







文章目录
什么是逻辑(Logistic)回归
逻辑回归是一种用于解决二分类(要么是0要么是1)问题的机器学习方法。比如:一个患者的肿瘤是否为良性的,结果只有 是 或 不是 两种可能性。
Sigmoid函数
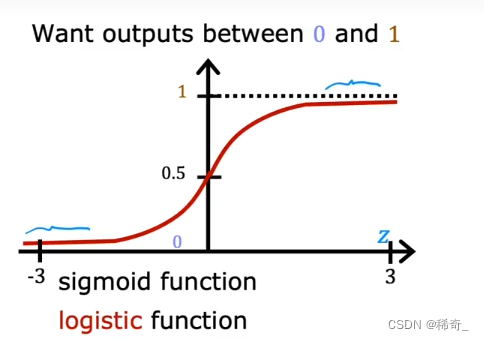
为了建立逻辑回归算法,需要一个重要的数学函数,它被称为逻辑函数(Logistic function)或者Sigmoid函数。
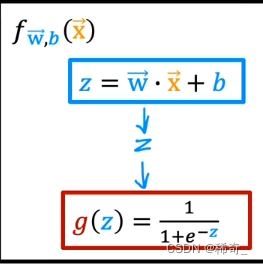
公式:
图像:
这里的 z 与线性回归中的公式一样:
合并起来就是逻辑回归模型:它接收一个特征或一组特征x,输出0到1之间的数字:
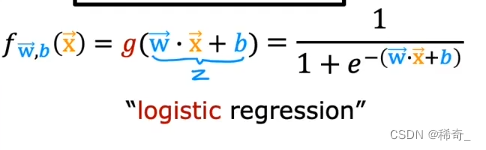
那么输出的0到1之间的数字代表着什么呢?
举个例子:
我们想要预测一个患者的肿瘤是否是恶性的,我们把良性的定义为y = 0,恶性的为 y = 1,x为肿瘤大小。我们想知道y = 1 的概率是多大。
这个时候的输出结果为0.7,那么这意味着有70%的可能性,肿瘤是恶性的。那么肿瘤是良性的可能性就是30%。
公式的另一种写法:

决策边界(Decision Boundary)
我们的逻辑回归模型返回的是一个0到1之间的数字,但我们想要的是确定的0或者1这两个数字。也就是这个肿瘤是良性的,或者不是良性的。
所以我们就要选择一个阈值(threshold),当输出的值超过这个值的时候,我们可以认为这个肿瘤不是良性的,反之亦然。
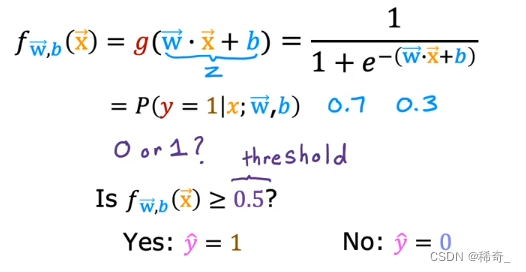
那么什么时候sigmoid函数会大于阈值呢:

简单来说,就是wx+b大于等于0的时候,因为:
f(x) = g(z),只有当 z 大于等于 0 的时候,g(z) 才会大于等于0.5(见下图),而 z = wx + b 所以就得到当w*x+b大于等于0的时候我们就说这个肿瘤不是良性的。
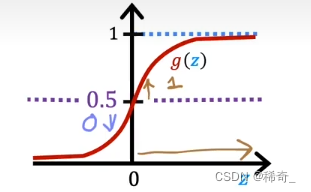
而这个0.5我们就成为决策边界Decision Boundary。
多个特征的决策边界
线性决策边界
现在我们假设我们有两个特征x1, x2,下图的蓝色小圈我们假设为正例子(y = 0),红色叉我们假设为负例子(y = 1)
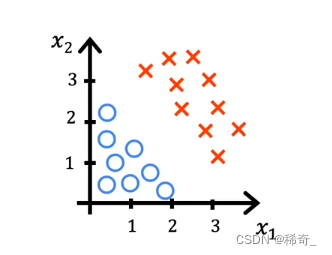
那么我们的逻辑回归模型的函数就是:
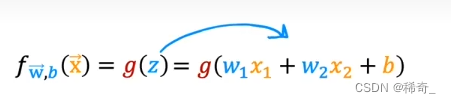
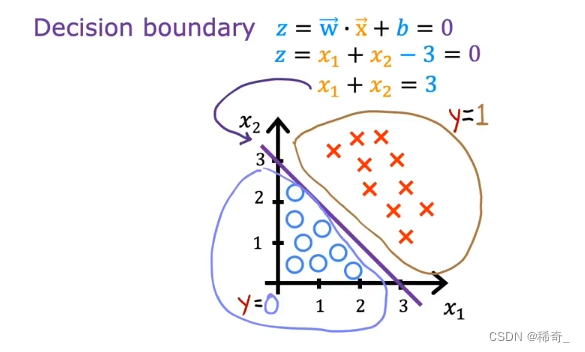
我们假设w1 = 1, w2 = 1, b = -3,我们的决策边界是: z = w*x + b = 0 也就是 x1 + x2 = 3 这条直线:
非线性决策边界
当数据呈现如下分布:
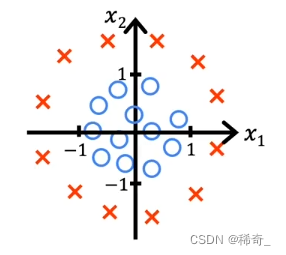
我们的逻辑回归函数就会是一个多项式函数:
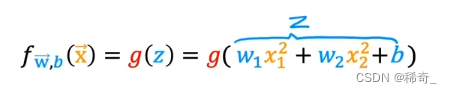
假设w1 = 1,w2 = 1,b = -1,那么决策边界就是:
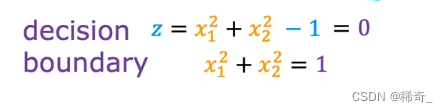
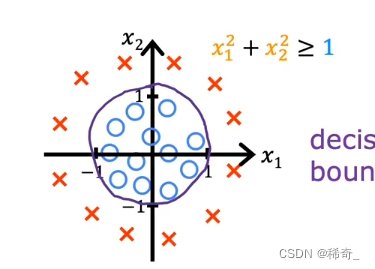
逻辑回归的代价函数
如何选择 w 和 b 的值呢?
我们尝试像之前一样使用代价函数 (Cost Function) 或者叫 平方误差成本(squared error cost)
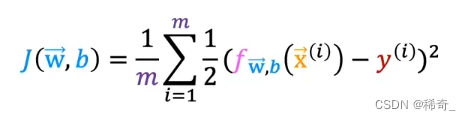
在之前的线性回归中,使用squared error cost后的图像是一个凸函数(convex)
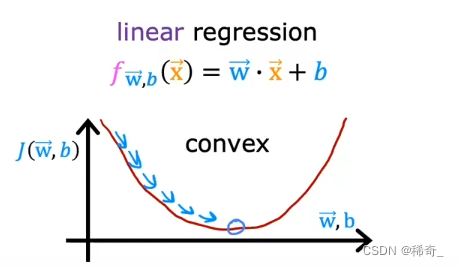
所以我们可以一步步地靠近最小值(极小值),但是如果在逻辑回归中,使用squared error cost后的图像是不平滑的,呈现起伏的:
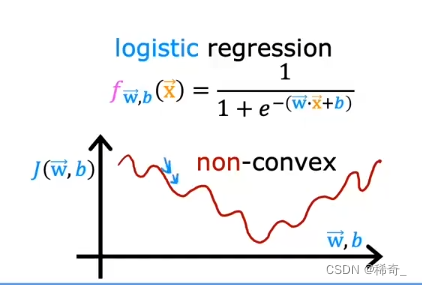
这将会导致我们会到达很多很多个局部最小值,而不是真正的全局最小值。
所以我们将采用一个新的代价函数
Logistic loss 函数
我们定义一个新的函数叫做Loss function:
我们将最后一项的平方里的函数提出来:
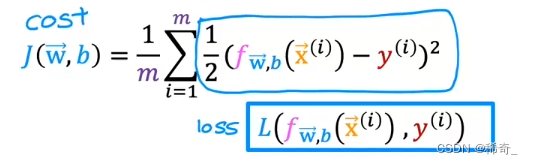

推导过程
现在让我们来看看这两个表达式的图像:
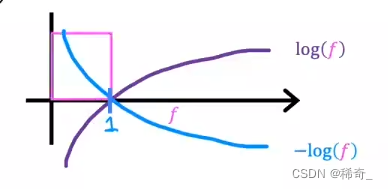
让我们放大第一个log函数中的0到1之间的图像:
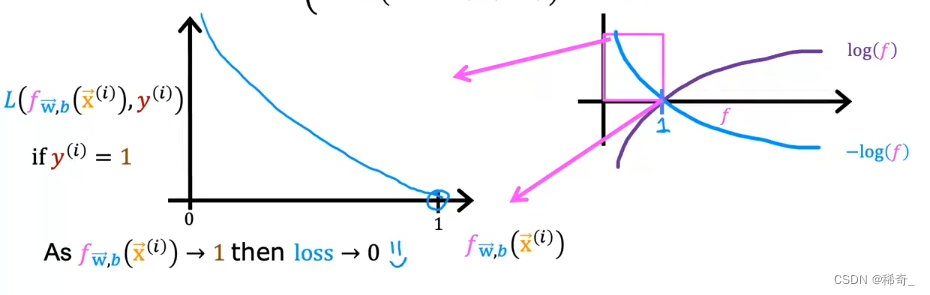
我们可以从图像中看出,当算法预测出1的可能性非常接近1的时候(也就是横坐标无限接近1的时候),而真实的标签也是1的时候,那么Logister loss function的值(也就是纵坐标的值)无限接近0,这说明误差非常小,因为我们无限接近正确答案。反之:如果我们算法预测出为0的概率很大的话(横坐标得值无限接近0),那么loss function的值就会无限接近无穷大(纵坐标的值无限接近无穷大),这就说明误差非常大,我们偏离了正确答案。
现在我们来看看第二个log函数的图像,基本和第一个图像差不多:

与第一张图像相似,只是方向改变了。
这样就能很好地找到全局最小值了
逻辑回归的代价函数
我们可以简化上面的分布式函数为一行:
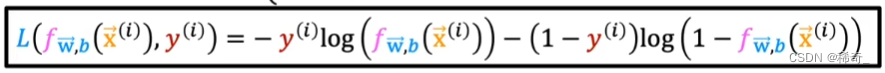
当y(i) = 1 的时候,后面一项的1-y(i)就会变成1-1 = 0,所以就会自动消失,同理,当y(i) = 0的时候,前一项也会消失。所以这个函数和上面的函数是完全相等的。
梯度下降实现
与线性回归相似,也是重复更新w和b的值:

j = 1…n,n为特征的数量,对J(w,b) 求导后为:
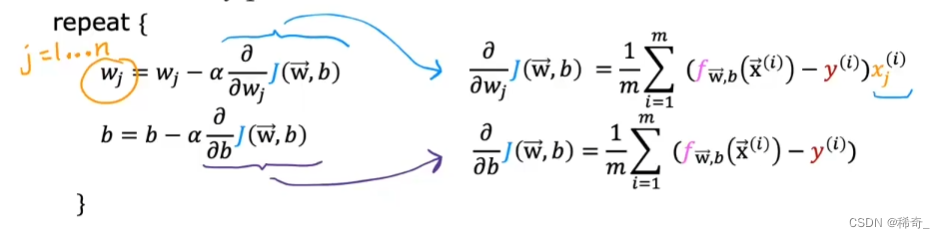
与线性回归相同点:
- 需要同时更新每个w和b
- 都采用学习曲线来监控梯度下降
- 都可以使用向量化来提高运行时间
- 都可以使用特征缩放以获得相似的值范围














 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









