







 本文围绕Apollo7.0自动驾驶预测模块展开,介绍其整体框架,包括消息、数据和代码主流程,以及容器、场景、评估器和预测器等组件。阐述环境信息编码过程,涉及子图和全局图处理。还讲述轨迹生成器原理,新增分布和交互部分。最后展示预测效果并给出测试指标。
本文围绕Apollo7.0自动驾驶预测模块展开,介绍其整体框架,包括消息、数据和代码主流程,以及容器、场景、评估器和预测器等组件。阐述环境信息编码过程,涉及子图和全局图处理。还讲述轨迹生成器原理,新增分布和交互部分。最后展示预测效果并给出测试指标。
1 引言
自动驾驶领域中预测模块关键问题:对周边车辆、行人在接下来数秒时间内的多种行为状态进行预测,进一步影响车主的路径规划。近年来自动驾驶领域行为预测采取较多的一种方式:采用类似VectorNet(《VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation》)分层的图神经网络的思想,将道路等静态环境信息以及动态交通参与者的运动轨迹均进行编码,编码后经过类似TNT(《TNT:Target-driveN Trajectory Predictio》)思想的方式进行轨迹预测。
2021年12月29日,Apollo7.0版本正式发布。本次7.0版本预测模块更新部分的核心思路与上述两篇论文非常接近,但主要区别在于使用MLP(多层感知机)替代了GCN(图神经网络),以及增加了更加丰富的工程化的优化方式。
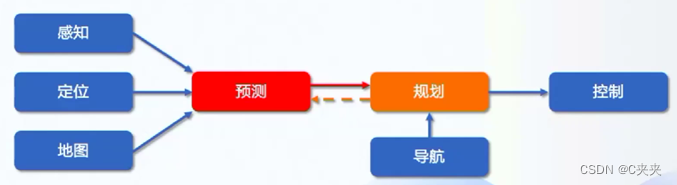
预测模块承接的上游模块是感知、定位和地图,通过预测算法给出未来运动轨迹输出给下游规划模块。在自动驾驶中可以通过预测主车周边障碍物的行为帮助主车做出决策,帮助更好的完成自动驾驶。交互式决策的意思是在预测过程中要考虑被预测障碍车和主车的交互,使预测和规划的轨迹更加平稳和准确。
2 整体框架
2.1 总体框架
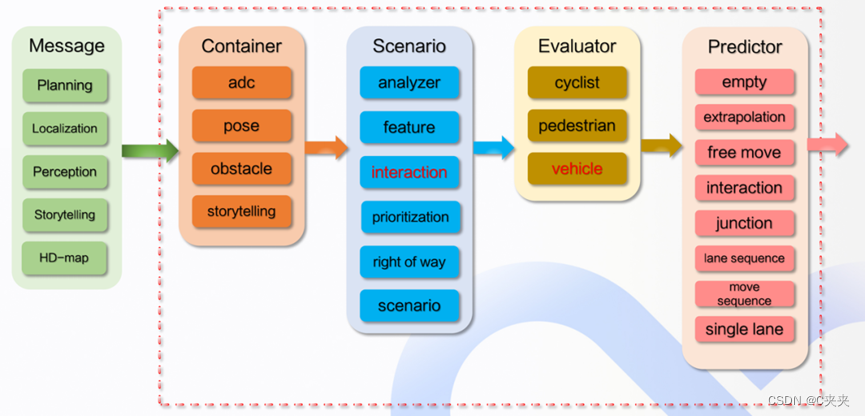
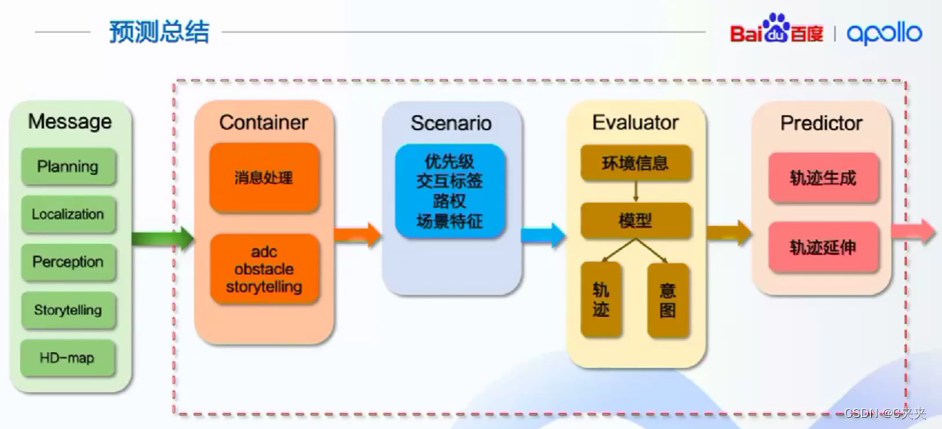
绿色模块表示预测模块所依赖的上游模块,红色虚线框中是预测模块的整体流程,预测模块的下游是规划模块。
预测所依赖的上游模块包括规划、定位、感知、storytelling和高清地图,其中storytelling是根据主车状态做场景分析(交叉路口场景、车道行驶场景);预测模块的整体逻辑包括容器(Container),场景(Scenario)、评估器(Evaluator)和预测器(Predictor)。
2.1.1 消息主流程
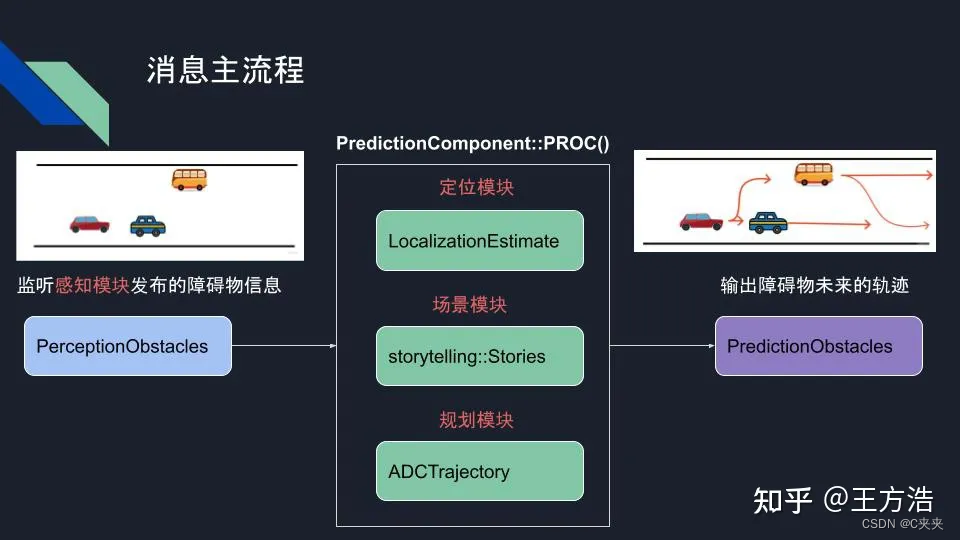
预测模块接收感知到的障碍物消息,然后结合自身的位置和规划信息,输出的结果是障碍物未来一小段时间的预测轨迹。
2.1.2 数据主流程
数据主流程的作用主要是为了帮助训练,例如在线无人车预测的数据,可以保存下来给离线使用。同时在调试的时候也可以通过跑离线任务来定位问题。
- 在线流程:用于在线推理,根据感知到的障碍物信息(类型、位置、速度)预测未来一小段时间内障碍物的轨迹,给规划模块使用
- 离线流程:用于离线训练模型,把在线计算的一部分数据保存下来给离线使用,同时用于调试。
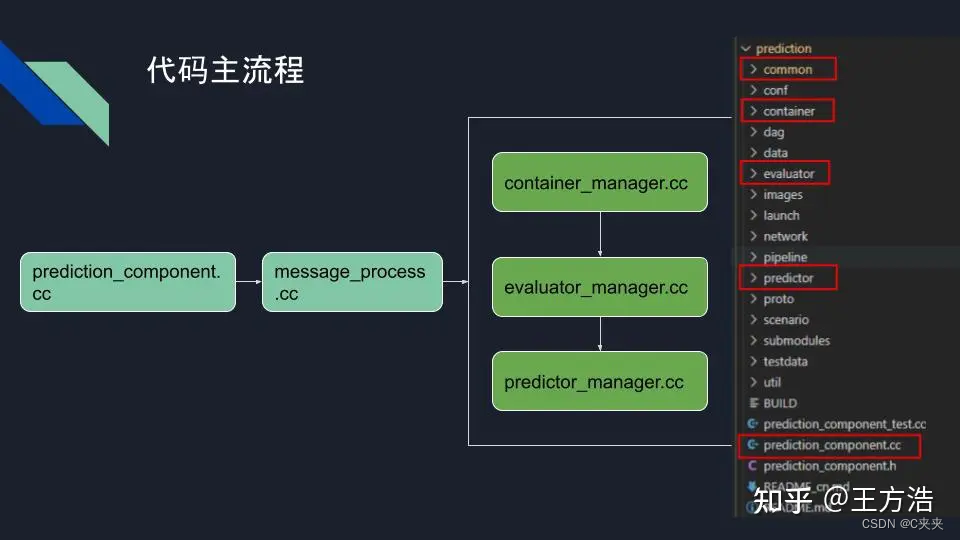
2.1.3 代码主流程
主流程在"message_process.cc"中,然后通过评估器和预测器来输出最后的预测结果。其中不同的障碍物类型对应不同的评估器和预测器。
2.2 容器(Container)
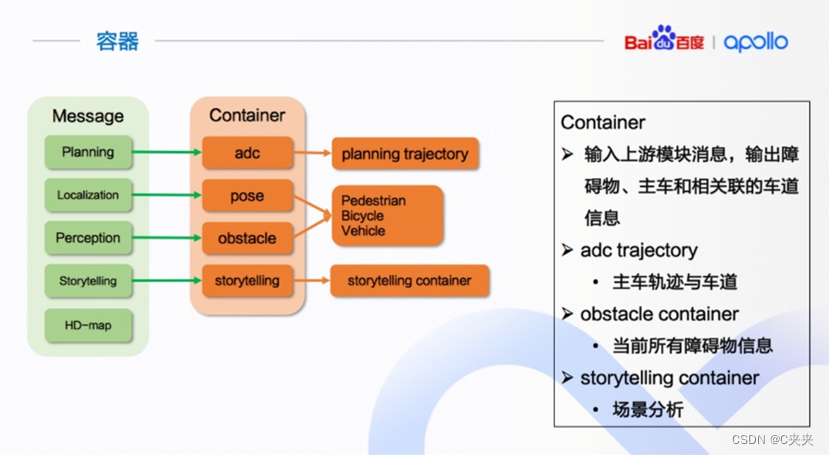
- 作用:处理上游模块的信息
- 包含:主车轨迹;主车位置;障碍物信息、障碍物与相关车道信息、相关车道信息;storytelling即根据主车位置判断当前场景。
- 输入输出:输入为上游模块一系列信息;输出为障碍物、主车和相关车道信息
预测模块的三大容器
pose_container (自动驾驶车辆当前的位置信息)
adc_trajectory_container (自动驾驶车辆规划的轨迹信息)
obstacles_container (感知到的障碍物信息)
- pose_container:主要是保存自动驾驶车自身的位置和速度信息
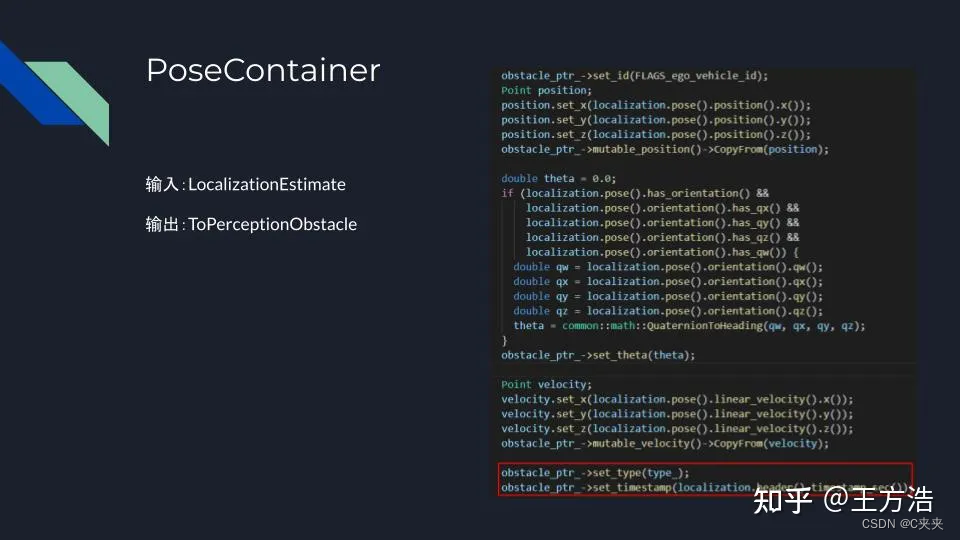
- ADCTrajectoryContainer:主要保存自动驾驶车规划好的轨迹,即自动驾驶汽车自身的驾驶意图。和pose_container一样是用来考虑障碍物和自动驾驶汽车本身的交互。

- ObstaclesContainer:主要保存障碍物信息,采用LRUcache来保持障碍物,并且定期淘汰过期的障碍物。同时还会对障碍物进行聚类,找出同一条车道上的所有障碍物,组成障碍物簇。
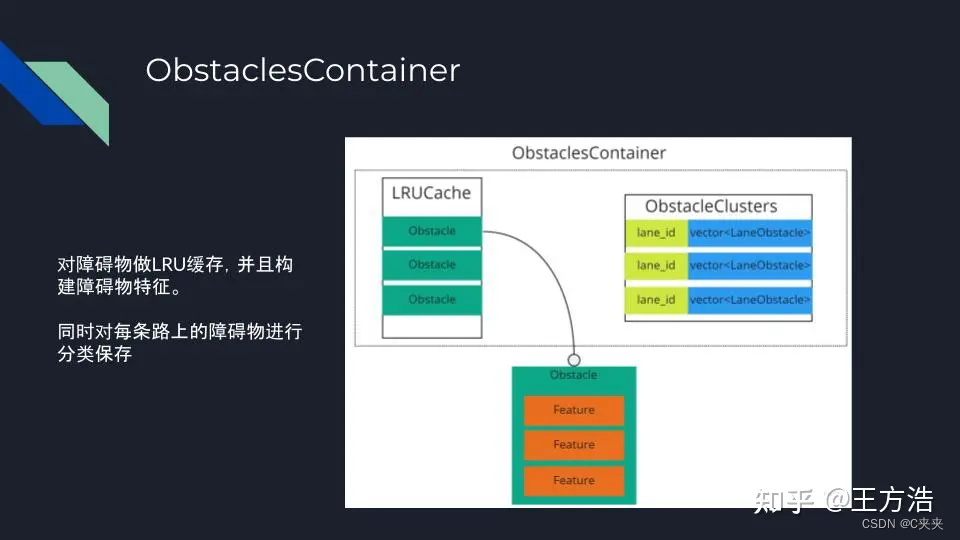
路网
在添加障碍物时,会计算出当前障碍物可能的行驶轨迹,即未来障碍物几种可能的驾驶路径选择,这通过路网来实现。举例:障碍物有2种路径选择,一种是直行,对应的车道分别是:l20,l98,l95;一种是右拐,对应的车道分别是:l20,l31,l29。
2.3 场景(Scenario)
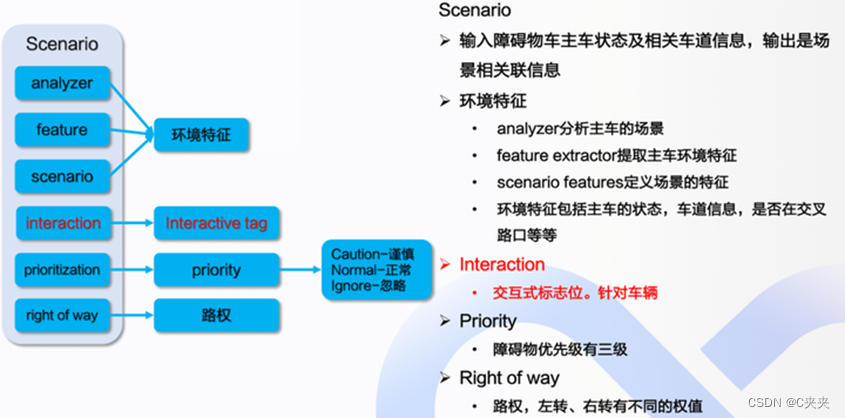
- 作用:包括场景特征以及一些与场景相关联的信息,包括根据障碍车和道路判断对主车的影响
- 包含:环境特征、交互标志位、障碍物优先级、设置权重
- 输入输出:输入为障碍物主车状态及相关车道信息,输出为场景相关联信息
- 与以往版本即6.0的区别:
- 6.0为将车辆、人过去的状态和位置作为输入,放在神经网络中,得到一个未来的预测,实际上还是拟合函数。
- 7.0为先根据障碍车的位置判断是否为交互式车辆(危险等级为ineraction及caution),然后针对交互式车辆用交互式模型;若为其它类型车辆,对于不在道路上的,使用卡尔曼滤波器。
- 创新点:7.0更加细分了感知障碍物的类别判断,使得感知预测更加细致,提升点在于有针对性,预测效果更好。
2.4 评估器(Evaluator)
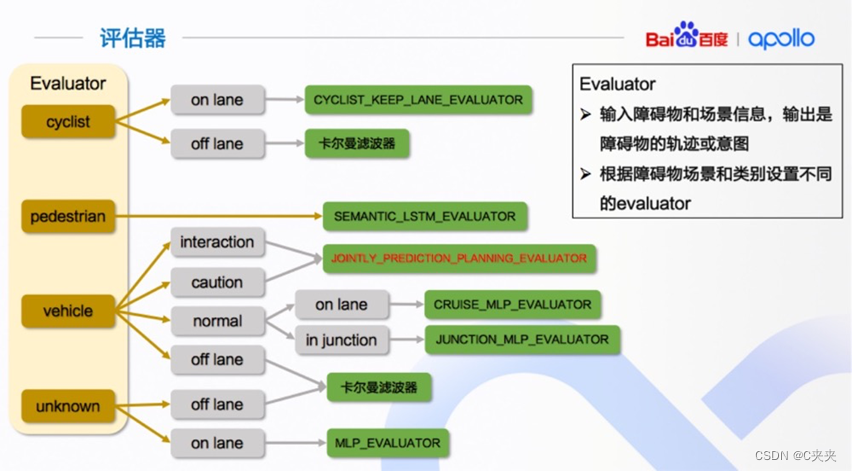
- 作用:评估器是预测的模型,即机器学习或深度学习的模型,用来预测障碍物未来轨迹和意图。
- 包含: 障碍物主要包括四类为自行车、行人、车辆、未知障碍物(感知模块中未检测出的)。在预测模块中,不同障碍物类型对应不同的评估器和预测器。
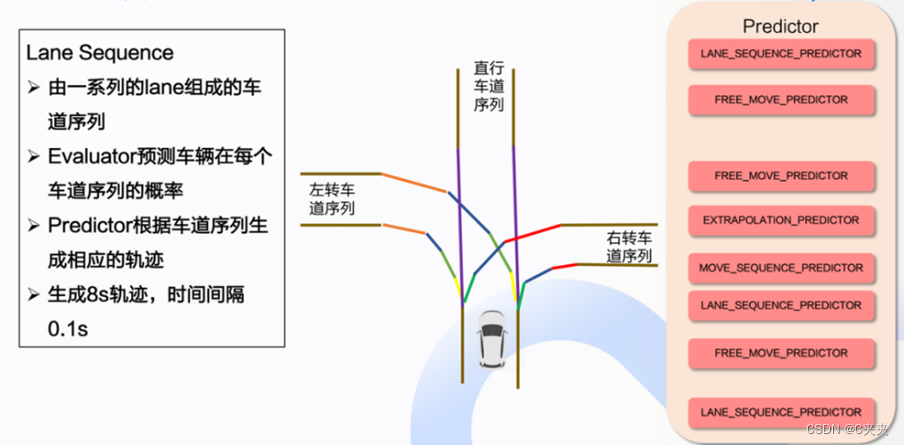
- 输入输出:输入为障碍物和场景信息;输出为障碍物的轨迹和意图,其中障碍物的意图指障碍物在每个车道序列的概率。
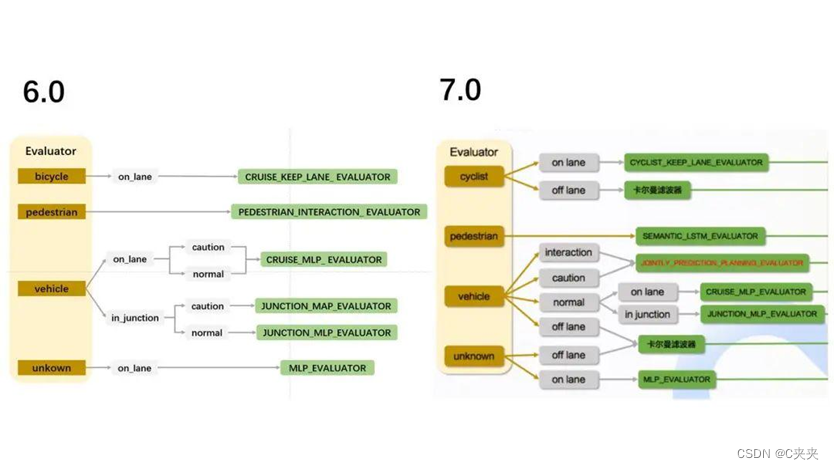
- 与以往版本即6.0的区别:
- 6.0版本在车辆部分,将其分为onlane和injunction,再按caution和normal去做划分。
- 7.0版本直接做等级划分,只在normal情况下做onlane和injunction划分。
- 7.0版本中多了interaction等级,其中caution均指向JOINTLY_PREDICTION_PLANNING_EVALUATOR。6.0版本中的onlane情况下的caution 和 normal 均指CRUISE_MLP_ EVALUATOR。
障碍物
感知侧输入的障碍物分为静态障碍物和动态障碍物,只有动态障碍物会进入预测模块,静态障碍物不做处理,打包后输出至规划侧。
预测模块六类评估器
预测模块会根据不同障碍物类型,障碍物在不在车道上,选择不同的评估器和预测器。
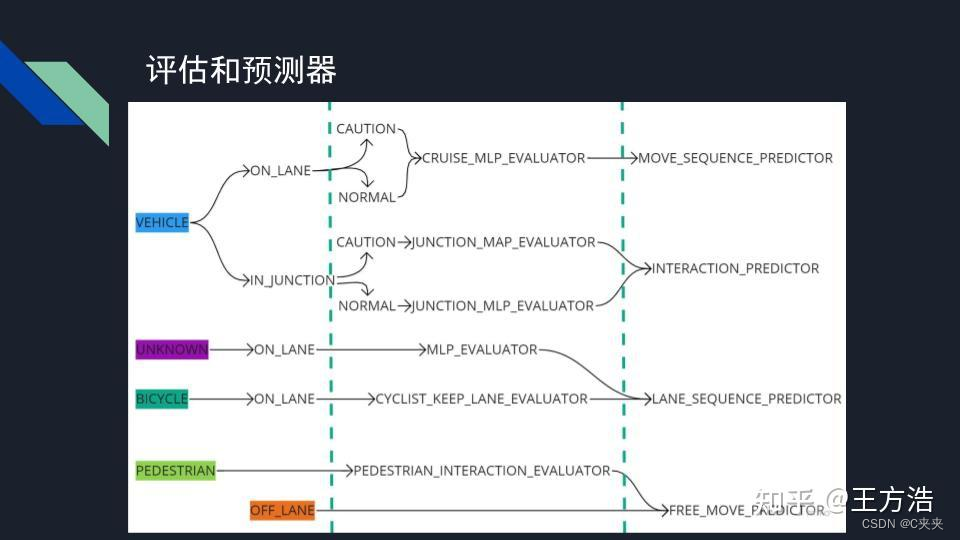
评估器大部分基于深度学习模型,少量基于规则的模型。
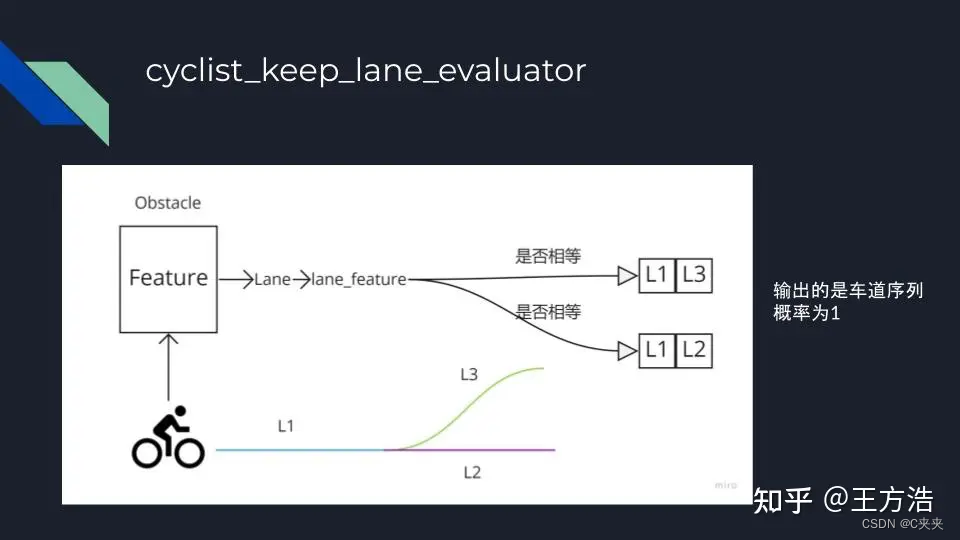
cyclist_keep_lane_evaluator
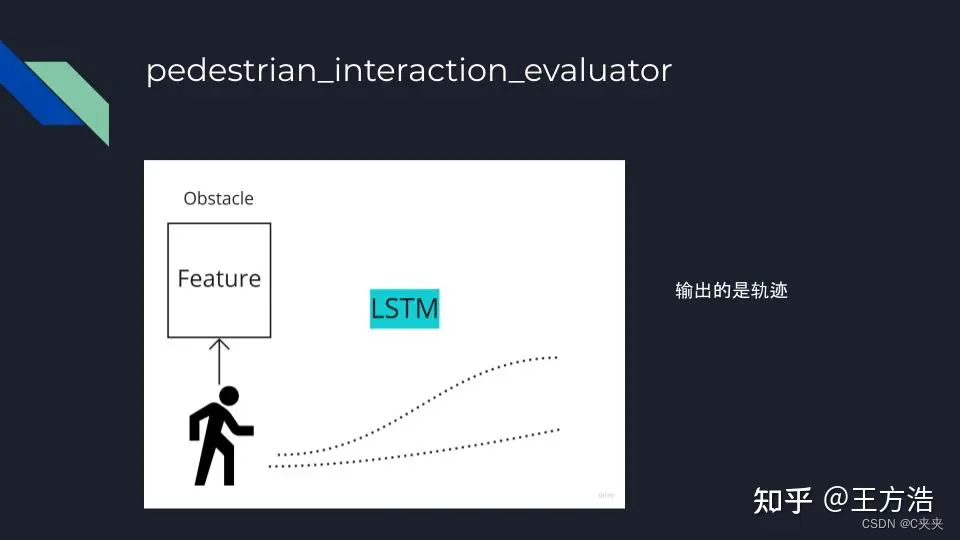
pedestrian_interaction_evaluator
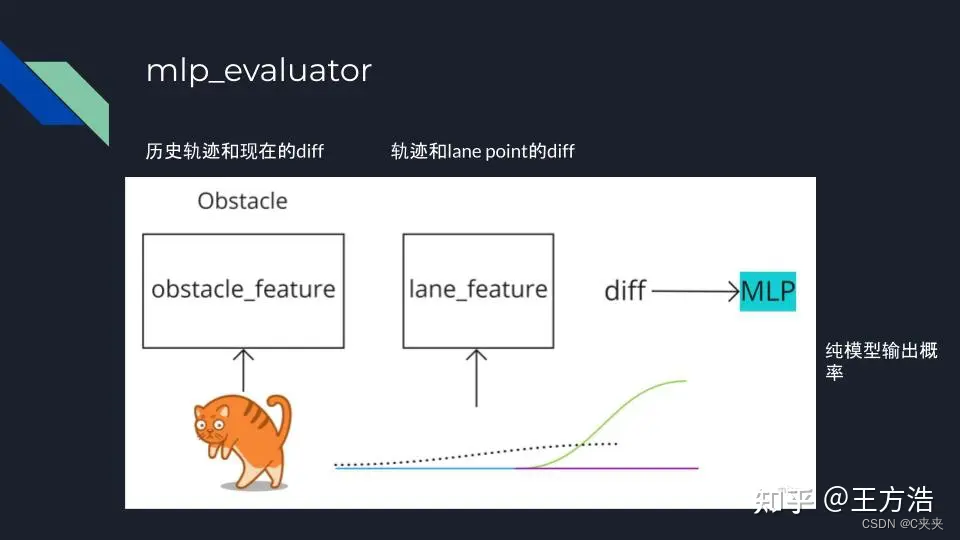
mlp_evaluator
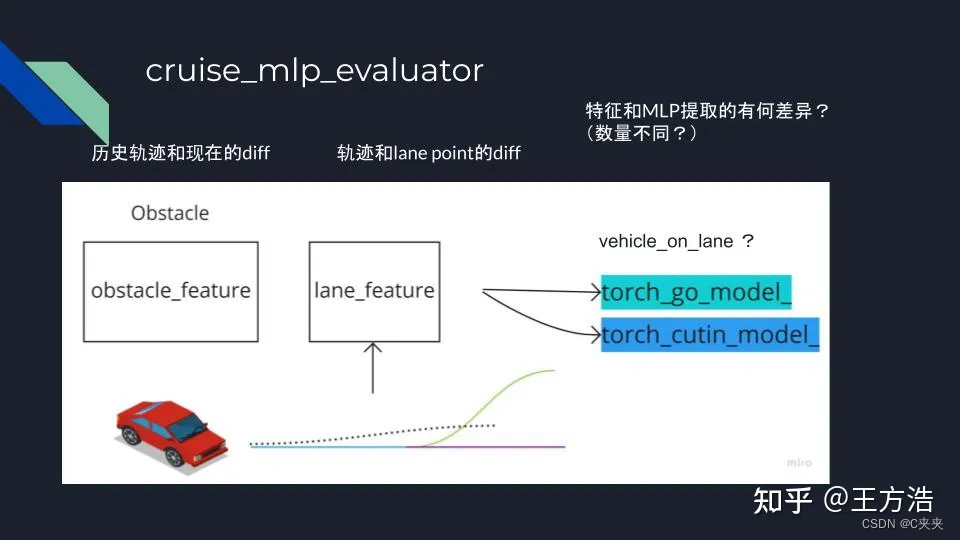
cruise_mlp_evaluator
junction_mlp_evaluator
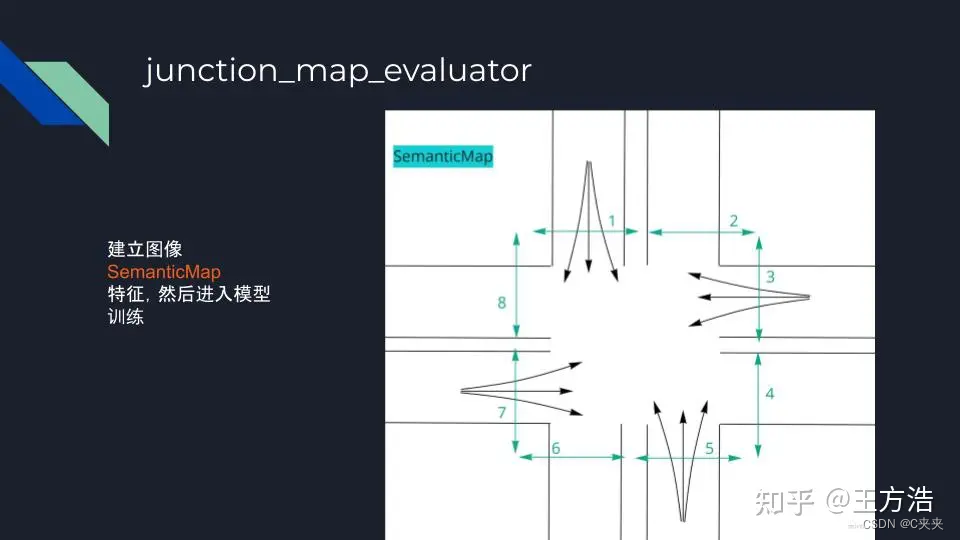
junction_map_evaluator
- 单车在路上:基于规则的模型,只要当前的自行车在之前生成好的车道序列上,就认为该车会保持当前车道;若车道选择较多,生成好的车道序列最多限制大小为4条,本车道最多选择2条,相邻车道最多选择2条。
- 行人:基于LSTM模型,最多预测2s的轨迹,行人没有区分在不在路上,默认行人为一个自由移动的模型。
- 车道上的UNKNOW类型:基于mlp_evaluator模型,是一个神经网络,输入的特征为障碍物的轨迹和车道的误差(位置、夹角、速度等)来判断车辆拐弯的概率和直行的概率。
- 在路上的车辆模型:也是神经网络,与mlp_evaluator区别不大,主要输入特征有些差别。
- 路口:路口情况较复杂,把路口分为12等分,然后预测障碍物可能的出口,同时还要考虑车辆和本车之间路径是否有冲突,最后得出预测的结果。
2.5 预测器(Predictor)


- 作用:预测器是在Evaluator获取预测轨迹或意图后,进行轨迹的延伸或者生成,处理完后最终生成8秒的轨迹。
- 输入输出:输入为短期预测轨迹或意图;输出为完整8s轨迹。
预测模块四类预测器
预测器最后输出的结果为一系列的轨迹点。
move_sequence_predictor
extrapoiation_predictor
lane_sequence_predictor
free_move_predictor
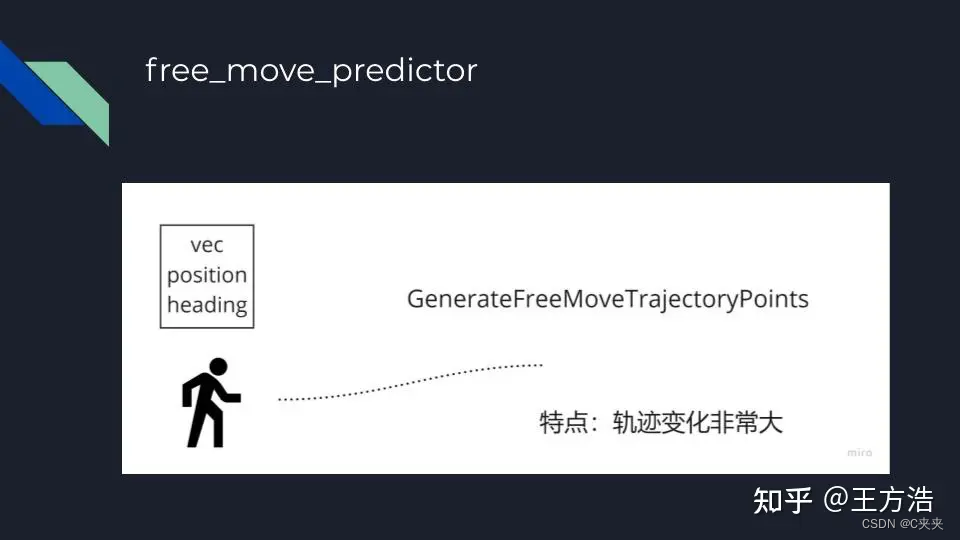
- free_move_predictor:自由移动预测器,补充轨迹
主要预测不在路上的所有类型的障碍物及行人,之前行人通过pedestrian_interaction_evaluator评估之后,只有2s的预测轨迹,后面会通过free_move_predictor补充6s的轨迹,一共预测8s。卡尔曼滤波
通过当前的速度和朝向拟合8s的轨迹,因此变化很大,表现的预测线将甩来甩去。
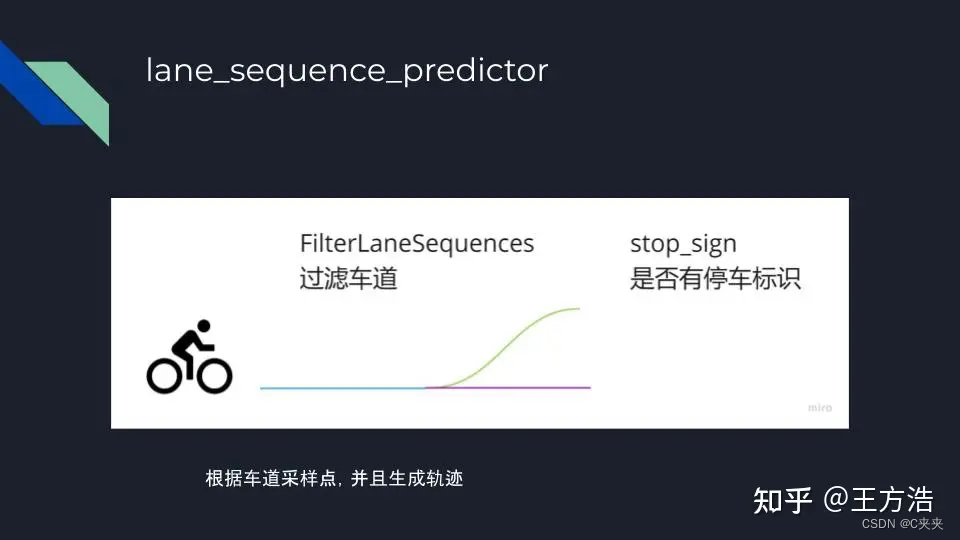
- lane_sequence_predictor:沿车道行驶预测器,生成轨迹
会根据评估的车道,过滤一些不太可能的车道,然后选择一条曲率最低的路径。
3. move_sequence_predictor:受运动学约束沿车道行驶预测器,生成轨迹
move_sequence_predictor和lane_sequence_predictor有轻微不同,主要在于生成轨迹的部分,进行了多项式拟合EvaluateQuarticPolynomial
4. extrapoiation_predictor:根据短期轨迹判断长期轨迹
2.6 模块总结
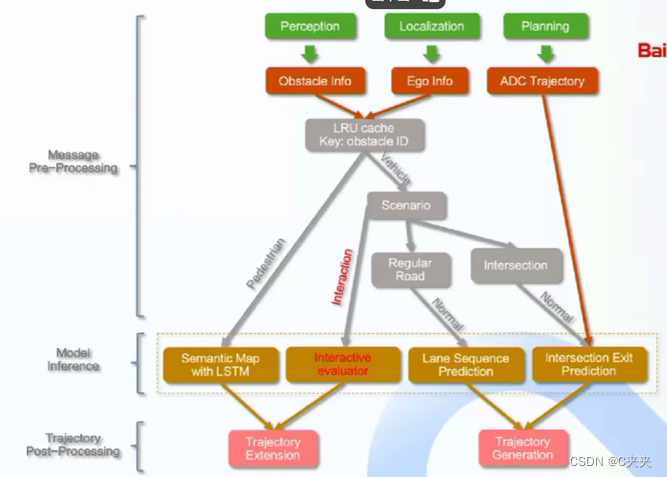
首先处理上游模块消息,得到障碍物、主车、主车轨迹等信息,然后分析障碍物所在场景给障碍物赋予不同级别,再根据场景和障碍物类别去配置不同evaluator,最后对短期轨迹或者意图做一个后处理,从而生成完整轨迹。
3 环境信息编码
3.1 为什么要编码?
最初对障碍物车辆的预测只依赖于障碍车自身的运动状态,但障碍车的运动状态与当下所处环境密不可分。例如,当下障碍车在下一个路口的右转车道上,可以判定其基本上要右转,如果在直行车道上,则很可能直行。
编码的作用是把道路之类的信息以形成特征的方式保存,以此决定障碍车的预测轨迹。此外,当主车ADC的planning轨迹有可能和障碍车辆产生交互时,例如主车需要变道、加塞时,也会对周边车辆产生影响,因此编码流中也会包含主车轨迹。
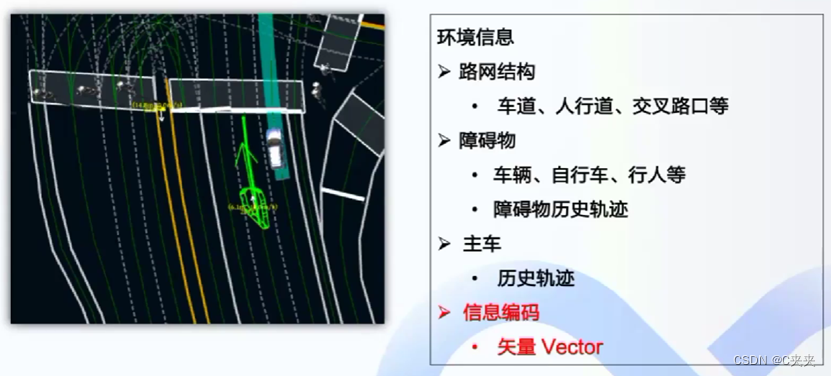
绿色是主车道,左边绿色多边形是感知检测到的障碍车,编码将所有信息包括历史轨迹信息、道路信息等编码成矢量vector。
3.2 如何编码?
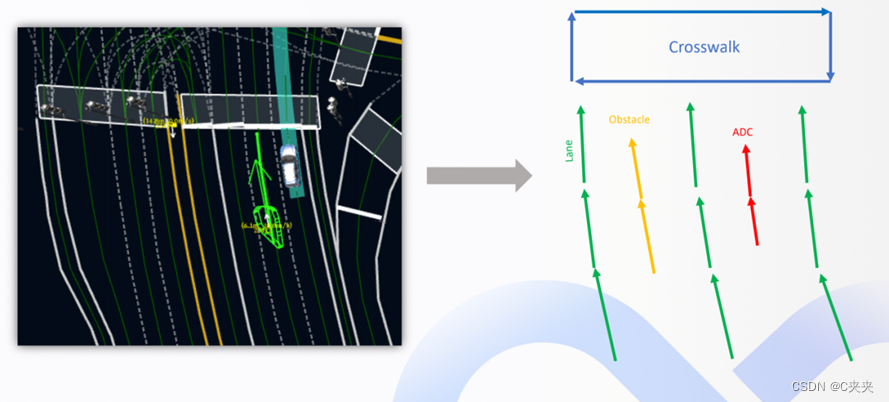
在Apollo7.0的设计中,蓝色表示人行道,四个向量的四条边均是有效的,连接后用以表示人行道;道路边缘是指polyline(图中的多线段)也是以向量的方式形成;障碍物(obstacle)轨迹和自车 ADC 轨迹同理。用这种方式,可以将左边的仿真图变成了右边编码后的图。
具体的结构化数据存储信息编码过程如下:
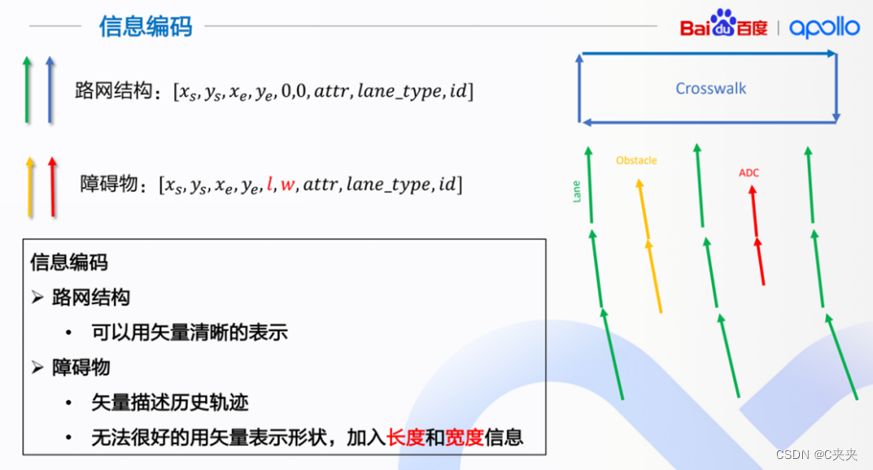
- 信息编码环节
- Xs,Ys为起始点的横纵坐标;Xe,Ye 为结束点的横纵坐标;
- attr是需要额外放置的属性;
- lane_type 是判断线端是什么类型,虚线or实线,双黄线or单黄线;
- id是指每条路的标识;
- 障碍物中的l,w,对应路网的 0,0,是指障碍物的长和宽。
- 信息编码完成后
将其抽象理解为以下彩虹图,每个图都由多个矢量组成,不同颜色的方块都表示不同的九维矢量(红色为主车轨迹、黄色为障碍物轨迹、绿色为道路、蓝色为人行道)。每一列描述为多线段,即多矢量的一个线段,表示一个完整的物体。
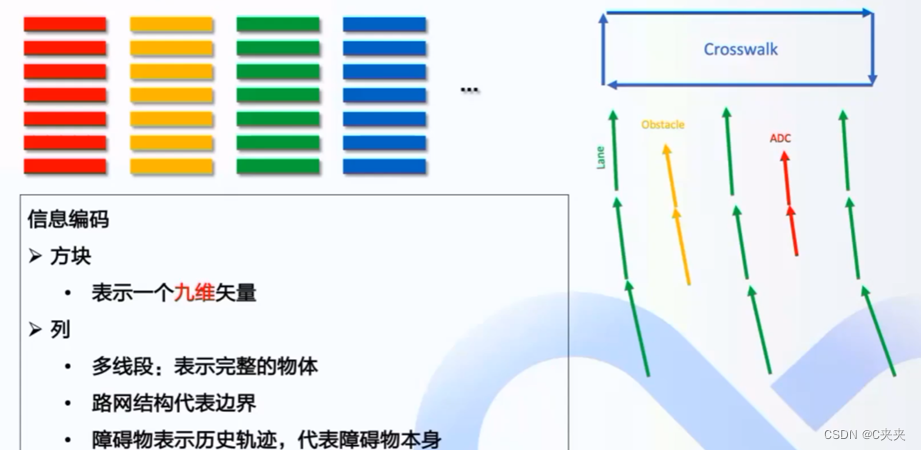
3.3 信息编码后
3.3.1 总体框架

编码后形成的不同颜色的色块。每一个色块其又由多种子元素构成。例如绿色(表示道路)由三段构成,轨迹则被分为两段。之后需要完成的任务:1、形成子图;2、全局图的交互;3、输出最终的语义地图
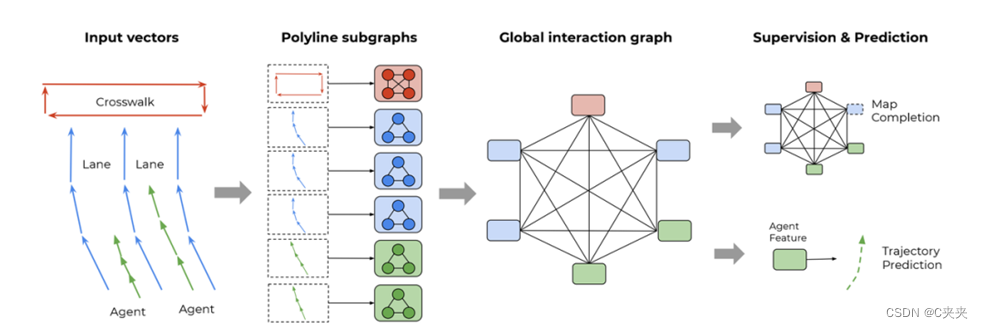
3.3.2 子图
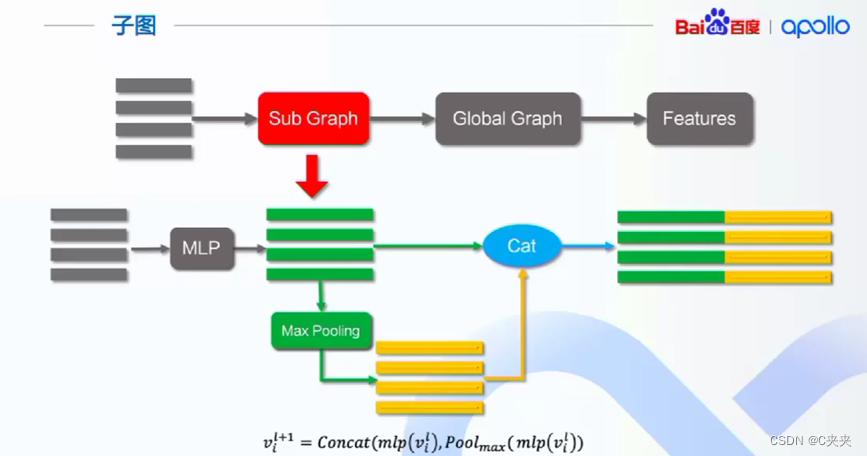
- 作用:专门处理矢量,表示每一个向量特征进行处理
- 步骤:首先利用MLP将九维数据提升到高维空间,然后进行最大池化,再进行拼接,完成子图的处理。
- 在子图阶段,每一个元素进行一次全连接,让每个元素之间产生联系。例如:将红色人行道(crosswalk)的每一条边全连接在一起,lane和轨迹也是如此。
- 子图的网架构:
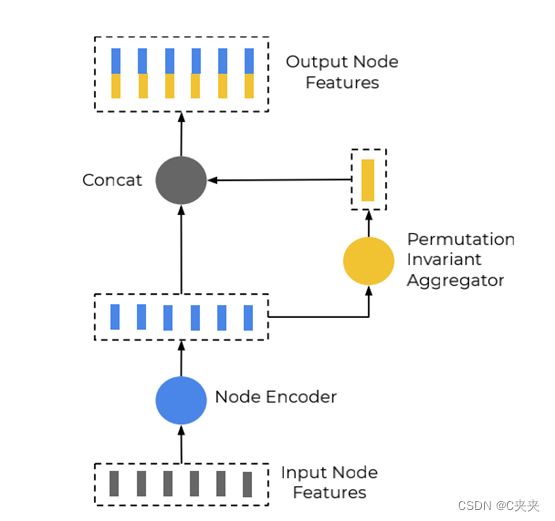
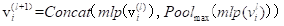
- 详细解释:
- Node Encoder用的是MLP,即全连接的一个网格结构,将数据相关联提升到高维空间。
- Permutatation Invariant Aggregator 使用的是Max Pooling,最大值池化。
- 在VectorNet中,在MLP上包裹了一层GCN,从而使得有连接关系的节点(每一条轨迹都带有前后指向关系的节点组成)能够进行特征层面的传播。Apollo这里单纯采用了MLP,我们猜测可能会在特征层损失一部分向量信息(节点与节点的连接关系)。
- 在考虑部署情况时,需要将我们的模型使用TorchScript的jit方法导出成一个中间状态,才可以以ONNX的形式或在C++平台上部署。GCN当前对TorchScript的导出还不友好,比如GCN通常采用torch_gemotric.data 来进行数据输入,而如果想通过TorchScript进行导出,则只支持tensor的形式;以及在某些算子层,TorchScript也不直接支持GCN的导出。因此单独使用MLP反而是一个更加朴适的方法。
3.3.3 全局图
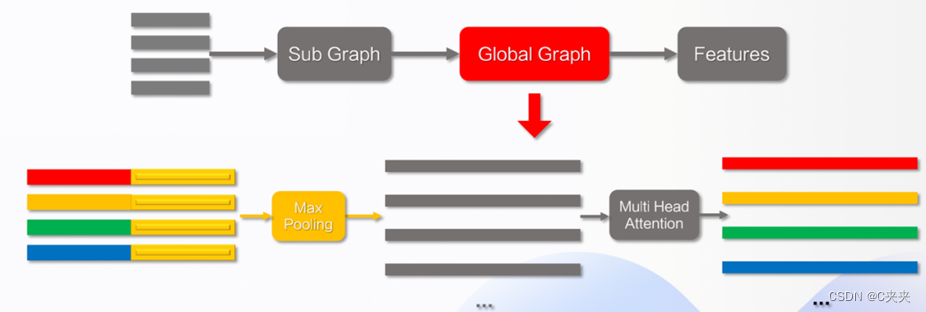
- 作用:对所有的向量进行处理,用来处理多线段。经过全局处理后,可得到每个物体的特征向量。
- 内容:这部分是对每个完整的物体做处理,这一部分会对所有的物体都会做一个交互。这里交互既包含了车辆,也包含了路网在内。
- 步骤:拿到子图特征后,做一个最大池化,再使用multi head attention来进行全局交互。下面的公式是multi head attention的计算过程。

- MultiHeadattention的具体操作:把Attention加在一起。Attention是指之前的特征(P)经过Q 矩阵,T K矩阵,V 矩阵,之后再做softmax合在一起。基本意思是指第一层进来的东西,经过Max Pooling,再经过Self Attention 运算,就会输出整体的这个结果。
Attention 机制
对于一个图像而言,当对其进行预测,或是做类似YOLO的目标检测或图像分类,其特征是对于整张图而言的。但Attention机制下会采用某些权重比,让其对某一部分的区域产生兴趣,这部分会多学。例如照片中的某个位置有只狗,这个位置的权重相对会高一点。Apollo这里用的是 self Attention,核心思想是使全局图的元素产生更多的交互,产生更多的兴趣点。
3.3.4 输出最终的语义地图
最后输出为每一个物体所对应的特征向量,然后取出需要的特征向量进入下一步处理流程。
4 轨迹生成器
《VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation》这篇论文原文在经过编码后,直接使用了比较通用的方法作为解码器,生成目标预测的轨迹点。
而Apollo7.0中经过编码后,使用类似于TNT (Target-driveN Trajectory Prediction)思想的方式进行轨迹预测。
4.1 总体框架

在实际道路上采一些样点,称为候选点(图中的菱形样点),根据候选点,预测可能会到达的选中点(图中所示的星点),最后由可到达的选中点,决定可能会生成何种轨迹。即从一堆点中学习出一些真正可能去到的选中点,再学习出从当前位置到选中点的轨迹。
预测任务分为三步:
- 给定环境的context,估计每个候选点的可能性,从而选择概率高的候选点,下图分别用钻石和星星表示候选点和选中点;
- 根据目标,估计每个选定目标的轨迹(分布);
- 对所有的轨迹进行排名的评分和选择。
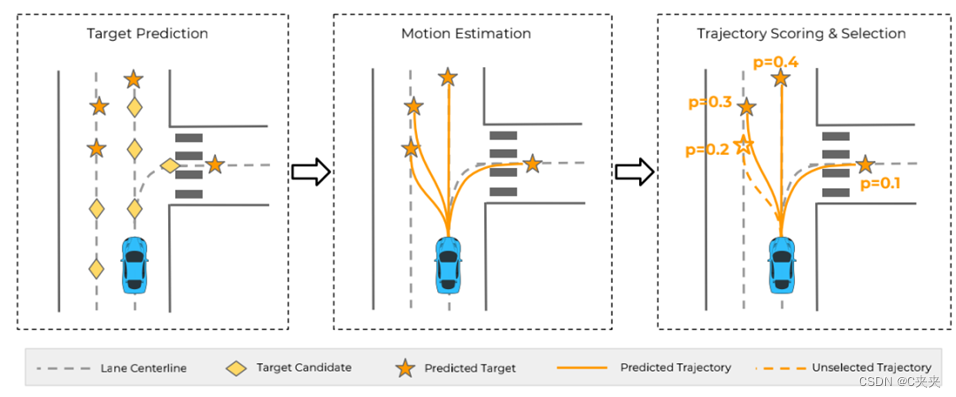
Target -> 轨迹 -> 轨迹概率分布 -> 轨迹交互
4.2 Target
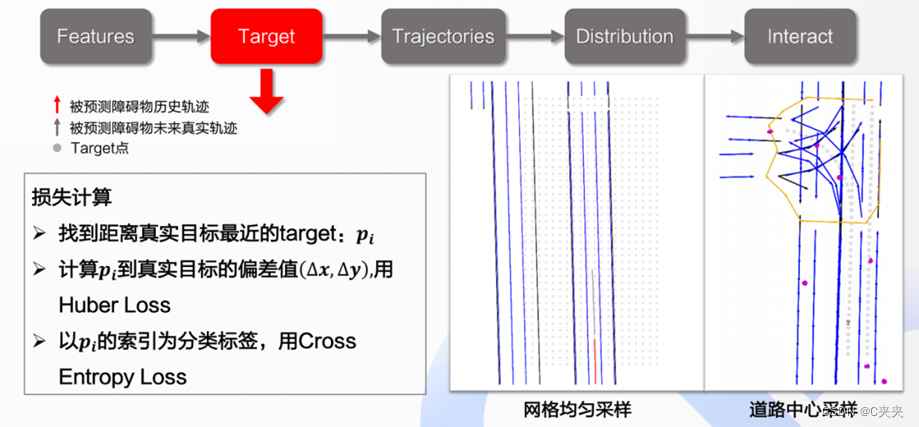
- 将概率估计转换为分类任务:对Target点的计算方式
假设过去的状态: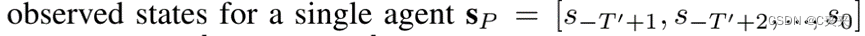
预测未来的状态:
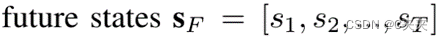
用真实的Target拼接特征向量来生成预测的轨迹,用生成的轨迹和真实轨迹做一个Huber loss。
使用X=(Sp,Cp)表示所有的过去状态,就是要尝试估计 p(sF |x):给定过去状态未来状态的边缘概率。Cp 代表着此时的背景(环境)
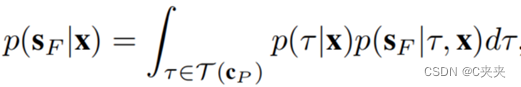
核心思想:通过设计目标空间τ(Cp) (候选点位置), 候选点分布p(τ|x)可以很好地捕捉意图不确定性。一旦确定了目标,进一步证明了控制不确定性(轨迹)可以通过简单的单峰分布可靠地建模。通过一组离散位置来近似目标空间τ(Cp),将p(τ |x)的估计转化为一个分类任务。
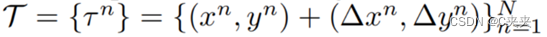
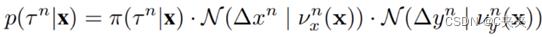
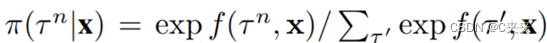
在以上的公式中,N 表示广义的正态分布,Huber作为距离函数,平均值表示为v。可训练功能 f和v由两层多层感知器(MLP)实现,目标坐标和场景上下文特征作为输入。他们预测目标位置上的离散分布及其最可能的偏移量。
最终核心:分类问题,每个候选点到底哪个属于哪一个选中点(星点)。
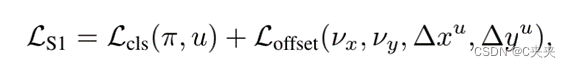
Loss:Lcls是交叉熵,Loffset是HuberLoss,u是预测选中点离最近的真值选中点的距离。
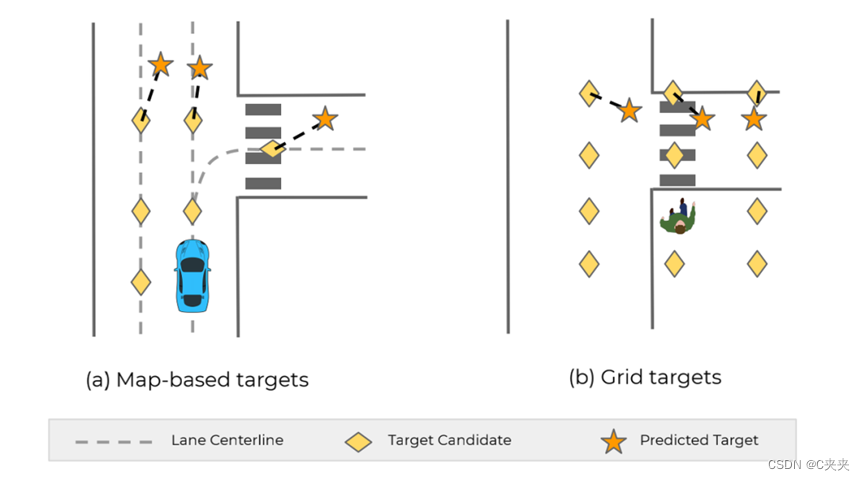
- Target的选取原则:尽可能覆盖车辆的行驶区域/车辆可能的行驶车道,选取的范围和密度都必须适中
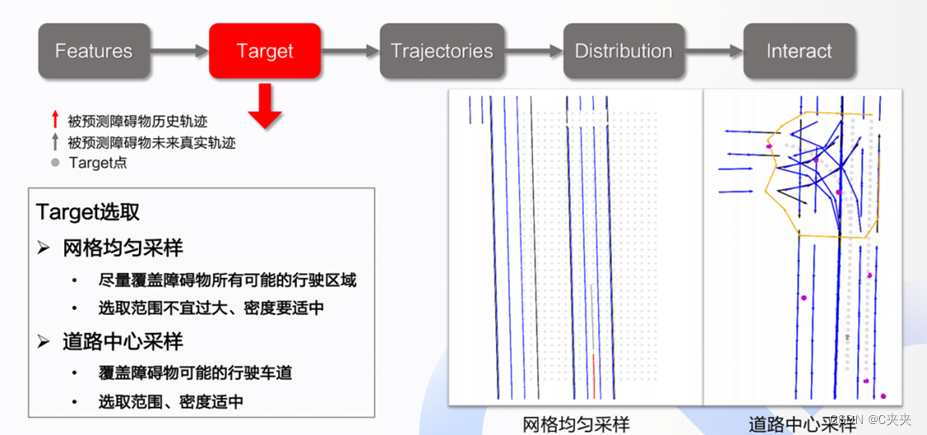
- 损失计算
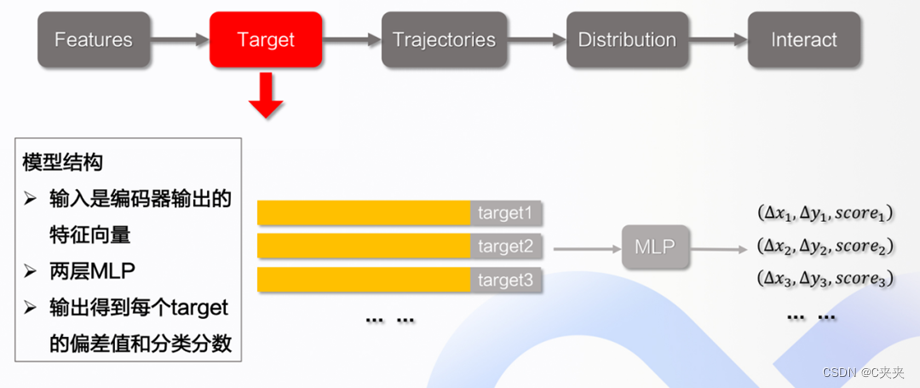
- 模型结构
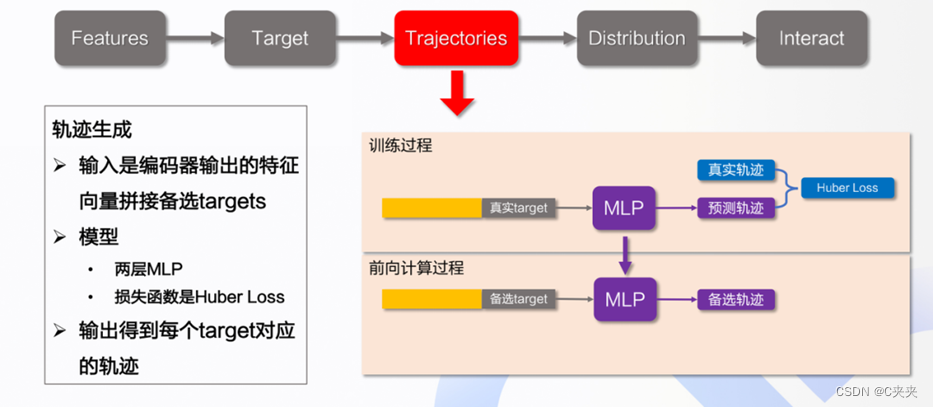
4.3 Trajectories
在得到选中点之后,根据选中点生成轨迹。输入为编码器输出的特征向量,再与每一个Target进行拼接,过了MLP之后,得到每个每个Target的偏差值和分类分数。
两个假设:时间步长时条件独立的,即时间上步与步的预测是独立的,可以使模型避免顺序预测,提高计算效率;对一个选中点只有一条最大概率的Trajectory,这样的轨迹分布为正态单峰分布的,这在短期内肯定是正确的;对于较长的时间范围,可以在(中间)目标预测和运动估计之间进行迭代,这样假设仍然成立。
总而言之,通过两层的MLP来预测每一个Target的轨迹SF,它将上下文特征X和目标位置τ作为输入,并为每个目标输出一条最可能的未来轨迹。由于它是以第一阶段的预测目标为条件的,为了使学习过程顺利进行,训练时通过输入位置真值作为目标。
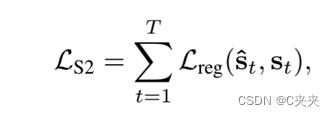
损失函数则是预测轨迹与真实轨迹的差值,这么做期望达到生成轨迹最后一个点,跟Target的点尽可能的重合。
4.4 Distribution
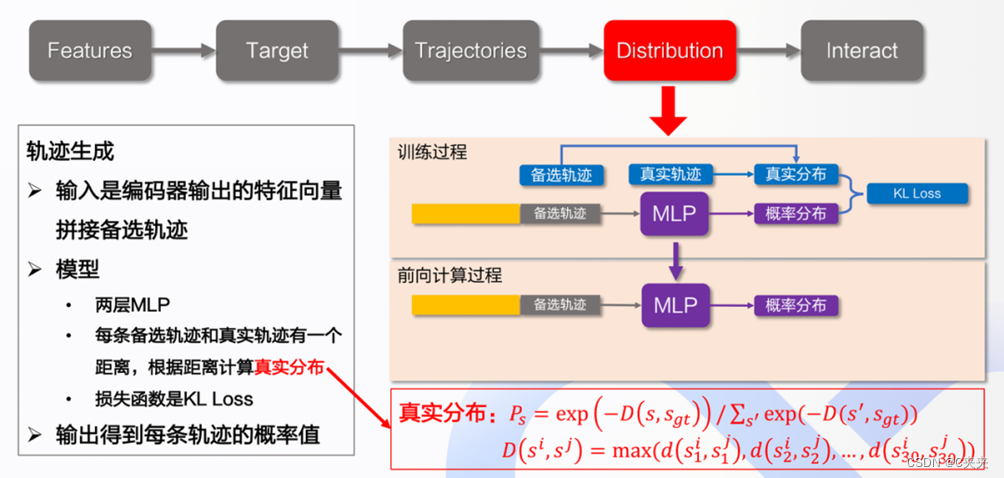
- 这一部分为Apollo7.0版本的新增部分。
- 轨迹生成分成两部分,第一部分为训练过程,第二部分为前向计算过程。
- 训练过程:编码器得到的特征向量再拼接备选轨迹,得到每个备选轨迹的概率值,得到每一个概率值分类的分数,即根据轨迹去计算轨迹的一个概率分布,真实分布(计算公式见图)是指被选轨迹距离真实轨迹越近时,它的概率越高。
- 前向计算:计算备选轨迹的概率分布。
4.5 Interaction
这一部分为Apollo7.0版本的新增部分。
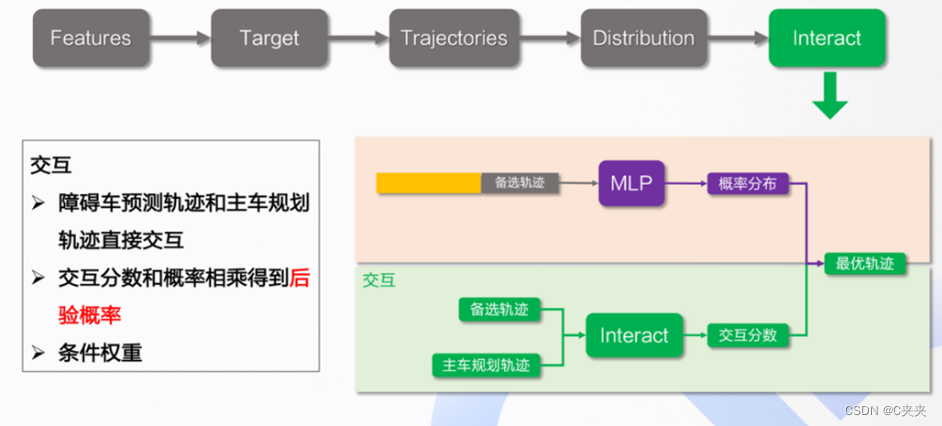
4.5.1 后验概率
前文所考虑了障碍车预测轨迹和环境的影响,但还需要与主车规划轨迹进行交互打分,去选择最优轨迹。例如交互前该障碍车预测轨迹为0.8 分,和主车的轨迹交互后可能不再是 0.8 分,可能会重新打分。即交互分数*概率=后验概率。
4.5.2 交互情况
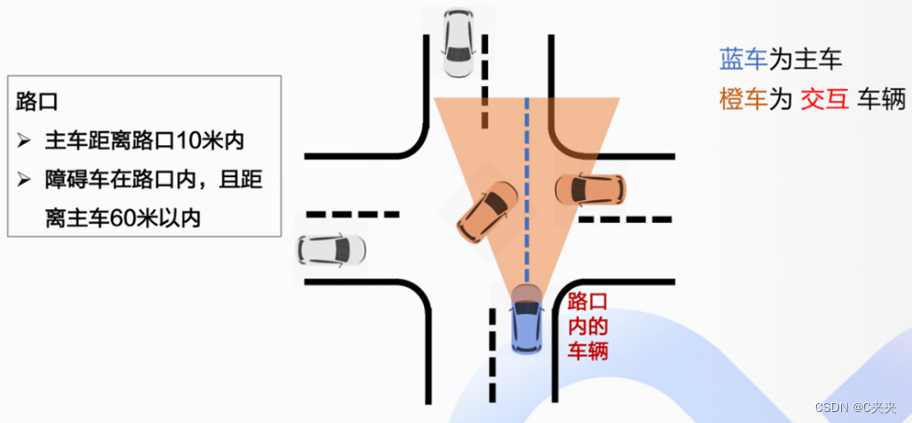
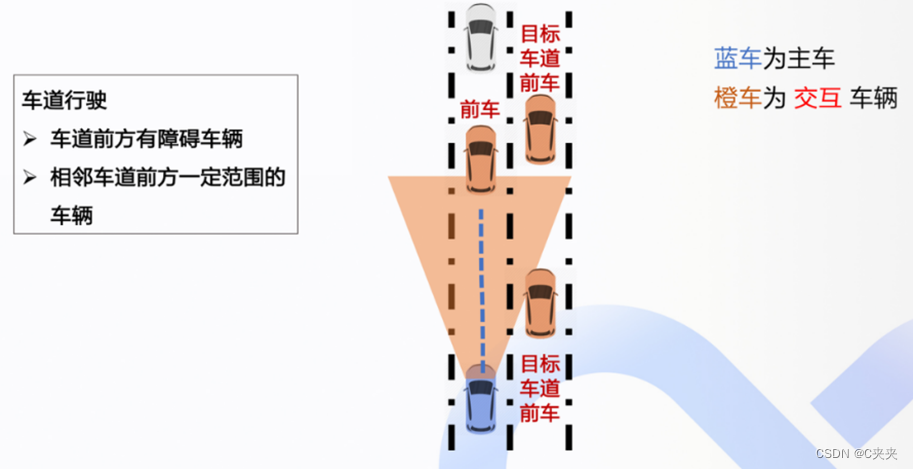
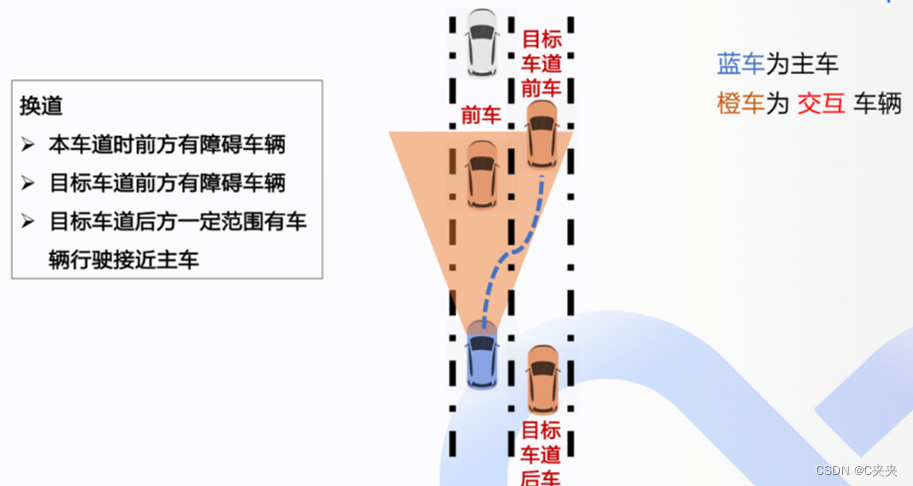
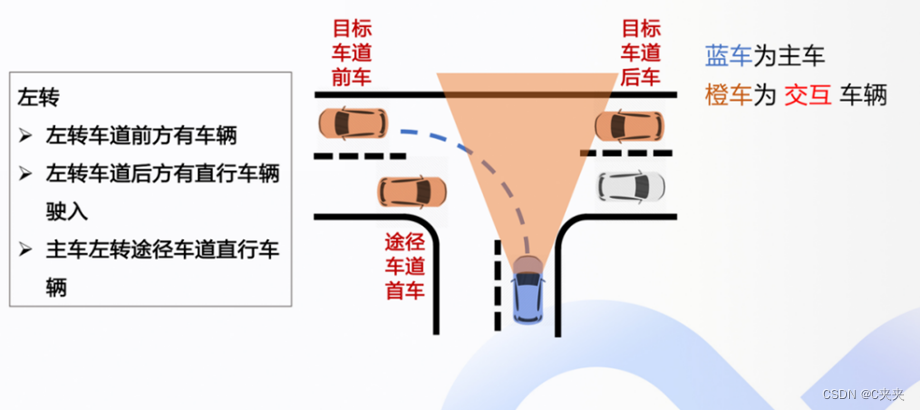
4.5.3 交互分数计算
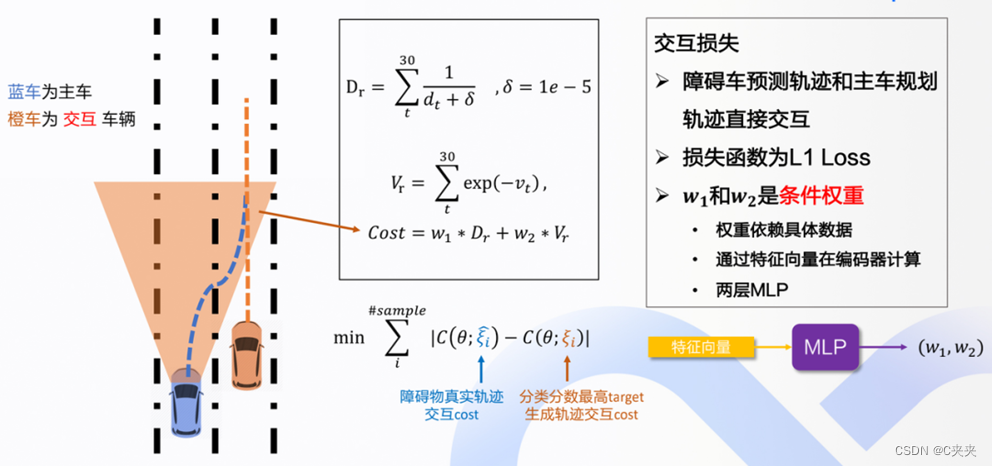
- 交互是通过两个轨迹之间的直接交互实现的。假如说50条备选轨迹,就会有50条交互分数(用cost表示)。是指交互的严重程度,如果cost较大,说明危险程度较大,会削弱对该条预测轨迹的发生概率。
- 预测轨迹与规划轨迹之间的时间看齐。预测未来3s,时间间隔0.1s,共用30个选中点。
- 30个选中点之间的相对距离(D)累加,30个点的相对速度(V)累加起来,两项经过两个条件权重(W1和 W2)进行加权,之后相加得到交互分数cost。如果距离越近,那么cost越大;如果速度差距越大,那么cost也越大。
- W1和 W2这两项条件权重是通过编码器的特征向量,经过MLP实现的。
5 预测效果演示

- 第一张图为最原始的环境编码后的矢量图。
- 第二张图为选中点预测结果(即上文所述的星点)。
- 第三张图是备选轨迹生成,根据每个选中点的位置生成了相应的轨迹。
- 第四张图是最优轨迹的选择,通过本身的轨迹预测分数和主车轨迹的交互分数,得到一个最优轨迹。
测试指标
衡量预测效果的好坏,(TNT)论文使用的是MR、MinFDE、MinFDE和DAC几个指标来进行衡量。
- MR (Miss Rate,缺失率) | 描述检测结果中的漏检率的指标
- minFDE( Minimum Final Displacement Error , 最小最终距离误差) | 对于 N个预测轨迹,选择预测终点与真值预测误差最小的作为评估结果
- minADE( Minimum Average Displacement Error,最小平均距离误差 ) | 对于N个预测轨迹,选择平均轨迹预测点与真值预测误差最小的作为评估结果
- MinFDE | 只能评估最好的估计有多好,但不能评估所有轨迹的优劣
- DAC(Drivable Area Compliance ,如果模型产生n个可能的未来轨迹,并且其中m个轨迹在某个点离开可移动区域,则该模型的DAC为(nm)/ n。因此,较高的DAC意味着更好的预测轨迹质量。如果存在n个样本,并且其中m个具有其最佳轨迹的最后一个坐标距离地面真值超过2.0 m,则未命中率为m / n。
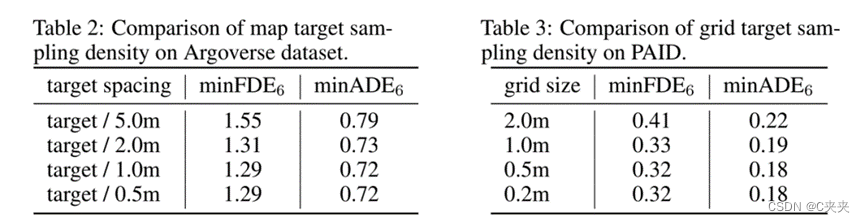
表2及表3分别为在地图采样时样点取点距离的效果对比,表2为车辆检测中取样的效果,可以看出每1m取一个样点可性价比最优。表3为行人检测中的取样效果,可以看出每0.5m取一个样点可性价比最优。
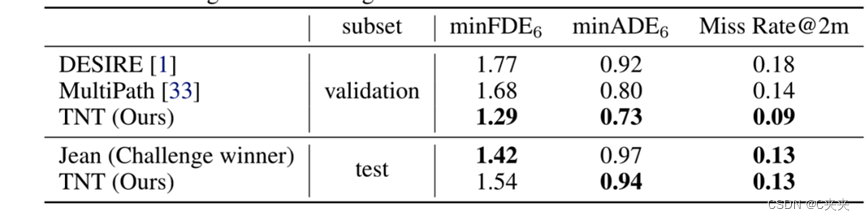
从下图的检测结果的测评指标来看,TNT的效果较好。
6 总结
当前Apollo 7.0的轨迹预测由于有许多工程化方法,尚未提供量化分析其性能的方法或指标。我们可以通过剥离其代码,使用到传统轨迹预测的评测指标上来。但不可否认的是,由于TNT本身方法在之前轨迹预测中表现较好,且其改进版本DenseTNT也拿到了相关比赛的第一名,我们认为该方法对于准确性是有依托的。
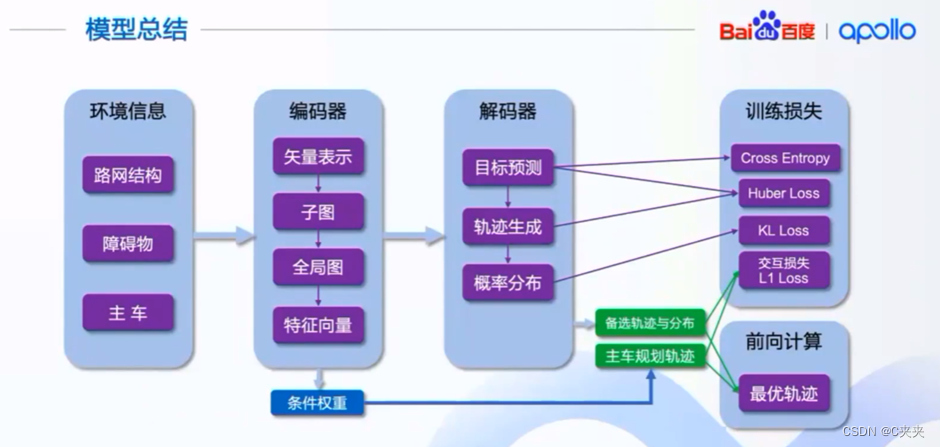
编码器得到每一个物体的特征向量,通过特征向量得到条件权重,解码器部分通过特征向量得到备选的轨迹。
预测挑战:

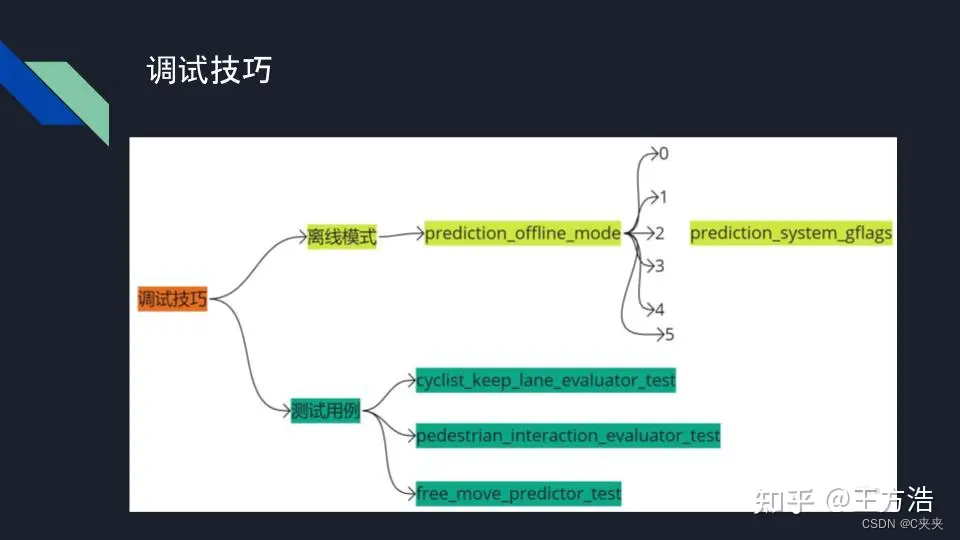
附: 调试技巧
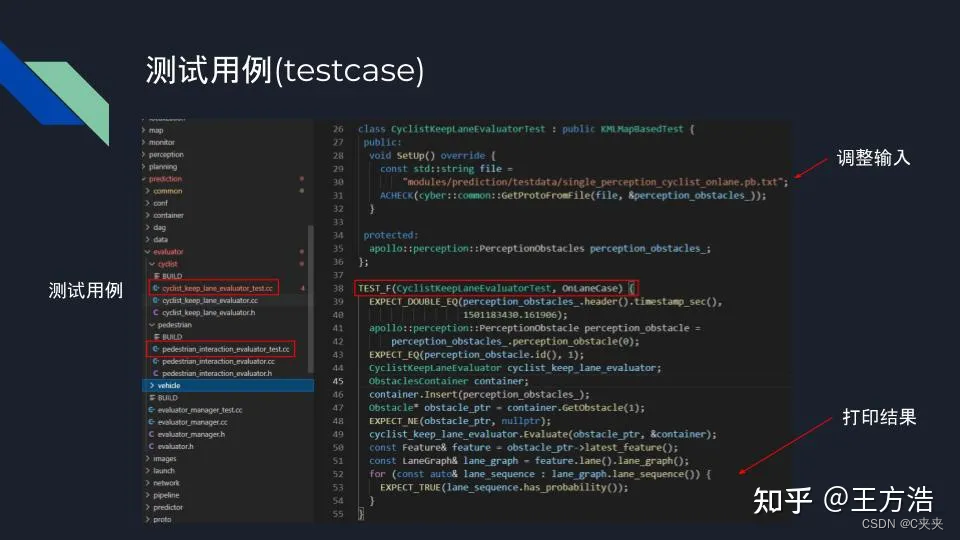
Apollo的预测模块有2种调试方式,一种是离线模式,另外一种是跑测试用例。
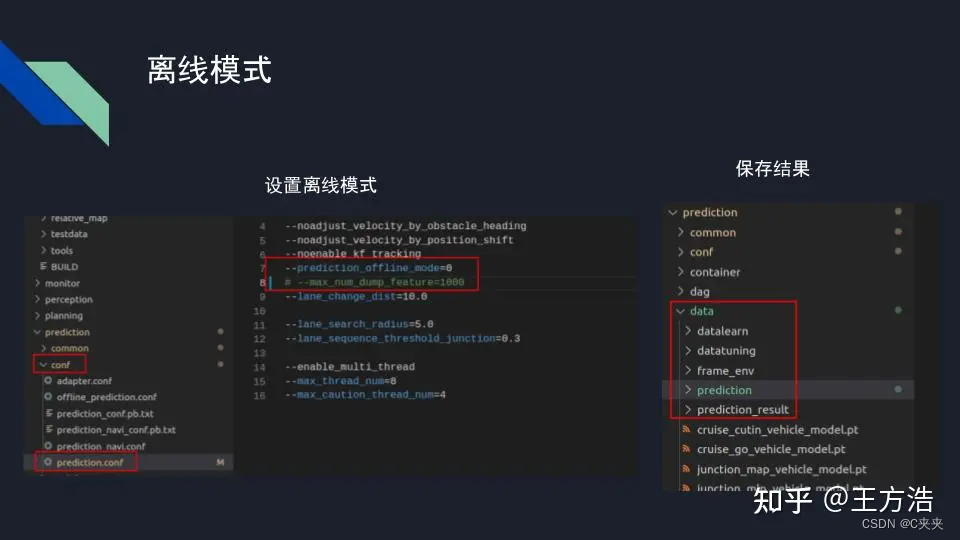
离线模式的打开方式如下
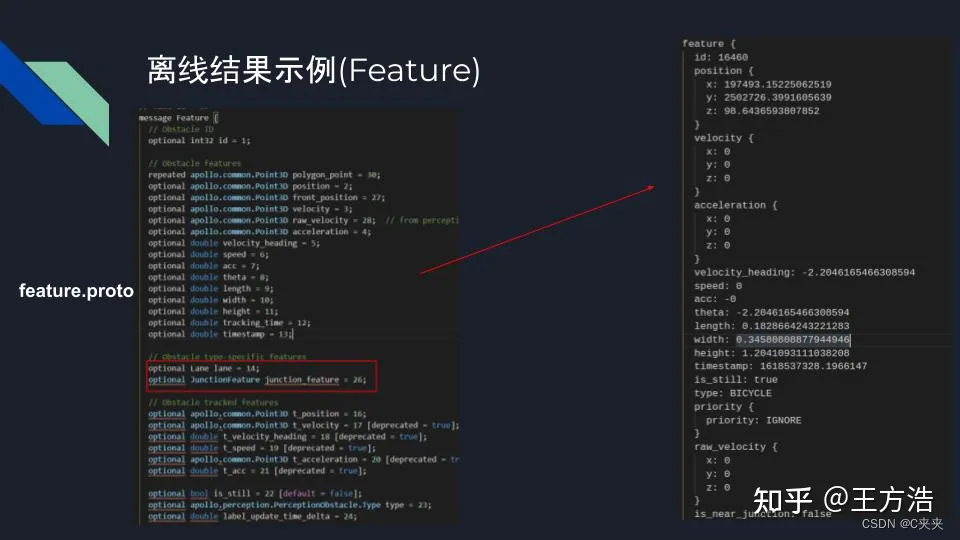
离线模型的结果是一些特征和预测的信息,可以帮助我们分析。
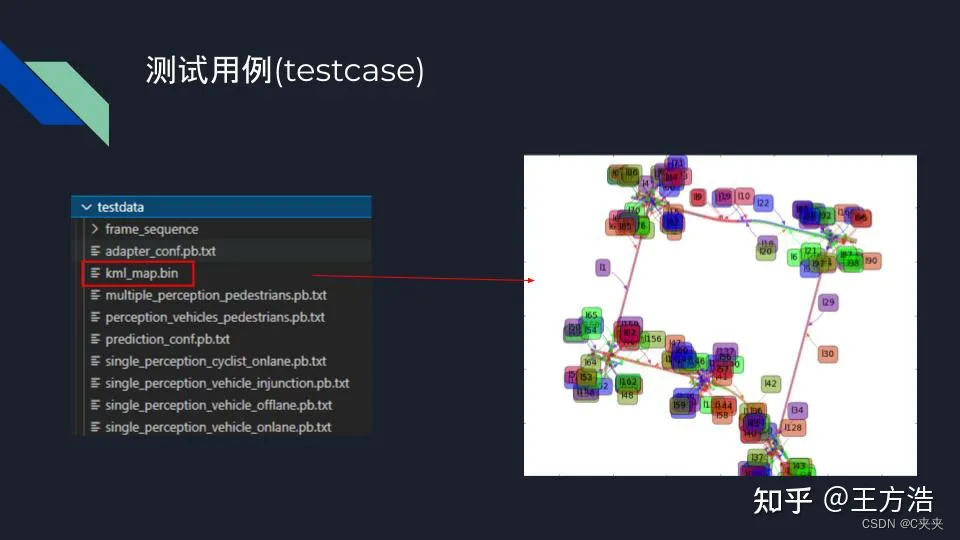
预测用到的地图是kml_map.bin,下面是可视化的结果。
 然就可以结合地图和每个评估器、预测器的测试用例来熟悉和测试它们的功能。
然就可以结合地图和每个评估器、预测器的测试用例来熟悉和测试它们的功能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









