




web学习笔记大纲
- 一、Oracle数据库
- 二、JDBC
- 三、HTML
- 四、CSS
- 五、Servlet
- 六、JSP
- 七、Struts2框架
- 八、mybatis框架
- 九、JavaScript
- 十、JQuery框架
一、Oracle数据库
1.概念
概念:数据库是一种存储管理数据的软件,全称RDBMS(关系数据库管理系统),简称数据库(db)
数据库里常见的基本概念
(1)表(table): 二维表,实际负责数据的存储
(2)行(row): 存放一组具体的业务数据,也称为"记录"
(3)列(column): 描述了业务数据里的一个具体的属性,也称为"字段"
-主键(primary key): 唯一表示表里的一条记录,非空唯一
-外键(foreign key): 用来体现两张表数据之间的关系
数据库服务器
1.OracleServiceXE提供数据管理服务
2.OracleXETNSListener
内置客户端
sqlplus: oracle提供的内置的基于dos界面的客户端软件 输入命令sqlplus 用户名/密码
isqplus: oracle提供的基于浏览器形式的客户端软件(图形界面)
-链接: http://127.0.0.1:8080/apex
解锁hr用户:
1.通过isqlplus客户端解锁
2.通过sqlplus命令行解锁
(1)sqlplus sys as sysdba
(2)不用输入口令,直接回车
(3)alter user hr account unlock;
(4)alter user hr identified by 密码;
(5)exit
2.sql命令(增删改查)
1)select命令
-- 基本查询操作
select 字段名1,字段名2,字段名3 from 表名; --查询指定字段
select * from 表名; -- 查询全部字段(效率低,不建议使用)
select 字段名 别名 from 表名; -- 起别名(不区分大小写,默认是大写字母)
select 字段名 "别名" from 表名; -- 起别名(区分大小写)
select 字段名1||'_'||字段名2 别名 from 表名; -- 字符串拼接
select distinct 字段名1,字段名2 from 表名; -- 去除查询结果中字段名1和字段名2都相同的数据
-- 排序
select * from 表名 order by 字段名1 asc(默认,可不写); -- 按照字段名1进行升序排列
select * from 表名 order by 字段名2 desc; -- 按照字段名2进行降序排列
注意: 排序对象可以是字段名,别名,列号,如果有多个字段名,按顺序依次排序,null值在oracle里默认是最大值
-- 条件查询
select * from 表名 where 条件;
例如:
select * from employees where salary>=10000;
select * from employees where between 区间1 and 区间2; --区间判断
select * from employees where not between 区间1 and 区间2;
select * from employees where department_id in(值1,值2,值3); --枚举查询
select * from employees where department_id not in(值1,值2,值3);
select * from employees where department_id is null; --空值查询
-- 模糊查询
select * from 表名 where 字段名1 like 占位符值1;
例如:
--转义字符,escape关键字指定某个字符为转义字符
select * from employees where last_name like 'S\_%' escape '\';
注意: % 表示0-n个字符, _ 表示一个字符
根据字段名查询表: select TABLE_NAME from user_tab_columns where column_name='需要查询的字段名';
2)insert命令
语法: insert into 表名 values(值1,值2,值3…);
-- 全表插入
insert into student values(1,'hehe','13810020030','hehe@123.com',sysdate);
insert into student values(2,'haha','12345678910','haha@123.com',null);
注意: 1.values后值的个数,类型,数量必须与表里的字段保持一致
2.如果不方便给定值的字段(可以为空字段)必须使用null占位
-- 选择插入
insert into student(id,name,mobile,email) values(3,'lala','12345678902','lala@123.com');
注意: 对于表里非空或者没有默认值的字段必须出现
3)update命令
语法: update 表名 set 字段1=‘新值’,字段2=‘新值’ where 条件;
-- 将id为 3 的数据 name 改成baizhi3, mobile 改成12345678900
update student set name='baizhi3',mobile='12345678900', where id = 3;
4)delete命令
语法: delete 表名 where 条件;
3.函数— oracle提供的功能函数(单行函数、组函数)

1)单行函数
概念: 作用于指定表里的每一行数据执行一次,返回一个结果数据
-- abs(num): 计算num的绝对值
select abs(salary) from employees; --作用于表里的107行数据,得到107个执行结果
select abs(-2) from employees; -- 107个执行结果(表里107行)
-- dual: oracle提供的"单行单列表",为了维护select语句的完整性
select abs(-2) from dual;
-- sysdate,systimestamp: 代表当前系统时间
select sysdate from dual; -- 注意: oracle里默认的日期格式为: 'dd-mon-rr'
-- 打印当前系统时间(显示四位年、月、日、小时分钟秒、星期)
select to_char(sysdate,'yyyy-mm-dd,day,hh24:mi:ss') from dual;
-- 可以截取日期中的某一个组成部分
select to_char(sysdate,'day') from dual;
-- 用两种方式打印1997年入职的员工信息
select * from employees where hire_date like '%97';
select * from employees where to_char(hire_date,'yyyy') = 1997;
-- 请打印02-03-04是星期几
select to_char(to_date('02-03-04','dd-mm-rr'),'day') from dual;
2)组函数
硬性语法要求: 首尾呼应
a.如果select里出现了字段与组函数并存的情况,此时必须写group by
b.只有出现在group by里的字段才有权出现在select里,没有出现在group by里的字段需要配合组函数出现在select里
c.如果在group by里对字段应用了函数,则在select里显示时,需要应用同样的函数进行处理

注意: 空值一般使用nvl(字段名,为空时所替换的值)来处理
例如:select * from employees order by nvl(department_id,0) ;
-- 请打印公司的平均工资,最高工资,最低工资
select avg(salary),max(salary),min(salary) from employees;
-- 1.count(字段) : 统计指定字段中非空数据的个数
select count(department_id) from employees;
-- 2.count(*) : 统计结果中非空行的数量
-- 请打印1997年入职的员工人数
select count(*) from employees where hire_date like '%97';
分组语句: group by
-- 请打印部门编号以及部门的最高工资
select department_id,max(salary) from employees group by department_id;
-- 统计1997年各部门入职的人数
select department_id,count(*) from employees where hire_date like '%97' group by department_id;
-- 统计1997年各月入职的员工人数
select to_char(hire_date,'mm'),count(*) from employees where hire_date like '%97' group by to_char(hire_date,'mm');
分组数据的条件筛选: having
-- 请打印部门编号,人数(显示人数大于2的结果,按人数排序)
select department_id,count(*) from employees group by department_id having count(*)>2 order by count(*);
having和where的区别
1.where出现在分组前,以行为单位进行筛选,可使用单行函数
2.having出现在分组后,以组为单位进行筛选,可使用组函数
注意:如果一个功能where和having都能实现,则优选where
-- 查询部门编号为30和50的平均工资,按照部门进行分组
select department_id,avg(salary) from employees where department_id in(30,50) group by department_id;
select department_id,avg(salary) from employees group by department_id having department_id in(30,50);
总结:
语法: select … from … where … group by … having … order by …;
顺序:
1.from — 确定数据来源表
2.where — 对来源表里进行数据筛选
3.group by — 对满足要求的数据进行分组
4.having — 对分组后的数据进行再次筛选
5.select — 按用户要求统计数据
6.order by — 按照一定顺序显示统计好的数据
4.伪列(rownum、rowid)
概念: 表里不存在的,通过select * 无法查询到的列
rowid: 在数据库里唯一标识一条记录,对记录所在空间的物理地址运算得到
rownum:数据库服务器会为每次出现在查询结果里的,满足要求的记录编号,从1开始
select *,row num,rowid from employees; -- error
-- 解决:
select employees.*,rownum from employees; --用表名修饰
select e.*,rownum from employees e; --用表的别名修饰
-- 请打印表里的前5行数据
select * from employees where rownum <= 5;
-- 请打印表里的第6到第10行数据
select * from (select e.*,rownum r from employees e where rownum between 1 and 10) where r between 6 and 10;
注意: rownum使用时必须从1开始用,>=1 =1 < <= between 1 and n;
select * from employees where rownum between 6 and 10; -- error
5.子查询
1)子查询结果是单行单列
-- 查询工资最高的员工信息
select * from employees where salary = (select max(salary) from employees);
2)子查询结果是多行一列(多个值)
-- 查询last_name是Taylor的员工所在部门下的所有员工信息
select * from employees where department_id in(select department_id from employees where last_name = 'Taylor');
3)子查询结果是多行多列
-- 查询工资排名最高的前五名员工信息
select * from (select * from employees e order by salary desc) where rownum <= 5;
4)关联子查询
通过表的别名进行区分查询
-- 请查询各部门工资最高的员工信息
select e1.* from employees e1 where e1.salary = (select max(salary) from employees e2 where e2.department_id = e1.department_id);
6.表连接
当结果数据来自于多张表时,需要通过一定的条件,讲多张表的记录合并成一行记录显示给用户
-- 打印员工的编号,姓名,工资,部门编号,以及所在部门名称
select e.employee_id,e.first_name||'_'||e.last_name name,e.salary,d.department_name from employees e,departments d where e.department_id = d.department_id;
1)内连接
使用inner join连接,inner 可以省略,使用on指定连接条件,其他判定条件沿用where
-- 打印60部门员工信息,以及所在部门信息
select e.*,d.* from employees e join departments d on e.department_id = d.department_id where e.department_id = 60;
注意: 内连接只会显示符合连接条件的记录,对于连接条件为null的记录直接舍弃,不在结果中显示
2)外连接
可以处理连接条件为null的记录
分类: a.左外连接: 在表连接的过程中,以"左表"为主(左表记录全部出现),右表辅助(没有对应的记录补齐空行),使用left outer join定义(outer可以省略)
b.右外连接:表连接时以"右表"为主,"左表"辅助,关键字 – right outer join
c.全外连接:表连接时两张表的记录全部出现,谁缺谁补,关键字full outer join
-- 打印所有员工信息,以及他们所在部门的信息
-- 左外连接实现
select e.*,d.* from employees e left join departments d on e.department_id = d.department_id;
-- 右外连接实现
select e.*,d.* from departments d right join employees e on e.department_id = d.department_id;
-- 全外连接实现
select e.*,d.* from employees e full join departments d on e.department_id = d.department_id;
3)自连接
通过为一张表定义两个别名的方式,模拟表连接
-- 请打印员工的姓名以及他的领导姓名
select e.first_name||'_'||last_name name,m.first_name||'_'||last_name name from employees e left join employees m on e.manager_id = m.employee_id;
4)多表连接
-- 打印员工详细信息,所在部门信息,以及所在的城市
select e.*,d.*,l.* from employees e left join departments d on e.department_id=d.department_id left join locations l on d.location_id = l.location_id;
7.sql命令的分类
1)概念区分
sql:结构化的查询语言,用来操作管理所有数据库数据的命令
plsql:oracle公司对sql命令的增强和改进
sqlplus:oracle提供的工具 - 操作工具命令
2)sql命令区分
dql - 数据查询语言 select
dml - 数据操作语言 insert update delete
ddl - 数据定义语言 create drop truncate alter
dcl - 数据控制语言 grant revoke
tcl - 事务控制语言 commit rollback
8.建表
1)合法标识符
a.由 字母 / 数字 / _ / $ / # 组成,其中数字不能开头
b.不能是关
键字,不区分大小写,字数控制在30个字符内
2)数据类型
a.数字类型(不区分整数和小数)
①number(n1,n2):有效位数为n1的数字,其中小数点后占n2位,n1最大取值为38,省略n2则表示整数
②number:一个很大的,数据库能表示的最大值,相当于java里的double
b.字符类型(不区分字符和字符串)
①varchar2(n):不定长字符串,最大可存储n个字节,存储时会根据实际值大小调整。n的最大值为4000
②char(n):定长字符串,不论实际值大小,一律分配n个字节的空间,n的最大取值4000
③nvarchar2(n):以字符为单位存放数据,n最大取值1333
c.日期类型:date(dd-mon-rr) timestamp
d.大数据类型:CLOB(字符大对象,4G) BLOB(二进制大对象,4G)
e:注意: java中的boolean类型,在数据库里通常使用数字"0或1"
3)约束类型
a.主键约束(primary key,简称pk) – 表里的唯一标识符,非空唯一,表里最多只有一个主键
b.非空约束(not null,简称nn)
c.唯一约束(unique,简称uk) – 通常也称为"唯一键",有值的时候值唯一,空值不在统计范围
d.外键约束(简称fk) – 通常使用关键字references定义,必须指向另一张表的"主键"或"唯一键"
e.检查约束(简称ck,也称为"自定义约束") – 使用关键字check(约束条件)
9.数据库里的其它对象
1)序列sequence
作用: 可以生成一系列唯一有序数值的对象,是一个公开的公共的对象
语法:create sequence 序列名;
start with num —起始值
increment by num — 步长
maxvalue num — 最大值
cycle | nocycle — 是否支持循环
cache num | nocache — 是否有缓存
drop sequence 序列名 — 删除序列
获取: 通过调用序列提供的一个变量nextval来获取序列里的值,一旦获取到值,值与序列再无关系
currentval 获取当前序列值,需要先调用nextval才能使用
2)视图view
概念: 一条起了名字的查询语句,视图没有数据,只有命令
创建: create view 视图名 as 查询语句;
删除: drop view 视图名;
作用:
1.简化查询,提高查询语句的复用性
2.帮助做表的权限管理
a. create view emp as select employee_id,last_name,… from employees;
b. create view boss as select * from employees;
c. 禁掉employees表的访问权限,对外提供emp和boss;
3)索引index
概念:是一个两列多行的表(对建立索引的字段值排序 — 值所在的物理位置rowid)
创建: create index 索引名 on 表名(字段名);
作用: 当建立索引的字段出现在查询条件里时,db server会自动应用索引提高查询效率
注意: 索引不是越多越好,浪费空间,降低增删改效率
oracle server 会默认为表里的"主键"和"唯一键"自动添加索引
10.事务(transaction)
1)概念
是操作数据库数据的最小单位,是由一组不可再分的sql命令组成的集合,事务的大小由实际的业务觉得。
2)原理
数据库服务器会为每一个连接上来的client,开辟一小块内存空间(回滚段),用来暂时缓存sql命令的执行结果,当事务结束时根据client的指令决定数据的处理方式,client发出commit指令(成功),则将回滚段的数据写入数据文件;client发出rollback(失败),则清空回滚段里的数据
3)边界
a. begin: 从写第一条sql命令的那一刻
b. end
①如果输入一组DML(insert update delete)命令,需要手动显示输入commit或者rollback结束事务
②如果输入一组DDL或者DCL命令,则命令成功后自动commit
③如果输入一组DML命令后退出client,正常退出做commit,非正常做rollback
4)数据安全 — 每一行记录都有一把锁(“行级锁”)
a. 写锁
oracle服务器会为事务操作过的记录自动添加"行级写锁",在锁没有释放之前,其它事务不能操作这条记录,在当前事务结束时,锁会被释放,然后随机分给一个等待锁的事务。
b.查询命令select不受行级锁的限制
c.读锁:在执行select命令时,手动获取行的锁标记
-- 查询时获取所有数据,并针对结果里的行进行加锁
select ... from ... for update;
-- 对查询结果加锁时,以nowait方式加锁(如果无法加锁,直接返回)
select ... from ... for update nowait;
-- 对查询结果加锁时,如无法直接加上,则等待num秒
select ... from ... update wait num;
5)事务的四大特性(ACID)
A(atomic):原子性: 组成事务的sql命令不可再分
C(consistancy)一致性:在事务运行中,数据的状态要与事务所做的操作保持一致
I(isolation)隔离性: 事务并发运行时,事务之间不应该互相影响
D(durable)持久性: 事务结束时,数据必须做"持久化"操作
二、JDBC
1.概念
是java程序连接数据库的桥梁,通过jdbc驱动java程序可以操作访问数据库软件
2.jdbc的组成
(1)接口:由sun公司定义,提供给程序员开发使用,已经在jdk里提供(java.sql包和javax.sql包)
(2)实现类:由数据库厂商提供,通过jar包的形式
ojdbc5.jar — jdk5/jdk6
ojdbc5.jar — jdk7/jdk8
3.搭建环境(导入jar包)
(1)普通文本编辑工具,将jar包所在路径配置到CLASSPATH环境变量里
(2)使用集成开发工具
①在项目路径下新建一个lib文件夹,将ojdbc6.jar拷贝到文件夹下
②右键选中jar包,选择build path,选择add to build path
(3)在myeclipse里配置数据库操作窗口
①菜单window --> show view --> others --> 搜索db browser --> 选中
②在打开的窗口右键 --> new --> 填表格
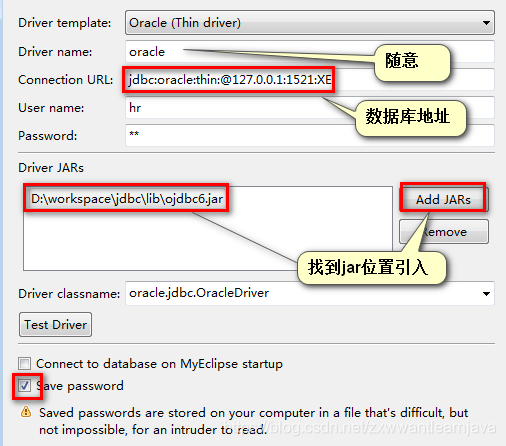
③在src目录下新建一个sql包,里面新建一个xxx.sql的文件
4.第一个jdbc程序
1)注册Driver(加载驱动)
Class.forName("驱动类的全类名");
注意: 可以在一个jdbc程序里注册多个Driver驱动类
2)获取数据库连接
代码: Connection conn = DriverManager.getConnection(地址,用户名,密码);
注意: 实际负责建立数据库连接的程序是Driver实现类,DriverManager只是一个工具类
地址解析

3)创建Statement(sql命令的传送工具)
代码: Statement stm = conn.createStatement();
4)执行sql命令(传送)
a. executeUpdate(sql): 用来执行inser update delete命令,返回int值(命令影响了几条数据)
b. executeQuery(sql): 用来执行select命令,返回值为ResultSet(结果集)
c. execute(sql): 可以用来执行所有的sql命令,返回boolean值(标记是否有结果集返回)
5)处理结果集
方法: next() / getXxx()系列

6)释放资源
注意: 资源释放按照生成顺序反向释放 rs — stm — conn
5.带参sql命令的执行
1)使用Statement执行带参sql
缺陷
①命令字符串的拼接比较繁琐
②sql注入

2)使用PreparedStatement执行带参的sql
① PreparedStatement是Statement的子接口,可以解决sql注入(字符串拼接)的问题
②使用
a.创建PreparedStatement对象(需要直接指定执行的sql)
PreparedStatement ps = new prepareStatement(sql);
ps允许指定半成品sql,允许在sql命令中使用?作为占位符来代替暂时不方便给定的值
b.为?设置值: ps提供一系列的setXxx();
ps.setInt(int index, Integer value);
ps.setString(int index, Stringvalue);
ps.setDouble(int index, Double value);
ps.setDate(int index, Date value);
c.执行sql
ps.executeUpdate()和ps.executeQuery()

6.工具类 – JdbcUtil
(1) java代码复用的基本原则
a.函数封装: 经常反复出现在程序中的一段功能代码(冗余代码),通过函数封装可以提高代码的复用性
b.尽量减少"硬编码": 将可能会发生改变的值直接定义在java程序中(值的改变会导致程序的重新编译),将改变的值定义在配置文件
(2)配置文件
概念: 用来保存程序运行过程中所需要的一些数据
a.文件类型: xxxx.properties / xxx.xml
b.properties文件格式: 每一行定义一个值,一行由两部分name和value,中间等号或空格连接
c.集合类Properties: 是HashTable的子类,主键和值默认都是String类型,处理properties文件的工具
Properties集合提供了load(字符输入了)函数用来读取保存配置文件的内容
(3)效率
a.将读取文件的代码写在static静态代码块中
b.改变流的获取方式 getConnection();
InputStream is = 类对象.getResourceAsStream(路径); //代表src的根路径
7.O-R mapping
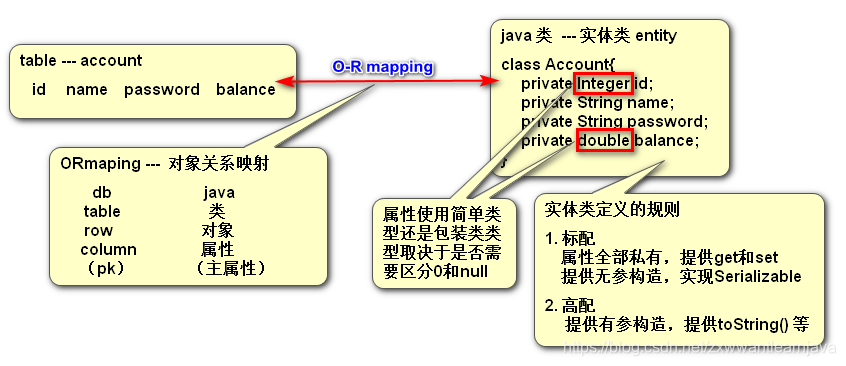
实体类的作用: 用来封装数据库数据, 属性名最好和表中字段名保持一致
函数的返回值: 正常情况必须返回指定类型的值, 非正常情况,异常对象可作为一种返回值形式来表示
8.DAO(date access object 数据访问对象)
作用: 完成对数据库里一张表所有数据访问操作(增删改查)
命名规范:
(1)为每一张表提供一个与之对应的dao程序
(2)定义dao接口,命名以dao为后缀
(3)为接口提供实现类,接口名+Impl
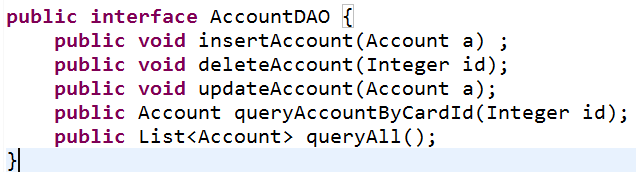
好处: 对调用者屏蔽底层数据库的差异
9.Service(业务层)
作用: 为了完成用户的一个具体的业务需求,需要定义函数来实现具体的业务过程(一定会落实到具体的数据库操作上)
(1)定义规则
a.每一个业务功能定义一个函数
b.程序命名规范"xxxxService" — 接口;实现类: “xxxxServiceImpl”
(2)Jdbc中的事务控制
a.jdbc中默认的事务提交策略为"一条命令提交一次" — 自动提交
b.手动提交API
① conn.setAutoCommit(boolean bn);true–自动提交 false-- 手动提交
一经设置,永久生效(在当前conn的生命周期中,一直有效)
②conn.commit(); conn.rollback();
(3)代码结构

(4)使用ThreadLocal对象解决service层事务控制问题
1.ThreadLocal : 线程局部变量,一个ThreadLocal对象可以为每一个线程保存一个独占数据
2.使用API
(1)创建对象ThreadLocal<独占数据的类型> tol = new ThreadLocal<>();
(2)存数据tol.set(数据);
(3)取数据tol.get() --> 独占数据
(4)解除与当前线程的绑定 tol.remove();
3.作用
(1)为一个线程锁定一个数据,使得我们在线程的任意代码组成部分里都可以获取到这个数据(一个数据)
(2)为不同的线程锁定不同的数据
(5)使用ThreadLocal改写JdbcUtil
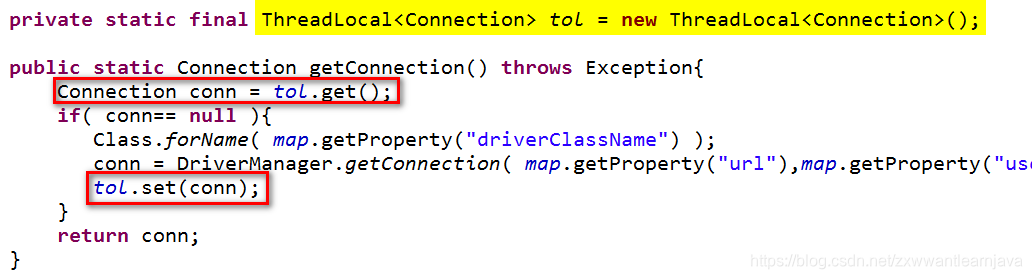
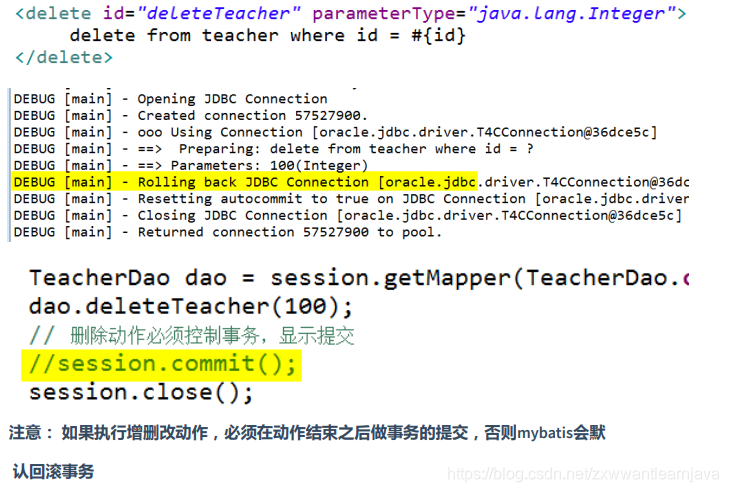
(6)理论上,conn应该在线程结束时被关闭,实际开发中,线程结束的位置不固定,一般会在事务结束时就关闭连接,关闭同时切记解除conn与当前线程的绑定关系(dao层函数不能关闭连接)


(7)业务层开发步骤
①获取数据库连接,并控制提交策略为手动提交
②完成业务功能(数据检验,数据库的访问操作 – 需要dao对象)
③提交或者回滚
④释放资源

10.项目结构

11.日期处理
// String转换成java.util.Date
System.out.println("请输入日期:");
String str = s.next();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date date = sdf.parse(str);
// java.util.Date转换成String
Date date = new Date();//获取当前时间
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh-mm-ss");
String str = sdf.format(date);
// java.util.Date转换成java.sql.Date
java.util.Date ud = java.util.Date();
long time = ud.getTime();//将java.util.Date转换成long类型
java.sql.Date sd = new java.sql.Date(time);
三、HTML
1. 概念
(1)标记语言:使用一些特殊的标记符号对所要展示的文本内容进行标记说明,不会发出任何机器指令,也不会体现具体的业务信息
(2)HTML超文本标记语言:对文本内容的显示样式,风格进行标记说明
(3)XML可扩展标记语言:对文本内容的含义进行标记说明
2. html说明
(1)使用html技术定义的文档,通常称为"网页",文件名会以 .html 或者 .htm为结尾
(2)可以使用任意文本编辑器开发html文件,使用浏览器解释执行(存在浏览器差异)
3. 基本语法
(1)使用“标签”的形式进行标记
<标签名> ---- 开始标签
标签体 ---- 文本内容 or 其他标签
</标签名> ---- 结束标签
注意:标签嵌套的顺序
特例: <标签名/> ---- 空标签(没有标签体的标签)
(2)标签可以有属性
<标签名 属性名=“属性值" 属性名=‘属性值’ 属性名=属性值> … </标签名>
例如: <hr color=“red” size=“3” width="90%“/>
(3)标记语言文档只能有一个“根标签”(所有内容必须都定义在根标签里)
4. 根标签
<html> --- html文档的根标签
<head> </head> --- 对文档的一些配置信息进行说明
<body> </body> --- 显示在浏览器窗口里的内容
</html>
5. head标签
用来对网页的特性属性进行说明定义,通常不会显示在浏览器的窗口里
1)<title> 定义网页标题,唯一一个有机会出现在窗口里的head标签
2)<meta/> 用来为网页定义特征属性
<meta http-equiv="content-type" content=“text/html;charset=GBK"/>
<meta http-equiv="refresh" content="3;url=http://www.baidu.com"/>
6. body标签
用来定义正文内容,可以显示在浏览器窗口里
(1)text属性:用来定义正文内容的颜色(英文单词 or 6位16进制数 RGB)
(2)bgcolor属性:背景色
7. 基础标签
1)注释标签: <!-- 注释的内容 -->
2)标题标签: <h1>.....<h6> 值越大字越小,自占一行(“块级元素")
3)标尺线 : <hr color="" size="粗细" width=”长度,百分比,像素px"/>
4)居中标签:<center> </center>
5)字体设置: <font color="" size="">
6)段落标签: <p>
7)特殊设置: <br/>换行 空格 < >
8)字体设置: <b> 加粗 <i>斜体 <s>删除线 <u>下划线 <sub> <sup>
9)跑马灯: <marquee scrolldelay="速度" direction=“方向 left right">
8. 列表标签
1)有序列表 : <ol type="A a I i"> ---- <li></li>
2)无序列表 : <ul type="circle square"> --- <li></li>
9. 图片标签
<img src="图片路径" width=“” height=“” align=“top,middle,bottom,left”/>
align属性:控制图片和后面文字的对齐方式
10. 超链接标签
语法: <a 属性> 提示文字
使用方法1:普通的超链接 【重点】
<a href=“目标资源的路径” target=“打开资源的窗口 _self _blank”>提示文字,图片
注意:_blank属性表示,开启一个新的窗口来展示目标资源
使用方法2:可以通过name属性定义“锚点”,通过超链接在一个网页的上下文之间跳转
1)使用标签定义锚点
2) 在网页第一版面定义普通的超链接,在href属性里指定锚点
11. 表格标签 【重点】
<table border=“粗细” bordercolor=“” width=“” height=“” align=“” cellspacing=“”>
<tr align=“文字水平对齐” bgcolor=“背景色”>
注意: 数据或者表格里需要展示的内容必须放在里。td里可以放任意html标签(图片,超链接,文字)
属性介绍
table --align: 设置表格与窗口边框的水平对齐方式,可选值 left center right
table -- cellspacing:各个td之间的间隔
align— 水平方向对齐, left center right
特殊属性: 单元格的合并
colspan: 横向跨多少个字段
rowspan:纵向占多少行
12. 表单标签【重点******】
1)概念
采集用户数据的网页元素
2)定义
<form action=“” method=“”>: 表单开始的标签
action— 用来指明表单数据提交给对方(server)哪一个程序处理
method— 表单数据的提交方式 , 可选值 get 和 post
1)get方法:用固定的格式将表单里的所有数据拼接到地址栏传递给对方程序
固定格式: 地址?name=value&name=value&......
缺陷:数据不安全,数据量少,中文乱码(地址栏)
get方法是表单提交的默认method值
2)post方法:通过数据包的形式向对方程序传递数据
优势:安全 , 数据量大 , 不容易出现中文乱码
3)常见的表单元素
1)文本框:<input type="text" name=""/>
–value: 定义默认值
–readonly:只读
–maxlength:限制文本框里可以输入的最大字符数量
2)密码框:<input type="password" name=""/>
3) 单选钮: <input type="radio" name="" value="表示的数据"/>
–如果需要两个或者两个以上单选钮具备排他性,需要为他们指定同样的name属性值
–checked属性:表示默认被选中
4)复选框:<input type="checkbox" name="" value=""/>
– 表示同一个含义的多个复选框需要定义同样的name
– checked属性:默认没选中
5)下拉列表:
<select name="">
<option value="背后的数据" selected> 网页显示的提示文字 </option>
</select>
6)提交按钮:<input type="submit" value="按钮上的提示文字"/>
7)重置按钮:<input type="reset" value="提示文字"/>
form元素补充
1)文本域:<textarea cols="列数" rows=“行数”>默认提示文字</textarea>
2) 日期框(H5):<input type="date,week,month,time" name="xxx"/>
3)数字框(h5):<input type="number" name="" value="默认值" min="" max=""step=""/>
4)email输入框(h5):<input type="email" name=""/>
5)隐藏框:<input type="hidden" name="" value=""/>属于表单的一部分,不显示,会提交
6)按钮标签:<input type="button" value="提示文字"/>
四、CSS
1.概念
cascading style sheet 级联样式表 ,层叠样式表
作用:在html标签的基础之上为网页添加更丰富的视觉效果和更简单的样式设置
使用:配合html标签(添加到现有的网页之中,为网页里的标签提供丰富的视觉效果)
2. 网页里嵌入css代码
1)行内样式 — 通过标签的style属性来设置css样式
<h1 style="样式属性名:值;样式属性名:值;...."></h1>
2)内嵌样式 – 集中统一将css代码定义在head标签里
语法: <head>
<title></title>
<meta ...... />
<style type="text/css">
选择器{ css代码 }
</style>
</head>
选择器:通过语法来限定标签
选择器常见写法
1)标签名选择器:直接通过标签名指定,适用于网页里的所有同名标签
h1{ background:blue }
2) 类选择器: 通过 .类名 方式定义样式 ,标签里需要使用样式的通过class属性指定
.c1{ background:green }
<h1 class="c1"></h1> <p class="c1"></p>
3) id选择器: 通过 #id值 方式定义, 标签里需要使用样式的通过id属性指定
#d1{ background:red }
<h1 id="d1"></h1>
4) 后代选择器: 选择器1 选择器2 这样的样式是为所有出现在选择器1里的选择器2定义
div #d1{ background:orange }
<h1> aaaaaaaaaaaaaaaaaa </h1>
<div>
<h1> bbbbbbbbbbbbbbbbbb </h1>
<p id="d1">
ccccccccccccccccccc
<h1>ddddddddddddddddddddddd</h1>
</p>
</div>
3)外部样式文件
特点:将css代码单独定义在一个以 .css为结尾的文件里,需要使用样式的网页通过
link标签引入
<link type="text/css" rel="stylesheet" href="xxx.css文件路径"/>
4)注意事项
当三种样式引入同时作用于一个标签上时,如果样式之间不冲突,那么效果叠加;如果有冲突,则采用就近原则,最终生效的优先级别是: 行内样式–> 内嵌样式 --> 外部样式文件
3. 常见属性
font-size : 字体大小
font-weight : 字体宽度
text-indent : 文本缩进
text-align : 文本位置
line-height : 行高
color : 颜色
border : 边框
background : 背景
4. 与css配合的标签
1)span标签
对一行内的少量文字进行样式设置,微调风格。标签本身没有任何样式,可以配合css为文字设置样式
2)盒子模型
a. 外补白margin : 指的是两个元素之间的距离
b. 内补白padding:指的是元素内容和元素边框之间的距离
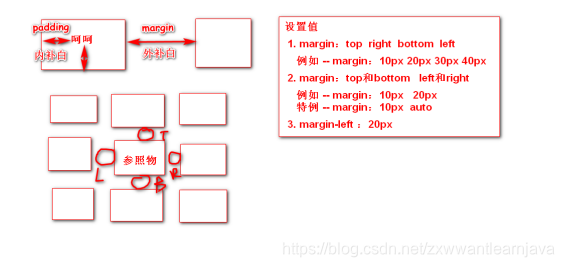
3)div标签
作用:代表了网页里的一块区域,是块级元素(自占一行),默认div会出现在当前文本的下一行,宽度整行,高度由内容决定。通常配合css做布局管理。
a) position: static(默认的),absolute,relative,fixed
absolute – 绝对定位后,会随着文档的滚动而移动
fixed:将div绝对定位到窗口的某一个位置,不会随着文档滚动而移动
b) float属性 1)一旦div设置了float属性,则它将脱离最底层(文档层),在浮动层分配空间 2)一旦设置了float属性,则div不再是块级元素 3)可选择: left right
五、Servlet
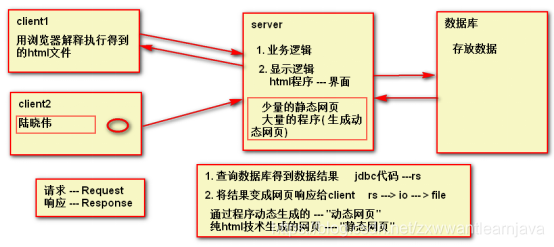
1.概念
Servlet : 运行在server上的 , 用java编写的一小段程序 . 可以接收client的http请求,
并按照要求为client做出响应( 一般以网页的形式体现 — 动态网页)
servlet : 一种生成动态网页的技术
2.将开发好的servlet程序部署到tomcat上
1)搭建环境 — 将开发所需各种资源引入到项目中
将tomcat/lib/servlet-api.jar引入到myeclipse项目中
2)实现Servlet程序的三种方式

HttpServletRequest — 代表client到server通道
HttpServletResponse ---- 代表 server到client的通道
3)web项目包作用图解

4)写配置文件web.xml

5)启动服务器,访问程序
http://ip:port/项目名/url-pattern
6)常见错误
- occurred at line xxx行 xxxx列
解决: 检查配置文件的xxx行xxx列是否写错 - 如果访问程序时报405错误
解决: 检查方法名service是否写错 - 如果访问程序时 , 浏览器做了下载动作
解决: 检查响应内容的类型是否正确 - 404或者500错误 ( 找不到资源 )
解决: 检查WEB-INF文件夹名是否正确
检查classes里是否部署的是.class文件
检查servlet程序是否正确继承了HttpServlet
检查web.xml文件中网名是否以”/” 开头
3.client向server发送请求的方式
1)地址栏手动输入程序的地址发送请求访问 ---- 访问首页
http://ip:port/应用名/资源的相对路径
a.访问的是html文件 资源相对路径指的是html文件的文件名
http://ip:port/应用名/day1/First.html
b.访问的是servlet程序 资源的相对路径指的是servlet程序的网名
http://ip:port/应用名/first
2)通过点击超链接发送请求
第一步: 在server上新建一个html文件,里面提供一个超链接
第二步: 将目标程序的地址封装在href属性里 , 供用户点击
<a href=”用户想访问程序的uri ”>
3)通过点击表单的提交按钮 完成请求的发送
第一步: 在html文件中提供一个表单
第二步: 将表单提交的程序地址封装在action属性中
<form action=”目标程序的地址 --- uri ”>
a. 获取表单提交(get或者post)的数据
String value = request.getParameter(“请求参数名 ---- 表单元素的name属性的值”);
b. 如果请求里含有中文 , 则通过以下方式设置编码
request.setCharacterEncoding(“UTF-8”);
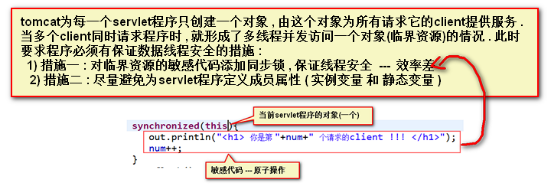
4. Servlet程序的生命周期
Servlet程序的生命周期由tomcat容器控制
- client发出请求 到 server做出响应 的过程

- 生命周期过程


5.采用myeclipse工具自动部署web应用
1.将需要使用的tomcat服务器软件配置在myeclipse工具中
① window菜单 show view others 搜索servers 选中
② 窗口右键 configure server connector 左边选中tomcat6.x 右边选择enable选中tomcat安装路径ok
③ 可以在myeclipse的servers窗口里启动和关闭tomcat服务器软件
2.开发具备自动部署能力的web应用
① 新建一个web项目
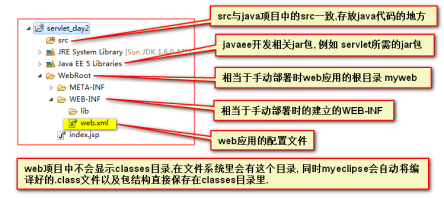
② 部署项目 — 自动部署
选中部署工具(工具栏) 选中需要部署的项目 选择部署的服务器 ok

6.多个servlet配合完成client端的一个请求
1)forward (请求转发)
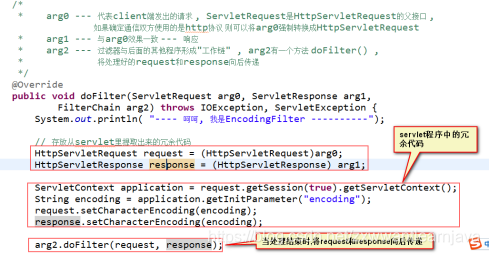
①代码
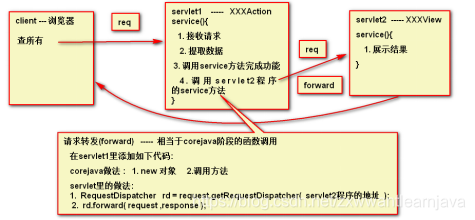
②数据传递

③forward工作方式的特点
a. 请求转发连接的多个程序之间处于一个request的生命周期
b. 请求转发发生在服务器程序内部 , client不知晓 ,地址栏不变, 与网页内容不匹配
c. 请求永久转向
d. 只在本应用内部程序之间跳转

2)请求重定向

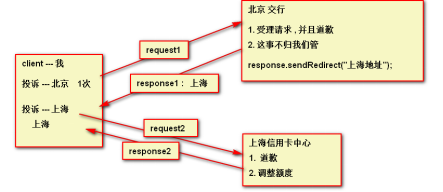
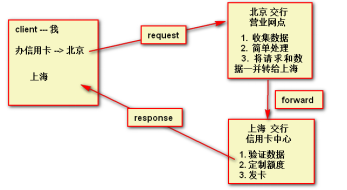


7.Cookie
1)概念
http协议 --> 一次连接协议、无状态协议
服务器写到浏览器软件上的一小段字符串, 由name和value组成 ( 不支持中文 ). 根据http协议的规定 , 服务器只能读取自己曾经写过的cookie.
2 ) API
在java中,一个Cookie对象代表了浏览器上的一个cookie .
① 写Cookie
创建Cookie对象 — Cookie c = new Cookie( name , value );
写Cookie — response.addCookie(c) ;
② 读取Cookie
Cookie[] cs = request.getCookies();— 如果没有cookie则cs为null
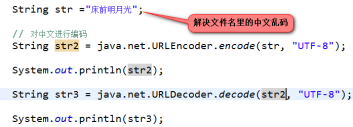
③ cookie的中文处理
java.net.URLEncoder.encode( str , 编码方式) ;
java.net.URLDecoder.decode(str, 解码方式);
④ 设置Cookie的存活时间
cookie.setMaxAge( time ) ;— time单位是秒
a. time为正数 — 存活时间
b. time为0 ,表示删除当前cookie. (读取cookie ,将存活时间设为0 , 将cookie写回)
c. time为负数 , 表示当前cookie会一直在浏览器上存活,直到浏览器关闭
8.HttpSession
会话 , 代表同一个浏览器和server之间的一次完成通信( 包括多次请求 )
1) 是一个作用域 , 可以存放命名属性
存数据 session.setAttribute(“name”, value );
取数据 Object value = session.getAttribute(“name”);
移除数据 session.removeAttribute(“name”);
2) 获取HttpSession对象
HttpSession session = request.getSession( true );
3) 特点
① 生命周期长
begin 用户所访问的程序里第一次出现getSession(true)时 , tomcat会为用户创建
session对象.
end timeout(有效时间内,用户没有发起任何操作) , 默认为30分钟

② 一个用户一个HttpSession对象( 用户特指浏览器软件 )

注意: 保存sessionId的cookie叫做"JSESSIONID", id的值为32位16进制数
保存sessionId的cookie 默认存活时间为 ”负数”

4) 使用场景
① 强制登录验证
第一步:在登录成功的分支里,添加代码(向session中存放一个登录标志)
第二步: 在后面需要验证的程序开始 , 添加代码( 获取session中的登录标志 ,如果
没有,则跳转到登录页面)
② 各种退出( 安全退出 关闭浏览器退出 )
安全退出 : 编写一个程序,在程序中调用invalidate方法注销session
关闭浏览器退出: 在浏览器关闭时, 用来保存sessionId的cookie会随之销毁( cookie
的存活时间是负数) , 下一次访问无法得到原有session.
③ 用session来在重定向过程中传递数据
简单数据(String) 将数据拼接到uri之后带到下一个程序( 数据量少,容易出现乱码)
复杂数据 将数据存入session带到下一个程序. (用完后及时移除数据)
5)关于session的有效存活时间长短
① 安全角度 — 时间短 , 时间到销毁session
② 内存使用角度 — 时间短 ,时间到将session以及里面的相关内容写入文件(内存置换)
问: 为什么实体类需要实现Serializable接口?
方便将数据写入文件中
9.ServletContext
1)是web.xml文件在内存中体现
① tomcat启动时,会默认去读每一个web应用的配置文件 , 并将读到的内容封装成
ServletContext对象保存在内存中 . 一个web应用只有一个ServletContext对象.
② ServletConfig对象 : 封装了配置文件中一段关于一个servlet的配置信息
③ 获取对象
ServletContext application1 = this.getServletContext() ;
//此处this指当前servlet程序对象
④ 使用场景 ( 不重要 )
a. 将个人数据加入到配置文件中

b. 程序中如果需要使用

2)是一个作用域
① 存放命名属性
setAttribute(name,value) --- 存
getAttribute(name) --- 取
removeAttribute(name) --- 移除
② 特点
a. 生命周期长 : tomcat启动 tomcat关闭
b. 共享范围 : 被当前应用的所有程序共享 ( 谨慎使用 )
③ 获取方式
ServletContext application2 = session.getServletContext() ;
application2 == application1 true
3)三大作用域的比较

10.连接池
1)连接池(Connection pool) : 用来存储管理数据库连接的对象

2)在tomcat里配置连接池信息 , 使得tomcat启动时建立连接池
编写 tomcat/conf/context.xml
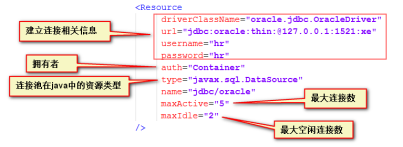
3)通过代码获取数据库连接


4)配置tomcat连接池的两种不同方式
① 编写tomcat/conf/context.xml文件 , 将ojdbc5.jar放置在tomcat的lib目录里
连接池一旦配置成功 , 可以被所有web应用共同访问
② 将编写好的context.xml文件粘贴到web project的META-INF目录里, 并将ojdbc5.jar
放置在web应用的lib目录里, 此时连接池就只能被当前应用所使用
11.过滤器
1)对于servlet程序中的通用基础代码( 反复出现的功能代码 ) 的处理
① corejava — 封装成函数,在需要的位置调用
② servlet — 封装到过滤器程序中,统一处理 .
对请求和响应的预处理 , 在request到达servlet之前 , 在响应回到client之前 , 执行
过滤器代码
2)定义过滤器
① 写程序 ---- implements Filter接口
② 写配置文件

3)当请求需要通过多个过滤器时,会按照配置文件中过滤器声明的先后顺序通过。
4)默认过滤器只会过滤来自于client端的请求,不会理睬其他方向的请求。通过配置可以
定义过滤什么方向的请求。
<filter-mapping>
<filter-name></filter-name>
<url-pattern></url-pattern>
<dispatcher> REQUEST FORWARD INCLUDE </dispatcher>
</filter-mapping>
5)关于url-pattern的多种写法
① 如果需要过滤少量的servlet请求 — 可以写多个url-pattern标签,列出所有被过滤
的请求的网名
② 如果需要过滤client端的所有请求(html,jsp,servlet,image,css) — /*
③ 如果需要过滤大量的servlet客户端请求(不是全部)— 通过为网名添加前缀的方
式解决
LoginFilter —> /protected/*
LoginAction —》 /LoginAction
QueryAllPersonsAction —> /protected/QueryAllPersonsAction
UpdatePersonAction ---->/protected/UpdatePersonAction
④ 如果需要过滤所有的servlet请求,不包括html或者jsp请求 — 通过为网名添加一
个特殊的后缀解决 *.action
/myweb/Error.html
/myweb/index.jsp
/myweb/first.action
12.监听器(Listener)
1)监听事件模型 : 事件源(source) 事件对象(event) 监听器(listener)
当事件源产生特定的事件对象时,会触发监听器代码运行
2)Servlet里的监听器
① 生命周期监听器 — 监听三大作用域的创建和销毁事件
ServletContextListener HttpSessionListener ServletRequestListener
② 作用域里的命名属性监听器
ServletContextAttributeListener ServletRequestAttributeListener
HttpSessionAttributeListener
3)编程
① 写程序
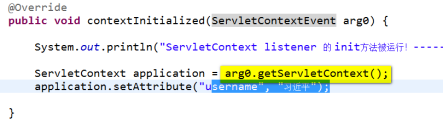
② 写配置文件



六、JSP
1.概念
Jsp(java service page),是一种生成动态网页的技术
2.文件特点
① jsp文件必须以.jsp为结尾
② jsp文件可以放置在web应用目录下的任意位置(除了WEB-INF — 目前)
Jsp和servlet的表现形式上的区别
① jsp --> 在大量的html标签中嵌入少量的java代码,html标签比重大 – XXView
② servlet --> 在大量的java代码中嵌入少量的html标签,java代码比重大 – XXAction
3.Jsp的原生标签:脚本 指令 动作
① 脚本元素:用来向jsp页面里嵌入“纯java代码”的标签



如何保证jsp页面里的数据的线程安全?
尽量避免在声明脚本里定义变量(线程不安全)!
4.指令元素:页面 包含 标签库
① 页面指令 <%@page %>:利用标签的属性描述jsp页面信息 【重点】
语法:<%@page 属性=”值” 属性=“值” … %>


② 标签库指令:<%@taglib uri=”” prefix=""%>【重点】
③ 包含指令(不重要):<%@include file="jsp文件路径" %>
作用:将指定的jsp的“源代码”包含到当前jsp页面里,也成为“静态包含”
使用:主要用来在jsp领域做“代码复用”
注意:不建议使用,复用场景单一,如果定义成普通的java类,复用机会更多
5.动作元素:包含动作 转发动作
① 包含动作 — <jsp:include page=”下一个资源的网名” />【重点】
功能:将其他网页资源的输出结果包含到当前jsp页面的输出结果里(合并输出),
也称为“动态包含”。
使用:主要用来做复杂页面的显示
Filter —》 默认只过滤client —》 <dispatcher> REQUEST FORWARD INCLUDE</dispatcher>
② 转发动作 — <jsp:forward page=”下一个资源的网名” />【了解】
功能:将请求由当前jsp转发到下一个指定的资源 ( 等价于servlet里的forward )
写法:
Servlet --》request.getRequestDispatcher(“网名”).forward(request,response);
Jsp --> <jsp:forward page=”下一个资源的网名” />
注意:<% response.sendRedirect(....); %>
6.Jsp里的隐含对象(内置对象)
① 概念:jsp页面里一直存在的,起好名字的,可以被直接使用的对象。
② 九大内置对象
1)request ---- HttpServletRequest
2)response ---- HttpServletResponse
3)session ---- HttpSession
4)application ---- ServletContext
5)config ----- ServletConfig (代表配置文件中的一段servlet标签)
6)page ----- this (代表当前jsp翻译成程序后创建的对象)
7)out ---- JSPWriter ( 相当于servlet里的PrintWriter )
8)exception ---- Exception (只有isErrorPage=true的jsp页面里有)
9)pageContext ---- PageContext (jsp特有的对象,功能最强大的)
③ 隐含对象的本质
隐含对象实际上是service方法的局部变量,tomcat在翻译网页代码前,会在service方法里提前定义一组局部变量,然后才是网页内容翻译,所以在网页内容里可以使用这些局部变量。
注意: 声明脚本的代码不会出现在service方法里,不能使用隐含对象。
④ PageContext对象
1)是一个作用域,可以存放命名属性
setAttribute(name,value) getAttribute(name)
特点:生命周期最短(只在当前页面内生效),用来在jsp技术和内嵌(EL,用户自定义标签)的其他技术之间传递数据。
2)可以管理其他三个作用域

3)获取其他八个隐含对象
getRequest getSession getServletContext 。。。。。
4)可以做forward和include
7.EL(expression language)表达式语言
① 知识储备 — 干净的jsp要求(尽量减少脚本标签的使用)

② 准备
1)语法: ${ EL表达式 }
2)提前声明: <%@page isELIgnored=”false” %>
③ 功能
1)可以做普通的表达式计算
<%=1+1%> — ${1+1} ${3>4} — ${3 gt 4 }
${ a==null } — ${ empty a }
语法:通过关键字param实现, ${ param.请求参数名}
例如:

2)可以获取“作用域”里的命名属性,并且默认输出到浏览器 【重点】
语法:通过关键字 pageScope requestScope sessionScope applicationScope实现
${ xxxxScope.命名属性名 }

3)可以获取对象的属性,并且打印输出 【重点】
语法: ${ 对象. 属性名 }

4)可以获取浏览器上的cookie对象
语法:通过cookie关键字完成
${ cookie.cookie的名字 }–》cookie对象
${ cookie.cookie的name.value }–> cookie的值
例如:${ cookie.JSESSIONID.value }
5)可以访问配置文件中的“初始化参数”
语法:通过initParam关键字完成 ${ initParam.参数名 }
6)可以直接获取集合(List和Map)里的一个元素
List —》 第二个元素 --》 ${ list[1] }
Map —> 获取主键“one”对应的值 —》 ${ map.one }<–> ${ map["one"] }
8.JSTL(jsp standerd tag library)JSP标准标签库
① 知识储备
1)概念(用户自定义标签)— 用户根据功能需求自己研发的标签
2)自定义标签步骤
第一步:定义一个程序实现固定的接口(例如SimpleTag)
第二步:定义一个配置文件 xxx.tld (是一种特殊的xml文件)
第三步:将程序和配置文件部署到tomcat上(部署路径与原来一致)
② JSTL
1)apache组织里的一组程序员根据开发中所需要的通用基础功能开发的一组用户自定义标签,所有标签被划分成若干个子库(core sql fmt … )
2)将标签库的相关jar包引入到项目中
3)在jsp开始通过标签库指令引入需要的标签库
<%@taglib uri="标签库的名" prefix="简称" %>
Prefix:标签库的简称,用来区分不同标签库里的同名标签
③ JSTL里常见标签 【重点】
1)<c:if> ---- 条件判断标签
语法: <c:if test="boolean值"> 标签体 </c:if>
如果test属性值为true,则执行标签体里的代码,否则跳过。
注意:标签可以嵌套,可以通过if标签对html标签的属性是否存在进行控制
2)<c:forEach>---- 循环标签
第一个功能: 遍历集合( 所有集合 List Set Map )


第二个功能: 简单循环

3)<c:set> 定义变量的标签
①<c:set var="变量名" value="值" scope="page|request|session|application"/>
注意:只有String,int和boolean类型值可以直接赋值给value,其他值必须通过EL
获取后赋值给变量
Scope属性表示变量一旦被创建成功,会默认保存在某一个作用域里,成为
命名属性,如果省略了scope,则表示默认存放于pageContext作用域
② <c:set var="" scope="">值</c:set>
4)<c:remove var="" scope=""/>移除指定作用域里的指定的命名属性,如果省略scope属
性则表示移除所有 作用域里叫var的命名属性
5)<c:redirect url="网名"/>在jsp页面里请求重定向
6)<c:out value="" excapeXml="true|false"/>将给定的value值输出到浏览器上
7)<c:import url="" var=""/>相当于<jsp:include>, 可以将任意一张网页包含到当前页面里
8)<c:url value="网名">
① 可以将给定的网名变成uri,自动补齐应用名
② 自动检测浏览器是否支持cookie,如果不支持则自动将sessionid拼接到地址栏带入下一个程序
通过<c:param name="" value="">子标签完成请求参数的拼接
9.MVC编程思想
① 概念:在开发设计一个软件的时候,人为的将软件代码划分成3个组成部分M(module)模型,V(view)视图 , C(controller)控制。
② 使用:
M(module) — service + dao
V(view) ---- jsp + html
C(controller) — servlet(xxxAction)
class XXXAction{
//1. 收集请求里传递的数据 — 接收请求
// 2. 调用service层的方法完成功能
// 3. 根据结果控制跳转
}
③ 好处
1)各司其职,便于程序员协同开发,提高开发效率
2)弱耦合,便于软件的升级维护( 分层 ,interface ,反射 ,配置文件 )
④ 现有MVC的缺陷
1)dao代码冗余大(代码相似度90%)
2)现有的servlet开发的action程序有缺陷 – 控制器

七、Struts2框架
1.简介
1)框架:软件开发中的“半成品”,是对现有的通用功能代码的封装,提高代码的复用
性,提高软件的开发效率。
2)struts2框架:由apach组织开发的开源的,基于MVC的框架。提供一种新的控制器
Action,用来替换原来的servlet控制器。

2.搭建环境
1)引入struts2框架所需要的各种jar包(自己的,依赖的第三方jar包)
2)将struts.xml配置文件放置在src根目录下
3)初始化配置 — 配置核心过滤器(在web.xml文件中配置)

4)特有的 — 设置开发环境的编码( struts2框架默认UTF-8 )
① 在web项目上点击右键 – 选择properties
② 修改编码( 修改了当前项目的编码 )
5)写配置文件

3.跳转方式
转发到 jsp (默认): <result name="xxx" type="dispatcher">/xxx.jsp</result>
重定向到 jsp : <result name='xxx' type="redirect">/xxx.jsp</result>
重定向到 Action : <result name='xxx' type="redirectAction">xxx</result>
重定向到 jsp : :<result name='xxx' type="chain">/xxx.jsp</result>
4.收参
1)以单个数据的方式收集请求参数
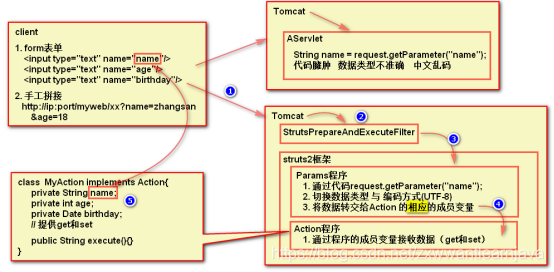
注意:
- 中文编码只能处理 表单post提交的中文,默认UTF-8编码
- 能够处理的日期格式必须为 yyyy-MM-dd
2)以对象的形式收集请求参数
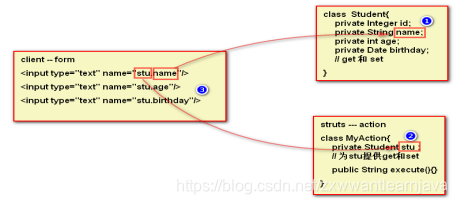
3)以集合或者数组的形式收集请求参数 — 复选框

5.扩充知识
1)在Struts的Action程序中如何获取servlet里的常见对象?
Struts2框架里提供了一个工具类 ServletActionContext ,通过这个类可以获取servlet里的常见对象。
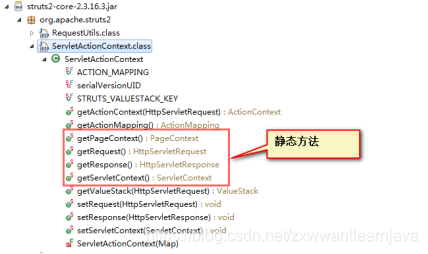
2)Struts里一个Action会产生多少个对象?
Servlet程序只有一个对象产生,由这个对象为所有请求服务,servlet是“单例”(便于tomcat管理少量的程序对象)
Struts2框架会为每一个请求创建一个action对象,在struts框架里action是多例( 收参 )
3)在myeclipse里配置xml文件的dtd文档,使得myeclipse可以“联想”(Alt+?)
① 将dtd文档放置到项目目录下
② window菜单 --> preferences --> 搜索xml catalog --> 选中
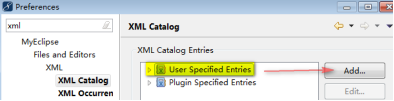
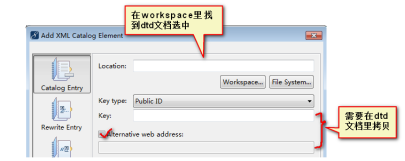
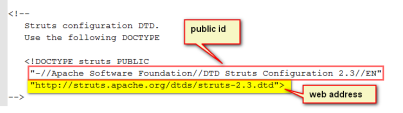
重启Myeclipse生效
6.package标签
1)作用
用来在配置文件中,对action的配置信息“模块”化管理,不影响程序的访问和功能。
2)namespace属性:用来对client端的请求地址url进行“功能模块”管理,便于后期维护功能的添加。

注意:同一个namespace下的action之间跳转时,不需要指定namespace,直接给action的网名即可
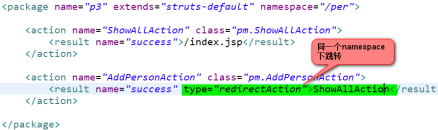
3)跨namespace跳转[重点]

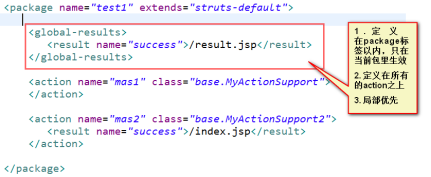
4)全局跳转
7.实现Action类的方式
1)第一种方式: class MyAction implements Action{ execute(){ … } }
2)第二种方式: class MyAction extends ActionSupport{ 默认的execute实现 }
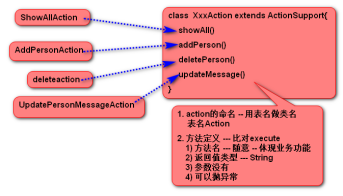
8.DMI(dynamic method invoke)动态方法调用
1)Struts框架允许在一个Action程序中,定义多个方法,以应对用户不同的功能需求。减
少开发中action的数量,便于后期维护。
注意:action程序最好继承ActionSupport(不用再定义execute方法)所有业务方法(名字与execute不同,其他位置完全一样)
2)开发步骤
① 写程序 : 将多个相关业务功能代码集中在一个action中完成
② 写配置文件
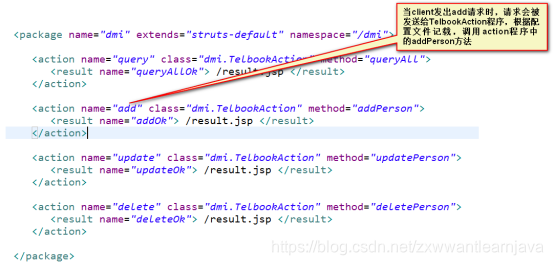
总结:DMI只是减少了action程序的数量,没有减少代码,也没有减少配置信息。
3)DMI支持通配符的写法 (不重要)
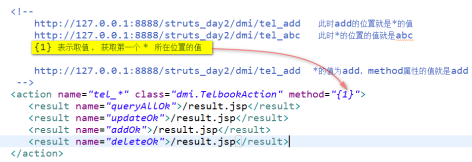
特殊使用
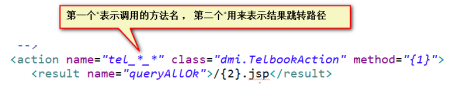
DMI通配符模式下的跨包跳转

关于DMI方式下的请求参数收集问题

9.拦截器
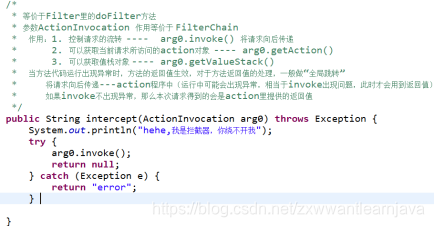
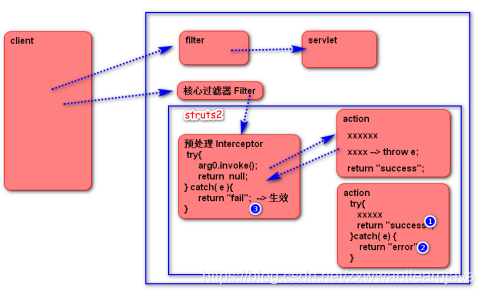
1)概念
将action程序中的冗余代码(通用功能)提取出来,放在拦截器里完成(在请求到达action程序之前或者响应离开框架之前执行),等价于servlet里的过滤器。
注意:拦截器是双向拦截(拦截request , 拦截response)拦截器属于struts框架,只会拦截action请求,不会考虑jsp
2)代码
① 写程序 : 实现Interceptor接口
② 配置文件 struts.xml
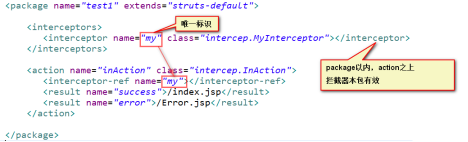
注意:
① 如果希望代码在action运行之后执行,可以将代码放置在invoke调用之后。
② 如果自定义了拦截器,并且在action中引用了自定义拦截器,则struts框架不再为程序提供默认拦截器(Params)
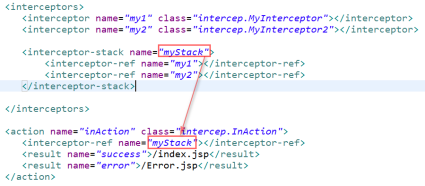
3)拦截器栈
作用: 当一个action程序需要通过多个拦截器时,为了简化声明,可以将多个拦截器做成拦截器栈,在action中引用
4)默认拦截器栈
如果一个package标签中的所有action都需要使用同一个拦截器栈,可以将这个拦截器
栈设置为默认拦截器栈,一旦设置,会对本包中的所有action生效
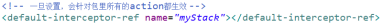
5)Struts框架下的拦截器体系(系统默认拦截器 用户自定义拦截器)
问题:一旦用户自定义拦截器,则系统默认的不再生效(Params)
解决:在自定义的拦截器栈里引入系统默认拦截器栈

延伸:
1)在struts框架里添加拦截器的步骤
第一步:自定义拦截器,并在配置文件中声明
第二步:自定义拦截器栈,将自定义拦截器,以及系统默认拦截器栈绑定到当前栈里
第三步:将自定义拦截器栈在配置文件中声明为 “默认拦截器栈”
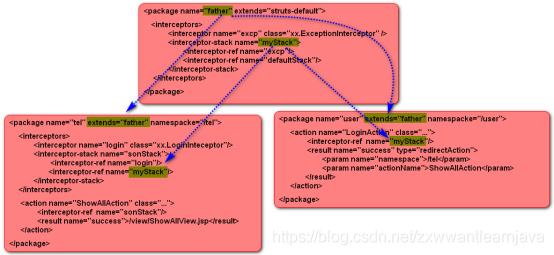
2)package的继承关系带来的启发
第一步:在配置文件中先定义一个package标签,在package里定义一些拦截器栈
<package name=”father” extends=”struts-default”>
第二步:在功能性package标签里,继承father
<package name=”myson” extends=”father”>
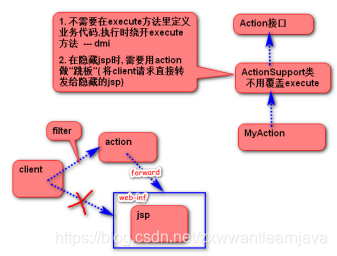
10.对于jsp文件的安全问题
1.拦截器只会拦截action请求,不考虑jsp,所以为了jsp的安全,可以将jsp由webroot下转移到WEB-INF目录里。
2.WEB-INF里的文件不能在地址栏直接访问(不能在程序里重定向,只能forward跳转)
3.定义一个action程序继承自ActionSupport(不用给定任何代码)
4.在配置文件下做如下声明:
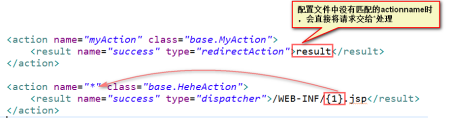
11.文件上传

开发步骤
-
定义一个jsp文件,在文件中提供表单File元素,可以选择上传的文件
注意:
1)表单标签form有一个默认属性enctype="application/x-www-form-urlencoded"
表示表单提交的数据,服务器端是可以通过request.getParameter()方法接收的
2)如果上传的数据不是普通表单元素(String),则需要修改enctype属性
enctype="multipart/form-data" -
在tomcat应用目录下新建一个文件夹用来保存用户上传的文件“upload”
-
开发接收文件的Action程序
第一步:修改文件名
在Action中提供一个属性用来收集上传文件的文件名,属性名字必须叫做
xxxFileName(xxx是File属性的名字),提供get和set方法。同样的做法
还可以收集 xxxContentType(上传文件的类型)

第二步:修改上传文件路径(定义在配置文件中)
Struts允许在配置文件中为action定义参数,action程序中通过定义同名的实
例变量来获取这个参数。



第三步:修改tomcat所在位置的绝对路径
ServletContext里提供了一个工具方法getRealPath(),可以获取tomcat服务器
所在位置的绝对路径。

2)文件读写的改进
在org.apache.commons.io.FileUtils的工具类,里面含有工具方法copyFile( src, dest)
参数一:需要被拷贝的源文件 参数二:目标文件
4. 实战建议 — 关于上传文件路径的处理
建议为每一个用户建立一个文件夹,用来保存该用户上传的文件,文件在命名时,遵
循 “用户名+文件名+系统时间+文件后缀”。


5. 关于文件的大小
Struts默认只允许上传2M以内的文件,如果需要改变大小,则添加以下配置
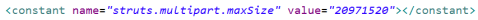
注意:配置信息在
12.文件下载

开发步骤:
- 提供一个jsp页面,在页面里定义下载文件的超链接(含有下载文件的文件名)

- 在struts.xml文件中通过标签定义下载文件所在路径

- 写程序
1)要求程序最好继承自ActionSupport
2)提供一个名字固定的方法 getInputStream()

3)对于输出流,不在代码中体现,会体现在配置文件中(struts框架已经封装好了一个
结果类型叫stream,直接应对输出流) - 写配置文件

- 设置信息的查找位置
13.图片验证码
- 作用:安全,减缓网站的访问压力
- 组成:随机数 + 图片背景
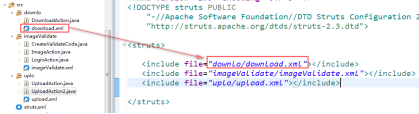
- Struts配置文件补充
将配置信息分别定义在不同的xml文件中, 在总的struts.xml里引入
八、mybatis框架
1.简介
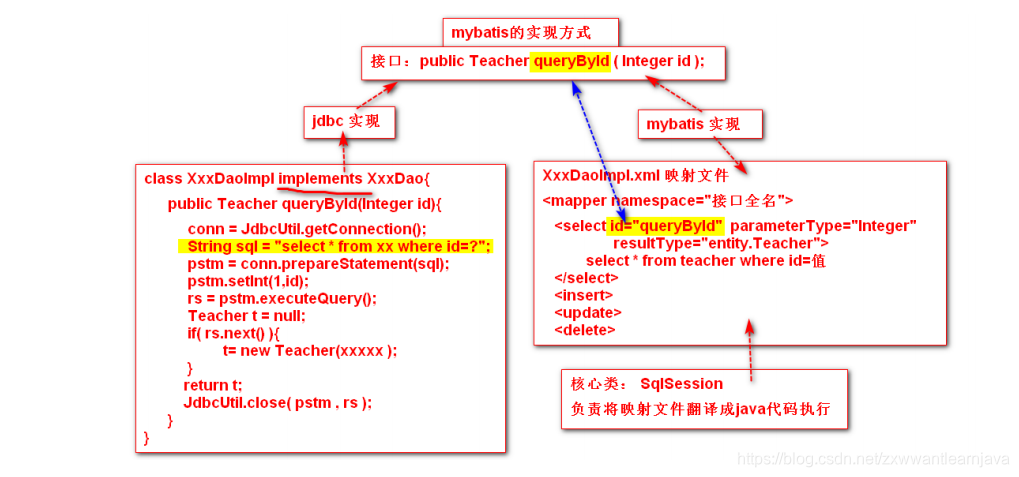
1)是一种基于java的框架,对原有jdbc代码进行封装,用来优化数据持久化操作。
2)提供了一种新的jdbc代码的实现方式来解决原有jdbc的缺陷
2.搭建环境
1)引入jar包
mybatis-3.2.2.jar ojdbc6.jar log4j.jar(不是必须的,做日志输出的jar包)
2)引入配置文件 — src下
mybatis-config.xml(文件名随意) log4j.properties
3)做初始化配置 — mybatis-config.xml
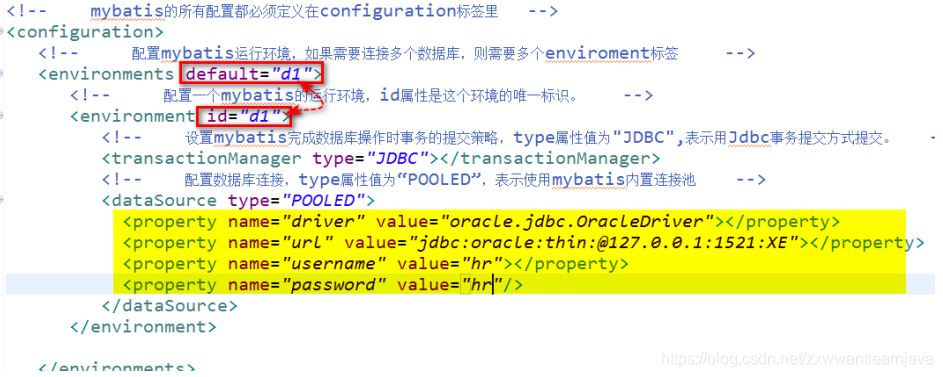
3.写映射文件
① 查询

② 删除
③ 添加
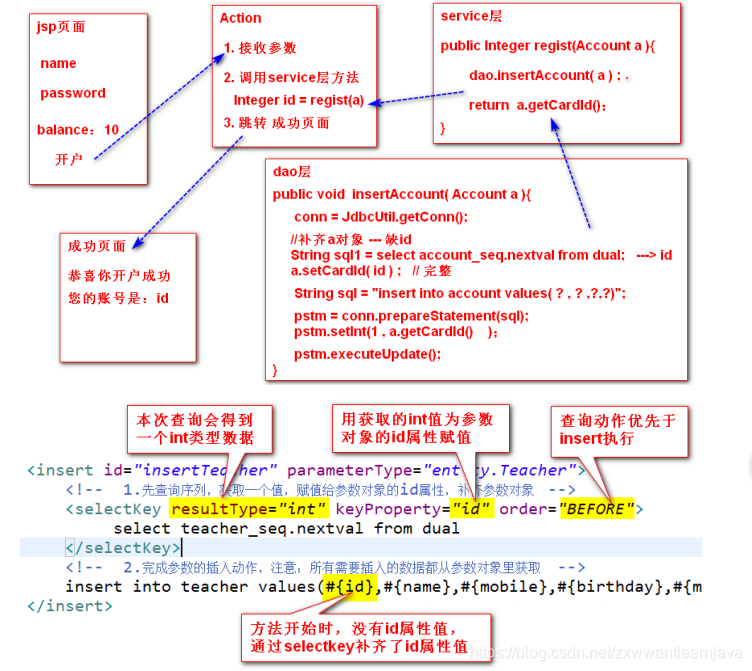
④ 修改

⑤ 查所有

4.注册映射文件

5.service层代码
1)mybatis里的核心类

2)代码开发
//1.创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//2.获取读文件的字符流对象(文件路径从src开始写,不能以/开头)
Reader reader = Resources.getResourceAsReader("文件路径");
//3.获取SqlSessionFactory对象
SqlSessionFactory factory = builder.build(reader);
//4.获取SqlSession
SqlSession session = factory.openSession();
//5.获取dao接口的实现类对象
XxxDao dao = session.getMapper(XxxDAo.class);
6.DBUtil类的封装
代码类似于JdbcUtil工具类
- Mybatis启动时需要读取配置文件(只读一次),将代码定义在static{}
- SqlSession里封装了Connection,特点与Connection完全一致,需要保证一个线程只能得
到唯一一个SqlSession,引入ThreadLocal - 进阶版封装 — 对service彻底屏蔽底层实现技术,达到解耦合的目的
package utils;
import java.io.IOException;
import java.io.Reader;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
public class DBUtils {
private static SqlSessionFactory factory;
static {
// 1.创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
try {
// 2.获取文件的字符流对象
Reader reader = Resources.getResourceAsReader("mybatis-config.xml");
// 3.获取SqlSessionFactory对象
factory = builder.build(reader);
} catch (IOException e) {
e.printStackTrace();
}
}
private static final ThreadLocal<SqlSession> local = new ThreadLocal<>();
public static SqlSession getSqlSession() {
try {
if (local.get() == null) {
SqlSession session = factory.openSession();
local.set(session);
}
} catch (Exception e) {
e.printStackTrace();
}
return local.get();
}
public static void close() {
SqlSession session = getSqlSession();
if (session != null) {
try {
session.close();
local.remove();
} catch (Exception e) {}
}
}
public static <T> T getDao(Class<T> a){
SqlSession session = getSqlSession();
return session.getMapper(a);
}
public static void commit(){
SqlSession session = getSqlSession();
session.commit();
close();
}
public static void rollback(){
SqlSession session = getSqlSession();
session.rollback();
close();
}
}
7.映射文件的特殊写法
① 多参查询
1)参数类型复杂或者参数不止一个时,可以省略parameterType
注意:mybatis不支持dao接口里的方法重载
2)方法的形参名不能长时间保留,在编译的过程中丢失,不能在映射文件中使用
3)简单解决方法

4)正规解决方法
通过注解,为参数定义一个可以被jvm访问的名字

② 特殊符号的处理
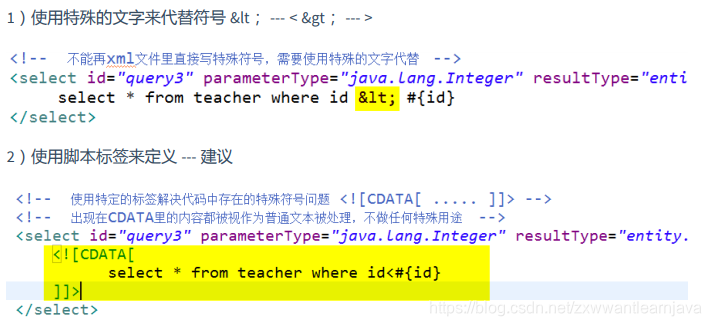
注意:多数脚本语言都会用CDATA标签解决特殊符号问题
③ 模糊查询
1)可以在映射文件的sql命令上,使用 || 来拼接通配符

2)在dao方法被调用的时候,对实参进行字符串拼接
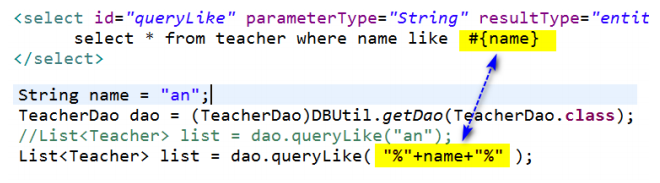
④ 分页查询
1)将需要计算的值定义成参数

2)将所有分页相关的数据封装成PageBean对象(实体类对象),将begin和end的计算
做成实体类对象的两个get方法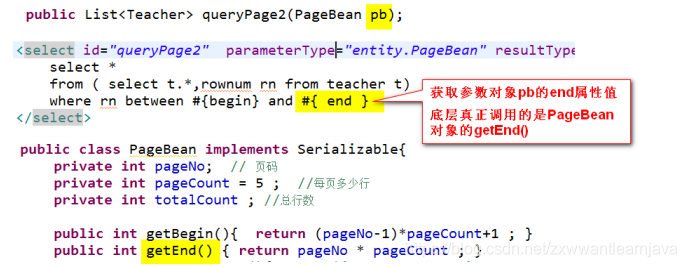
3)如果参数是两个以上对象

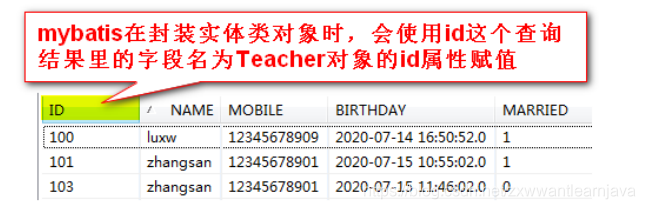
⑤ 字段名和属性名不一致
1)mybatis在封装查询结果数据时(实体对象),采用“查询结果里的字段名”,去为实
体类对象的“同名属性”赋值,如果没有找到同名属性,则赋值失败(为null)
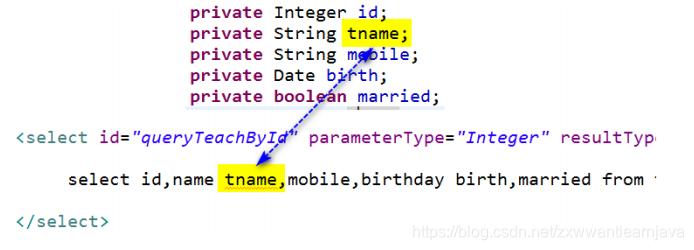
2)当实体类属性名与查询结果里的字段名不一致,解决:可以在查询命令编写过程
中,为字段定义“别名”,要求别名必须与实体类的属性名一致
⑥ 插入过程中null值处理

8.配置文件的优化 --mybatis-config.xml
① 简化实体类类名
1)mybatis允许在配置文件里为实体类entity统一定义“简称”或者“别名”,可以在映射文
件中使用。
2)使用标签定义

② 数据连接参数的定义
将配置文件中数据库连接信息所需要的参数定义在独立的小配置文件里,在mybatis的配置文件
中通过标签引入使用
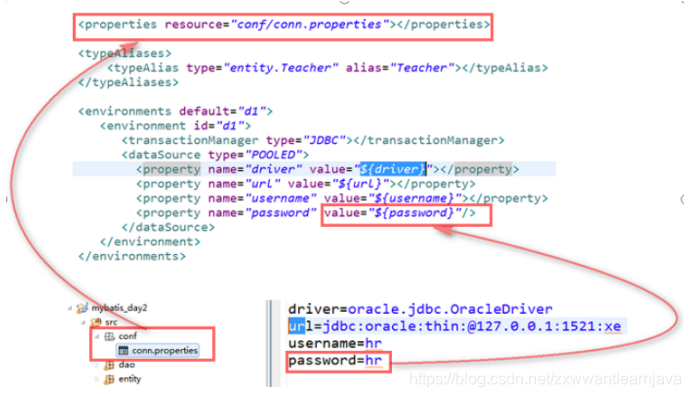
标记文档中的各种取值方式:
1.jsp页面里的EL表达式取值 — ${xxxScope.name}
2.mybatis的映射文件里获取参数对象的属性值 — #{ name } — PreparedStatement
3.mybatis映射文件中还可以使用 — ${name} — 底层使用的是Statement (sql命令字符串拼接)
4.mybatis配置文件中获取小配置文件定义的值 — ${xxxx}
5.struts2.xml文件中获取action程序的实例变量 — ${实例变量}
6.struts2.xml文件中DMI的通配符配置方式 — {1} 获取第一个通配符所在位置的值
9.关联关系数据的处理
分类 :
① 一对一: student 和 computer , person 和 身份证
② 一对多(多对一):普通关系(重点)student — team
③ 多对多:student — course product — order
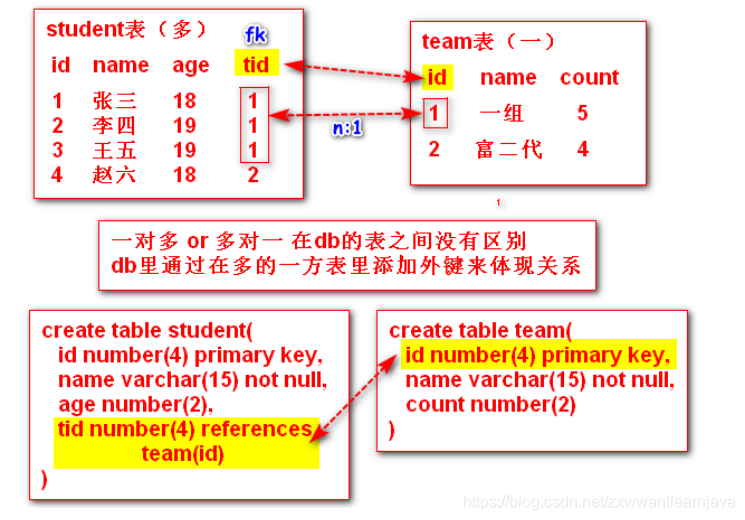
1)多对一
① 在db里描述数据以及数据间的关系
② 在java里通过实体类体现关系

③ 定义dao接口(多对一)
定义两个dao接口 StudentDao(5个) 和 TeamDao(5个方法)
1)TeamDao — 与原来单表操作一致
2)StudentDao — 拥有关系属性的实体类对应的dao
a.增删改 — 与原来的单表操作一致
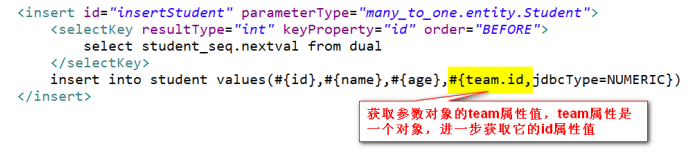
b.查询特殊 — 需要查询“完整”的学生对象(学生基本信息,所在小组基本信息)
所有数据来自两张表(需要表连接查询 – 左外连接)
select s.id,s.name,s.age,t.id,t.name,t.count
from student s left join team t
on s.tid = t.id
where s.id = #{id}

2)一对多
在db里描述关系和数据
与上面讲的多对一在db里的描述完全一致,数据库里不分一对多和多对一,统一通过外键的形
式体现两张表之间的关系(在多student的一方表里添加外键)
① 在java的实体类之间描述关系
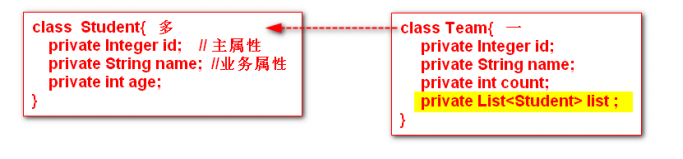
② 定义dao接口 – 两个dao
③ 实现接口 — mapper.xml
1)没有关系属性的类对应的dao ---- 按照单表操作实现即可
2)有关系属性的类对应的dao
a. 增删改 ---- 按照单表操作
b. 查询功能特殊 ---- 表连接查询
public Team queryTeamById(Integer id);
<resultMap id="res1" type="entity.Team">
<id column="tid" property="id"></id>
<result column="tname" property="name"></result>
<result column="count" property="count"></result>
<!-- 封装关系属性:是一个集合 -->
<collection property="list" ofType="entity.Student">
<id column="sid" property="id"></id>
<result column="sname" property="name"></result>
<result column="age" property="age"></result>
</collection>
</resultMap>
<select id="queryTeamById" parameterType="Integer" resultMap="res1">
select t.id tid,t.name tname,t.count,s.id sid,s.name sname,s.age
from team t left join student s on t.id = s.tid
where t.id = #{id}
</select>
3)一对一
① 在db里体现
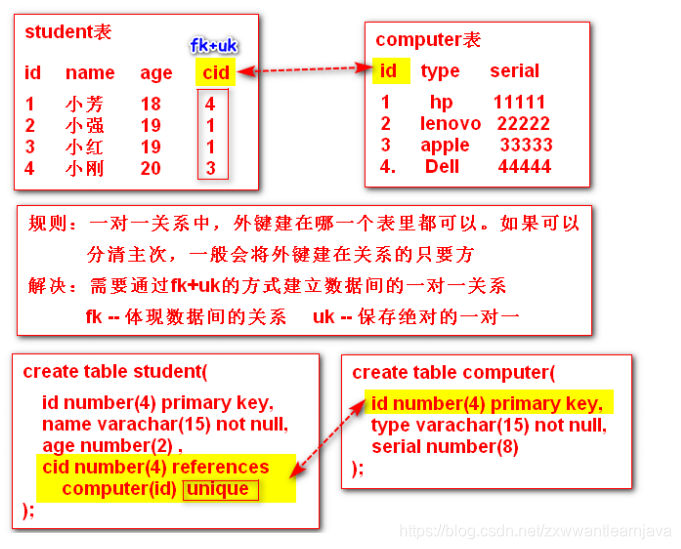
② 在java类里体现
class Student implements Serializable{
private Integer id; //主属性
private String name; //业务属性
private int age;
private Computer computer; //关系属性
}
class Computer implements Serializable{
private Integer id; //主属性
private String type; //业务属性
private int serial;
// private Student student; //关系属性
}
/*
规则:
1. 双向一对一 : 互相保留对象的一个引用
2. 单向一对一: 只有一方保留对方的引用
*/
③ 定义dao接口 – 两个dao
④ 写映射文件
1.没有关系属性的dao按单表操作实现 ---- ComputerDao b.
2.有关系属性的dao查询方法需要特殊处理,增删改按单表操作实现
public Student queryStudentById(Integer id);
<resultMap id="res1" type="entity.Student">
<id column="sid" property="id"></id>
<result column="name" property="name"></result>
<result column="age" property="age"></result>
<association property="computer" javaType="entity.Computer" >
<id column="tid" property="id"></id>
<result column="type" property="type"></result>
<result column="serial" property="serial"></result>
</association>
</resultMap>
<select id="queryStudentById" parametherType="Integer" resultMap="res1">
select s.id sid,s.name,s.age,c.id cid,c.type,c.serial
from student s left join computer c
on s.cid = c.id where s.id = #{id}
</select>
4)多对多
① 在db里体现
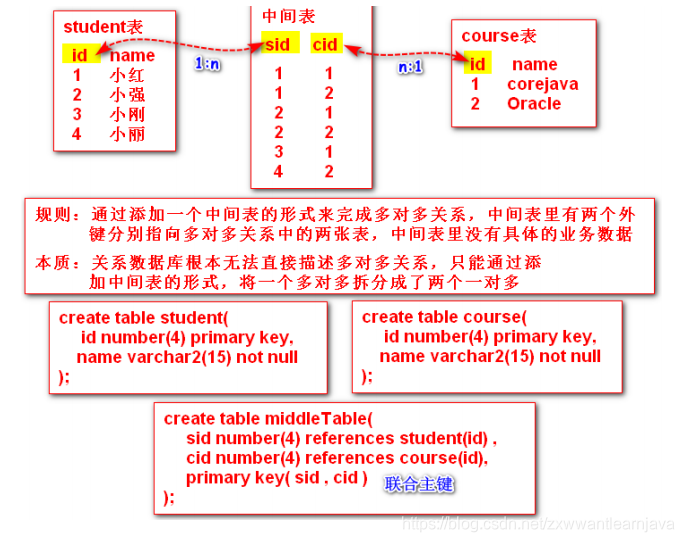
② 在java实体类里体现
class Student implements Serializable{
private Integer id;
private String name;
//关系属性
private List<Course> cs ;
}
class Course implements Serializable{
private Integer id;
private String name;
// private List<Student> ss;
}
/*
规则:通过添加对方引用的方式来体现关系
1. 双向多对多 --- 互相保留对方的一个集合引用
2. 单向多对多 --- 选择一方(关系的主要方)保留关系属性集合
*/
③ 定义dao接口
1)如果直接描述多对多关系,会导致“数据库里表的个数” 和 “实体类的数量” 不对等,如果
开发时只需要程序员提供“查询”功能,此时定义两个dao即可(针对实体类的数量)
a. 没有关系属性的dao — 按照原来的单表操作实现即可 ( 查询功能 )
b. 有关系属性的dao ---- 查询需要特殊处理(没有增删改功能) — 三张表连接查询
<resultMap id="res1" type="entity.Student">
<id column="sid" property="id"></id>
<result column="sname" property="name"></result>
<collection property="cs" ofType="entity.Course">
<id column="cid" property="id"></id>
<result column="cname" property="name"></result>
</collection>
</resultMap>
<select id="queryStudentById" parameterType="Integer" resultMap="res1">
select s.id sid,s.name sname,c.id cid,c.name cname
from student s left join middletable m
on s.id = m.sid
left join course c on c.id = m.cid
where s.id = #{id}
</select>
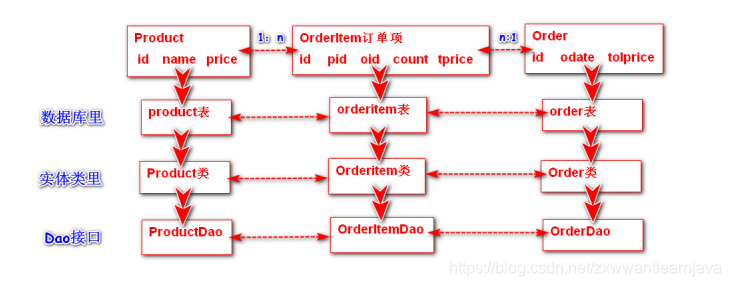
2)如果业务中需要提供“增删改”功能,建议在业务需求分析时,直接将多对多拆分成两个一
对多处理(通过添加一组业务数据的方式拆分)
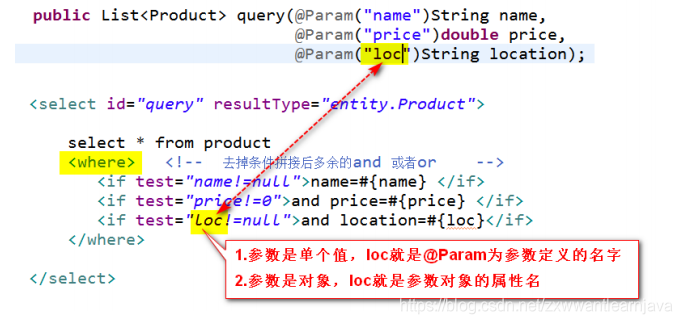
10.动态sql
通过使用标签在映射文件里动态拼接sql命令
1)if 和 where 标签
①
<if test="boolean"> 标签体 </if>
②<where>取代sql命令中的where指令,可以去掉条件里多余的and 或者 or</where>

2)if和set标签 — 用在update命令上

3)关于forEach标签 — 批量删除

11.mybatis的缓存机制
1)什么是缓存? 好处?
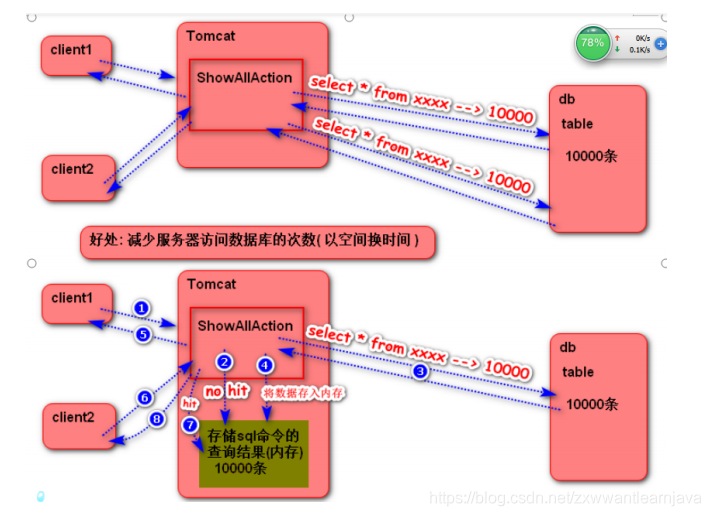
2)mybatis的缓存分类
a. 一级缓存:SqlSession级别的缓存(默认提供),sqlSession对象有一块缓存区域,只要当前session
执行过的sql命令结果都会被缓存在自己的空间里,不同的session互不影响 .
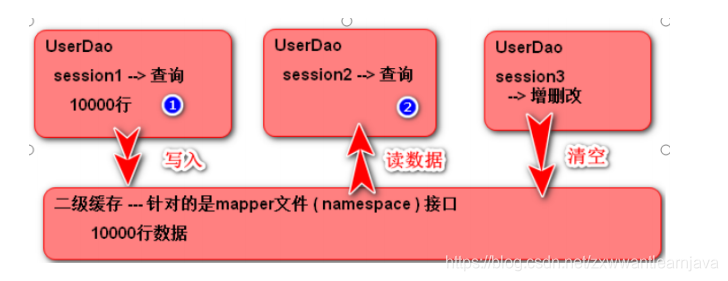
b.二级缓存:mapper级别的缓存(全局缓存),mybatis会为每一个namespace提供一块缓存区域
(不同的session执行了同一个namespace里的查询命令,结果都会被缓存在 namespace对应的缓存区里—二级缓存区里)
3)二级缓存
开启方式: 在mapper文件里添加上标签cache即可
特点:
1)当session关闭时,session执行的查询命令结果才会进入二级缓存
2)当session调用了接口里的增删改方法并提交(数据库里的数据发生改变),则二级缓存会被清空
九、JavaScript
1.特点
基于浏览器的,解释型的
1)可以使用任意文本编辑器开发,需要由浏览器执行
2)解释型:自顶向下,逐行翻译解释执行,解释一次执行一次,跨平台,存在严重
浏览器差异
3)语法规则:与java差不多,语法要比java松散
2.作用
需要嵌入到html页面里,为“网页”添加动画效果 — 运行方式类似css文件
1)html + css — 静态网页(里面的数据不会改变)
2)servlet ,jsp — 动态网页(嵌入java代码改变数据)
3)js — 添加动画效果(按钮功能添加,表单数据验证),网页刷新后,所有动画效果全部消失
嵌入方式: <script type="text/javascript"></script>
3.基础语法
1)js是一种弱数据类型语言
① java – 强数据类型语言(变量的类型 必须与 值的类型 一致 )
int a = 3; String str=“呵呵”; boolean ba = true;
② js – 弱数据类型语言(只有“数据”有类型,变量没有类型)
var a = 3; a = “hehe”;
2)js里的变量
① 变量可以重复声明定义,值以最后一个赋值为准
var a=3; var a=“hehe”; var a; alert(a); —> hehe
② 没有“块”作用域的概念
if( true ){ var a = 3; }
document.write( a );
③ 局部变量:定义在函数里面的,并且用var关键字声明的变量,仅限于在函数里面使用
④ 全局变量:除了局部变量,其他全部都是全局变量( 没有var关键字声明的变量)
3)数据类型
① 基本数据类型
a. 数字类型(不分整数和小数) ---- 3 和 3.0
b. 字符串类型(不分字符和字符串)— 定义时单引号和双引号都ok ‘hehe’ “呵呵”
c. boolean类型 — true|false 0-false | 1-true null-false | !null - true
if(true) if(3) if(“hehe”)
② 特殊的数据类型 — null undefinded(未定义的) NaN(not a number)
if( true ){ var a = 3; }
document.write( a );
③复合数据类型 — 数组,对象,Date,Math,Function类型
4)运算符
① 只要能计算出结果,js都会努力去做(计算时自动类型切换得到结果)
② 判断相等性(js里没有equals方法)
// a. == :只比较内容是否相同,不比较类型
var a = 3; var b="3"; alert( a==b ); --- true
// b. === : 比较内容,也比较类型
var a=3; var b="3"; alert(a===b); --- false
③ typeof — 获取一个值的具体类型
alert(typeof "abc"); // string
5)流程控制 — 与java完全一致
4.函数
1)定义函数
① 使用关键字function定义
// function 函数名(形参名,.....){ 代码实现 }
function add(a,b){ return a+b; }
② 隐式函数声明定义
在js里函数也被认作为一种数据类型,一个函数也可以被理解为“一个函数类型的值”,函数名就是保存这个值的变量名
语法 : var 函数名 = function(参数表){ 代码实现 }
使用: 函数名(实参);
2)变量之间的赋值
var fun1 = function(){ return "hehe"; };
// 将fun1里保存的“函数类型值”赋值给fun2变量,赋值成功,fun2里存放的也是“函数类型值”。
var fun2 = fun1;
// 调用fun1函数,将函数的返回值赋值给fun3变量,赋值成功后,fun3里存放的是String类型值
var fun3 = fun1();
注意:
1.JS 代码中没有方法重载的概念。函数被调用时,可以传入多余或者少于形参个数的实参。
2.所有传入的数据都被保存在arguments数组里
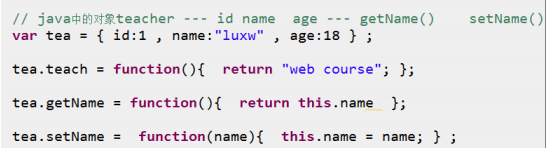
5.对象类型
1)js里只有对象,没有类,任意两个对象都不相同
2)创建对象
语法: var 对象名 = { 属性名:值 , 属性名:值 , … }
特点:对象创建成功之后,可以随时为对象添加新的属性,可以访问
添加 — 对象名.新属性名 = 值 获取 — 对象名.属性名
3)访问对象
① 访问具体的某一个属性值 — 对象名.属性名 or 对象名[“属性名”]
var stu1 = { id:1 , name:"lisi" };
alert( stu1.name );
alert( stu1["name"] );
② 遍历对象的所有属性 for…in语法
for(变量名 in 对象名){
// 循环每次执行,都会获取对象中的一个属性名赋值给指定的变量
// 访问: 对象名【属性名 --- 变量名】
}
4)js的对象只有属性,没有方法
6.数组类型
1)特点
长度不固定,可以随意扩充 ; 存放任意类型的数据 ---- 类似于java里的集合
2)创建数组
语法: var 数组名 = [ 值1, 值2, 值3,… ];
注意:数组定义好后,可以随时向里面填充数据 数组【下标】=值;
数组的长度 ----- 数组.length
3)数组访问
① 访问一个元素 : 数组[下标]
② 遍历数组 : 与java相似,使用for循环遍历
对象和数组的区别:
严格讲没有太大的区别,都可以用来存放一组数据。对象是靠属性名访问,数组是靠下标访问
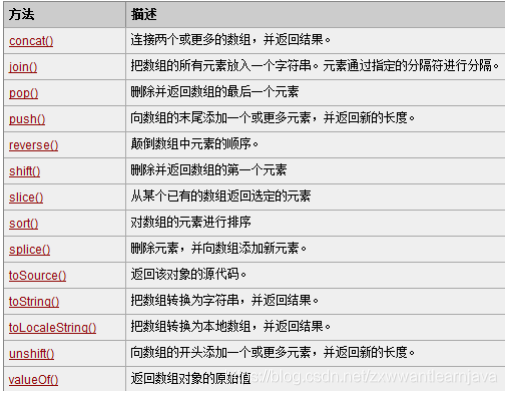
4)js为数组提供的一系列功能函数
7.复合数据类型
1)String类型
① 创建: var str = “xxxxx”
var str = new String(“呵呵呵”);
② 提供了一些功能函数
获取String长度的功能是 length属性,不是length函数
2)数学类型Math
相当于java里的工具类,里面的函数相当于java里的静态方法,使用Math直接调用
var num = Math.random();
3)日期类型
创建 — var date = new Date(); // 获取当前系统(浏览器)时间
var date = new Date(“1992-06-12”); //创建一个指定时间的日期对象
函数 — 提供功能函数来获取日期的各个组成部分。
8.代码的执行方式
1) js代码由事件触发运行,当网页里的html标签产生特定的,能够被浏览器捕获的事件时,触发js代码运行
2)监听事件模型: 事件源(html标签) 事件对象(浏览器捕获的事件) 监听器(指定代码)
3) js代码开发步骤:
① 确定事件源(功能与哪一个标签有关),需要添加监听器的标签
② 根据事件,选择合适的监听器,以属性的形式添加到html标签上
4)为标签添加监听器
① <标签名 监听器=“js代码”> ----- 适用于少量js代码的指定
② <标签名 监听器=“调用js里定义好的函数”> — 适用于大量js代码的添加
9.监听器
1)鼠标相关监听器(左键)
onclick — 单击事件
ondblclick — 双击事件
onmouseover — 鼠标移入
onmouseout — 鼠标移出
onmousemove — 鼠标移动
onmousedown – 鼠标按下
onmouseup — 鼠标松开
2)键盘相关监听器(不重要,任意键)
onKeyDown 按键按下
onKeyUp 按键抬起
3)body标签相关事件
onload 页面所有元素加载完成后触发的事件 【重点】
onscroll 页面滚动
onresize 缩放页面
4)form表单相关事件监听器
onblur 当前表单元素失去焦点 【重点】
onchange 当前表单元素失去焦点并且值发生改变 — 下拉列表 【重点】
onsubmit 表单提交事件 — form标签 【重点】
onfocus 当前元素获取焦点
10.事件代码的注意事项
1)事件冒泡:内部元素产生的事件,默认会扩散到外部容器中
取消事件冒泡 — event.cancelBubble=true;
event — 浏览器里产生的事件对象
event.clientX ,event.clientY 事件产生点的横纵坐标
2)通过为标签添加事件监听来修改标签的默认行为
① 超链接 — 点击后后会立刻发生跳转
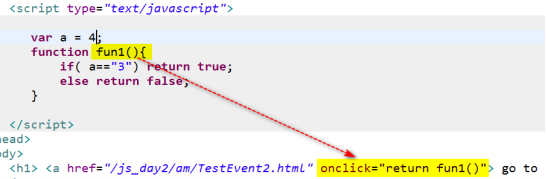
② 表单标签 ---- 点击submit按钮,会提交整个表单

11.DOM编程
1)dom — document object model 文档对象模型
标记语言文档,解析技术一般有两类 DOM SAX
2)DOM:浏览器会将整个文档加载进内存,将文档中的所有标签封装标签对象,在内存中形成一棵文档树,
每一个标签对象都成为这棵树的节点(Element --标签对象,node —文本内容)
3)DOM里最重要的对象
document对象 —代表整个文档(特指body部分,浏览器窗口里地址栏以下,状态栏以上的部分)
window对象 — 代表整个浏览器窗口,document是window的一部分(属性),使用其属性或函数时可以省略window
作用:通过使用dom提供的api(函数和属性)获取文档中的标签对象,进而修改标签对象的属性和样式,达到添加动画效果的目的
4)API
① 获取其他标签对象的方法
//1.根据标签的id属性获取指定标签 【重中之重】
var tag = document.getElementById("id属性值");
//2. 根据标签名来获取标签对象
var tags = document.getElementsByTagName("标签名");
//3. 根据标签的name属性值获取标签对象 --- 针对表单元素 input select
var tags = document.getElementsByName("name属性值");
//4. 根据 标签的class属性获取标签对象
var tags = documemt.getElementsByClassName("class属性值")
② 添加效果
通过修改标签的属性或者样式来达到目的
1)获取属性值 ---- var value = 标签对象.属性名
2)设置属性 ----- 标签对象.属性名 = 值;
3)设置css 样式 ----- 标签对象.style.css属性 = 值;
h1.style.color = “red”
h1.style.background=“blue”
4)设置class属性 ---- 标签对象.className = class样式名;
③ 常见属性
1)this :代表当前产生时间的标签对象(事件源)
2)event:代表当前事件对象
3)innerHTML : 为标签设置标签体里的内容,一旦设置成功,新值覆盖里面原来所有的旧值
④ 从网页中删除标签
// 1. 需要通过父标签对象删除子标签对象
parentTag.removeChild(子标签对象)
// 2. 对表格进行处理时,js主要针对的是tbody标签,不是table标签
// 3. 标签对象的一组关系属性
tag.parentNode -- 获取当前标签tag对象的父标签对象
tag.childNodes -- 获取当前标签tag对象的所有子标签
tag.firstChild -- 获取当前标签tag对象的第一个子标签
tag.lastChild -- 获取当前标签tag对象的最后一个子标签
tag.nextSibling -- 获取当前标签tag对象的“弟弟”(同级下一个标签)
tag.previousSibling -- 获取当前标签tag对象的“哥哥”(同级上一个标签)
//注意:js的关系属性,存在严重的浏览器差异
//4. 删除过程中的技巧
var ba = window.confirm("提示文字");
--方法返回Boolean值,表示对话框里的选择(确认--true,取消--false)
⑤ 向网页里添加标签
//1.创建新标签
var tag = document.createElement("标签名");
// 例如: <h1> hehehe </h1>
1) var h1 = document.createElement("h1"); // <h1></h1>
2) h1.innerHTML = "hehehe";
//2. 设置标签之间的关系
1)parentTag.appendChild( 子标签 ); //将新标签添加到父标签的最后面
2)parentTag.insertBefore(新标签,旧标签); // 将新标签添加到指定标签的前
3)parentTag.replaceChild(新标签,旧标签);//用新标签替换掉指定的旧标签
12.BOM编程
1)bom – browser object model 浏览器对象模型,一组与浏览器window对象相关的内置 对象和函数
2)window对象提供的函数和属性
// 1. 对话框 ( 警告框 , 确认框 ,提示输入框)
window.alert("警告内容");
var ba = window.confirm("提示文字");
// 提示输入框
var content = window.prompt("提示文字"); // 返回值为输入内容
// 2. window对象提供的location属性 【重点】
// location的href属性 ---在js代码里向其他资源发送请求(跳转),类似于超链接
//3. 定时器
// 1) 单次定时器
var id = window.setTimeout(fun,time); time单位是毫秒
在time毫秒后执行一次fun函数
window.clearTimeout( id值 ); --- 定时器
// 2)周期定时器
var id = window.setInterval(fun,time); time单位是毫秒
每隔time毫秒执行一次fun函数
window.clearInterval(id);
// 4. 打开和关闭浏览器窗口函数
var w = window.open("url"); 在新的浏览器窗口里打开指定的资源页面
window.close();
十、JQuery框架
1.概念
是一个基于JavaScript语言的框架 — 对原来js代码的合理封装
2.特点
相对于js代码比较
1)js代码比较复杂
js ---- var tag = document.getElementById(“id值”);
jquery ---- var tag = $("#id值");
2)js存在浏览器差异(数子标签),jquery可以屏蔽浏览器差异
3)提供了强大的界面支持(动画效果更佳丰富)
4)jquery支持对一组标签直接操作(不需要遍历)
5)jquery支持链式调用
3.搭建环境
引入相关的资源文件(以 .js 文件的形式存在)
<script type="text/javascript" src="js文件路径"></script>
4.基础语法
1)$("#id") —> 根据id值获取标签 — jquery习惯语法 $("")
2)jquery喜欢用函数调用的方式来完成功能
css(“css属性”,“值”) — 设置css样式
html() — 等价于js里的innerHTML属性,设置标签体内容
与Dom对象的区别
1)通过document.getElement…(…) 获取的是dom对象,不能使用jquery定义的函数
2)通过jquery方式获取的对象叫jquery对象$(""),可以调用jquery提供的函数
5.获取Jquery对象的方式
1)通过dom对象获取jquery对象
var jqueryObj = $( dom对象 ) ;
注意:在开发中主要用来处理解决 this (默认是dom对象)
2)通过html标签获取jquery对象
var h1 = $("<h1> hehehe </h1>");
注意: 用于向网页里添加新标签功能,创建新标签
3)通过选择器获取jquery标签对象
① 基本选择器
1.id选择器 – 根据标签的id属性值来获取标签对应的jquery对象 【重点】
语法:$("#id值")
2.标签名选择器 – 根据标签名获取jquery对象(一组jquery对象)【重点】
语法:$("标签名")
3.类选择器 – 根据标签的class属性值获取一组jquery对象
语法:$(".class属性值")
4.多路选择器 – 一次给定多个选择器获取一组jquery对象
语法:$("选择器1,选择器2,...")
5.全选择器 — 获取所有标签(包括body,head)
语法:$("*")
② 层次选择器
1.后代选择器 – 获取所有出现在选择器1里的选择器2(包括儿子、孙子) 【重点】
语法:$("选择器1 选择器2")
2.孩子选择器 – 获取所有出现在选择器1里的直接选择器2标签(孩子)
语法:$("选择器1>选择器2")
3.兄弟选择器 – 获取选择器1后续所有兄弟选择器2
语法:$("选择器1~选择器2")
4.下一个兄弟选择器 – 获取选择器1后的第一个兄弟选择器2
语法:$("选择器1+选择器2")
③ 过滤选择器
配合前面九种选择器使用,在一组jquery对象中筛选有用的jquery对象
- 基本过滤选择器
:first — 获取一组jquery对象中的第一个jquery对象 【重点】
:last — 获取一组jquery对象中的最后一个jquery对象
:not(selector) — 从一组jquery对象中,排除给定的选择器
:even — 获取一组jquery对象中下标为偶数的jquery对象 , 下标从0开始
:odd — 获取一组jquery对象中下标为奇数的jquery对象
:eq(index) – 获取下标为index的jquery对象
:gt(index) – 大于给定下标的jquery对象 【重点】
:lt(index)
- 内容过滤选择器
:contains(text) — 在一组jquery对象中,获取 文本内容是text的标签对
:has(selector) — 获取含有指定选择器的jquery对象
:parent — 获取有孩子节点的jquery对象
:empty — 获取空标签对象
- 可见性过滤选择器
:hidden ---- 获取一组jquery对象中被隐藏的标签
:visible ---- 获取可见的jquery对象
- 属性过滤选择器
[attribute] ----- 获取一组jquery对象中含有指定属性的标签
[attribute=value] — 获取一组jquery对象中的属性为value的标签对象 【重点】
[attribute!=value] — 获取一组jquery对象中除了value之外的标签对象
- 表单对象属性过滤选择器
:enabled
:disabled – 获取一组jquery标签对象中的处于失效状态的标签
:checked – 获取一组jquery对象中的被选中的标签对象 checked=true的 【重点】
:selected — 获取一组option标签对象中的被选中的option 【重点】
④ 表单选择器
:input $(":input") – 获取网页里的所有的input标签
:text
:pasword
:radio
:checkbox
$(":checkbox") <-> $(“input[type=checkbox]”)
$(":checkbox:checked") <-> $(“input[type=checkbox]:checked”)
:submit
:image
6.jquery对象的常见功能(函数)
jquery习惯通过函数调用的方式完成功能,支持链式调用(将所有功能函数都缀在对象之后)
1)length 或者 size()
获取一组jquery对象的个数
2)each()
//1. 作用:遍历一组jquery对象
//2. 语法
$("#u1 li").each( function(idx){
// 指定需要执行的jquery代码 或者 调用之前封装好的函数
// this --- 代表当前正在遍历的对象,是一个dom对象
// 此处idx代表正在遍历的对象的下标 -- 类似于循环变量
} );
3)prop() 或者 attr()
//1. 作用:获取或者设置标签对象的属性值(除了表单元素的value属性)
//2. 使用
设置属性值 ---- jquery对象.prop("属性名",“属性值”);
获取属性 ---- var value = jquery对象.prop("属性名");
删除属性 ---- jquery对象.removeAttr("属性名");
4)设置 or 获取 css样式的函数
- css() – 设置单个css样式
获取 — var value = jquery对象.css(css属性名);
设置 — jquery对象.css(“属性名”,“属性值”);
- 关于隐藏和显示标签
hide(time) – 在time毫秒内隐藏jquery标签对象(有动画效果)
show(time) – 在time毫秒内显示jquery对象
fadeIn() — 淡入
fadeOut() ---- 淡出
slideUp() — 隐藏
slideDown() — 显示
animate({})
- 添加一类css样式
设置样式
① jquery对象.addClass(css里一类样式的class名);
② jquery对象.prop(“class”,“class名”);
移除样式
jquery对象.removeClass();
5)三个关于内容操作的函数
① html() — 设置或者获取标签体内容的函数(标签体内容包括子标签和文本内容)等价于js里的innerHTML
获取 — var value = jquery对象.html();
设置 — jquery对象.html( 标签体内容 );
② text() – 设置或者获取标签体里的文本内容
③ val() — 设置或者获取表单元素的value属性值
获取 — var value = jquery对象.val();
设置 — jquery对象.val( value值 );
7.jquery中的事件添加
1)标签式事件添加
<标签名 监听器 = “代码 or 调用封装的函数 ”>
2)编程式事件添加
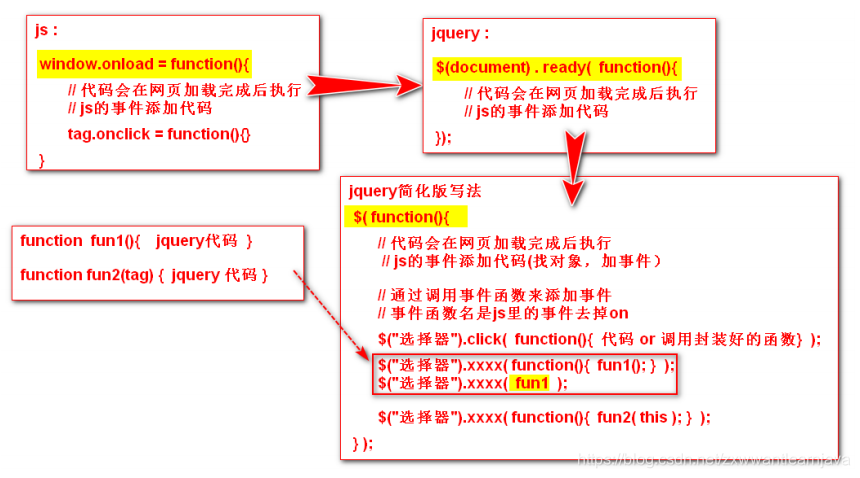
8.jquery中的其它功能函数
1)删除标签
//1) 删除标签的函数
thisTag.remove() ---> 删除当前标签对象
thisTag.empty() ---> 清空当前标签里的所有内容
//2) 关系函数
thisTag.parent() --> 获取父标签
thisTag.children() -->获取所有的孩子节点(忽略空格)
thisTag.next() ---> 获取下一个兄弟标签
thisTag.prev() ---> 获取上一个兄弟标签
thisTag.first() ---> 第一个孩子标签
thisTag.last() ----> 最后一个孩子
2)添加新标签
// 1)新建标签
var tag = $("<div>luxw</div>");
// 2)将tag放入网页中
parentTag.append( newTag ); --> 将新标签添加到现有父标签的最后一个子节点
parentTag.prepend( newTag); --> 将新标签添加到父标签现有子节点的第一个
siblingTag.after( newTag ); --> 添加到当前标签的下一个位置,称为"弟弟"标签
siblingTag.before(newTag);
// 3)现有事件函数【click..】只适用于网页里现有的标签对象,不适用于新添加的标签对象
解决:添加事件时,通过live("事件类型click,mouseover...",fun )解决。
3)复合事件
jquery对象.toggle(fun1,fun2,…) – 循环单击事件,单击第一次执行fun1,第二次执行fun2,第三次执行fun1
jquery对象.hover( fun1,fun2 ) – 第一个函数表示鼠标移入是的动作,第二个函数表示鼠标移出时的动作

















 1749
1749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









