






一、超参数调试
参数类型

如图为要处理的参数 ,用红色框圈起来的学习率最为重要,黄色框圈起来的参数𝛽,隐藏单元,
mini-batch 的大小是其次比较重要的,然后是紫色框圈起来的层数,学习衰减率。事实上,基本从不调试𝛽1,𝛽2和𝜀,默认其分别为 0.9,0.999 和10**−8。
如何选择调试值
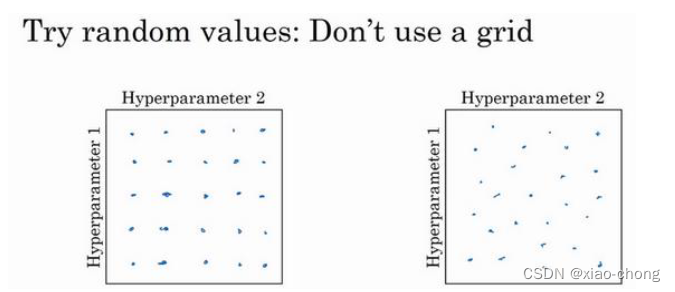
在早一代的机器学习算法中,常见的做法是在网格中取样点,如左图,然后系统的研究这些数值。这里我放置的是 5×5 的网格,实践证明,网格可以是5×5,也可多可少,但对于这个例子,你可以尝试这所有的 25 个点,然后选择哪个参数效果最好。当参数的数量相对较少时,这个方法很实用。
在深度学习领域,我推荐你采用右图的做法,随机选择点。因为左图中虽然有25个点,但每个参数实际上都只取到了5个值,而右图中25个点就是25个值,更有可能发现效果做好的那个。
实践中,超参数的数量可能不止2个,假设是三个就在三维的立方体网格中取,依此类推。
由粗糙到精细的策略
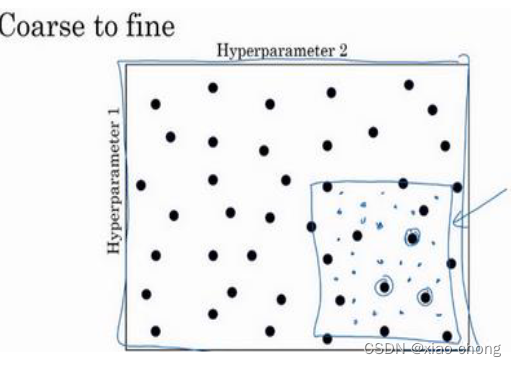
比如在二维的那个例子中,你进行了取值,也许你会发现效果最好的某个点,也许这个点周围的其他一些点效果也很好,那在接下来要做的是放大这块小区域(小蓝色方框内),然后在其中更密集得取值或随机取值,聚集更多的资源。
为超参数选择合适的范围
随机取值并不是在有效范围内的随机均匀取值,而是选择合适的标尺,用于探究这些超参数。
1.选取隐藏单元的数量和神经网络的层数,用线性轴较合适。

2.搜索超参数𝑎(学习速率) ,你画一条从 0.0001 到 1 的数轴,沿其随机均匀取值,那 90%的数值将会落在 0.1 到 1 之间,因此用线性轴不太合理,下面用对数标尺搜索更加合理。

在对数坐标下取值,取最小值的对数就得到𝑎的值,取最大值的对数就得到𝑏值,所以现在你在对数轴上的10𝑎到10𝑏区间取值,在𝑎,𝑏间随意均匀的选取𝑟值,将超参数设置为10𝑟,这就是在对数轴上取值的过程。
3.给𝛽 取值
假设𝛽是0.9 到 0.999 之间的某个值,我们要探究1-𝛽就可以用上述的对数标尺搜索,然后求得
𝛽 = 1 − 10**𝑟。
超参数调试实践

有两种实践方式,当没有许多计算资源或足够的 CPU和 GPU 时,一般采用第一种方式,用心照料一个模型,观察它的表现,耐心地调试学习率。如果拥有足够的计算机去平行试验许多模型,那就如右图同时试验多种模型,对比学习曲线。
二、Batch 归一化
作用:
Batch 归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大。
对单层神经网络进行Batch 归一化:

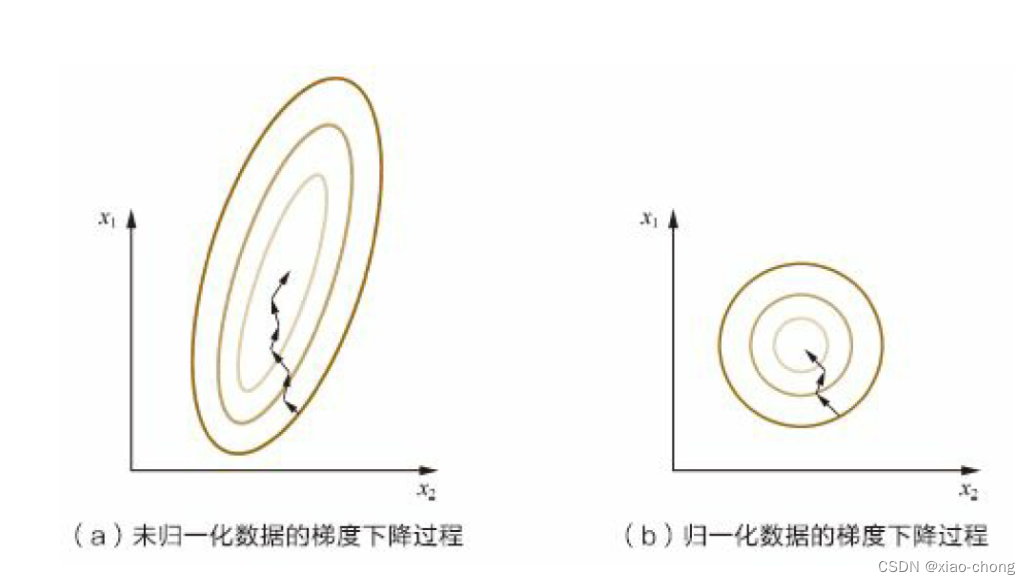
在学习 Batch 归一化之前,我们先回顾一下先前对逻辑回归的输入特征进行的归一化,如上图所示。通过上图中的四步,能将损失函数图像变得更圆更正,会帮助你更有效的训练𝑤和𝑏。
那么对于更深的模型呢,如果你想训练某个隐藏层的参数,比如𝑤[3],𝑏[3],那归一化𝑎[2]的平均值和方差便可使𝑤[3],𝑏[3]的训练更有效率。但在实践中,经常做的是归一化𝑧[2],按照下图的方式。
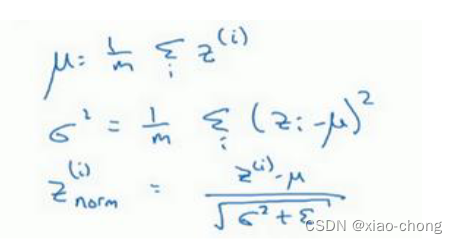
经过上述步骤能将这些𝑧值标准化,化为含平均值 0 和标准单位方差 ,但我们不想让隐藏单元总是含有平均值 0 和方差 1,也许隐藏单元有了不同的分布会更有意义,所以 还需要计算𝑧̃ (𝑖) =𝛾𝑧norm
(𝑖) + 𝛽,这里𝛾和𝛽是你模型的学习参数,在梯度下降中也需要更新它们。有了𝛾和𝛽两参数的控制,均值和方差可以是0 和 1,也可以是其它值。
总结起来就是如下四步:

将 Batch Norm 拟合进深层神经网络
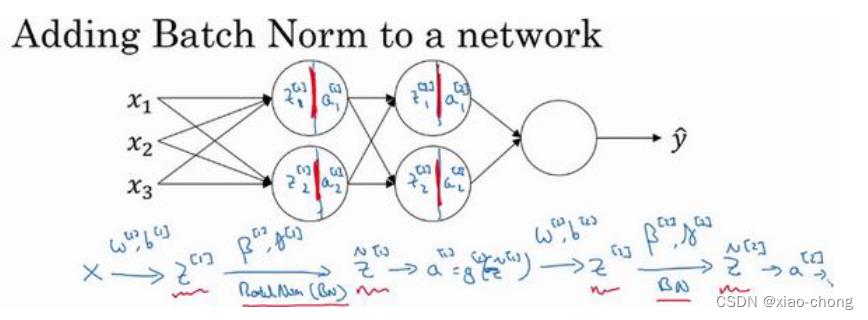
需要强调的是 Batch 归一化是发生在计算𝑧和𝑎之间的,大致步骤如同图中显示。
实践中,Batch 归一化通常和训练集的 mini-batch 一起使用。在 Batch 归一化的过程中,你要计算𝑧[𝑙]的均值,再减去平均值,这意味着加上的任何常数都将会被均值减去所抵消,所以其实你可以消除这个参数(𝑏[𝑙]),或者暂时把它设置为 0。
Batch Norm 为什么奏效
第一个原因:
归一化输入特征值,使其均值为 0,方差为1,每层的输入值分布范围都比较均匀,能使损失函数函数更圆,梯度下降时速度更快。
第二个原因
当神经网络在之前层中更新参数,Batch 归一化可以确保无论其怎样变化𝑧1[2],𝑧2[2]的均值和方差保持不变,所以即使𝑧1[2],𝑧2[2]的值改变,至少他们的均值和方差也会是均值 0,方差 1,或不一定必须是均值 0,方差 1,而是由𝛽[2]和𝛾[2]决定的值。 Batch 归一化减少了输入值改变的题,它使这些值变得更稳定,神经网络的之后层就会有更坚实的基础。
也可以这样想,它减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习,稍稍独立于其它层,这有助于加速整个网络的学习。
第三个原因
它有轻微的正则化效果,正如上面所说,它使后部单元不过分依赖任何一个隐藏单元,类似于dropout的效果。
三、Softmax 回归(Softmax regression)
作用:
logistic 回归的一般形式,识别多个分类。
步骤:

左边为步骤,右边为例子
训练一个 Softmax 分类器
1.我们先定义训练神经网络使会用到的损失函数,一般用到的损失函数
代价函数
2.梯度下降
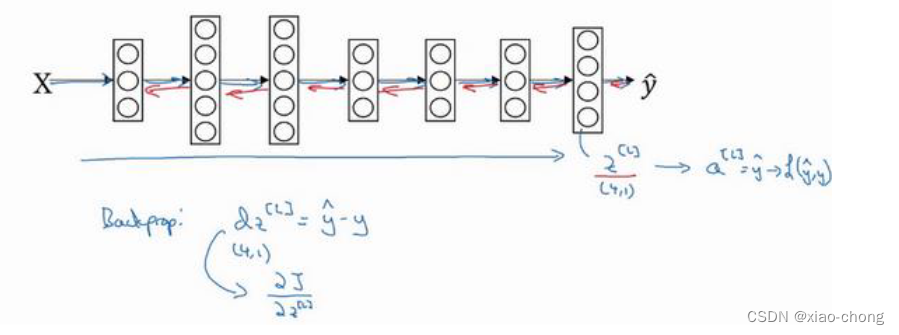
Softmax 分类就学到这里 ,接下来我们会学习一些深度学习框架,对于这些编程框架,通常你只需要专注于把前向传播做对,只要你将它指明为编程框架,前向传播,它自己会弄明白怎样反向传播,会帮你实现反向传播。
四、深度学习框架(Deep Learning frameworks)
框架种类

TensorFlow
这个我就不详细写笔记了,在课后的编程作业中好好应用一遍能更好的理解哦!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









