
错误示例:
void* arrayBufferPtr = nullptr;
napi_value arrayBuffer = nullptr;
size_t createBufferSize = ARRAY_BUFFER_SIZE;
napi_status verification = napi_create_arraybuffer(env, createBufferSize, &arrayBufferPtr, &arrayBuffer);
size_t arrayBufferSize;
napi_status result = napi_get_arraybuffer_info(env, arrayBuffer, &arrayBufferPtr, &arrayBufferSize);
delete arrayBufferPtr; // 这一步是禁止的,创建的arrayBufferPtr生命周期由引擎管理,不允许用户自己delete,否则会double free【建议】 合理使用napi_object_freeze和napi_object_seal来控制对象以及对象属性的可变性。
napi_object_freeze等同于Object.freeze语义,freeze后对象的所有属性都不可能以任何方式被修改;napi_object_seal等同于Object.seal语义,对象不可增删属性。两者的主要区别是,freeze不能改属性的值,seal还可以改属性的值。
开发者使用以上语义时,需确保约束条件是自己需要的,一旦违背以上语义严格模式下就会抛出Error(默认严格模式)。
Node-API常见问题
ArkTS/JS侧import xxx from libxxx.so后,使用xxx报错显示undefined/not callable或明确的Error message
-
排查.cpp文件在注册模块时的模块名称与so的名称匹配一致。
如模块名为entry,则so的名字为libentry.so,napi_module中nm_modname字段应为entry,大小写与模块名保持一致。
-
排查so是否加载成功。
应用启动时过滤模块加载相关日志,重点搜索"dlopen"关键字,确认是否有相关报错信息;常见加载失败原因有权限不足、so文件不存在以及so已拉入黑名单等,可根据以下关键错误日志确认问题。其中,多线程场景(worker、taskpool等)下优先检查模块实现中nm_modname是否与模块名一致,区分大小写。
-
排查依赖的so是否加载成功。
确定所依赖的其它so是否打包到应用中以及是否有权限打开。常见加载失败原因有权限不足、so文件不存在等,可根据以下关键错误日志确认问题。
-
排查模块导入方式与so路径是否对应。
若JS侧导入模块的形式为: import xxx from '@ohos.yyy.zzz',则该so将在/system/lib/module/yyy中找libzzz.z.so或libzzz_napi.z.so,若so不存在或名称无法对应,则报错日志中会出现dlopen相关日志。
注意,32位系统路径为/system/lib,64位系统路径为/system/lib64。
| 已知关键错误日志 | 修改建议 |
|---|---|
| module $SO is not allowed to load in restricted runtime | $SO表示模块名。该模块不在受限worker线程的so加载白名单,不允许加载,建议用户删除该模块。 |
| module $SO is in blocklist, loading prohibited | $SO表示模块名。受卡片或者Extension管控,该模块在黑名单内,不允许加载,建议用户删除该模块。 |
| load module failed. $ERRMSG | 动态库加载失败。$ERRMSG表示加载失败原因,一般常见原因是so文件不存在、依赖的so文件不存在或者符号未定义,需根据加载失败原因具体分析。 |
| try to load abc file from $FILEPATH failed. | 通常加载动态库和abc文件为二选一:如果是要加载动态库并且加载失败,该告警可以忽略;如果是要加载abc文件,则该错误打印的原因是abc文件不存在,$FILEPATH表示模块路径。 |
- 如果有明确的Error message,可以通过Error message判断当前问题。
| Error message | 修改建议 |
|---|---|
| First attempt: $ERRMSG | 首先加载后缀不拼接'_napi'的模块名为'xxx'的so,如果加载失败会有该错误信息,$ERRMSG表示具体加载时的错误信息。 |
| Second attempt: $ERRMSG | 第二次加载后缀拼接'_napi'的模块名为'xxx_napi'的so,如果加载失败会有该错误信息,$ERRMSG表示具体加载时的错误信息。 |
| try to load abc file from xxx failed | 第三次加载名字为'xxx'的abc文件,如果加载失败会有该错误信息。 |
| module xxx is not allowed to load in restricted runtime. | 该模块不允许在受限运行时中使用,xxx表示模块名,建议用户删除该模块。 |
| module xxx is in blocklist, loading prohibited. | 该模块不允许在当前extension下使用,xxx表示模块名,建议用户删除该模块。 |
接口执行结果非预期,日志显示occur exception need return
部分Node-API接口在调用结束前会进行检查,检查虚拟机中是否存在JS异常。如果存在异常,则会打印出occur exception need return日志,并打印出检查点所在的行号,以及对应的Node-API接口名称。
解决此类问题有以下两种思路:
-
若该异常开发者不关心,可以选择直接清除。
可直接使用napi接口napi_get_and_clear_last_exception,清理异常。调用时机:在打印occur exception need return日志的接口之前调用。
-
将该异常继续向上抛到ArkTS层,在ArkTS层进行捕获。
发生异常时,可以选择走异常分支, 确保不再走多余的Native逻辑 ,直接返回到ArkTS层。
napi_value和napi_ref的生命周期有何区别
-
native_value由HandleScope管理,一般开发者不需要自己加HandleScope(uv_queue_work的complete callback除外)。
-
napi_ref由开发者自己管理,需要手动delete。
Node-API接口返回值不是napi_ok时,如何排查定位
Node-API接口正常执行后,会返回一个napi_ok的状态枚举值,若napi接口返回值不为napi_ok,可从以下几个方面进行排查。
-
Node-API接口执行前一般会进行入参校验,首先进行的是判空校验。在代码中体现为:
CHECK_ENV: env判空校验 CHECK_ARG:其它入参判空校验 -
某些Node-API接口还有入参类型校验。比如napi_get_value_double接口是获取JS number对应的C double值,首先就要保证的是:JS value类型为number,因此可以看到相关校验。
RETURN_STATUS_IF_FALSE(env, nativeValue->TypeOf() == NATIVE_NUMBER, napi_number_expected); -
还有一些接口会对其执行结果进行校验。比如napi_call_function这个接口,其功能是执行一个JS function,当JS function中出现异常时,Node-API将会返回napi_pending_exception的状态值。
auto resultValue = engine->CallFunction(nativeRecv, nativeFunc, nativeArgv, argc); RETURN_STATUS_IF_FALSE(env, resultValue != nullptr, napi_pending_exception) -
还有一些状态值需要根据相应Node-API接口具体分析:确认具体的状态值,分析这个状态值在什么情况下会返回,再排查具体出错原因。
最后
有很多小伙伴不知道学习哪些鸿蒙开发技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?而且学习时频繁踩坑,最终浪费大量时间。所以有一份实用的鸿蒙(HarmonyOS NEXT)资料用来跟着学习是非常有必要的。
点击→【纯血版鸿蒙全套最新学习资料】希望这一份鸿蒙学习资料能够给大家带来帮助!~
鸿蒙(HarmonyOS NEXT)最新学习路线
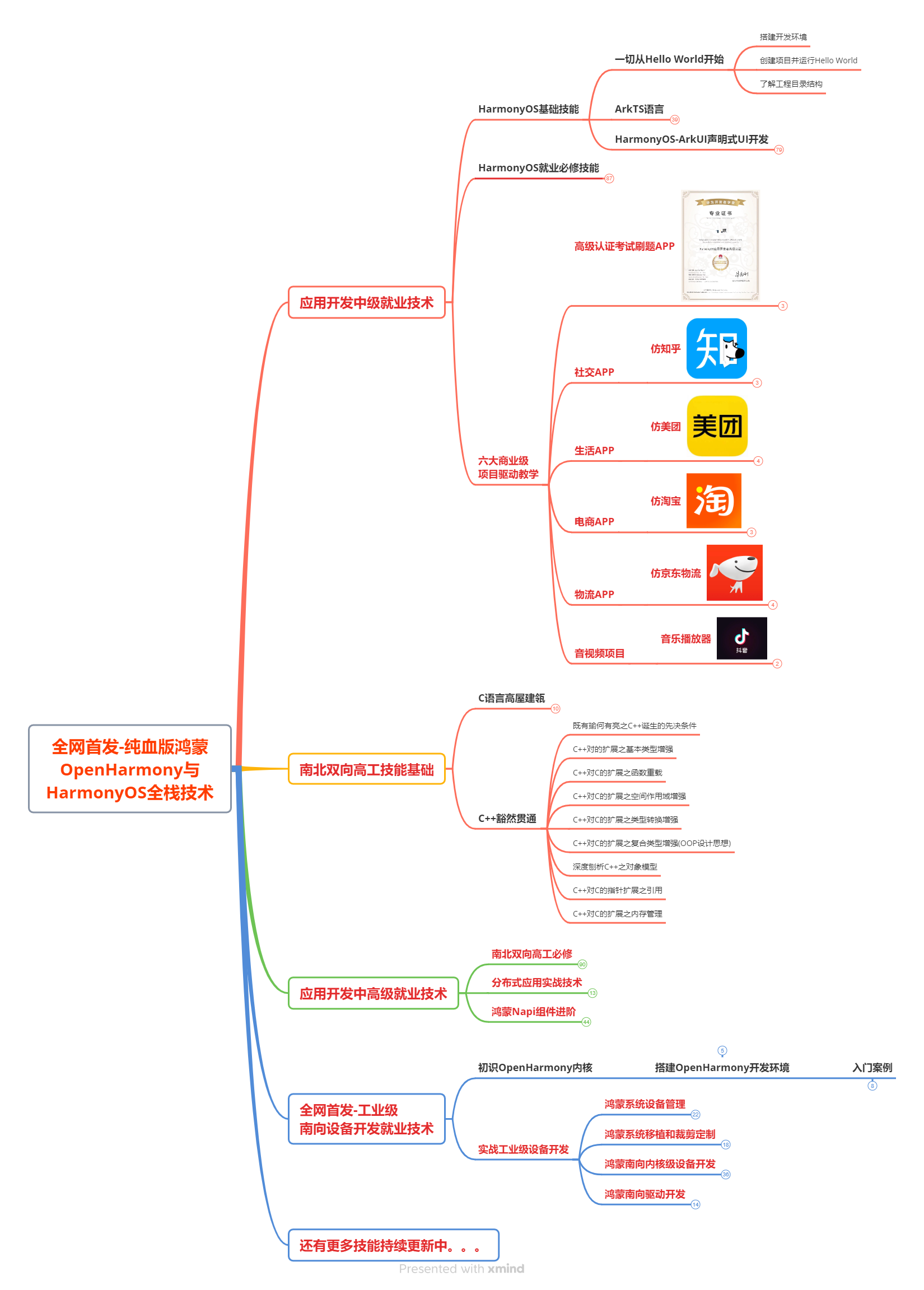
该路线图包含基础技能、就业必备技能、多媒体技术、六大电商APP、进阶高级技能、实战就业级设备开发,不仅补充了华为官网未涉及的解决方案
路线图适合人群:
IT开发人员:想要拓展职业边界
零基础小白:鸿蒙爱好者,希望从0到1学习,增加一项技能。
技术提升/进阶跳槽:发展瓶颈期,提升职场竞争力,快速掌握鸿蒙技术
获取以上完整版高清学习路线,请点击→纯血版全套鸿蒙HarmonyOS学习资料
2.视频学习资料+学习PDF文档
这份鸿蒙(HarmonyOS NEXT)资料包含了鸿蒙开发必掌握的核心知识要点,内容包含了(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、音频、视频、WebGL、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、(南向驱动、嵌入式等)鸿蒙项目实战等等)鸿蒙(HarmonyOS NEXT)技术知识点。
HarmonyOS Next 最新全套视频教程
《鸿蒙 (OpenHarmony)开发基础到实战手册》
OpenHarmony北向、南向开发环境搭建
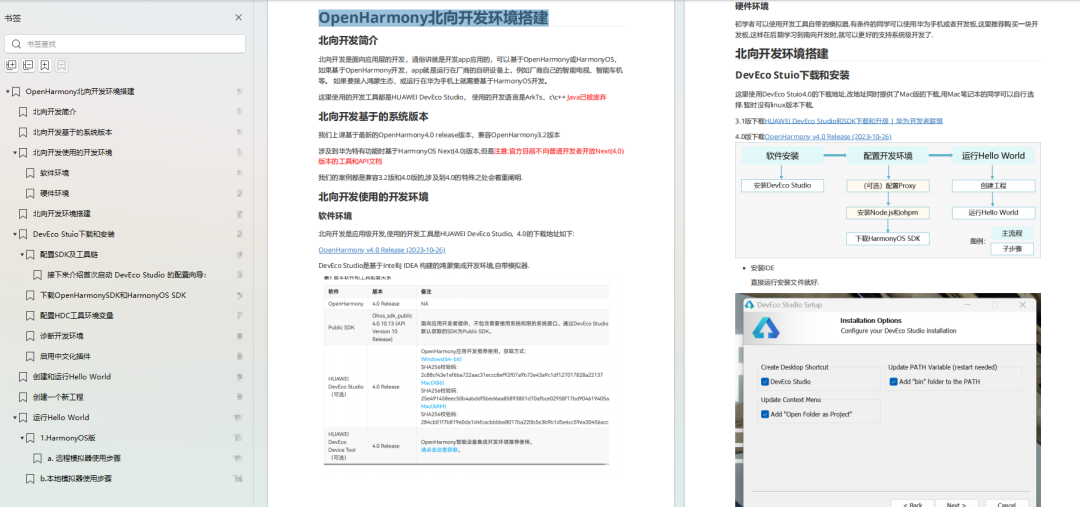
《鸿蒙开发基础》
- ArkTS语言
- 安装DevEco Studio
- 运用你的第一个ArkTS应用
- ArkUI声明式UI开发
- .……

《鸿蒙开发进阶》
《鸿蒙进阶实战》

大厂面试必问面试题

鸿蒙南向开发技术
鸿蒙APP开发必备

点击→纯血版全套鸿蒙HarmonyOS学习资料
总结
总的来说,华为鸿蒙不再兼容安卓,对程序员来说是一个挑战,也是一个机会。只有积极应对变化,不断学习和提升自己,才能在这个变革的时代中立于不败之地。















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









