






2014年7月29日 buddy分配算法
内核需要为分配一组连续的页框提供一种健壮、高效的分配策略。分配连续的页框必须解决内存管理中的外碎片(external fragmentation)。频繁的请求和释放不同大小的一组连续页框,必然导致分配页框的块分算来许多小块的空闲页框无法被一次性大量分配使用。
linux内核采用著名的伙伴系统算法来解决外碎片问题。该算法的核心思想是把所有的空闲页框分成11个链块表。每个链块表的大小分别为1,2,4,8,16,32,64,128,256,512和1024个连续的页框。
每个块b可以被分成两块b1和b2,假设b1的索引为bi1,b2的索引为bi2,并且由于是块内页框是连续的,则可以对bi1进行与(1<<order(2^order为b块的页框数))异或操作得到bi2,bi2也可以通过相同的方式得到bi1。
每个块的第一个页框物理地址应该是该块大小的整数倍。例如大小为16个页框的块,其起始地址应该为16*2^12(2^12为一个页框大小,4K)的倍数。假设要请求256个页框的块,算法先在256个页框的链表中检查是否有一个空闲块。如果没有,查找下一个更大的页框,也就是512个页框的链表。如果在512个页框的链表里存在这样的块,就把512个页框的块等分成两分,一份用于满足请求,一份插入到256个页框的链表中。如果在512个页框的链表里没有这样的块,就在1024个页框的链表中找。如果1024个页框的链表中有这样的块,就把1024个页框的256个页用于满足请求,把剩余的768个页框中的512个页框块放到大小为512个页框的链表中,并把剩余的256个页框块放入到256个页框的链表中。如果1024个页框的链表里也没有这样的块,分配失败,返回NULL。 在释放的时候通过把页框的索引进行异或操作得到伙伴的索引,通过将伙伴从它目前所在的链表中删除掉达到和伙伴合并的效果。
2014年8月31日 slab分配器
伙伴系统因为是按页框为单位来分配内存所,以只适合大块内存的分配,并且每次调用伙伴系统来分配内存都会刷新硬件高速缓存,内核函数对高速缓存的影响被称为函数足迹(footprint),被定义为函数退出时写高速缓存的百分比,所以要尽量少使用伙伴系统。内核里面对小内存(十几字节,几百字节)的需求是非常多的,内核采用了称为slab分配器的策略。slab分配器把内存区看作一个对象,这些对象由一组数据结构和几个叫做构造函数和析构函数组成。
由于很多对象(如filp,task_struct)分配使用并且释放后没有必要马上释放,因为创建和销毁的开销很大,slab分配器把对象统一放进高速缓存里来管理,每个高速缓存都是对一种对象的‘储备’,每个高速缓存由多个slab组成,为了进一步减少slab内部内存碎片,每个高速缓存还把slab分成三类:
1.free:这个slab里面都是空闲对象
2.partial:slab里面由部分空闲对象
3.full:slab里面的对象全部被使用了
先来看下高速缓存描述符的结构:
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];//本地高速缓存,每个cpu使用一个array_cache对象,每个对象都指向某cpu可使用的空闲对象池,大部分空闲对象都从从这里获得
unsigned int batchcount;//每次往本地高速缓存里填充和清空空闲对象的数量
unsigned int limit;//本地高速缓存里面分配对象的数量
unsigned int shared;
unsigned int buffer_size;//对象大小包括填充(padding)
/* 2) touched by every alloc & free from the backend */
struct kmem_list3 *nodelists[MAX_NUMNODES];//存放各种类型(full,partial,free)slab链表的对象
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */ //在每个slab中的对象最大数量
spinlock_t spinlock; //保护这个高速缓存对象的自旋锁
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder; // order of pgs per slab (2^n)
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags; //调用伙伴分配算法时使用的flags
size_t colour; /* cache colouring range */ //slab使用的颜色种类个数
unsigned int colour_off; /* colour offset */ //slab中的基本对齐便宜
struct kmem_cache *slabp_cache; //
unsigned int slab_size; //单个slab的大小
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor) (void *, struct kmem_cache *, unsigned long);
/* de-constructor func */
void (*dtor) (void *, struct kmem_cache *, unsigned long);
/* 4) cache creation/removal */
const char *name;
struct list_head next;//系统中所有的高速缓存通过这个链起来
};借用下http://blog.csdn.net/yunsongice/article/details/5272715这篇文章的图:
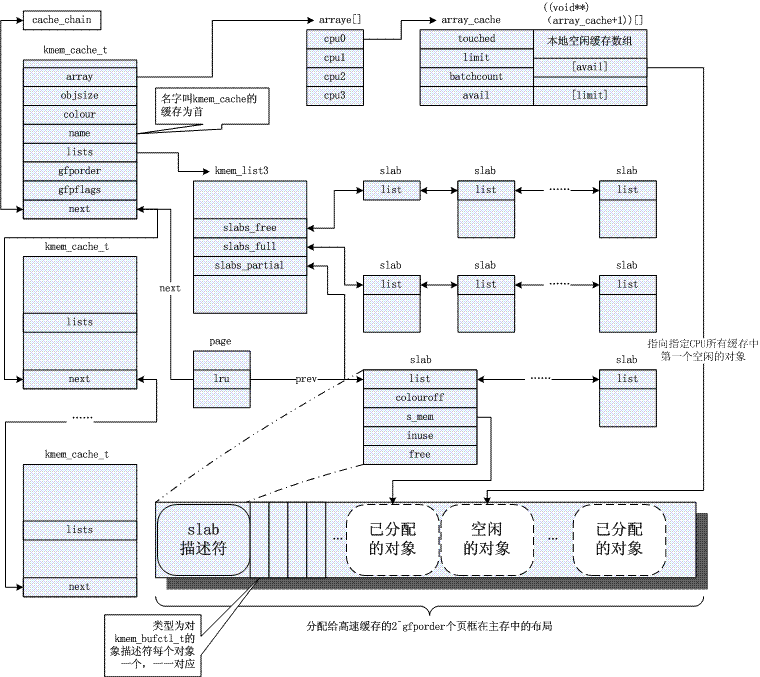
内核首先定义了一个名叫cache_cache的kmem_cache_t对象,主要用来分配kmem_cache_t对象,也就是缓存的缓存。
/* internal cache of cache description objs */
static struct kmem_cache cache_cache = {
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.shared = 1,
.buffer_size = sizeof(struct kmem_cache),
.flags = SLAB_NO_REAP,
.spinlock = SPIN_LOCK_UNLOCKED,
.name = "kmem_cache",
#if DEBUG
.obj_size = sizeof(struct kmem_cache),
#endif
};并把cache_cache作为cache_chain的第一个对象。
创建和销毁高速缓存时可以调用kmem_cache_create和kmem_cache_destroy函数。
/**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
* @dtor: A destructor for the objects.
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a int, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache
* and the @dtor is run before the pages are handed back.
*
* @name must be valid until the cache is destroyed. This implies that
* the module calling this has to destroy the cache before getting
* unloaded.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_NO_REAP - Don't automatically reap this cache when we're under
* memory pressure.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void*, struct kmem_cache *, unsigned long),
void (*dtor)(void*, struct kmem_cache *, unsigned long))
{
size_t left_over, slab_size, ralign;
struct kmem_cache *cachep = NULL;
struct list_head *p;
.....sanity检查..
/*
* Prevent CPUs from coming and going.
* lock_cpu_hotplug() nests outside cache_chain_mutex
*/
lock_cpu_hotplug();
//获取cache_chain的互斥对象
mutex_lock(&cache_chain_mutex);
//遍历系统里所有的高速缓存
list_for_each(p, &cache_chain) {
struct kmem_cache *pc = list_entry(p, struct kmem_cache, next);
mm_segment_t old_fs = get_fs();
char tmp;
int res;
/*
* This happens when the module gets unloaded and doesn't
* destroy its slab cache and no-one else reuses the vmalloc
* area of the module. Print a warning.
*/
set_fs(KERNEL_DS);
res = __get_user(tmp, pc->name);
set_fs(old_fs);
if (res) {
printk("SLAB: cache with size %d has lost its name\n",
pc->buffer_size);
continue;
}
//已经存在名为name的缓存
if (!strcmp(pc->name, name)) {
printk("kmem_cache_create: duplicate cache %s\n", name);
dump_stack();
goto oops;
}
}
...设置了debug选项的一些代码...
if (flags & SLAB_DESTROY_BY_RCU)
BUG_ON(dtor);
/*
* Always checks flags, a caller might be expecting debug
* support which isn't available.
*/
if (flags & ~CREATE_MASK)
BUG();
/* Check that size is in terms of words. This is needed to avoid
* unaligned accesses for some archs when redzoning is used, and makes
* sure any on-slab bufctl's are also correctly aligned.
*/
//让对象至少以字对齐
if (size & (BYTES_PER_WORD - 1)) {
size += (BYTES_PER_WORD - 1);
size &= ~(BYTES_PER_WORD - 1);
}
//下面的代码用于计算最终的对象对齐量
/* calculate out the final buffer alignment: */
/* 1) arch recommendation: can be overridden for debug */
if (flags & SLAB_HWCACHE_ALIGN) {
/* Default alignment: as specified by the arch code.
* Except if an object is really small, then squeeze multiple
* objects into one cacheline.
*/
ralign = cache_line_size();
while (size <= ralign / 2)
ralign /= 2;
} else {
ralign = BYTES_PER_WORD;
}
/* 2) arch mandated alignment: disables debug if necessary */
if (ralign < ARCH_SLAB_MINALIGN) {
ralign = ARCH_SLAB_MINALIGN;
if (ralign > BYTES_PER_WORD)
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
}
/* 3) caller mandated alignment: disables debug if necessary */
if (ralign < align) {
ralign = align;
if (ralign > BYTES_PER_WORD)
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
}
/* 4) Store it. Note that the debug code below can reduce
* the alignment to BYTES_PER_WORD.
*/
align = ralign;
//通过cache_cache来分配一个kmem_cache_t对象
/* Get cache's description obj. */
cachep = kmem_cache_alloc(&cache_cache, SLAB_KERNEL);
if (!cachep)
goto oops;
memset(cachep, 0, sizeof(struct kmem_cache));
...设置了debug选项的一些代码...
//如果对象比较大(大于等于一个页框的1/8),就把slab描述符放在外部的高速缓存上,否则把slab描述符放在slab上。
/* Determine if the slab management is 'on' or 'off' slab. */
if (size >= (PAGE_SIZE >> 3))
/*
* Size is large, assume best to place the slab management obj
* off-slab (should allow better packing of objs).
*/
flags |= CFLGS_OFF_SLAB;
size = ALIGN(size, align);
left_over = calculate_slab_order(cachep, size, align, flags);
if (!cachep->num) {
printk("kmem_cache_create: couldn't create cache %s.\n", name);
kmem_cache_free(&cache_cache, cachep);
cachep = NULL;
goto oops;
}
//计算slab的大小
slab_size = ALIGN(cachep->num * sizeof(kmem_bufctl_t)
+ sizeof(struct slab), align);
/*
* If the slab has been placed off-slab, and we have enough space then
* move it on-slab. This is at the expense of any extra colouring.
*/
if (flags & CFLGS_OFF_SLAB && left_over >= slab_size) {
flags &= ~CFLGS_OFF_SLAB;
left_over -= slab_size;
}
if (flags & CFLGS_OFF_SLAB) {
/* really off slab. No need for manual alignment */
slab_size =
cachep->num * sizeof(kmem_bufctl_t) + sizeof(struct slab);
}
//colour_off为硬件高速缓存行的大小
cachep->colour_off = cache_line_size();
/* Offset must be a multiple of the alignment. */
if (cachep->colour_off < align)
cachep->colour_off = align;
//colour为可以用的着色方案,剩余的空间/colour_off
cachep->colour = left_over / cachep->colour_off;
cachep->slab_size = slab_size;
cachep->flags = flags;
cachep->gfpflags = 0;
if (flags & SLAB_CACHE_DMA)
cachep->gfpflags |= GFP_DMA;
spin_lock_init(&cachep->spinlock);
cachep->buffer_size = size;
if (flags & CFLGS_OFF_SLAB)
cachep->slabp_cache = kmem_find_general_cachep(slab_size, 0u);
cachep->ctor = ctor;
cachep->dtor = dtor;
cachep->name = name;
if (g_cpucache_up == FULL) {
//初始化每cpu的本地高速缓存
enable_cpucache(cachep);
} else {
...初始化kmalloc用的本地高速缓存...
}
//加到cache_chain链表中
/* cache setup completed, link it into the list */
list_add(&cachep->next, &cache_chain);
oops:
if (!cachep && (flags & SLAB_PANIC))
panic("kmem_cache_create(): failed to create slab `%s'\n",
name);
mutex_unlock(&cache_chain_mutex);
unlock_cpu_hotplug();
return cachep;
}















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









