









本文将概要性的讲解 PostgreSQL 中 lazy vacuum 的流程和原理,代码将以 PG 10.17 版本为例。
背景知识
死元组和表空间膨胀
在 PG 中,update/delete 语句的实现通过 MVCC 机制的多版本链实现。如下图所示,更新一条元组时,会将原来的元组标记,并新增一条元组。后续的事物通过快照来判断元组的可见性。

对于一条已经被更新/删除的元组来说,当这条元组对所有事物都不可见后,它的存在就没有意义了,理应被删除,对于这种元组,我们称之为“死元组”。当一张表有大量更新/删除时,如果不做清理的话,表里面就会积攒很多这样的“死元组”,占用大量的空间,造成表空间膨胀。
事物号回卷
PG 的事物号采用 32 位无符号整数 xid 来表示,约能表示 40 亿数字。借用[1]中的图 b 来说,对于任意一个 xid ,它在环中的前 20 亿对它来说是过去,后 20 亿对它来说是未来。
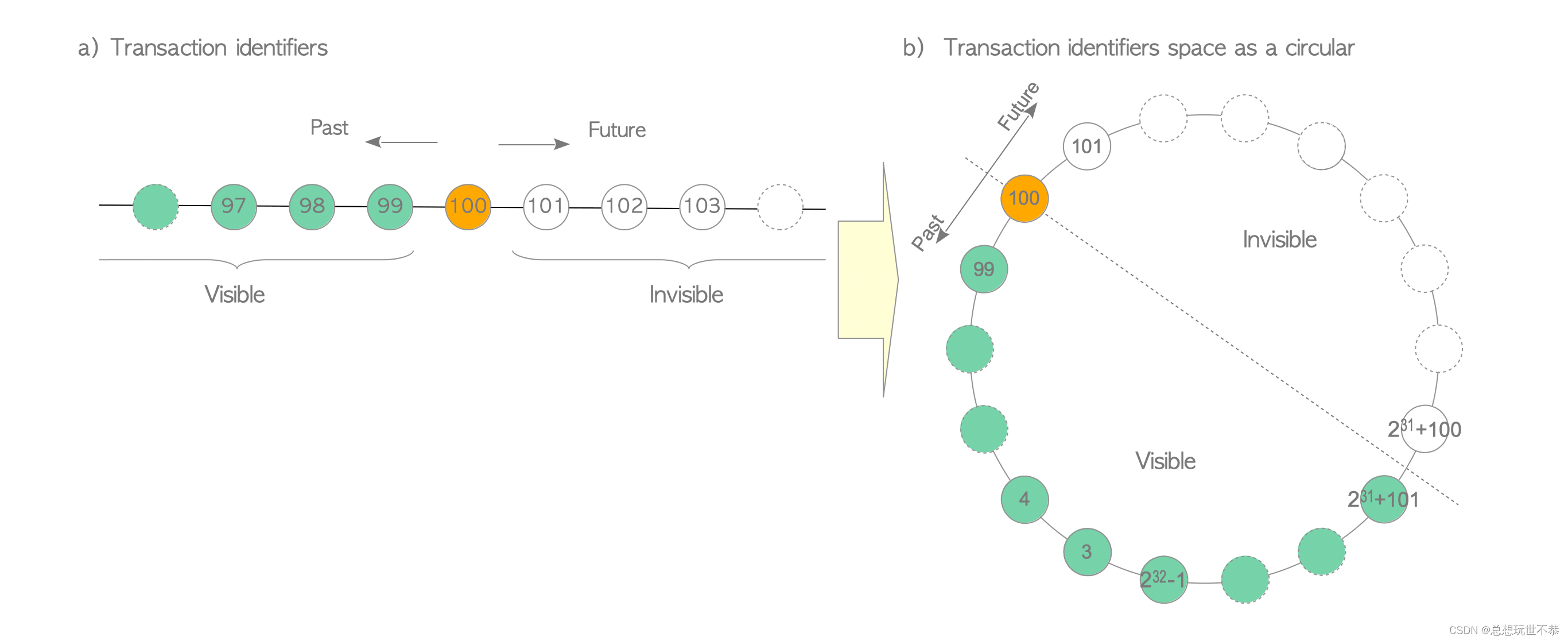
以上图为例,对于 xid 为 100 的事物来说,本来 99 是它的过去,当事物号耗尽的时候,99 会回卷重新使用。这时候就无法判断一条 xmin 或 xmax 为 99 的元组到底是过去还是未来。
Vacuum 功能概述
在提出上两个问题之后,就可以简单的介绍一下 vacuum 的功能:
- 清理死元组:删除死元组和其索引,回收表空间;
- 冻结元组的事物号:如果一个元组的事物号已经很老了,对于当前所有的事物都可见,那么就直接将它的事物号改为
FrozenTransactionId;(注:FrozenTransactionId对于所有事物号都属于过去) - 更新表的统计信息,方便优化器工作。
代码分析
总体结构
vacuum 的函数调用关系如下图所示。当执行 vacuum full 的时候,会调用图中左下角的 cluster_rel 函数;否则调用 lazy_vacuum_rel 函数。

在 lazy_vacuum_rel 函数中,主要完成以下几件事:
- 调用
vacuum_set_xid_limits设置一些阈值,用于后续判断是否采取迫切清理的策略(aggressive); - 调用
lazy_scan_heap做 vacuum 操作:删除元组和索引,清理表空间; - 调用
lazy_truncate_heap做截断操作,将表最后的空白页面截断; - 调用
FreeSpaceMapVacuum对 fsm 做 vacuum; - 更新系统表中的统计信息
lazy_scan_heap 函数
lazy_scan_heap 是做 vacuum 的主要函数。在介绍该函数之前,有几个术语/变量先要讲解一下含义:
-
死元组列表:vacuum 会维护一个数组,将当前 page 的所有死元组的头指针存在这个数组里;
-
relfrozenxid:标记一张表中所有 <relfrozenxid 的元组均被冻结;
-
迫切模式:这里直接引用 [2] 中的原文。当 relfrozenxid 满足特定条件时,将触发迫切模式;
冻结的过程有两种模式,依特定条件而择其一执行。一种为惰性模式另一种为迫切模式。惰性模式下,冻结过程仅适用目标表对应的VM扫描包含死元组的页面。迫切模式会扫描所有的页面,无论其是否包含死元组,都会更新与冻结过程相关的系统视图,并在可能的情况下删除不必要的 CLOG 文件。
-
过期元组:对所有事物均不可见的元组
该函数主要有以下几个步骤:
- 初始化若干变量,给死元组列表分配空间;
- 计算 next_unskippable_block,用于跳页逻辑判断;
- 循环遍历当前表的所有页面,进行 vacuum 处理。
- 如果有索引的话,需要先清理索引,再次访问表中的所有页面,进行清理操作;
计算 next_unskippable_block
如果出现很多页面都无需做 vacuum 的话,那么这些页面可以直接被跳过,提高 vacuum 效率。
vacuum 可以通过 vm (visbility map) 的状态来快速判断该页是否 全部可见/全部冻结,如果满足以下两个条件,那么当前页就可以跳过 vacuum。
- 处于迫切模式,且当前页面所有元组被冻结;
- 处于非迫切模式,且当前页面所有元组全可见;
如果发现超过连续 SKIP_PAGES_THRESHOLD (一般为32)个页面可跳,则后续处理到该页面时可以跳页。具体的跳页逻辑如下图所示,绿色的 page 为可以跳过的页面

之所以设置这个阈值有以下几个原因:
- OS 本身有页面预读算法,在读一个页的时候,OS 通常已经将该页后面的页面读进了操作系统的缓存,这时候只跳一个页并不会增加很高的性能;
- 如果跳页的话,整张表的
relfrozenxid无法被更新,会对后续 vacuum 执行的策略造成影响;
遍历处理所有页面
循环遍历当前表的所有页面,对于每个页面,都进行如下操作:
- 计算 next_unskippable_block,按照上图的逻辑判断是否需要跳页;
- 如果当前死元组列表快满了,调用
lazy_vacuum_index和lazy_vacuum_heap清理索引和元组; - 调用
ReadBufferExtended函数读取当前页面; - 获取当前页面的 clean up 锁,即排它锁。因为要修改页面,所以拿写锁。注意,这里只获取一次,如果处于非迫切模式且并不是最后一页的话,没获取到就算了,直接跳过当前页面,等下一次 vacuum 来处理。其他情况请参考代码里的注释;
- 调用
heap_page_prune函数,将当前页面上的 HOT 链进行修剪,将过期元组标记为死元组,对并调用PageRepairFragmentation进行页面空间整理 (关于这一部分的细节可以参考 [3] 这篇文章); - 遍历当前页面的所有元组,清理之前因为并发没有清理掉的过期元组和其他种类的元组,记录需要冻结的元组,并将所有死元组记录到死元组列表中;
- 如果有可冻结的元组,那么执行冻结操作;
- 如果当前表没有索引,那么直接调用
lazy_vacuum_page清理该页面:将死元组标记为LP_UNUSED,其他事物放元组的时候可以直接重用标记为LP_UNUSED的元组;
清理索引
如果当前表有索引的话,那么需要先清理索引。然后根据死元组列表,挨个访问所有存在死元组的 page (这里还有一次 IO),调用 lazy_vacuum_page 进行清理。
为什么在有索引的情况下不能进行上一节的第 8 步,原因很简单:没法保证原子性。如果索引没删除,而其指向的元组被删除甚至被重用,这会导致下一次按照这个索引找到的元组和这个索引没有任何关系,造成数据不一致。
总结
本文以一个较粗的粒度大致介绍了 lazy vacuum 的具体流程。对于其他的部分,如 vacuum full、autovacuum 的工作原理,将在后续的文章中讲解。
参考资料
[1] https://www.interdb.jp/pg/pgsql05.html
[2] https://www.modb.pro/db/238547
[3] https://blog.csdn.net/obvious__/article/details/121318928?spm=1001.2014.3001.5502















 3706
3706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











