









吐个槽 :在word文档中写好的 包括图片 在csdn粘贴过来后 图片必须重新上传 不爽啊!!
Flume-ng+Kafka+storm的学习笔记
Flume-ng
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html 官方的英文文档 介绍的比较全面。
不过这里写写自己的见解
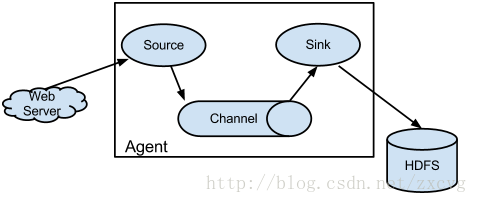
这个是flume的架构图
从上图可以看到几个名词:
Agent: 一个Agent包含Source、Channel、Sink和其他的组件。Flume就是一个或多个Agent构成的。
Source:数据源。简单的说就是agent获取数据的入口 。
Channel:管道。数据流通和存储的通道。一个source必须至少和一个channel关联。
Sink:用来接收channel传输的数据并将之传送到指定的地方。传送成功后数据从channel中删除。
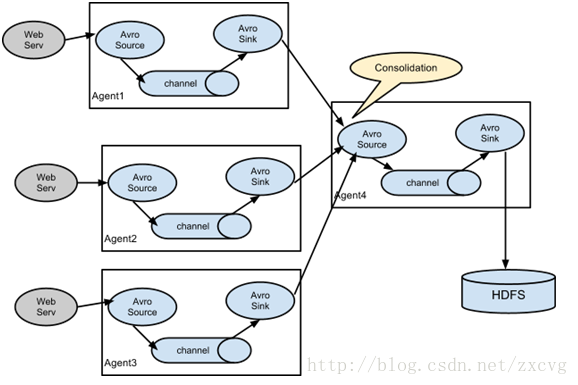
Flume具有高可扩展性 可随意组合:
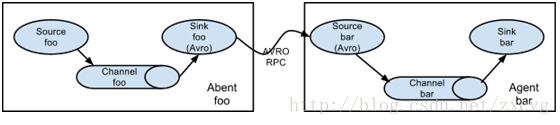
注意 source是接收源 sink是发送源
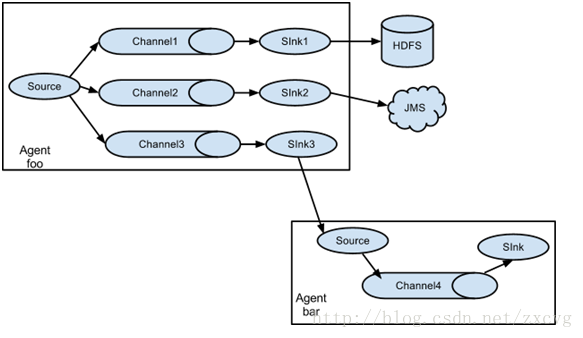
上图是一个source将数据发给3个channel 其中的sink2将数据发给JMS ,sink3将数据发给另一个source。
总的来说flume的扩展性非常高 根据需要可随意组合。
现在在说说一个概念叫Event:
Event是flume的数据传输的基本单元。Flume本质上是将数据作为一个event从源头传到结尾。是由可选的Headers和载有数据的一个byte array构成。
代码结构:
/**
* Basic representation of a data object inFlume.
* Provides access to data as it flows throughthe system.
*/
public interface Event{
/**
* Returns a map of name-valuepairs describing the data stored in the body.
*/
public Map<String, String> getHeaders();
/**
* Set the event headers
* @param headersMap of headers to replace the current headers.
*/
public void setHeaders(Map<String, String> headers);
/**
* Returns the raw byte array of the datacontained in this event.
*/
public byte[] getBody();
/**
* Sets the raw byte array of the datacontained in this event.
* @param body Thedata.
*/
public void setBody(byte[] body);
}这个是网上找的flume channel ,source,sink的汇总
链接是http://abloz.com/2013/02/26/flume-channel-source-sink-summary.html
|
下面介绍下kafka以及kafka和flume的整合
Kafka:
从这个链接抄了些内容下来http://dongxicheng.org/search-engine/kafka/
Kafka是Linkedin于2010年12月份开源的消息系统,它主要用于处理活跃的流式数据。活跃的流式数据在web网站应用中非常常见,这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。 这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
传统的日志分析系统提供了一种离线处理日志信息的可扩展方案,但若要进行实时处理,通常会有较大延迟。而现有的消(队列)系统能够很好的处理实时或者近似实时的应用,但未处理的数据通常不会写到磁盘上,这对于Hadoop之类(一小时或者一天只处理一部分数据)的离线应用而言,可能存在问题。Kafka正是为了解决以上问题而设计的,它能够很好地离线和在线应用。
2、 设计目标
(1)数据在磁盘上存取代价为O(1)。一般数据在磁盘上是使用BTree存储的,存取代价为O(lgn)。
(2)高吞吐率。即使在普通的节点上每秒钟也能处理成百上千的message。
(3)显式分布式,即所有的producer、broker和consumer都会有多个,均为分布式的。
(4)支持数据并行加载到Hadoop中。
3、 KafKa部署结构
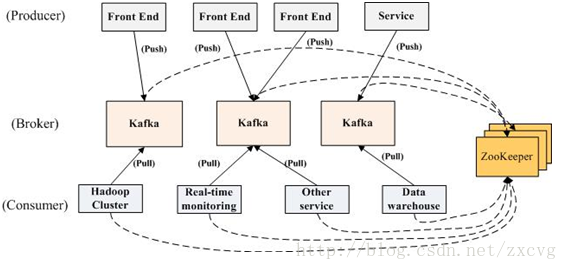
kafka是显式分布式架构,producer、broker(Kafka)和consumer都可以有多个。Kafka的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。几个基本概念:
(1)message(消息)是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。如果consumer订阅了这个主题,那么新发布的消息就会广播给这些consumer。
(2)Kafka是显式分布式的,多个producer、consumer和broker可以运行在一个大的集群上,作为一个逻辑整体对外提供服务。对于consumer,多个consumer可以组成一个group,这个message只能传输给某个group中的某一个consumer.
数据从producer推送到broker,接着consumer在从broker上拉取数据。Zookeeper是一个分布式服务框架 用来解决分布式应用中的数据管理问题等。
在kafka中 有几个重要概念producer生产者 consumer 消费者 topic 主题。
我们来实际开发一个简单的生产者消费者的例子。
生产者:
public classProducerTest {
public static void main(String[] args) {
Properties props = newProperties();
props.setProperty("metadata.broker.list","xx.xx.xx.xx:9092");
props.setProperty("serializer.class","kafka.serializer.StringEncoder");
props.put("request.required.acks","1");
ProducerConfigconfig = new ProducerConfig(props);
Producer<String, String> producer = newProducer<String, String>(config);
KeyedMessage<String, String> data = newKeyedMessage<String, String>("kafka","test-kafka");
try {
producer.send(data);
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
}
}上面的代码中的xx.xx.xx.xx是kafka server的地址.
上面代码的意思就是向主题 kafka中同步(不配置的话 默认是同步发射)发送了一个信息 是test-kafka.
下面来看看消费者:
public classConsumerTest extends Thread {
private finalConsumerConnector consumer;
private final String topic;
public static voidmain(String[] args) {
ConsumerTest consumerThread = newConsumerTest("kafka");
consumerThread.start();
}
publicConsumerTest(String topic) {
consumer =kafka.consumer.Consumer
.createJavaConsumerConnector(createConsumerConfig());
this.topic =topic;
}
private staticConsumerConfig createConsumerConfig() {
Properties props = newProperties();
props.put("zookeeper.connect","xx.xx.xx.xx:2181");
props.put("group.id", "0");
props.put("zookeeper.session.timeout.ms","10000");
// props.put("zookeeper.sync.time.ms", "200");
// props.put("auto.commit.interval.ms", "1000");
return newConsumerConfig(props);
}
public void run(){
Map<String,Integer> topickMap = new HashMap<String, Integer>();
topickMap.put(topic, 1);
Map<String, List<KafkaStream<byte[],byte[]>>> streamMap =consumer.createMessageStreams(topickMap);
KafkaStream<byte[],byte[]>stream = streamMap.get(topic).get(0);
ConsumerIterator<byte[],byte[]> it =stream.iterator();
System.out.println("--------------------------");
while(it.hasNext()){
//
System.out.println("(consumer)--> " +new String(it.next().message()));
}
}
}上面的代码就是负责接收生产者发送过来的消息 测试的时候先开启消费者 然后再运行生产者即可看到效果。
接下来 我们将flume 和kafka进行整合:
在flume的source数据源接收到数据后 通过管道 到达sink,我们需要写一个kafkaSink 来将sink从channel接收的数据作为kafka的生产者 将数据 发送给消费者。
具体代码:
public class KafkaSink extends AbstractSinkimplementsConfigurable {
private static final Log logger = LogFactory.getLog(KafkaSink.class);
private Stringtopic;
private Producer<String, String>producer;
@Override
public Status process()throwsEventDeliveryException {
Channel channel =getChannel();
Transaction tx =channel.getTransaction();
try {
tx.begin();
Event e = channel.take();
if(e ==null) {
tx.rollback();
return Status.BACKOFF;
}
KeyedMessage<String,String> data = new KeyedMessage<String, String>(topic,newString(e.getBody()));
producer.send(data);
logger.info("Message: {}"+new String( e.getBody()));
tx.commit();
return Status.READY;
} catch(Exceptione) {
logger.error("KafkaSinkException:{}",e);
tx.rollback();
return Status.BACKOFF;
} finally {
tx.close();
}
}
@Override
public void configure(Context context) {
topic = "kafka";
Properties props = newProperties();
props.setProperty("metadata.broker.list","xx.xx.xx.xx:9092");
props.setProperty("serializer.class","kafka.serializer.StringEncoder");
// props.setProperty("producer.type", "async");
// props.setProperty("batch.num.messages", "1");
props.put("request.required.acks","1");
ProducerConfigconfig = new ProducerConfig(props);
producer = newProducer<String, String>(config);
}
}
将此文件打成jar包 传到flume的lib下面 如果你也用的是maven的话 需要用到assembly 将依赖的jar包一起打包进去。
在flume的配置是如下:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels =channel1
# Describe/configuresource1
agent1.sources.source1.type= avro
agent1.sources.source1.bind= localhost
agent1.sources.source1.port= 44444
# Describe sink1
agent1.sinks.sink1.type= xx.xx.xx.KafkaSink(这是类的路径地址)
# Use a channel whichbuffers events in memory
agent1.channels.channel1.type= memory
agent1.channels.channel1.capacity= 1000
agent1.channels.channel1.transactionCapactiy= 100
# Bind the source andsink to the channel
agent1.sources.source1.channels= channel1
agent1.sinks.sink1.channel= channel1
测试的话是avro的方式传送数据的 可以这样测试
bin/flume-ng avro-client--conf conf -H localhost -p 44444 -F/data/flumetmp/a
/data/flumetmp/a 这个为文件的地址.
测试的时候在本地 一定要把上面写的消费者程序打开 以便接收数据测试是否成功。
接下来我们介绍下storm然后将kafka的消费者和storm进行整合:
Storm:
Storm是一个分布式的实时消息处理系统。
Storm各个组件之间的关系:
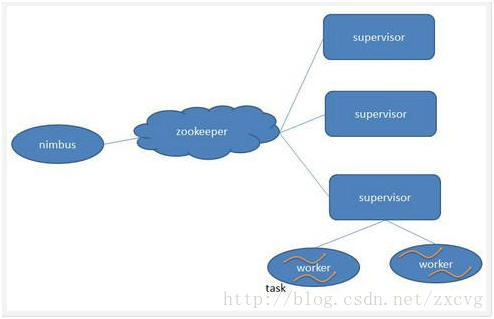
Storm集群主要由一个主节点和一群工作节点(worker node)组成,通过 Zookeeper进行协调。
主节点:主节点通常运行一个后台程序 —— Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。
工作节点: Supervisor,负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。Nimbus和Supervisor之间的协调由zookeeper完成。
Worker:处理逻辑的进程,在其中运行着多个Task,每个task 是一组spout/blots的组合。
Topology:是storm的实时应用程序,从启动开始一直运行,只要有tuple过来 就会触发执行。拓扑:storm的消息流动很像一个拓扑结构。
2. stream是storm的核心概念,一个stream是一个持续的tuple序列,这些tuple被以分布式并行的方式创建和处理。
3. spouts是一个stream的源头,spouts负责从外部系统读取数据,并组装成tuple发射出去,tuple被发射后就开始再topology中传播。
4. bolt是storm中处理 数据的核心,storm中所有的数据处理都是在bolt中完成的
这里就简单介绍一些概念 具体的可以看些详细的教程。
我们接下来开始整合storm和kafka。
从上面的介绍得知storm的spout是负责从外部读取数据的 所以我们需要开发一个KafkaSpout 来作为kafka的消费者和storm的数据接收源。可以看看这个https://github.com/HolmesNL/kafka-spout。我在下面只写一个简单的可供测试。
具体代码:
public class KafkaSpout implements IRichSpout {
private static final Log logger = LogFactory.getLog(KafkaSpout.class);
/**
*
*/
private static final long serialVersionUID = -5569857211173547938L;
SpoutOutputCollector collector;
private ConsumerConnectorconsumer;
private Stringtopic;
public KafkaSpout(String topic) {
this.topic = topic;
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
}
private static ConsumerConfig createConsumerConfig() {
Properties props = newProperties();
props.put("zookeeper.connect","xx.xx.xx.xx:2181");
props.put("group.id","0");
props.put("zookeeper.session.timeout.ms","10000");
//props.put("zookeeper.sync.time.ms", "200");
//props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void close() {
// TODOAuto-generated method stub
}
@Override
public void activate() {
this.consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, Integer> topickMap = newHashMap<String, Integer>();
topickMap.put(topic,new Integer(1));
Map<String, List<KafkaStream<byte[],byte[]>>>streamMap =consumer.createMessageStreams(topickMap);
KafkaStream<byte[],byte[]>stream = streamMap.get(topic).get(0);
ConsumerIterator<byte[],byte[]> it =stream.iterator();
while (it.hasNext()) {
String value = newString(it.next().message());
System.out.println("(consumer)-->" + value);
collector.emit(new Values(value), value);
}
}
@Override
public void deactivate() {
// TODOAuto-generated method stub
}
private boolean isComplete;
@Override
public void nextTuple() {
}
@Override
public void ack(Object msgId) {
// TODOAuto-generated method stub
}
@Override
public void fail(Object msgId) {
// TODOAuto-generated method stub
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("KafkaSpout"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODOAuto-generated method stub
return null;
}
}
public class FileBlots implementsIRichBolt{
OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getString(0);
for(String str : line.split("\\s+")){
List a = newArrayList();
a.add(input);
this.collector.emit(a,newValues(str));
}
this.collector.ack(input);
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("words"));
}
public Map<String, Object> getComponentConfiguration() {
// TODOAuto-generated method stub
return null;
}
}
public class WordsCounterBlots implementsIRichBolt{
OutputCollector collector;
Map<String, Integer> counter;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
this.counter =new HashMap<String, Integer>();
}
public void execute(Tuple input) {
String word = input.getString(0);
Integer integer = this.counter.get(word);
if(integer !=null){
integer +=1;
this.counter.put(word, integer);
}else{
this.counter.put(word, 1);
}
System.out.println("execute");
Jedis jedis = JedisUtils.getJedis();
jedis.incrBy(word, 1);
System.out.println("=============================================");
this.collector.ack(input);
}
public void cleanup() {
for(Entry<String, Integer> entry :this.counter.entrySet()){
System.out.println("------:"+entry.getKey()+"=="+entry.getValue());
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
public Map<String, Object> getComponentConfiguration() {
// TODOAuto-generated method stub
return null;
}
}Topology测试:
public class KafkaTopology {
public static void main(String[] args) {
try {
JedisUtils.initialPool("xx.xx.xx.xx", 6379);
} catch (Exception e) {
e.printStackTrace();
}
TopologyBuilder builder = newTopologyBuilder(); builder.setSpout("kafka",new KafkaSpout("kafka"));
builder.setBolt("file-blots",new FileBlots()).shuffleGrouping("kafka");
builder.setBolt("words-counter",new WordsCounterBlots(),2).fieldsGrouping("file-blots",new Fields("words"));
Config config = new Config();
config.setDebug(true);
LocalCluster local = newLocalCluster();
local.submitTopology("counter", config, builder.createTopology());
}
}
至此flume + kafka+storm的整合就写完了。注意 这个是 初始学习阶段做的测试 不可正式用于线上环境,在写本文之时 已经离测试过去了一段时间 所以可能会有些错误 请见谅。
















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











