






最近在进行机器学习的时候重新复习了一遍大学阶段学习过的一个算法,大名鼎鼎的K-Means算法,作为机器学习的一个入门级算法,在重新复习完之后,我又有了新的理解与感悟。
先说我自己得出来的结论:
K-Means算法本质上就是:增加同类内元素的相似性,减少不同类之间的相似性,关键是对K值的选择
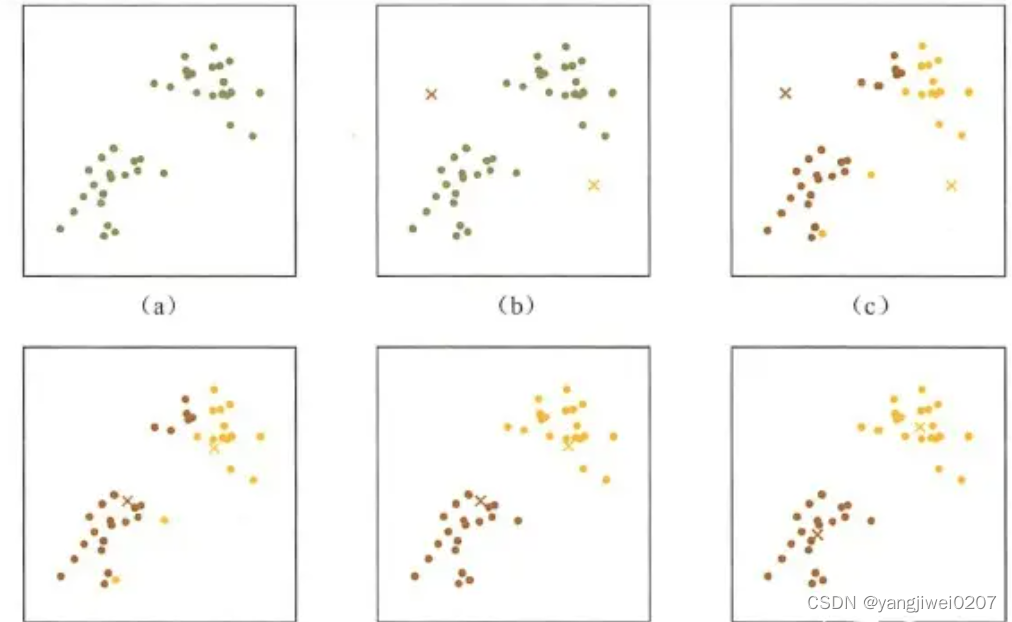
在上图给出的示例中:【欧式距离】
a 是原始数据
b 是随机划分的两个K值
c 是基于两个k值分类,分类标准是到该类的欧氏距离最小
d 是基于上一步分好的类,在各自的类中计算 使用均值法求解各个点的欧氏距离最小的点 确定中心点
e 是以 在上一步确定好的中心点的基础上,重复 c
f 是重复d
当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
我在给出一个动态的图来帮助理解

在我最近做的一个用户互动参与画像的分析中,我便使用到了K-Means算法来对用户的价值进行分类, 来判断该用户的价值高低以便后续针对性的对其精力的投放。
在 R(regular)/F(frequence)/E(engage) 的模型上进行K-Means的使用,即基于以往用户的 频率、周期、参与程度进行预测,给该用户打上价值标签
该项目是使用spark来完成的,首先是将数据读取进来
rfe_score_df = rfe_df.select('userId', recency_score, frequency_score, engagement_score)
rfe_score_df.show()
+------+-------+---------+----------+ |userId|recency|frequency|engagement| +------+-------+---------+----------+ | 296| 2| 5| 1| | 467| 2| 5| 3|
使用VectorAssembler将R/F/E三个维度合并到一块
vec_assembler = VectorAssembler(inputCols=['recency', 'frequency', 'engagement'], outputCol='features')
vec_df = vec_assembler.transform(rfe_score_df)
vec_df.show()
+------+-------+---------+----------+-------------+ |userId|recency|frequency|engagement| features| +------+-------+---------+----------+-------------+ | 296| 2| 5| 1|[2.0,5.0,1.0]| | 467| 2| 5| 3|[2.0,5.0,3.0]| | 675| 2| 5| 2|[2.0,5.0,2.0]|
开始进行KMeans聚类算法训练模型
kmeans = KMeans(k=4, featuresCol='features', predictionCol='prediction')
kmeans_model: KMeansModel = kmeans.fit(vec_df)
kmeans_result_df = kmeans_model.transform(vec_df)
kmeans_result_df.show()+------+-------+---------+----------+-------------+----------+ |userId|recency|frequency|engagement| features|prediction| +------+-------+---------+----------+-------------+----------+ | 296| 2| 5| 1|[2.0,5.0,1.0]| 3| | 467| 2| 5| 3|[2.0,5.0,3.0]| 0| | 675| 2| 5| 2|[2.0,5.0,2.0]| 2|
获取每类的聚类中心点 R/F/E 的均值 centers_list = kmeans_model.clusterCenters()聚类中心点求和 R/F/E求和,求和是为了接下来确定 均值欧氏距离最小的点,从而确定中心点centers_sum_list = [np.sum(x) for x in centers_list]聚类中心点求和后进行降序排序,目的是为了进行价值度的匹配clusters_index_dict = {} for i in range(len(centers_sum_list)): clusters_index_dict[i] = centers_sum_list[i] ordered_result_dict = dict(sorted(clusters_index_dict.items(), key=lambda x: x[1], reverse=True))降序排序的结果和5级标签对应, 打上对应的标签five_id_list = five_df.rdd.map(lambda x: x.id).collect() index_id_dict = dict(zip(ordered_result_dict.keys(), five_id_list))打上标签 @F.udf def clusterId_to_tagsId(prediction): return index_id_dict[prediction]由于总共就分 4 类,因此 prediction 总能取值就是【0,1,2,3】这四个,在预测的记过中 select 出 userId和prediction,将 prediction 传入 clusterId_to_tagsId 中进行标记,从而对每一个 userID 进行了标记result_df = kmeans_result_df.select('userId', clusterId_to_tagsId('prediction').alias('tagsId')) result_df.show()此处只展示了两行数据
+------+------+ |userId|tagsId| +------+------+ | 296| 50| | 467| 48|
到此位置对所有用户进行了预测并打上了价值标签,实现了K-Means算法的应用
















 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











