







文章目录
什么是梯度下降?
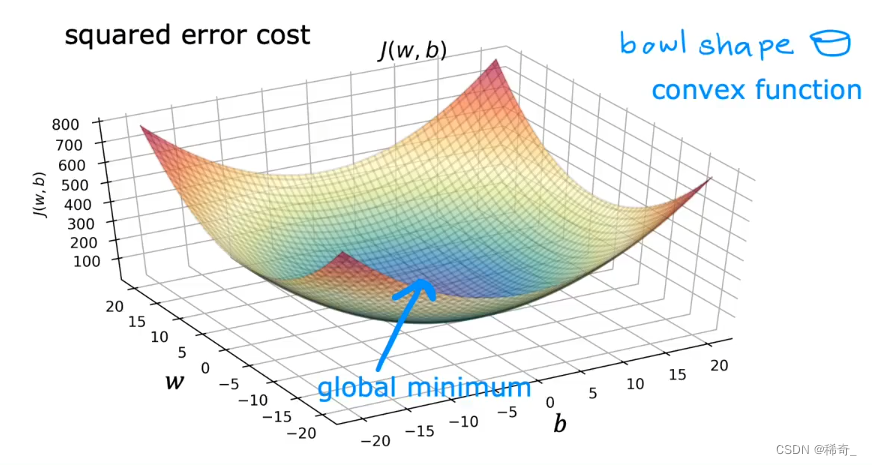
梯度下降是寻找目标函数最小化的方法。
比如在上一个单变量线性回归模型文章中我们的目标是得到最拟合的单变量线性回归Function,也就是得到代价函数的最小值:min J(w,b) 。
那么如何得到呢?梯度下降法就可以通过不断迭代调整参数来寻找最合适的值。
梯度下降表达式
我们还是用单变量线性回归模型中的J(w,b)来举例:
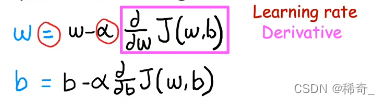
我们持续不断地更新w和b,直到他们收敛,也就是计算后他们的值已经不会出现什么变动,那么我们就得到了局部(以下文章会解释为什么是局部)/ 全局最小值(只是收敛到极小值,而不是真正意义上的最小值。以下说的最小值,其实都是极小值)或是鞍点。
注意我们需要同步更新w和b,也就是w更新后,b更新时用的还是没有更新的w。

表达式解释
这里的等号是一个赋值符号,而不是数学意义上的相等符号。
这里的Alpha是学习率(learning rate),用来控制步长,也就是我们每一步的跨度,一定大于0,通常在0到1之间,在之后的文章中会详细讲解。
这里的最后一项是对于代价函数J(w,b)的偏导,用来控制方向。
梯度下降的直观理解
为了更直观的观察梯度下降是如何让目标函数的最小化,我们假设只有一个参数的代价函数 J(w),在上一章中我们知道J(w)是一个二次函数(quadratic function),也就是一个抛物线。
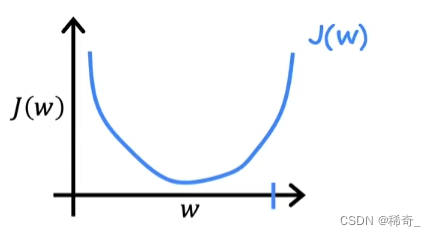
我们假设一个在抛物线上的初始点
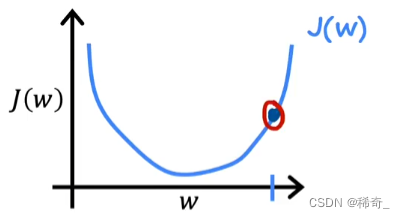
现在开始进行梯度下降: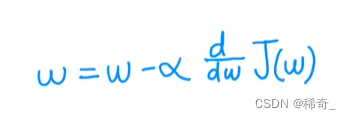
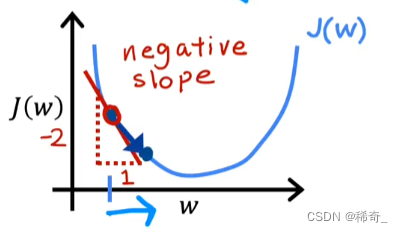
这里的最后一项(对J(w)的求导)在图中就是这个点的斜率:
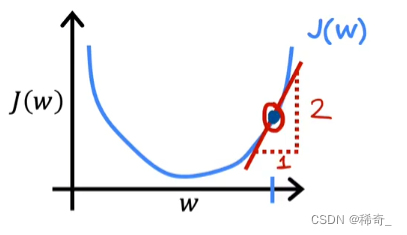
那么也就是w = w -
α
\alpha
α * 一个正数,由于alpha一定是正数,所以w减小了所以在图中的表现就是点向左移动,也就是向最小值靠近:
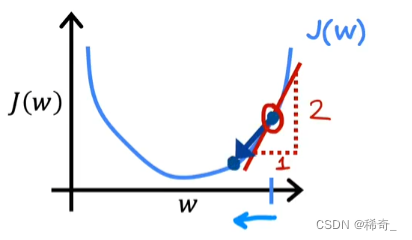
再来看另一个例子,当我们取的点在抛物线左边: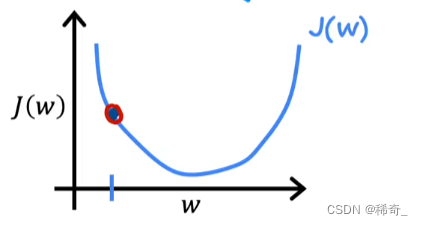
那么这个时候J(w)的求导就是负数,也就是一个负的斜率:
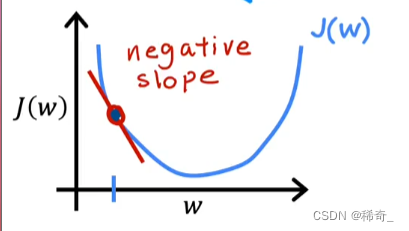
那么现在w = w -
α
\alpha
α * 一个负数,w增大了,所以在图中的表现就是点向右移动,也在向最小值靠近:
学习率(learning rate)
学习率的过大或过小都会造成一些影响:
学习率过小: 梯度下降的速度会非常慢,因为每次下降的步长都太小,虽然最终也能得到正确结果,但会花费非常长的时间。
学习率过大: 梯度下降的过多,会错过最小值,并且无法收敛。
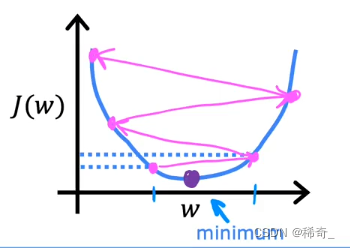
固定的学习率只能找到局部最小值
由于当 J(w) 的取值在局部最小值的时候,这个点的斜率为0,那么在下一次更新的时候,由于最后一项求导值为0,0乘上alpha还是0,所以w的取值已经不会再改变。
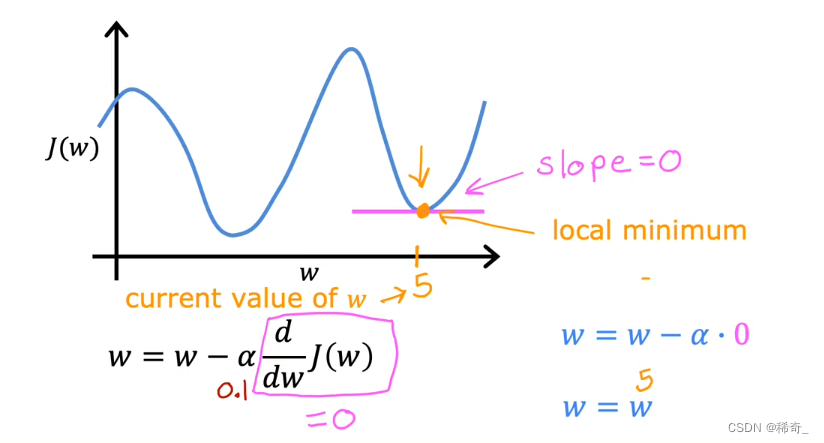
到达哪个局部最小值取决于选择的起始点
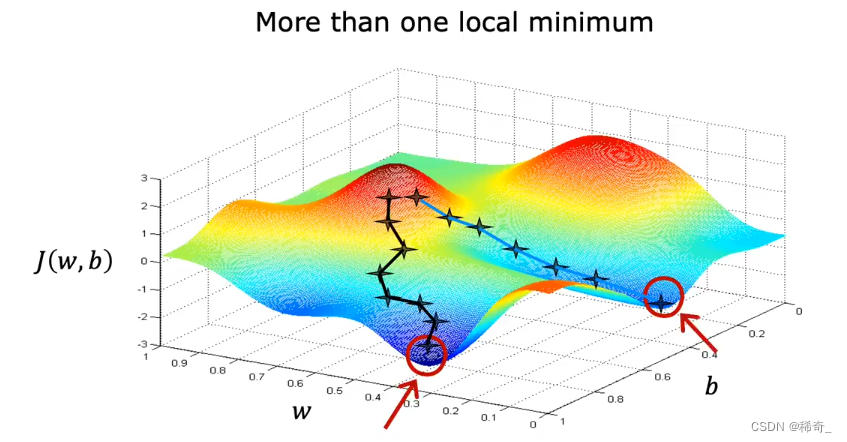
但在回归中使用平方代价函数时,代价函数没有也永远不会有多个局部最优解,也就是只有全局最优解。这种函数我们称为凸函数。
J(w) 靠近最小值的速度会逐渐变慢
即使在 alpha(学习率)不变的情况下,随着 J(w) 的值向最小值靠近的时候,点的斜率会越来越小,所以w变化的速度也会逐渐变慢。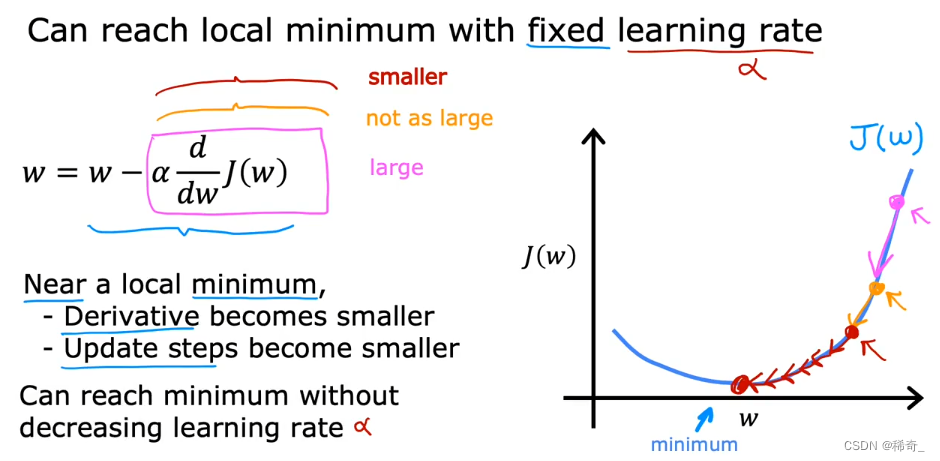
线性回归中的梯度下降
回顾上一章的内容: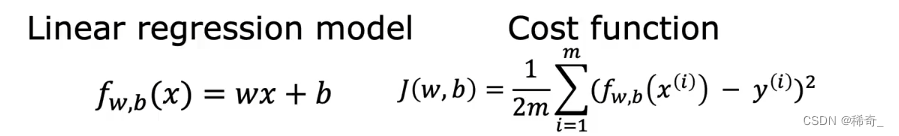
在对J(w,b)进行求导后得到:
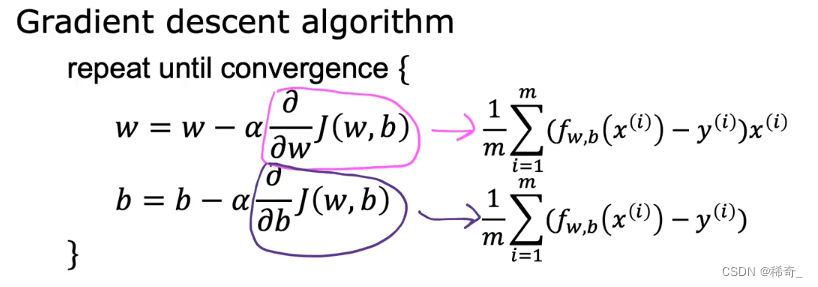
求导过程:
对w求导:

对b求导:
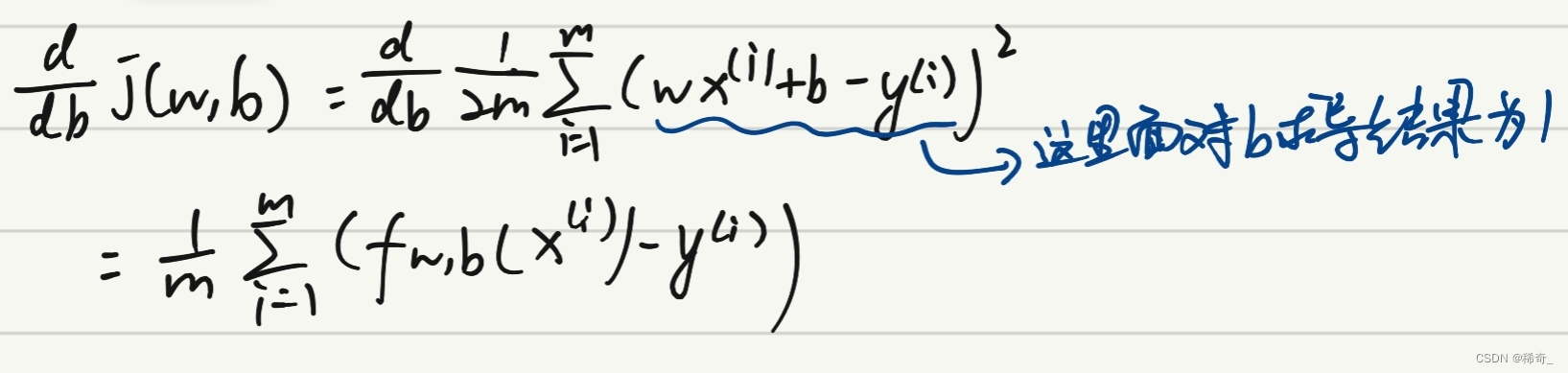
重复对 w 和 b 的求导,直到它们收敛。我们就找到了 f(x) 的最小值。














 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









