






之前使用DataX来实现数据的同步,只是将数据送到了指定的位置,但是并没有分区处理,这样当数据多了的时候就不是可以很方便的管理数据了,因此,可以增设一个分区来对数据进行处理。
1、我们可以先创建一个hive数据表,在建表时侯增加一个用来标记日期的字段用于分区,和MySQL的数据表的结构是相同的,以我的为例:
create table tbl_logs
(
id bigint,
log_id string,
remote_ip string,
site_global_ticket string,
site_global_session string,
global_user_id string,
cookie_text string,
user_agent string,
ref_url string,
loc_url string,
log_time string
)
partitioned by (today string)
row format delimited
fields terminated by '\t'
;
2、接下来就是进行json文件的配置了,跟我上一篇的配置大同小异,但是在路径中稍有变动
json文件配置:
http://t.csdnimg.cn/yyva2![]() http://t.csdnimg.cn/yyva2
http://t.csdnimg.cn/yyva2 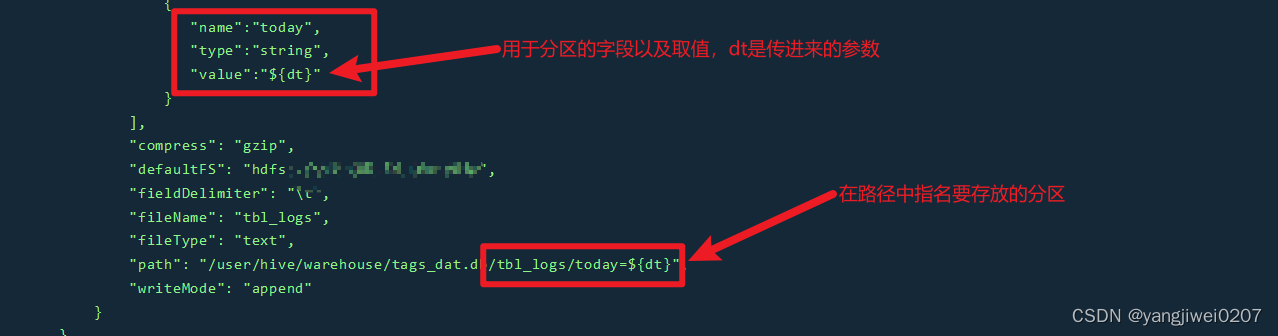
3、这里有一个坑,就是你在指明分区路径的时候,这时候分区是已经存在了的,不然DataX就会报错没有这个路径,可以自己先创建分区,由于是按照每日新增数据来进行分区管理的,因此这里可以手动创建分区
alter table tbl_logs add partition (today='2024-02-18')
 这个时候在使用DataX的时候就不会再报错了
这个时候在使用DataX的时候就不会再报错了
4、我们也可以通过shell脚本来自动的运行DataX来实现数据的同步,因为每天都需要处理,所以可以进行脚本定时,后面我们需要做的就只有每天手动创建一个分区而已。

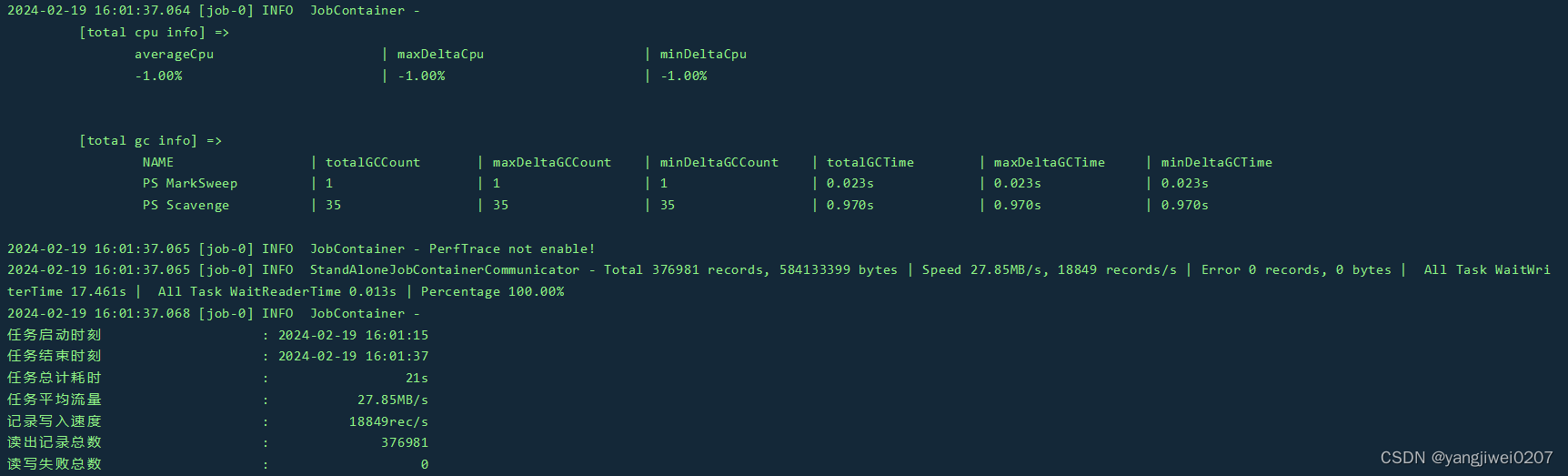
5、当成功运行了脚本之后会显示

















 7076
7076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











