







数据库版本
- PG 16.1
queryid 是什么
queryid 是将 sql 规范化 (normalization) 后,通过哈希函数计算出来的 64 位整数。
以 SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data; 这条 SQL 为例。当我们在 PG 中执行这条 sql 时,内核在语义分析阶段会将其规范化后计算哈希值。这个 sql 中,如果将 id<300 改成 id<400 ,它们对应的规范化 sql 仍然是同样的,queryid 也是同样的。
如果启用了 pg_stat_statements 插件,会看到其规范化后的 sql 语句 SELECT id, data FROM tbl_a WHERE id < $1 ORDER BY data; 和计算出来的 queryid。
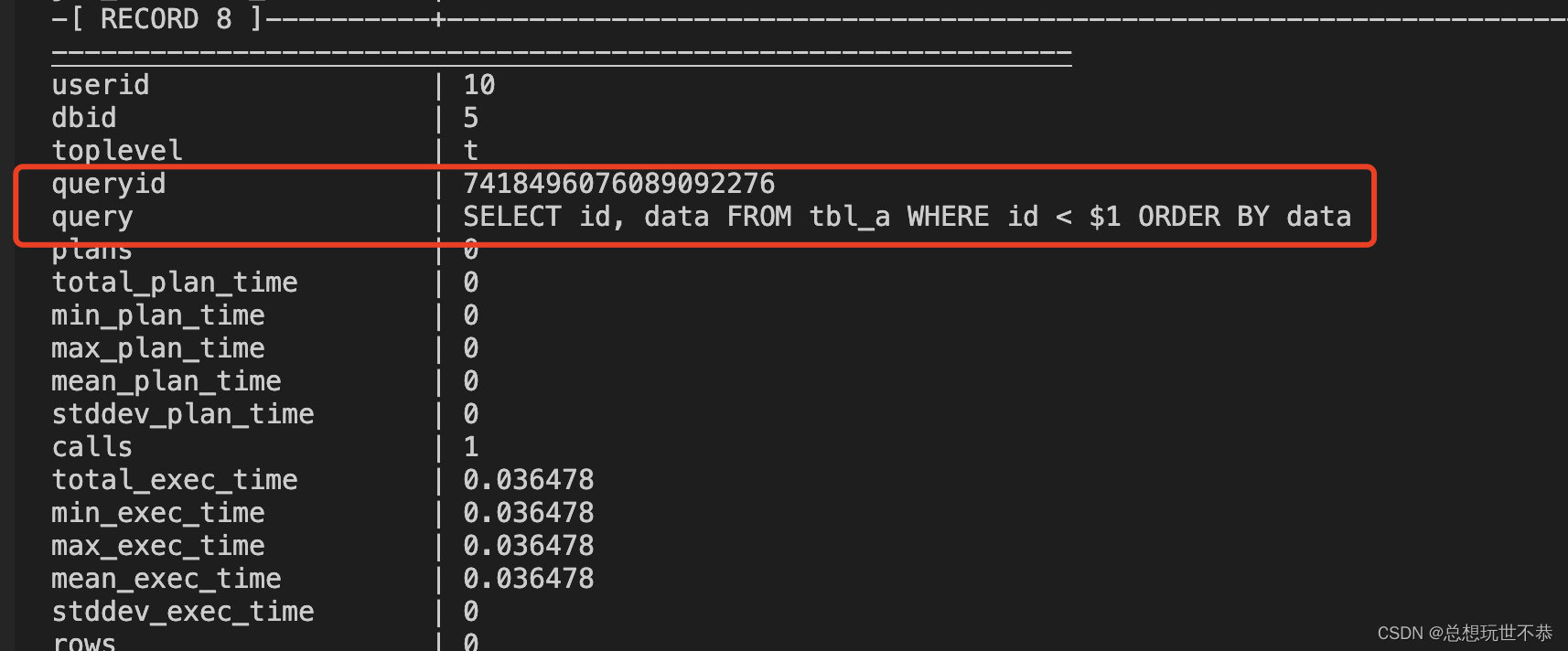
如何计算 queryid
众所周知,PG 在处理 SQL 时,会经过 词法分析->语法分析->语义分析->生成计划->执行计划 等阶段,而 queryid 的计算就是在语义分析阶段的 JumbleQuery 函数中完成的。
还以上文的 SQL SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data; 为例,语义分析阶段后,内核已经得到了 SQL 对应的 query 结构,如下图所示。(借用 interdb.jp [1] 文章中的图)
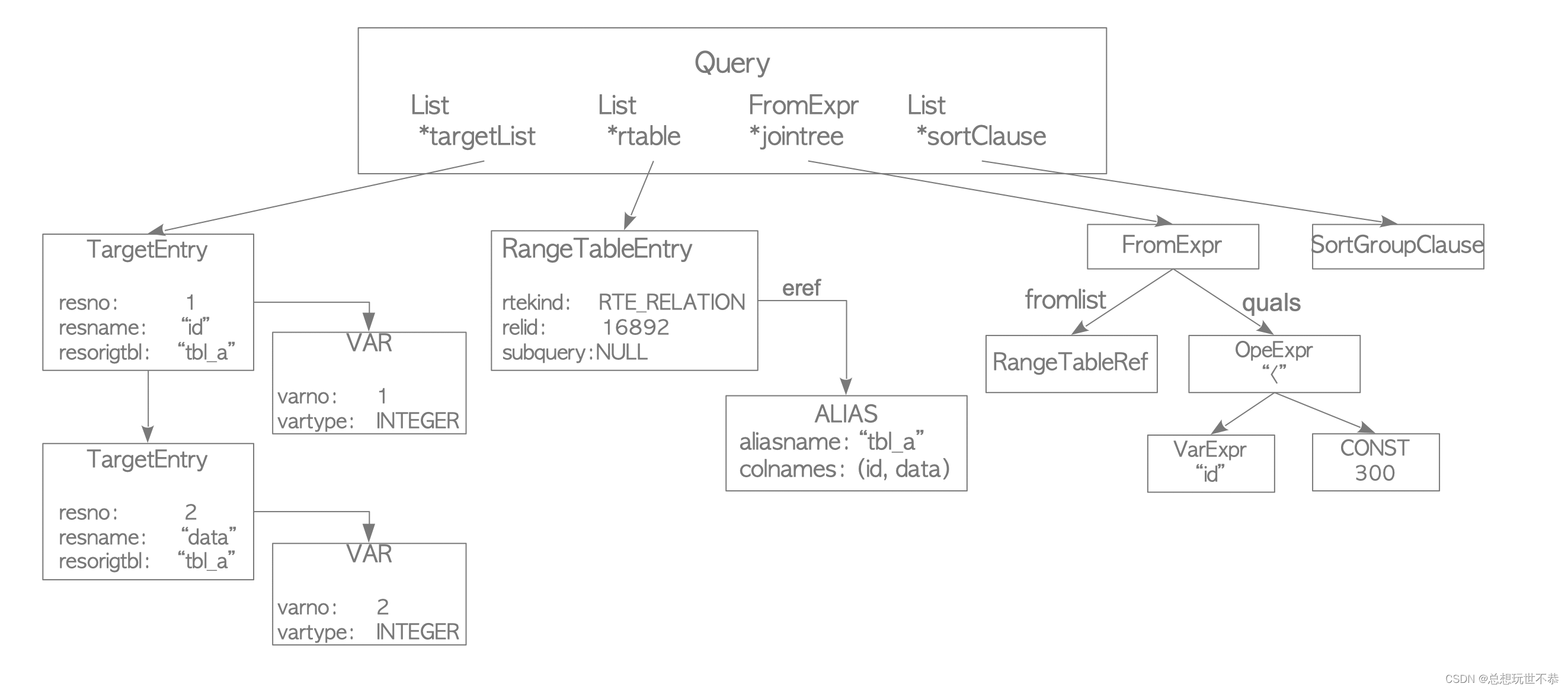
内核对所有需要 jumble 的结构都设定了对应 jumble 的方法,维护在 queryjumblefuncs.switch.c 文件中,下面简单列几行
case T_Alias:
_jumbleAlias(jstate, expr);
break;
case T_RangeVar:
_jumbleRangeVar(jstate, expr);
break;
case T_TableFunc:
_jumbleTableFunc(jstate, expr);
break;
static void
_jumbleAlias(JumbleState *jstate, Node *node)
{
Alias *expr = (Alias *) node;
JUMBLE_STRING(aliasname);
JUMBLE_NODE(colnames);
}
而对应到每个最终的结构上时,使用 AppendJumble 函数进行处理。将所有的输入都转成 unsigned char* 存到 jstate->jumble 变量里。如果发现长度满了就把之前的哈希一下从头开始存
static void
AppendJumble(JumbleState *jstate, const unsigned char *item, Size size)
{
unsigned char *jumble = jstate->jumble;
Size jumble_len = jstate->jumble_len;
/*
* Whenever the jumble buffer is full, we hash the current contents and
* reset the buffer to contain just that hash value, thus relying on the
* hash to summarize everything so far.
*/
while (size > 0)
{
Size part_size;
if (jumble_len >= JUMBLE_SIZE)
{
uint64 start_hash;
start_hash = DatumGetUInt64(hash_any_extended(jumble,
JUMBLE_SIZE, 0));
memcpy(jumble, &start_hash, sizeof(start_hash));
jumble_len = sizeof(start_hash);
}
part_size = Min(size, JUMBLE_SIZE - jumble_len);
memcpy(jumble + jumble_len, item, part_size);
jumble_len += part_size;
item += part_size;
size -= part_size;
}
jstate->jumble_len = jumble_len;
}
上述过程完成后,就得到了一个完整的 jumble 字符串。然后用内核的 hash_any_extend 对这个字符串进行哈希,得到的 64 位无符号整数就是 queryid(输出时会将其转为 int64)。
pg_stat_statement 生成规范化 sql
PG 内核所做的只是将一个 SQL 解析成 Query 结构,然后将所需要的部分拼起来哈希一下,得到一个 queryid,并没有规范化 sql 的概念。而 pg_stat_statement 的 generate_normalized_query 函数可以帮我们做到这一点,从
SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;
生成
SELECT id, data FROM tbl_a WHERE id < $1 ORDER BY data; 规范化的 sql。
下面是函数的源码,代码很长,其实就是做了一件事:将 sql 中的常量替换成 $1、$2…
static char *
generate_normalized_query(JumbleState *jstate, const char *query,
int query_loc, int *query_len_p)
{
char *norm_query;
int query_len = *query_len_p;
int i,
norm_query_buflen, /* Space allowed for norm_query */
len_to_wrt, /* Length (in bytes) to write */
quer_loc = 0, /* Source query byte location */
n_quer_loc = 0, /* Normalized query byte location */
last_off = 0, /* Offset from start for previous tok */
last_tok_len = 0; /* Length (in bytes) of that tok */
/*
* Get constants' lengths (core system only gives us locations). Note
* this also ensures the items are sorted by location.
*/
fill_in_constant_lengths(jstate, query, query_loc);
/*
* Allow for $n symbols to be longer than the constants they replace.
* Constants must take at least one byte in text form, while a $n symbol
* certainly isn't more than 11 bytes, even if n reaches INT_MAX. We
* could refine that limit based on the max value of n for the current
* query, but it hardly seems worth any extra effort to do so.
*/
norm_query_buflen = query_len + jstate->clocations_count * 10;
/* Allocate result buffer */
norm_query = palloc(norm_query_buflen + 1);
for (i = 0; i < jstate->clocations_count; i++)
{
int off, /* Offset from start for cur tok */
tok_len; /* Length (in bytes) of that tok */
off = jstate->clocations[i].location;
/* Adjust recorded location if we're dealing with partial string */
off -= query_loc;
tok_len = jstate->clocations[i].length;
if (tok_len < 0)
continue; /* ignore any duplicates */
/* Copy next chunk (what precedes the next constant) */
len_to_wrt = off - last_off;
len_to_wrt -= last_tok_len;
Assert(len_to_wrt >= 0);
memcpy(norm_query + n_quer_loc, query + quer_loc, len_to_wrt);
n_quer_loc += len_to_wrt;
/* And insert a param symbol in place of the constant token */
n_quer_loc += sprintf(norm_query + n_quer_loc, "$%d",
i + 1 + jstate->highest_extern_param_id);
quer_loc = off + tok_len;
last_off = off;
last_tok_len = tok_len;
}
/*
* We've copied up until the last ignorable constant. Copy over the
* remaining bytes of the original query string.
*/
len_to_wrt = query_len - quer_loc;
Assert(len_to_wrt >= 0);
memcpy(norm_query + n_quer_loc, query + quer_loc, len_to_wrt);
n_quer_loc += len_to_wrt;
Assert(n_quer_loc <= norm_query_buflen);
norm_query[n_quer_loc] = '\0';
*query_len_p = n_quer_loc;
return norm_query;
}
参考资料
[1] https://www.interdb.jp/pg/pgsql03/01.html
















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











