






一,提出数据需求
首先要把数据需求提出来,先落地成一个标准的文档。数据需求是由业务或者产品去做,然后设计数据采集方案是基于我们的数据需求,首先要满足数据需求,其次在数据在设计完成之后要进行评审。/基于需求设计完成之后需要跟业务以及技术进行技术评审,去沟通是不是能满足业务需求,然后技术这边要去沟通是不是可实现的,或者实现代码是否过大,也要去做一些权衡。
关于需求的常见误区
(1)全都要埋(就是不管我看不看,全埋)
- 埋点范围不清晰,研发人员无从下手
- 研发资源有限,无法对全局进行细致埋点
(2)全都会看(就是每个指标我都设计出来,但是后期会不会看,后期会不会看其实并不是这个指标我们要不要设计,这个指标设计出来也会有优先级,就像本次梳理优先级一样,我们指标并不是所有的指标都会去看,所以在设置和配置这个指标的时候要去考虑优先级和必要性)
- 没有明确分析目标,看数时思路混乱
- 业务人员精力有限,无法每日消化大量数据
(3)全都得用(就是数据都拿出来了,是否符合我们当前的场景)
- 汇报时失去重点,难以得出分析结论
- 管理人员时间有限,无法快速获取信息
合理需求的三要素
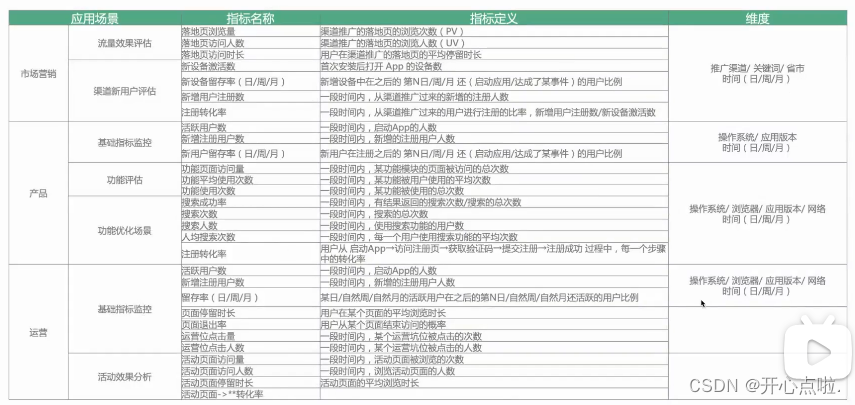
(1)应用场景:首先我们要基于场景,就是非常重要的场景我们一定要看
(2)指标:场景那么基于场景后我们需要将指标落地,比如这个地方我要看转化
(3)维度:指标的话还有一些细分的维度,比如课程,会有一些偏好。维度会直接关系到埋点老师的工作量,因为维度落地下来全都是事件的属性。
所以以上三点就是考虑要不要实现以及要不要转化成代码的一个主要的考量

需求梳理步骤
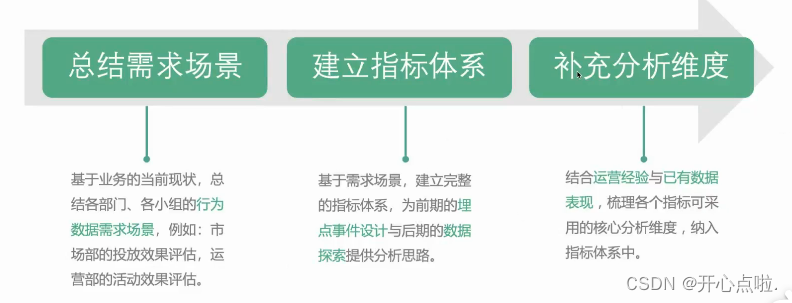
完善需求文档
二,设计数据采集方案
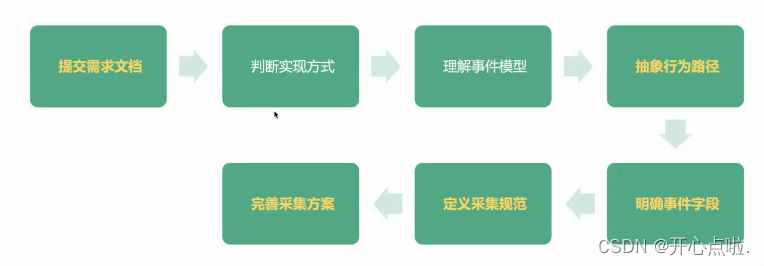
(1)提交需求文档:落地出来需求指标,那就是这个需求文档
(2)判断实现方式:判断是全埋点还是自定义才可以实现的,或者说是一些东西要去做公共属性,比如说区分,这个东西是从小程序还是app来的,这个是实现方式的基本判断。
(3)理解事件模型:理解神策底层的事件模型因为我们所有事件设计的话都是基于某个模型设计出来的,然后这个才是一个符合规范的事件,这样的话才可以正常的入库。
(4)抽象行为路径:比如一个关键的场景下可能分为1234,我们需要把这几部分抽象出来,然后做为事件,比如这块一个点击,那块一个浏览,那就是第一步点击,第二步浏览。
(5)明确事件的字段:字段其实就是刚刚提到的维度,明确事件字段的话就是比如刚刚有一个按钮点击的事件,那么这个按钮点击有那些必要采的属性,比如按钮名称,按钮当前所在的页面需要采,这就是一些事件字段。
(6)定义采取规范:采集规范就是我们最后落地下来的埋点文档,就是某一个事件对应的属性,属性类型的规范,最重要的是触发时机的规范。
(7)完善采集方案:这块是基于评审的基础上去完善,比如评估这个地方不好实现,那么这个属性可能就采不了了,那我们就要去掉或者是换成其他的采集了。
以上则是步骤。
提交需求文档
eg:希望通过对登录注册流程的各节点进行数据分析,优化用户登录,提高 用户体验
首先第一步我们要提供以下文档,比如说之后我们产品迭代的时候可能就是某一个功能点的一些指标,比如新增一个登录注册的一个方式,要去看用这个功能的人数,人数占比等。
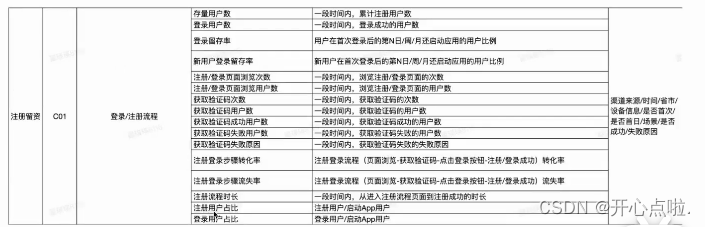
判断实现方式
用户关联(确认用户识别方式)
场景:(1)本次新线上映,所有的数据对我们的环境来说都是一个新的数据,这种就是所有的数据全部是新上的,就是全是新端的数据,就是要去判断用户关联的方式。
(2)后期迭代。比如说新增了一条产品线,之前没有的,比如我要新增另外一个APP,可能是给运营的人员使用,那这个也需要埋点的话,可能一个新端上来的话也要去识别用户关联的方式。
全域用户关联,一个用户在不同端的行为通过唯一id将其串联。使之不同端&登录前后的行为被识别为同一个用户(把不同端的数据拉起,用户登录前后,比如说用户在APP登录前是使用的安卓id标识,那么触发登录这个动作的话我们要调一个登录相关的接口,那登录之后的数据和登录之前的数据就可以实现一个绑定,就是可以把他认为是同一个人的)
全埋点(通过标准 SDK 采集客户端页面数据即传统的 PV & Session 模型)
使用全埋点为什么还要涉及采集方案呢,因为采集方案涉及的这一部分其实就是一个自定义的内容。为什么还要设计呢????因为全埋点虽然说很简单,就是SDK集成之后就直接已经有数据了,但是对于我们的,比如说产品老师,业务老师也就是看数方不够好用。
- 快速方便,用于基础指标评估
- 不够全:仅能采集普适性的数据;例如,采集的事件受限于规定的触发时机,比如button
- 不够细:不支持多维下钻分析;例如,点击的时候会默认采集元素的id,元素的名称这种,但是他有没有两说,其次的话他有一个下单的按钮,那我们相关的业务数据也是没有的,比如课程报名需要花多少钱,这个钱是没有的。那么优惠券相关的信息也是没有的。
- 不够准:核心业务数据,如订单数、交易金额等,受限于数据传输丢失,无法拿到精准数据。
自定义埋点(研发人员按照事件模型进行手动埋点)
- 支持灵活的数据采集方式,覆盖前端、后端采集及数据导入
- 事件模型可以采集更多的自定义行为与维度
- 数据采集更为准确
- 实施流程较长、成本较高
理解事件模型

事件模型包含事件(Event)和用户(User)两个核心实体,即只有事件表 和用户表两张表
抽象的话如何去抽象:
比如在用户表中,最关键的属性就是用户ID,以及一些其他属性,比如性别,开卡日期等。
事件表:历史数据,这些东西落到这里,基本就不会对此再进行修改 。
主要的几个点就是首先用户ID就是使用userID来标识用户,其次就是触发事件的名称叫什么,比如浏览这种,以及一些其他携带的属性。

抽象行为路径
抽象行为路径就是我们刚刚所提及到的。
这里举一个简单的例子:
- 用户点击活动落地页(就是有落地页曝光出来)
- 点击报名按钮
- 微信报名/下单成功
- 加v
加v有课程之后才会有以下操作
- 浏览课程详情页
- 开始播放课程
- 结束学习
明确事件字段
就是我们要去确认需要那些属性上报到这里

查看上图,就会一些章节在这里。例如我就点击第一章 考博方式。然后我们就开始上报这节课程的事件。前端的话,比如我们点击这个章节后跳转,那我们就在这个位置去上报开始学习课程。然后也会有一些维度,开始学习之后我们要去看该课程播放的人数,次数这些的时候,我们就用开始学习课程这个事件就可以了,那么我们也需要一些必要的维度去看,比如课程名称,分类,以及一些讲师的信息。

定义采集规范
每个属性所对应的数据类型我们要去定义。
开发老师上报的数据类型是什么,那么在后台的数据类型也就是什么样子的,所以说如果我们前后上报的数据类型不一致,可能就会涉及到一个类型转化的操作。类型转化失败就会导致数据的丢失
















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









