






摘要:我们提出了Seed1.5-VL,这是一个视觉语言基础模型,旨在推进通用多模态理解和推理。 Seed1.5-VL由一个532M参数的视觉编码器和20B活动参数的混合专家(MoE)LLM组成。 尽管其架构相对紧凑,但在广泛的公共VLM基准和内部评估套件中提供了强大的性能,在60个公共基准中的38个上实现了最先进的性能。 此外,在以代理为中心的任务中,如GUI控制和游戏,Seed1.5-VL的表现优于领先的多模态系统,包括OpenAI CUA和Claude 3.7。 除了视觉和视频理解之外,它还展示了强大的推理能力,使其在视觉谜题等多模态推理挑战中特别有效。 我们相信这些能力将使跨不同任务的更广泛的应用成为可能。 在本报告中,我们主要全面回顾了我们在跨模型设计、数据构建和不同阶段的训练中构建Seed1.5-VL的经验,希望本报告能够激发进一步的研究。 现在可以在www.volcengine.com。Huggingface链接:Paper page,论文链接:2505.07062
研究背景和目的
视觉语言模型 (VLM) 作为一种新兴的人工智能范式,旨在使通用 AI 能够感知、推理和行动于开放式的虚拟和物理环境中。通过将视觉和文本模态统一于一个模型中,VLM 在多模态推理、图像编辑、GUI 代理、自动驾驶和机器人等领域取得了显著进展,并应用于教育、医疗保健、聊天机器人和可穿戴设备等实际场景。然而,当前的 VLM 仍存在局限性,尤其是在需要 3D 空间理解、对象计数、想象性视觉推理和交互式游戏等任务中。这些局限性突显了 VLM 开发的内在挑战,例如:
-
标注数据稀缺: VLM 缺乏与大型语言模型 (LLM) 相当丰富且多样化的视觉-语言标注数据,尤其是在基于低级感知现象的概念上。
-
多模态数据异质性: 多模态数据的异质性为训练和推理带来了额外的复杂性,例如数据管道设计、并行训练策略和评估协议。
为了解决这些挑战,本研究开发了 Seed1.5-VL,一个用于视觉语言理解的多模态基础模型。该模型旨在通过以下方式提升 VLM 的能力:
-
数据合成: 开发了一套针对关键能力(如 OCR、视觉定位、计数、视频理解和长尾知识)的数据合成管道,以及在训练后阶段用于视觉谜题和游戏的管道。
-
预训练: 在包含图像、视频、文本和人类-计算机交互数据的数十万亿个多模态标记上进行预训练,以获取广泛的视觉知识和掌握核心视觉技能。
-
后训练: 结合人类反馈和可验证奖励信号,进一步增强其通用推理能力。
-
训练优化: 针对多模态模型架构的不对称性,开发了一种混合并行方案和视觉标记重新分配策略,以平衡 GPU 工作负载,并提高训练效率。
研究方法
本研究采用以下方法来构建和评估 Seed1.5-VL:
-
数据收集和预处理: 收集了涵盖图像、视频、文本和人类-计算机交互数据的数十万亿个多模态标记。针对不同能力,开发了数据合成管道,例如 OCR、视觉定位、计数、视频理解和长尾知识等。
-
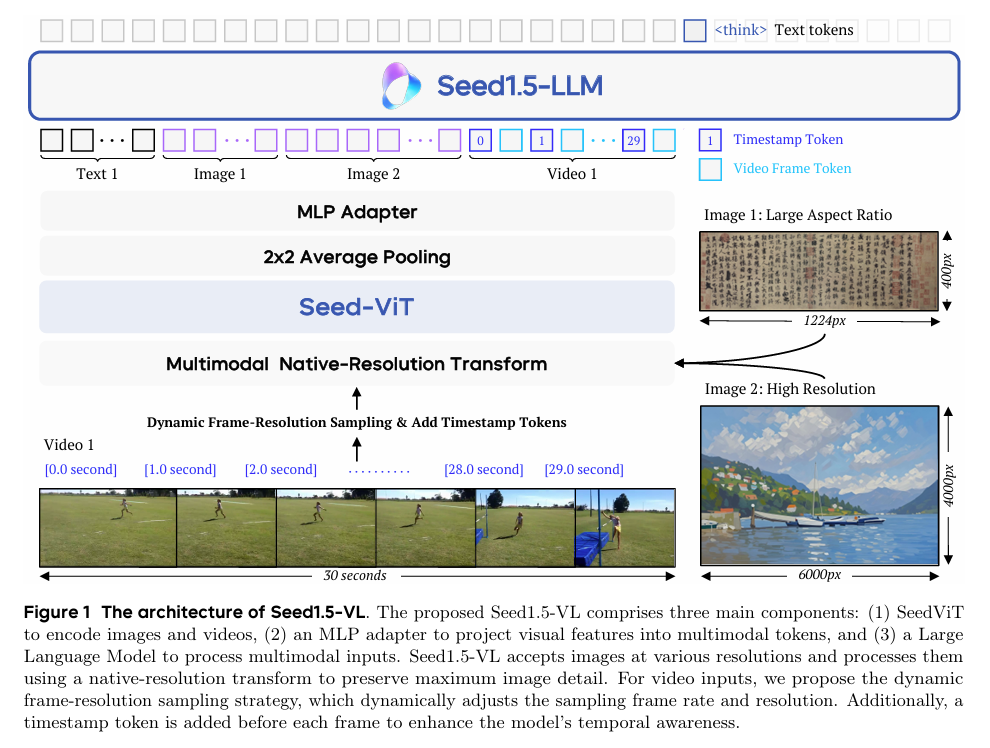
模型架构: 种子1.5-VL 由三个主要组件组成:视觉编码器、MLP 适配器和大型语言模型 (LLM)。视觉编码器支持动态图像分辨率,并采用 2D RoPE 进行位置编码。MLP 适配器将视觉特征投影到多模态标记中。LLM 处理多模态输入。
-
预训练: 种子1.5-VL 的预训练分为三个阶段:
-
掩码图像建模 (MIM): 使用 2D RoPE 提高视觉感知能力,尤其是在视觉几何和结构意识方面。
-
原生分辨率对比学习: 将视觉编码器初始化为 MIM 训练的学生模型,并使用 SigLIP 和 SuperClass 损失进行优化。
-
全模态预训练: 采用 MiCo 框架,构建包含视频帧、音频、视觉字幕和音频字幕的视频数据元组,并通过对齐这些嵌入来学习统一的跨模态表示。
-
-
后训练: 使用监督微调 (SFT) 和强化学习 (RL) 来增强 Seed1.5-VL 的指令遵循和推理能力。SFT 数据集包含通用指令数据和长链推理 (LongCoT) 数据。RL 使用人类反馈和可验证奖励信号来进一步提升模型性能。
-
训练基础设施: 开发了一种混合并行方案来并行化视觉编码器和语言模型,并使用工作负载平衡、并行感知数据加载和容错机制来提高训练效率。
-
评估: 在公共基准和内部基准上评估 Seed1.5-VL 的性能,涵盖视觉推理、定位、计数、视频理解和计算机使用等任务。
研究结果
-
公共基准: 种子1.5-VL 在 60 个公共基准中取得了最先进的性能,包括 38 个视觉-语言基准、19 个视频基准和 7 个 GUI 代理任务中的 3 个。
-
内部基准: 在内部基准上,种子1.5-VL 在 OOD、代理、原子指令遵循和 STEM 等类别中取得了最先进的性能,并展现出强大的推理和知识检索能力。
-
多模态代理: 在 GUI 交互和游戏等代理任务中,种子1.5-VL 超越了 OpenAI CUA 和 Claude 3.7 等领先的多模态系统。
-
定性示例: 种子1.5-VL 能够解决复杂的视觉推理任务(如 Rebus 谜题)、解释和纠正视觉输入中的代码、作为计算机交互和游戏的代理,并生成基于图像的创意文本。
研究局限
-
精细视觉感知: 在复杂视觉感知任务中,种子1.5-VL 在准确计数对象、识别图像中的细微差别以及精确解释复杂空间关系方面存在困难。
-
推理能力: 在复杂推理任务中,种子1.5-VL 在解决 Klotski 拼图、导航简单迷宫等任务时表现不佳,并存在组合搜索方面的挑战。
-
3D 空间推理: 在 3D 空间推理任务中,种子1.5-VL 存在局限性,例如 3D 对象操作和 3D 对象投影方面的推理。
-
幻觉: 种子1.5-VL 仍然存在幻觉问题,尤其是在视觉输入与语言模型知识发生冲突时。
-
时间推理: 种子1.5-VL 在处理连续动作的时序和推断物体之间顺序方面存在困难。
-
多图像推理: 种子1.5-VL 在需要综合多个图像中的线索进行推理的任务中表现不佳。
未来研究方向
-
统一的视觉链式推理: 将图像生成能力纳入基础模型,以增强视觉链式推理机制,从而提高模型的推理能力和鲁棒性。
-
工具使用机制: 将代码使用和其他外部工具纳入 VLM 框架,以解决组合搜索等复杂推理任务的挑战。
-
改进的视觉感知能力: 研究和开发更先进的视觉感知技术,例如改进的对象计数、图像差异识别和空间关系理解,以提高模型的准确性和鲁棒性。
-
减少幻觉: 研究和开发更有效的幻觉缓解技术,例如基于视觉感知的幻觉检测和基于强化学习的幻觉消除。
-
增强的时间推理能力: 研究和开发更强大的时间推理技术,例如基于视频分析的时序事件识别和基于多模态融合的时间序列预测。
-
多图像推理: 研究和开发更有效的多图像推理技术,例如基于图神经网络的图像关系建模和基于强化学习的多图像推理。
本研究为 VLM 领域的发展做出了重要贡献,并为进一步研究提供了宝贵的经验和启示。随着技术的不断进步,VLM 将在未来发挥更大的作用,并为人工智能的发展做出更大的贡献。

















 2942
2942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









