







概要
本实验使用streamlit库设计前端页面,提供数据输入、超参数调整等功能。展示模型训练结果和评估指标,如准确率、混淆矩阵、ROC曲线等。同时使用 Streamlit 构建简单易用的Web界面,也可以实现用户与模型的交互。(代码在资源绑定里面。)
前情回顾
上一篇文章我们用了KNN,SVM,决策树和随机森林模型,并记录了一些在不同参数下模型的性能度量。通过储存的文件来进行观察并进行了简单的对比。得到模型XGBoost的效果最好。
整体架构流程
模型对比概述(分析可以看上一篇文章)
当 KNN 模型中的 K 值为 13 时,模型的性能最为优越。
SVM 模型核函数为 rbf,正则化参数为 1 时模型效果最优。
决策树模型度量标准参数为 entropy,最大深度参数为 4时模型效果最优。
随机森林模型决策树个数为 400,最大深度参数为 4 时模型效果最优。
XGBoost 模型,学习率为 0.01,决策树个数为 500,最大深度参数为 4 时模型效果最优。
模型性能对比可视化
我们选择每一个模型在最优的参数下(参数)所做的性能对比。
models = {
"KNN": KNeighborsClassifier(n_neighbors=14),
"SVM": SVC(kernel='rbf', C=1, probability=True),
"Decision Tree": DecisionTreeClassifier(criterion='entropy', max_depth=4),
"Random Forest": RandomForestClassifier(n_estimators=400, max_depth=4),
"XGBoost": xgb.XGBClassifier(learning_rate=0.01, n_estimators=500, max_depth=4)
}
# 定义性能度量的列表
metrics = ['Accuracy', 'Recall', 'F1 Score']
performance_data = {model: [] for model in models}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred, average='macro') # 根据需求选择指标
f1 = f1_score(y_test, y_pred, average='macro') # 根据需求选择指标
performance_data[name] = [accuracy, recall, f1] # 将每一个模型转换字典为数组形式存储起来,以便绘制图像
performance_matrix = np.array(list(performance_data.values()))
bar_width = 0.2 # 定义柱状图的宽度和间距
index = np.arange(len(models))
colors = ['r', 'b', 'g']
plt.figure(figsize=(10, 6))
for i, metric in enumerate(metrics):
plt.bar(index + i * bar_width, performance_matrix[:, i], bar_width, label=metric, color=colors[i])
plt.xlabel('模型种类')
plt.ylabel('分数')
plt.title('模型性能对比')
plt.xticks(index + bar_width, models.keys()) # 设置模型名称作为x轴刻度(每隔一个bar_width的距离)
plt.legend()
plt.tight_layout()
plt.show()
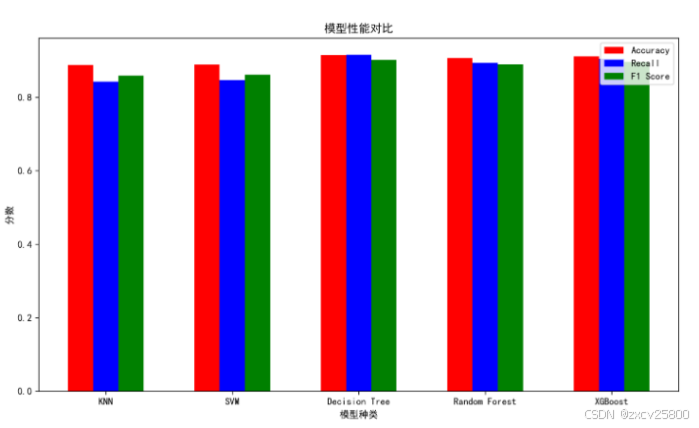
由图可以清晰地看出,在各项评价指标上,包括准确率、召回率和 F1 值,决策树模型均表现出色,得分远高于其他模型。与之相比,XGBoost 模型虽然表现次于决策树,但在准确率和 F1 值上仍然保持较高的水平,说明其在一些复杂任务中具有一定的优势。基于这些评估指标,决策树模型无疑是当前任务中最优的选择。它不仅在多个评估标准上表现突出,而且其模型结构直观、易于理解,便于后续的模型优化与调整。相比之下,XGBoost 等模型虽然在某些情境下可能表现更为复杂,但由于其相对较长的训练时间和对参数调优的需求,在某些应用场景下可能未必是最优选择。
因此,结合实验结果和模型性能分析,我们建议采用决策树模型进行数据的预测和分析,以获得更高效、更准确的结果。
前端展示
为方便数据的输入以及分析,所以设计出一个前端页面来进行更好的效果展示。Streamlit是一个开源的Python库,旨在快速搭建机器学习和数据科学的交互式Web应用。借助Streamlit,可以轻松创建前端界面,展示模型的预测、可视化图表等内容。
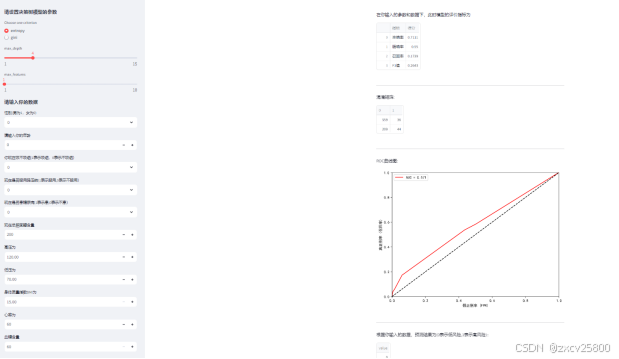
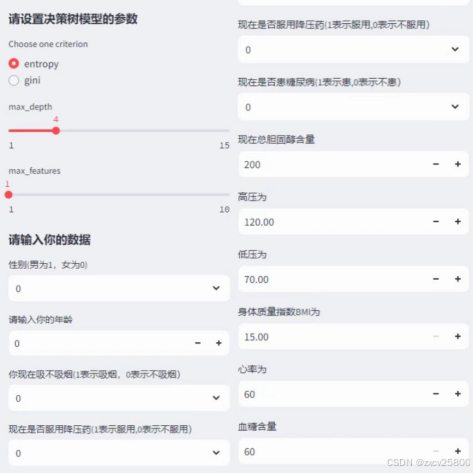
如图1所示,整个前端分为左右两个栏目,用于分别区分用户输入和模型预测输出。如图2所示,这个前端左侧栏实现了一个交互式的高血压风险预测系统,用户可以通过输入一系列个体化的健康数据来预测其是否存在高血压风险。输入的数据涵盖了多个方面,包括:性别、年龄、吸烟状况、每日吸烟量、是否服用降压药、糖尿病状况、总胆固醇、血压值、体重指数(BMI)、心率、血糖水平以及其他健康风险指标。这些信息能够帮助系统更精准地分析和预测高血压的风险,给出个性化的预测结果。
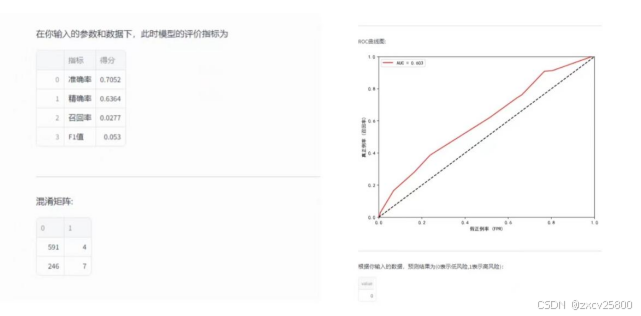
如上图所示,在页面的右侧栏,展示了基于输入数据的决策树模型预测结果,包括模型判断的风险等级(如低风险、中风险或高风险)以及相关的预测概率。同时,还提供了模型在当前设置参数下的各类评估指标,这些指标包括:预测的准确率、召回率、精确率、F1值等常见的分类模型评估标准。此外,还展示了混淆矩阵,它帮助用户理解模型的分类效果以及不同分类结果的分布情况。
为了进一步评估模型的表现,页面还提供了AUC(曲线下面积)值和ROC(接收者操作特征)曲线,这些工具能够帮助用户评估模型在各种阈值下的预测能力和分类效果。这些评价指标的展示,旨在让用户更全面地了解模型的实际表现,并为进一步优化和调整模型提供依据。
小结
在此次实验中,是通过边上实践课边学习代码敲出来的,也是第一次接触streamlit函数,发现设计前端页面也比较有趣,当然在第一次运行前段代码时也比较迷糊,前端页面python代码是要在终端运行的(无法在集成器中打开运行),而且每写一点代码,只要刷新页面,代码好想就会自己运行了一样,直接把运行结果展示在页面上。以下为我在网上找到对streamlit的功能的解释,可以帮助我们更好的深入了解其功能。
同时在本次工作中,通过对多个机器学习模型(如KNN、决策树、XGBoost等)的设计、训练和优化,我们成功地提高了模型性能,并实现了对不同超参数的系统化调优。通过构建基础函数和利用循环自动化参数设置与模型训练,我们有效地简化了流程,减少了冗余代码,使得模型的训练与评估更加高效。但是尽管通过自动化流程对不同的超参数进行调优,但模型选择和参数空间的设置仍然是有限的,可能没有覆盖到所有可能的组合,有可能会错过最优模型的参数,导致得到的结果可能不是最佳的。在某些复杂的任务中,进行大规模的超参数搜索时,尤其是对于一些复杂模型(如XGBoost、随机森林等),训练和评估过程的计算开销较大,可能会有较长的计算时间。
答辩总结
gini指数和entropy参数都是决策树的分支的评判标准。
Gini指数计算相对简单,能够有效地处理连续型和离散型数据。并且在类别分布比较均匀的情况下,Gini 指数能够很好地衡量数据集的纯度。但是当类别数量较多时,可能会导致过度拟合。因为它更倾向于将数据集划分成多个小的、纯的子集,可能会使得决策树过于复杂。
从entropy(信息熵)的角度很好地衡量了数据的不确定性,对于理解数据的内在结构有很好的理论支持。在处理分类问题时,能够有效地找到最能降低不确定性的划分属性。计算涉及对数运算,相对 Gini 指数计算复杂度稍高。而且对于连续型数据,需要先进行离散化处理才能更好地应用信息熵来划分。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









