







request的get使用和post使用
开始用request的这个库,他的实现原理也是基于urllib的
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多。
Get请求
response = requests.get("http://www.baidu.com/")
* response的常用方法:
* response.text 返回解码后的字符串,解码后就是字符串了,保存直接以w保存,不用wb了
* respones.content 以字节形式(二进制)返回。保存用wb保存。(爬图片这种的就用二进制)
* text解不出来,就用二进制去解码。respones.content.decode('utf8')也可以解出字符串,
* 保存的时候也是用w保存就好,如果就是以二进制的方式,那么保存的时候用wb也能解成字符串。
*
* response.url 发起url
* response.cookie 返回得cookie
* response.status_code 响应状态码
* response.request.headers 请求的请求头
* response.headers 响应头
* response.encoding = 'utf-8' 可以设置编码类型
* response.encoding 获取当前网站的编码类型
* response.json() 内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常
添加请求头
添加请求头
import requests
kw = {'wd':'美女'}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
# params 接收一个字典或者字符串的查询参数,
# 字典类型自动转换为url编码,不需要urlencode()
response = requests.get(
"http://www.baidu.com/s?",
params = kw,
headers = headers
)
注意
- 使用response.text 时,Requests 会基于 HTTP 响应的文本编码自动解码响应内容,大多数 Unicode 字符集都能被无缝地解码,但是也会出现乱码请求。推荐使用response.content.deocde()
- 使用response.content 时,返回的是服务器响应数据的原始二进制字节流,可以用来保存图片等二进制文件。
post请求
import requests
req_url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
#分析表单数据
formdata = {
'i': '老鼠爱大米',
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION',
'typoResult': 'false',
}
#添加请求头
req_header = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
response = requests.post(
req_url,
data = formdata,
headers = req_header
)
#print (response.text)
# 如果是json文件可以直接显示
print (response.json())
Xpath的使用
什么事xpath
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
什么是xml?W3School
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
XML和 HTML 的区别
| 数据格式 | 描述 | 作用 |
|---|---|---|
| XML | 可扩展标记语言 | 用来传输和存储数据 |
| HTML | 超文本标记语言 | 用来显示数据 |
要想用xpath就得安装,pip install lxml
常见语法
| 表达式 | 含义 |
|---|---|
| / | 从根节点开始 |
| // | 从任意节点 |
| . | 从当前节点 |
| … | 从当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
常用用法
from lxml import etree
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1" id="1" ><a href="link4.html">fourth item</a></li>
<li class="item-0" data="2"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data)#构造了一个XPath解析对象。etree.HTML模块可以自动修正HTML文本。
li_list = html.xpath('//ul/li')#选取ul下面的所有li节点
#li_list = html.xpath('//div/ul/li')#选取ul下面的所有li节点
a_list = html.xpath('//ul/li/a')#选取ul下面的所有a节点
herf_list = html.xpath('//ul/li/a/@href')#选取ul下面的所有a节点的属性herf的值
text_list = html.xpath('//ul/li/a/text()')#选取ul下面的所有a节点的值
print(li_list)
print(a_list)
print(herf_list)
print(text_list)
#打印
[<Element li at 0x1015f4c48>, <Element li at 0x1015f4c08>, <Element li at 0x1015f4d08>, <Element li at 0x1015f4d48>, <Element li at 0x1015f4d88>]
[<Element a at 0x1015f4dc8>, <Element a at 0x1015f4e08>, <Element a at 0x1015f4e48>, <Element a at 0x1015f4e88>, <Element a at 0x1015f4ec8>]
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
['first item', 'second item', 'third item', 'fourth item', 'fifth item']
通配符
| 通配符 | 含义 |
|---|---|
| * | 选取任何元素节点 |
| @* | 选取任何属性的节点 |
常用用法
from lxml import etree
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1" id="1" ><a href="link4.html">fourth item</a></li>
<li class="item-0" data="2"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data)
li_list = html.xpath('//li[@class="item-0"]')#选取class为item-0的li标签
text_list = html.xpath('//li[@class="item-0"]/a/text()')#选取class为item-0的li标签 下面a标签的值
li1_list = html.xpath('//li[@id="1"]')#选取id属性为1的li标签
li2_list = html.xpath('//li[@data="2"]')#选取data属性为2的li标签
print(li_list)
print(text_list)
print(li1_list)
print(li2_list)
#打印
[<Element li at 0x101dd4cc8>, <Element li at 0x101dd4c88>]
['first item', 'fifth item']
[<Element li at 0x101dd4d88>]
[<Element li at 0x101dd4c88>]
表达式
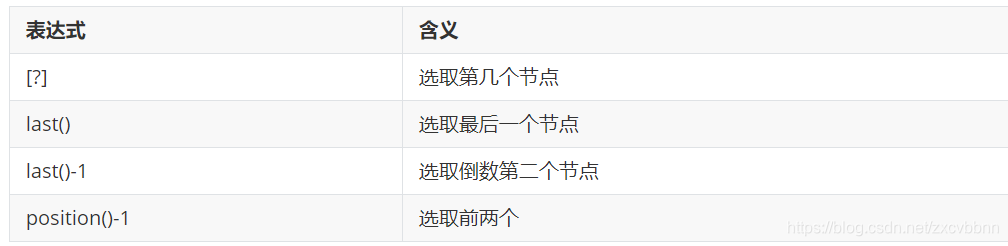
注意【】没有0,下标就是以1开始的
常见用法
from lxml import etree
data = jiayuan
html = etree.HTML(data)
li_list = html.xpath('//ul/li[1]') # 选取ul下面的第一个li节点
li1_list = html.xpath('//ul/li[last()]') # 选取ul下面的最后一个li节点
li2_list = html.xpath('//ul/li[last()-1]') # 选取ul下面的最后一个li节点
li3_list = html.xpath('//ul/li[position()<= 3]') # 选取ul下面前3个标签
text_list = html.xpath('//ul/li[position()<= 3]/a/@href') # 选取ul下面前3个标签的里面的a标签里面的href的值
print(li_list)
print(li1_list)
print(li2_list)
print(li3_list)
print(text_list)
#打印
[<Element li at 0x1015d3cc8>]
[<Element li at 0x1015d3c88>]
[<Element li at 0x1015d3d88>]
[<Element li at 0x1015d3cc8>, <Element li at 0x1015d3dc8>, <Element li at 0x1015d3e08>]
['link1.html', 'link2.html', 'link3.html']
函数
| 函数名 | 含义 |
|---|---|
| starts-with | 选取以什么开头的元素 |
| contains | 选取包含一些信息的元素 |
| and | 并且的关系 |
| or | 或者的关系 |
常见用法
from lxml import etree
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1" id="1" ><a href="link4.html">fourth item</a></li>
<li class="item-0" data="2"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data)
li_list = html.xpath('//li[starts-with(@class,"item-1")]')#获取class包含以item-1开头的li标签
li1_list = html.xpath('//li[contains(@class,"item-1")]')#获取class包含item的li标签
li2_list = html.xpath('//li[contains(@class,"item-0") and contains(@data,"2")]')#获取class为item-0并且data为2的li标签
li3_list = html.xpath('//li[contains(@class,"item-1") or contains(@data,"2")]')#获取class为item-1或者data为2的li标签
print(li_list)
print(li1_list)
print(li2_list)
print(li3_list)
#打印
[<Element li at 0x101dcac08>, <Element li at 0x101dcabc8>]
[<Element li at 0x101dcac08>, <Element li at 0x101dcabc8>]
[<Element li at 0x101dcacc8>]
[<Element li at 0x101dcac08>, <Element li at 0x101dcabc8>, <Element li at 0x101dcacc8>]
插件
- Chrome插件 XPath Helper
- Firefox插件 XPath Checker














 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









