







聚类分析kmeans
#数据格式
# -- coding: utf-8 --**
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram,linkage
import xlrd as xr
import pandas as pd
from sklearn import preprocessing
from sklearn.cluster import AgglomerativeClustering
from sklearn.cluster import KMeans
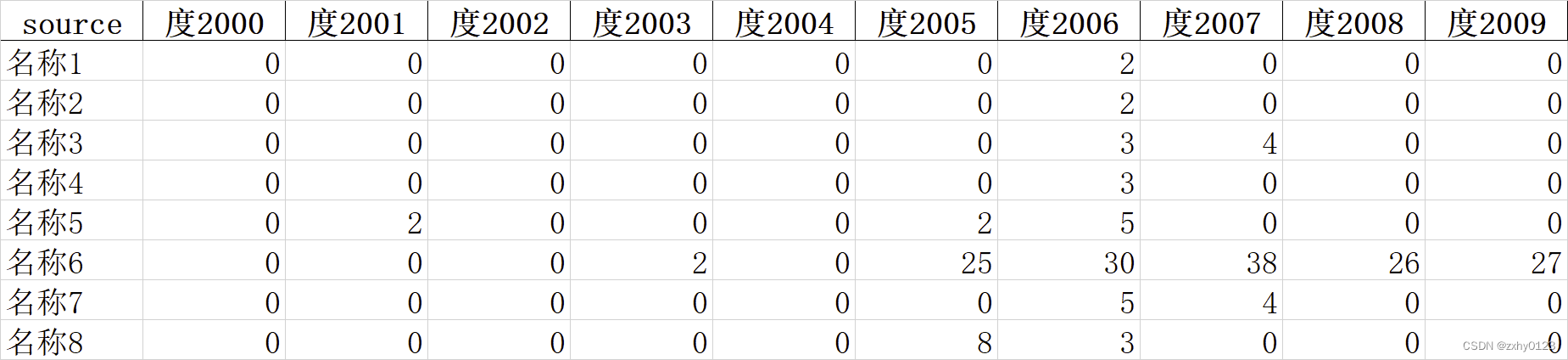
data23=pd.read_excel('历年节点度指标合并.xlsx',sheet_name='节点度指标',index_col='source')
row23=data23.iloc[:,0].size
# 设置为4个聚类中心
Kmeans = KMeans(n_clusters=4)
# 训练模型
Kmeans.fit(data23)
#获取聚类中心
Kmeans.cluster_centers_
#获取类别
leibie=Kmeans.labels_
# print(leibie)
leibie=pd.DataFrame(leibie)
leibie= leibie.rename(columns={0:'聚类类别'})
# print(leibie)
writer = pd.ExcelWriter('聚类类别.xlsx', engine='xlsxwriter',options={'strings_to_urls': False})
leibie.to_excel(writer, "聚类类别", index=False)
writer.save()
# print(len(leibie))
# #获取每个点到聚类中心的距离和
# Kmeans.inertia_
#插入数据
data23=pd.read_excel('历年节点度指标合并.xlsx',sheet_name='节点度指标')
leibie=pd.read_excel('聚类类别.xlsx',sheet_name='聚类类别')
row2=leibie.iloc[:,0].size
data23['聚类类别']=''
for i in range(row2):
data23.iloc[i,23]=leibie.iloc[i,0]
writer = pd.ExcelWriter('历年节点度指标聚类分析.xlsx', engine='xlsxwriter',options={'strings_to_urls': False})
data23.to_excel(writer, "节点度指标", index=False)
writer.save()















 1567
1567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









