






文章目录
研究背景
高血压是全球常见的慢性疾病,是心血管疾病的主要风险因素,严重影响健康。由于高血压早期常无明显症状,传统的血压测量方法难以提前预测风险。因此,早期预测和干预至关重要。
在现如今社会高速发展的情况下,人们的生活水平越来越高,在追求精神和物资丰富的同时,疾病也在悄然而至。所以在这个情况下,我们需要对高血压,高血糖,高胆固醇等一系列祸从口入的疾病进行研究,随着大数据和人工智能的发展,通过多维数据(如生活方式、遗传因素等)建立预测模型,能够更准确地评估个体的高血压风险。这为个性化预防和治疗提供了基础,有助于提高健康管理效率,减少高血压及其并发症的发生。本文就是对高血压风险预测。
数据可视化展示
本文所用到的数据集是来自https://www.heywhale.com/mw/dataset/6736f8d20bb59b78302c1397/content
高血压与各个特征的关系
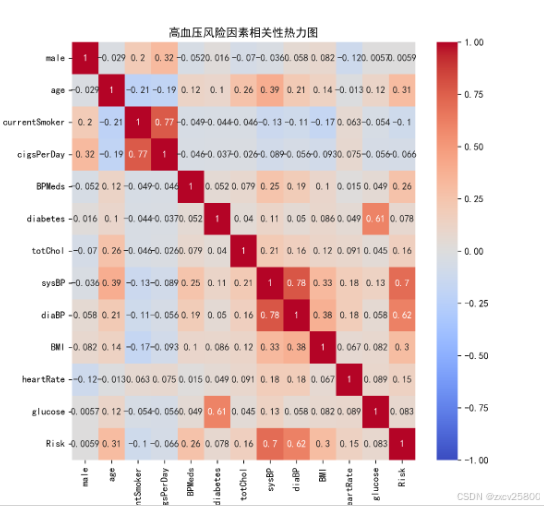
由热力图可以知道每一个特征与高血压患病的风险的关系,其中可以看出年龄,血管的舒张与收缩的压强有关,接下来我们将对个别数据关系进行可视化。
年龄与高血压的关系
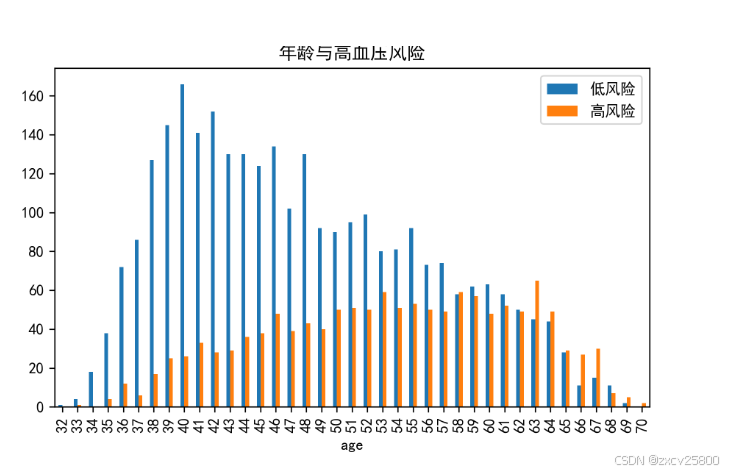
由图看出来,在随着年龄的增加,人们患高血压的风险越来越高,其中中年人患高血压的风险最高,所以对中老年人高血压检测是很必要的。
收缩压(高压)与舒张压(低压)与患高血压的关系
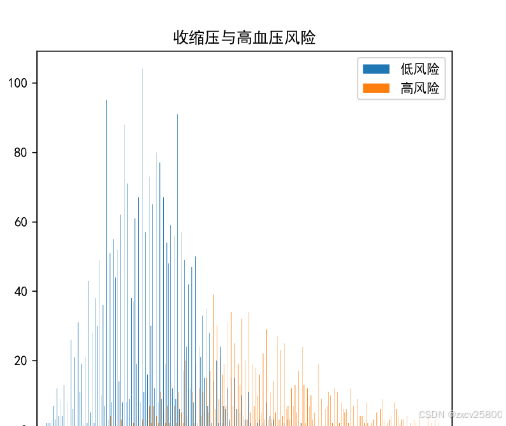
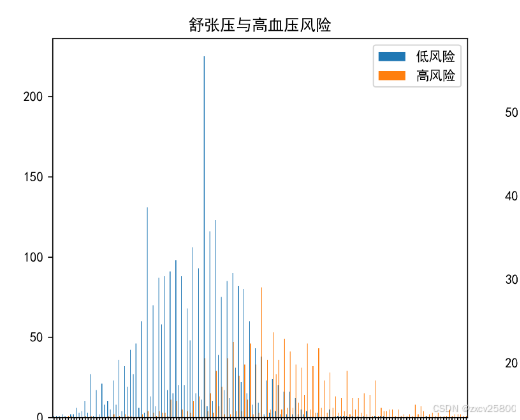
医学上规定收缩压大于140mmHg,舒张压小于90mmHg的是高血压,由图也可以轻易看出来收缩压和舒张压越高,患高血压的风险就越大。
整体架构流程
导入必要的库
#分类任务
import sklearn
import numpy as np
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split #划分数据集
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score,confusion_matrix
from sklearn.metrics import roc_curve, auc
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
plt.rcParams['font.family'] = 'simhei' # 可以让图像中显示中文(黑体),无需引用
plt.rcParams['axes.unicode_minus'] = False
数据分析预处理
"'数据预处理'"
df = pd.read_csv(r"C:\Users\lenovo\Desktop\zxd\作业\机器学习实践\高血压数据集\Hypertension-risk-model-main.csv")
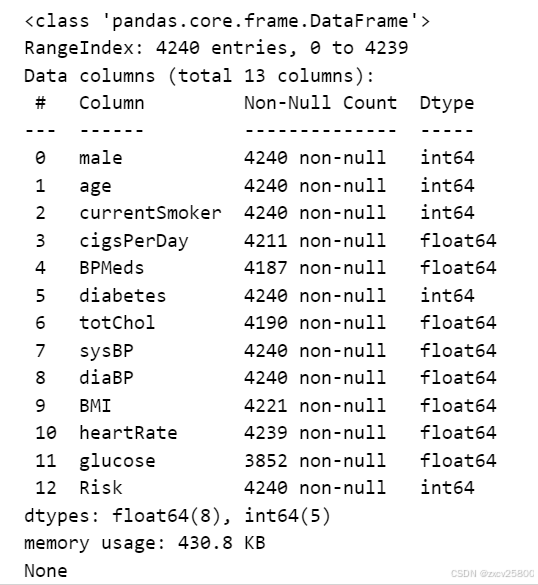
# print(df.shape) #查看数据大小为(4241,13)
# print(df.isnull().sum()) #查看每一类的缺失值 # print(df.isna().sum())一样
# print(df.info()) #获取数据的基本统计信息
for column in df.columns:
if df[column].dtype in ["int64", "float64"]:
mean_value = df[column].mean() #用均值填充空值
df[column].fillna(mean_value, inplace = True)
X = df.iloc[:,:-1].values
y = df.iloc[:,-1].values
# print(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size = 0.8,random_state = 42) #数据集的分割
模型的训练
KNN模型
knn_model = KNeighborsClassifier(n_neighbors=5)
# knn_model.fit(X_train,y_train)
# y_pred = knn_model.predict(X_test)
# accuracy_score(y_test,y_pred)
evaluation = pd.DataFrame({'Model': [],
'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': [],
'AUC值': []})
def knn_diff_criterion(model,k, X_train, y_train,X_test,y_test):
dt_model = model
dt_model.fit(X_train, y_train)
y_test_predict = dt_model.predict(X_test)
acc_test = accuracy_score(y_test, y_test_predict)
precision_test = precision_score(y_test, y_test_predict)
recall_test = recall_score(y_test, y_test_predict)
f1score_test = f1_score(y_test, y_test_predict)
y_test_predict_proba = dt_model.predict_proba(X_test)
# print('y_train_pre_proba', y_train_predict_proba)
false_positive_rate, recall, thresholds = roc_curve(y_test, y_test_predict_proba[:, 1])
roc_auc = auc(false_positive_rate, recall) # 计算auc的值
r = evaluation.shape[0]
evaluation.loc[r] = ['knn分类模型(k值为为{})'.format(k), acc_test,
precision_test, recall_test, f1score_test, roc_auc]
evaluation.to_csv('./evaluation_knn2.csv', sep=',', header=True, index=True,
encoding='utf_8_sig')
for k in range(2,100):
knn_model = KNeighborsClassifier(n_neighbors=k)
knn_diff_criterion(knn_model,k, X_train, y_train,X_test,y_test)
SVM模型
svm_model = SVC(kernel='linear')
# svm_model.fit(X_train,y_train)
# y_pred = svm_model.predict(X_test)
# accuracy_score(y_test,y_pred)
evaluation = pd.DataFrame({'Model': [],
'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': [],
'AUC值': []})
def SVM_diff_criterion(model, k, c, X_train, y_train,X_test,y_test):
dt_model = model
dt_model.fit(X_train, y_train)
y_test_predict = dt_model.predict(X_test)
acc_test = accuracy_score(y_test, y_test_predict)
precision_test = precision_score(y_test, y_test_predict)
recall_test = recall_score(y_test, y_test_predict)
f1score_test = f1_score(y_test, y_test_predict)
y_test_predict_proba = dt_model.predict_proba(X_test)
# print('y_test_pre_proba', y_test_predict_proba)
false_positive_rate, recall, thresholds = roc_curve(y_test, y_test_predict_proba[:, 1])
roc_auc = auc(false_positive_rate, recall) # 计算auc的值
r = evaluation.shape[0]
evaluation.loc[r] = ['SVM分类模型(核为{},正则化参数为{})'.format(k, c), acc_test,
precision_test, recall_test, f1score_test, roc_auc]
evaluation.to_csv('./evaluation_SVM2.csv', sep=',', header=True, index=True,
encoding='utf_8_sig')
kernel = ['rbf','poly']
C = [1, 2, 3, 4]
for k in kernel:
for c in C:
model = SVC(kernel=k, C=c,probability=True)
SVM_diff_criterion(model, k, c, X_train, y_train,X_test,y_test)
决策树模型
# knn_model = KNeighborsClassifier(n_neighbors=5)
# knn_model.fit(X_train,y_train)
# y_pred = knn_model.predict(X_test)
# accuracy_score(y_test,y_pred)
evaluation = pd.DataFrame({'Model': [],
'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': [],
'AUC值': []})
def decision_tree_with_diff_criterion(model,criterion,max_depth,feature, X_train, y_train,X_test,y_test):
dt_model = model
dt_model.fit(X_train, y_train)
y_test_predict = dt_model.predict(X_test)
acc_test = accuracy_score(y_test, y_test_predict)
precision_test = precision_score(y_test, y_test_predict)
recall_test = recall_score(y_test, y_test_predict)
f1score_test = f1_score(y_test, y_test_predict)
y_test_predict_proba = dt_model.predict_proba(X_test)
# print('y_train_pre_proba', y_train_predict_proba)
false_positive_rate, recall, thresholds = roc_curve(y_test, y_test_predict_proba[:, 1])
roc_auc = auc(false_positive_rate, recall) # 计算auc的值
r = evaluation.shape[0]
evaluation.loc[r] = ['决策树分类模型(度量标准为{},深度为{},最大特征数为{})'.format(criterion, max_depth,feature), acc_test,
precision_test, recall_test, f1score_test, roc_auc]
evaluation.to_csv('./evaluation_dtree.csv', sep=',', header=True, index=True,
encoding='utf_8_sig')
criterion_all = ['gini', 'entropy'] # gini-CART算法,entropy——ID3算法
max_depths = [1, 2, 3, 4,5]
max_features = [1,2,3,4,5,6,7,8,9,10]
for criterion_select in criterion_all:
for max_depth in max_depths:
for feature in max_features:
model = DecisionTreeClassifier(criterion=criterion_select, max_depth=max_depth,max_features=feature)
decision_tree_with_diff_criterion(model,criterion_select,max_depth,feature,X_train, y_train,X_test,y_test)
随机森林模型
# rtree_modle = RandomForestClassifier(n_estimators = 500,random_state=42)
# rtree_model.fit(X_train,y_train)
# y_pred = rtree_model.predict(X_test)
# accuracy_score(y_test,y_pred)
evaluation = pd.DataFrame({'Model': [],
'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': [],
'AUC值': []})
def random_tree_diff_criterion(model, estimator, depth, X_train, y_train,X_test,y_test):
dt_model = model
dt_model.fit(X_train, y_train)
y_test_predict = dt_model.predict(X_test)
acc_test = accuracy_score(y_test, y_test_predict)
precision_test = precision_score(y_test, y_test_predict)
recall_test = recall_score(y_test, y_test_predict)
f1score_test = f1_score(y_test, y_test_predict)
y_test_predict_proba = dt_model.predict_proba(X_test)
# print('y_train_pre_proba', y_train_predict_proba)
false_positive_rate, recall, thresholds = roc_curve(y_test, y_test_predict_proba[:, 1])
roc_auc = auc(false_positive_rate, recall) # 计算auc的值
r = evaluation.shape[0]
evaluation.loc[r] = ['随机森林分类模型(核为{},深度为{})'.format(estimator, depth), acc_test,
precision_test, recall_test, f1score_test, roc_auc]
evaluation.to_csv('./evaluation_rtree2.csv', sep=',', header=True, index=True,
encoding='utf_8_sig')
n_estimators = [300,400,500]
max_depths = [1, 2, 3, 4]
for n_estimator in n_estimators:
for depth in max_depths:
rtree_model = RandomForestClassifier(n_estimators = n_estimator,max_depth=depth,random_state=42)
random_tree_diff_criterion(rtree_model,n_estimator, depth, X_train, y_train,X_train,y_train)
例如:
代码运行完都会在本地生成一个csv文件,用来保存数据。接下来是部分csv文件的内容,仅供参考。
结果展示

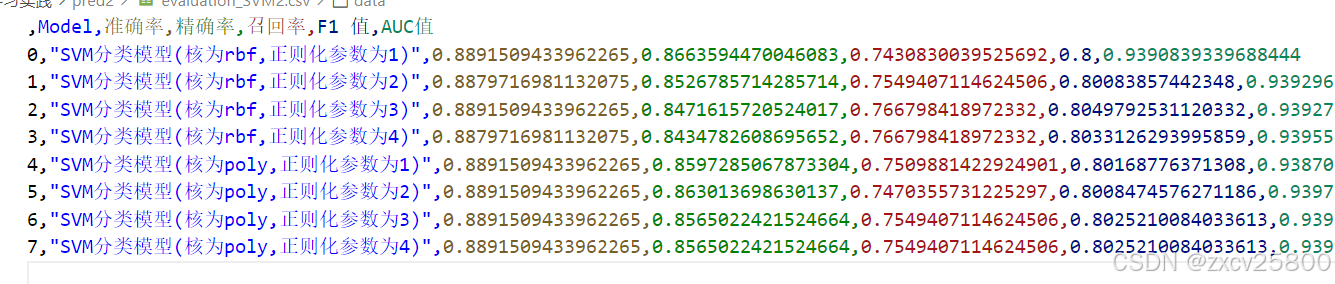
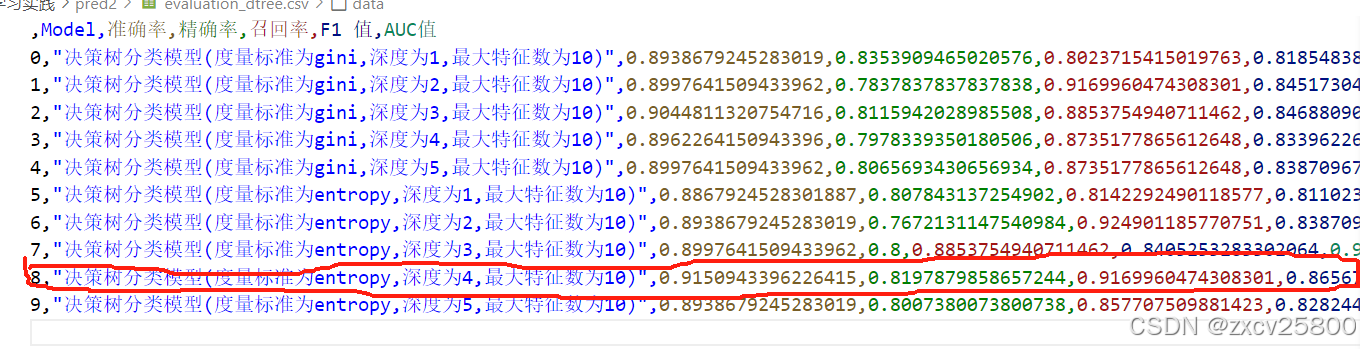

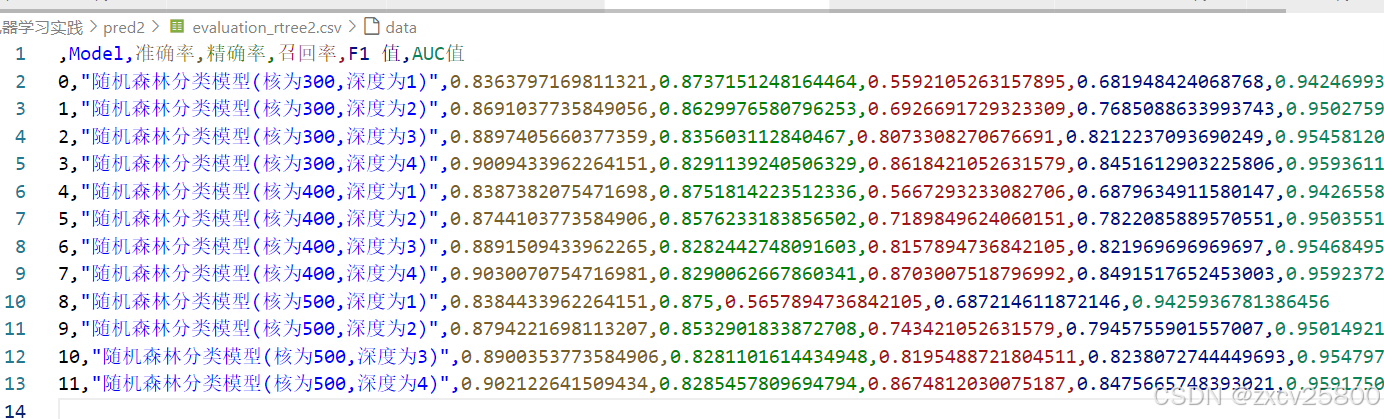
所以如图所示,决策树分类模型(度量标准为entropy,深度为4)是最优的
小结
这是小编第一次编写文章,也是在便敲写代码,边听课学习,代码看起来比较长也比较冗余,这是因为我的实力还不够,没法简写,大家尽可能可以跑一跑代码,亲自试一试,会有不一样的感受的。
如果有机会我也会上传一下我所写的预测模型前端,可以对高血压风险有进一步的预测。
欢迎大家留言交流,大家可以一起进步。
希望文章对大家有帮助!!!

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









