






1. 典型开源多模态大模型
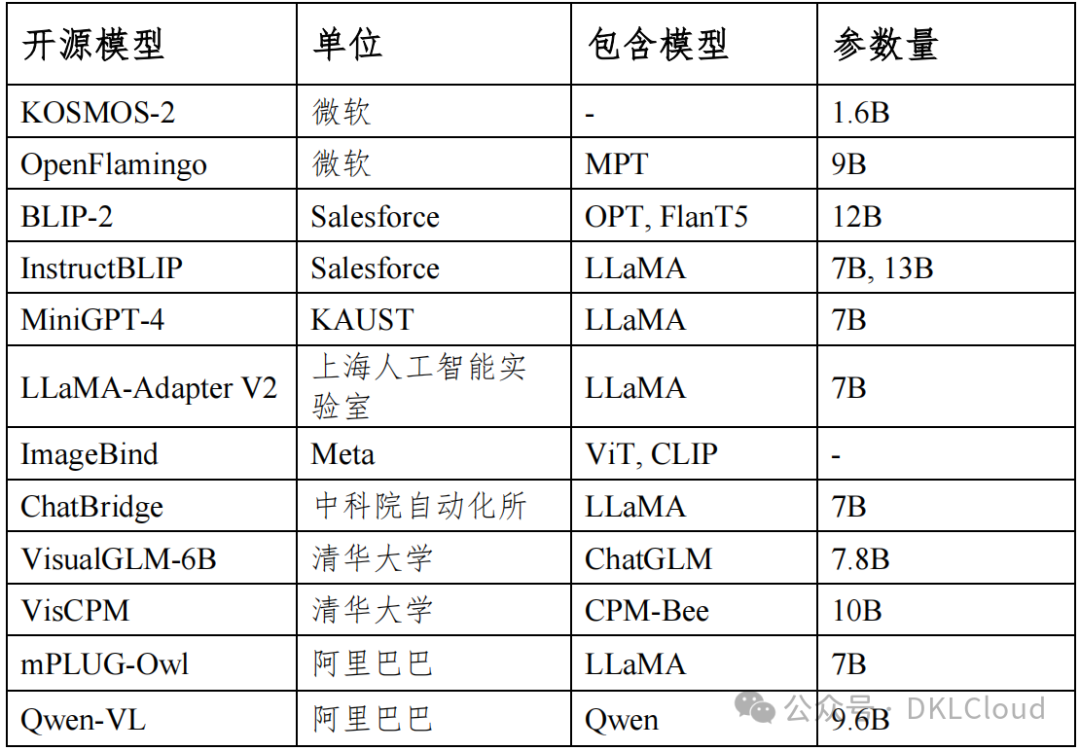
(1)KOSMOS-2
KOSMOS-2是微软亚洲研究院在 KOSMOS-1 模型的基础上开发的多模态大模型。其中,KOSMOS-1 是在大规模多模态数据集上重头训练的,该模型具有类似 GPT-4 的多模态能力,可以感知一般的感官模态,在上下文中学习(即少样本学习)并能够遵循语音指示(即零样本学习)。
KOSMOS-2 采用与 KOSMOS-1 相同的模型架构和训练目标对模型进行训练, 并在此基础上新增了对图像局部区域的理解能力。
(2)OpenFlamingo
OpenFlamingo模型是 DeepMind Flamingo 模型的开源复现版,可实现多模态大模型的训练和评估。OpenFlamingo 使用交叉注意力将一个预训练的视觉编码器和一个语言大模型结合在一起。
它是在大型多模态数据集(例如 Multimodal C4)上进行训练,可以实现以交错的图像/文本为输入来进行文本生成。例如,OpenFlamingo 可用于生成图像的标题,或者根据图像和文本段落生成问题等。这使得其能够使用上下文学习快速适应新任务。
(3)BLIP-2
BLIP-2通过一个轻量级的查询转换器弥补了模态之间的差距,该转换器分两个阶段进行预训练。
第一阶段从冻结图像编码器引导视觉语言表示学习。
第二阶段将视觉从冻结的语言模型引导到语言生成学习。BLIP-2 在各种视觉语言任务上实现了最先进的性能,尽管与现有方法相比,可训练的参数明显更少。例如,BLIP-2 模型在零样本 VQAv2 上比 Flamingo 80B 高 8.7%,可训练参数减少了 54 倍。
(4)InstructBLIP
InstructBLIP的特点是设计了一种视觉语言指令微调方法,它基于预训练的 BLIP-2 模型,对视觉语言指令进行微调。具体地,InstructBlip 复用了 BLIP-2 的结构,有一个图像编码器,一个语言大模型和一个 Q-Former 模块来连接前两者。
并且采用了指令感知的视觉特征提取过程, 指令不仅会指导语言大模型生成文本,同时也会指导图像编码器提取不同的视觉特征。
这样的好处在于对于同一张图片,根据不同的指令,可以得到基于指令偏好更强的视觉特征,同时对于两个不一样的图片,基于指令内嵌的通用知识,可以使得模型有更好的知识迁移效果。
(5)MiniGPT-4
MiniGPT-4使用语言大模型来增强视觉语言理解,将语言能力与图像能力结合。其利用视觉编码器和语言大模型 Vicuna[109]进行结合训练。具体地,MiniGPT-4 使用一个投影层来将来自 BLIP-2的冻结视觉编码器与冻结的 Vicuna 语言大模型(基于 LLaMA 指令微调得到)对齐。并通过两个阶段来训练 MiniGPT-4。第一个预训练阶段使用大约 500 万个图像-文本对进行视觉-语言对齐训练。第二个微调阶段进行多模态指令微调以提高其生成可靠性和整体可用性。MiniGPT-4 能够产生许多类似于 GPT-4 中展示的新兴视觉语言能力。
(6)LLaMA-Adapter V2
LlaMA-Adapter V2是一种参数高效的视觉指令模型。具体地,首先通过解锁更多可学习参数(例如范数、偏差和比例)来增强LlaMA Adapter,这些参数将指令遵循能力分布到整个 LLaMA 模型中。其次,采用了一种早期融合策略,将视觉标记提供给早期的语言大模型,有助于更好地整合视觉知识。
然后,通过优化不相交的可学习参数组,引入了图像-文本对和指令跟随数据的联合训练范式。该策略有效地缓解了图文对齐和指令跟随这两个任务之间的干扰,仅用小规模的图文和指令数据集就实现了强多模态推理。在推理过程中,该 模 型 将 额 外 的 专 家 模 型 ( 例 如 字 幕 /OCR 系 统 ) 合 并 到LLaMA-Adapter 中,以进一步增强其图像理解能力。
(7)ImageBind
ImageBind是 Meta 发布的模型,它的目标是利用图像为中心绑定学习一个嵌入空间,将文本、图像/视频、音频、深度(3D)、热(红外辐射)和惯性测量单元(IMU)六个模态的数据都投影到这同一个嵌入空间中。进而,在这个空间中可以实现跨模态检索和匹配等任务,此外将该模型与生成模型结合,还可实现音频生成图像、图像生成音频等应用效果。
(8)ChatBridge
ChatBridge是一个新型的多模态对话模型,利用语言的表达能力作为桥梁,以连接各种模式之间的差异,可支持文本、图像、视频、音频几个模态任意组合的模型输入与输出信息。
该模型包括两阶段的训练,首先是每个模态与语言对齐,提升跨模态相关性和协同学习能力,接下来是多任务的指令微调,使其与用户的意图对齐。ChatBridge 在面向文本、图像、音频与视频等模态信息的广泛下游任务中表现出优异的零样本学习能力。
(9)VisualGLM-6B
VisualGLM-6B是由语言模型 ChatGLM-6B 与图像模型BLIP2-Qformer 结合而得到的一个多模态大模型,其能够整合视觉和语言信息。
可以用来理解图片,解析图片内容。该模型依赖于 CogView数据集中 3000 万个高质量的中文图像-文本对,以及 3 亿个精选的英文图像-文本对进行预训练。这种方法使视觉信息能够很好地与ChatGLM 的语义空间对齐。在微调阶段,该模型在长视觉问答数据集上进行训练,以生成符合人类偏好的答案。
(10)VisCPM
VisCPM是一个多模态大模型系列,其中的 VisCPM-Chat 模型支持中英双语的多模态对话能力,而 VisCPM-Paint 模型支持文到图生成能力。VisCPM 基于百亿参数量语言大模型 CPM-Bee(10B)训练,融合视觉编码器和基于扩散模型的视觉解码器以支持视觉信号的输入和输出。得益于 CPM-Bee 基座的双语能力,VisCPM 可以仅通过英文多模态数据预训练,泛化实现中文多模态能力。
(11)mPLUG-Owl
阿里达摩院的 mPLUG-Owl大模型可以支持多种数据模态,包括图像、文本、音频等。它采用了预训练和微调的方法,通过使用大规模的预训练数据和对特定任务微调的数据,可以快速高效地完成各种多模态任务。与传统的多模态模型相比,mPLUG-Owl 有更高的准确率和更快的运行速度。此外,它还具有高度的灵活性和可扩展性,可以根据实际需要进行快速部署和优化。
(12)Qwen-VL
Qwen-VL是支持中英文等多种语言的视觉语言模型。Qwen-VL 以通义千问 70 亿参数模型 Qwen-7B 为基座语言模型,在模型架构上引入视觉编码器,使得模型支持视觉信号输入,并通过设计训练过程,让模型具备对视觉信号的细粒度感知和理解能力。除了具备基本的图文识别、描述、问答及对话能力之外,Qwen-VL 还具备视觉定位、图像中文字理解等能力。
2. 典型开源框架与工具
PyTorch:PyTorch自身提供了几种加速分布数据并行的技术,包括分桶梯度(bucketing gradients)、通信和计算的重叠(overlapping computation with communication ) 以 及 在 梯 度 累 积 ( gradient accumulation)阶段跳过梯度同步(skipping gradient synchronization)。
PyTorch 分布式数据并行可以用 256 个 GPU 达到接近线性的可扩展性程度。在 DP 的基础上,原生支持 DDP,每个节点都有自己的本地模型副本和本地优化器,支持多机多卡的分布式训练。
一般来说,DDP 都显著快于 DP,能达到略低于卡数的加速比,但要求每块GPU 卡都能装载完整输入维度的参数集合。在 1.11 版本后,PyTorch 开始支持 FSDP 技术,可以更加高效的将部分使用完毕的参数移至内存中,显著减小了显存的峰值占用,更加吻合大模型的特性。
Tensorflow:TensorFlow是一款由 Google Brain 团队开发的开源机器学习框架,被广泛应用于各种深度学习领域。它可以处理多种数据类型,包括图像、语音和文本等,具备高度的灵活性和可扩展性。TensorFlow 使用数据流图计算模型来建立机器学习模型,用户可以通过定义操作和变量在数据流图上构建自己的神经网络模型。
此外,TensorFlow 还提供了众多优化器、损失函数和数据处理工具,以便用户轻松进行模型训练和优化。TensorFlow 在多个领域有广泛的应用,包括自然语言处理、图像识别和语音识别等。它可以灵活地运行在不同硬件平台上,包括 CPU、GPU 和 TPU 等。TensorFlow 还提供了高级 API,使开发者可以快速构建、训练和部署深度学习模型。
PaddlePaddle:飞桨(PaddlePaddle,Parallel Distributed Deep Learning)是我国较早开源开放、自主研发、功能完备的产业级深度学习框架。飞桨不仅在业内最早支持了万亿级稀疏参数模型的训练能力,而且近期又创新性的提出了 4D 混合并行策略,以训练千亿级稠密参数模型,可以说分布式训练是飞桨最具特色的技术之一。
飞桨的分布式训练技术在对外提供之前就已经在百度内部广泛应用,如搜索引擎、信息流推荐、百度翻译、百度地图、好看视频、文心 ERNIE 等等,既包含网络复杂、稠密参数特点的计算机视觉(CV)自然语言处理(NLP)模型训练场景,又覆盖了有着庞大的 Embedding 层模型和超大数据量的推荐搜索训练场景。
MindSpore:MindSpore是一款适用于端边云全场景的开源深度学习训练/推理框架。MindSpore 能很好匹配昇腾处理器算力,在运行高效和部署灵活上具有很好的能力。
MindSpore 还具有无缝切换静态图动态图、全场景覆盖、新 AI 编程范式等特点。MindSpore 还提供了多种高层 API,如 MindArmour、MindSpore Hub、MindInsight 等,方便开发者进行安全训练、模型共享、可视化分析等操作。
Jittor:Jittor是一个基于即时编译和元算子的高性能深度学习框架。Jittor 集成了算子编译器和调优器,可以为模型生成高性能的代码。Jittor 与 PyTorch 兼容,可以方便地将 PyTorch 程序迁移到 Jittor 框架上。
Jittor 支持多种硬件平台,包括 CPU、GPU、TPU 等。Jittor 在框架层面也提供了许多优化功能,如算子融合、自动混合精度训练、内存优化等。
OneFlow:OneFlow能够较好适用于多机多卡训练场景,是国内较早发布的并行计算框架。OneFlow 会把整个分布式集群逻辑抽象成为一个超级设备,用户可以从逻辑视角的角度使用超级设备。
最新版本的 OneFlow 和 TensorFlow 一样,实现了同时对动态图和静态图的支持,而且动静图之间转换十分方便。此外,OneFlow兼容了 PyTorch,支持数据 + 模型的混合并行方式,可提升并行计算性能。
Colossal-AI:“夸父”(Colossal-AI),提供了一系列并行组件,通过多维并行、大规模优化器、自适应任务调度、消除冗余内存等优化方式,提升并行训练效率,并解耦了系统优化与上层应用框架、下层硬件和编译器,易于扩展和使用。提升人工智能训练效率的同时最小化训练成本。
**在三方面进行了优化:优化任务调度、消除冗余内存、降低能量损耗。**夸父从大模型实际训练部署过程中的性价比角度出发,力求易用性,无需用户学习繁杂的分布式系统知识,也避免了复杂的代码修改。仅需要极少量的改动,便可以使用夸父将已有的单机 PyTorch 代码快速扩展到并行计算机集群上,无需关心并行编程细节。
Megatron-LM:Megratron是 NVIDIA 提出的一种基于PyTorch 分 布式 训练 大 规 模 语 言模型 的 架 构 , 用于训 练 基 于Transformer 架构的巨型语言模型。
针对 Transformer 进行了专门的优化,主要采用的是模型并行的方案。Megatron 设计就是为了支持超大的 Transformer 模型的训练的,因此它不仅支持传统分布式训练的数据并行,也支持模型并行,包括 Tensor 并行和 Pipeline 并行两种模型并行方式。
同时提出了更加精细的 pipeline 结 构 与communication 模式。通过多种并行方式的结合,可以让大模型的训练更快。将核心操作 LayerNorm 和 Dropout 安装输入维度进一步切分,使得这两个需要频繁运行的操作在不大幅增加通信开销的情况下实现了并行。
DeepSpeed : 在 2021 年 2 月 份 , 微 软 发 布 了 一 款 名 为DeepSpeed的超大规模模型训练工具,其中包含了一种新的显存优化技术——零冗余优化器 ((Zero Redundancy Optimizer, ZeRO)。
该技术去除了在分布式数据并行训练过程中存储的大量冗余信息,从而极大地推进了大模型训练的能力。从这个角度出发,微软陆续发布了ZeRO-1,ZeRO-2,ZeRO-3 和 ZeRO-3 Offload,基本实现了 GPU 规模和模型性能的线性增长。
基于 DeepSpeed,微软开发了具有 170 亿参数的自然语言生成模型,名为 Turing-NLG。2021 年月,推出了能够支持训练 2000 亿级别参数规模的 ZeRO-2。目前最新版本 ZeRO-3 Offload 可以实现在 512 颗 V100 上训练万亿参数规模的大模型。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享]👈

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享👈

















 2896
2896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









