









在项目中看到了likely、unlikely宏的使用, 一直不是很清楚它们的作用,所以就深究下。
likely表示被测试的表达式大多数情况下为true, unlikely则表示相反。
两个宏定义:
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)这两个宏经常在条件转移的语句中使用,如if, else if等,这些语句生成的汇编代码都带有jmp指令.
-
CPU流水线的一些基本知识.
-
CPU流水线设计将一条指令的执行分成了好几个阶段,每个阶段都是独立的逻辑电路,而且每个阶段都有自己的阶段寄存器,所以各个阶段就可以实现真正的并行执行。
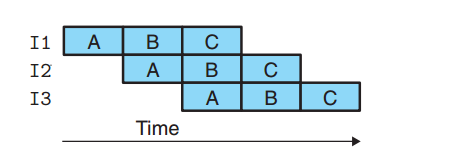
这里借用下CSAPP上的插图:
这里每条指令被分成了3个阶段, 指令I1的A阶段执行完毕后,指令I2进入了A阶段执行,而指令I1则进入B阶段执行,I1的B阶段和I2的A阶段是并行执行的。
jmp指令对流水线带来的影响
- 由于jmp指令的执行会导致CPU跳转到另一个内存地址,执行全新的指令,导致流水线里面的指令失效,所以CPU需要flush掉流水线上的寄存器,这种操作需要几个cycle来恢复流水线的执行. 这种影响被称之为hazard, 具体可以参考 hazard Wiki likely,unlikely带来的优化
-
根据gcc手册, 所以这两个宏是用来告诉编译器分支的可能走向,从而帮助CPU进行分支预测来增强CPU流水线性能的.
看下下面的代码
int main (char *argv[], int argc) { int v; v = atoi(argv[1]); if (likely(a == 5)) a++; else a--; printf("%d\n", a); return 0; }编译,带上-O2选项,得到的汇编代码:
0000000000400510 <main>: 400510: 48 83 ec 08 sub $0x8,%rsp 400514: 48 8b 7f 08 mov 0x8(%rdi),%rdi 400518: 31 c0 xor %eax,%eax 40051a: e8 f1 fe ff ff callq 400410 <atoi@plt> 40051f: 83 f8 02 cmp $0x2,%eax 400522: 75 18 jne 40053c <main+0x2c> /* likely在这里表示a很有可能是2, 所以将执行a++和printf调用放在一起, 免去了jmp带来的影响 */ 400524: be 03 00 00 00 mov $0x3,%esi 400529: bf 48 06 40 00 mov $0x400648,%edi 40052e: 31 c0 xor %eax,%eax 400530: e8 bb fe ff ff callq 4003f0 <printf@plt> 400535: 31 c0 xor %eax,%eax 400537: 48 83 c4 08 add $0x8,%rsp 40053b: c3 retq 40053c: 8d 70 ff lea -0x1(%rax),%esi 40053f: eb e8 jmp 400529 <main+0x19> /* jump到调用printf代码处, 导致cpu flush掉流水线上的内容. */ 400541: 90 nop
适用场景
-
gcc手册表示这两条指令应该在程序员对分支走向相当确定的情况下使用。不过大多数程序员还是会预测失败,所以建议经过大量profiling来确定可能性。
在linux内核代码中likely和unlikely经常被用在错误代码处理的情况, 因为错误发生的情况往往是少数的。















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









