






H264编码原理
一 、H264概述
H.264:同时也是MPEG-4第十部分,是由ITU-T视频编码专家组(VCEG)和ISO/IEC动态图像专家组(MPEG)联合组成的联合视频组(JVT,Joint Video Team)提出的高度压缩数字视频编解码器标准。H.264 不仅具有优异的压缩性能,而且具有良好的网络亲和性。和MPEG-4 中的重点是灵活性不同,H.264 着重在压缩的高效率和传输的高可靠性,因而其应用面十分广泛。
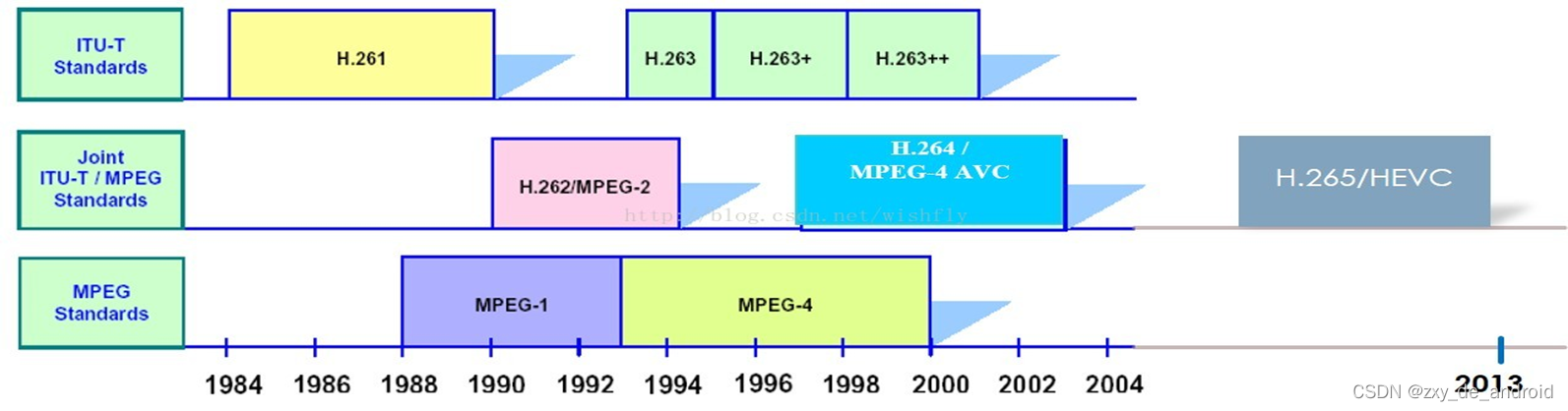
ITU-T 视频编码发展历程如图:
二 、H264的特点
1 、H264标准的主要特点如下
- 更高的编码效率: 同H.263等标准的特率效率相比,能够平均节省大于50%的码率。
- 高质量的视频画面: H.264能够在低码率情况下提供高质量的视频图像,在较低带宽上提供高质量的图像传 输是H.264的应用亮点。
- 提高网络适应能力: H.264可以工作在实时通信应用(如视频会议)低延时模式下,也可以工作在没有延时的视频存储或视频流服务器中。
- 采用混合编码结构: 同H.263相同,H.264也使用采用DCT变换编码加DPCM的差分编码的混合编码结构,还增加了如多模式运动估计、帧内预测、多帧预测、基于内容的变长编码、4x4二维整数变换等新的编码方式,提高了编码效率。
- H.264的编码选项较少: 在H.263中编码时往往需要设置相当多选项,增加了编码的难度,而H.264做到了力求简洁的“回归基本”,降低了编码时复杂度。
- H.264可以应用在不同场合: H.264可以根据不同的环境使用不同的传输和播放速率,并且提供了丰富的错误处理工具,可以很好的控制或消除丢包和误码。
- 错误恢复功能: H.264提供了解决网络传输包丢失的问题的工具,适用于在高误码率传输的无线网络中传输视频数据。
- 较高的复杂度: 264性能的改进是以增加复杂性为代价而获得的。据估计,H.264编码的计算复杂度大约相当于H.263的3倍,解码复杂度大约相当于H.263的2倍。
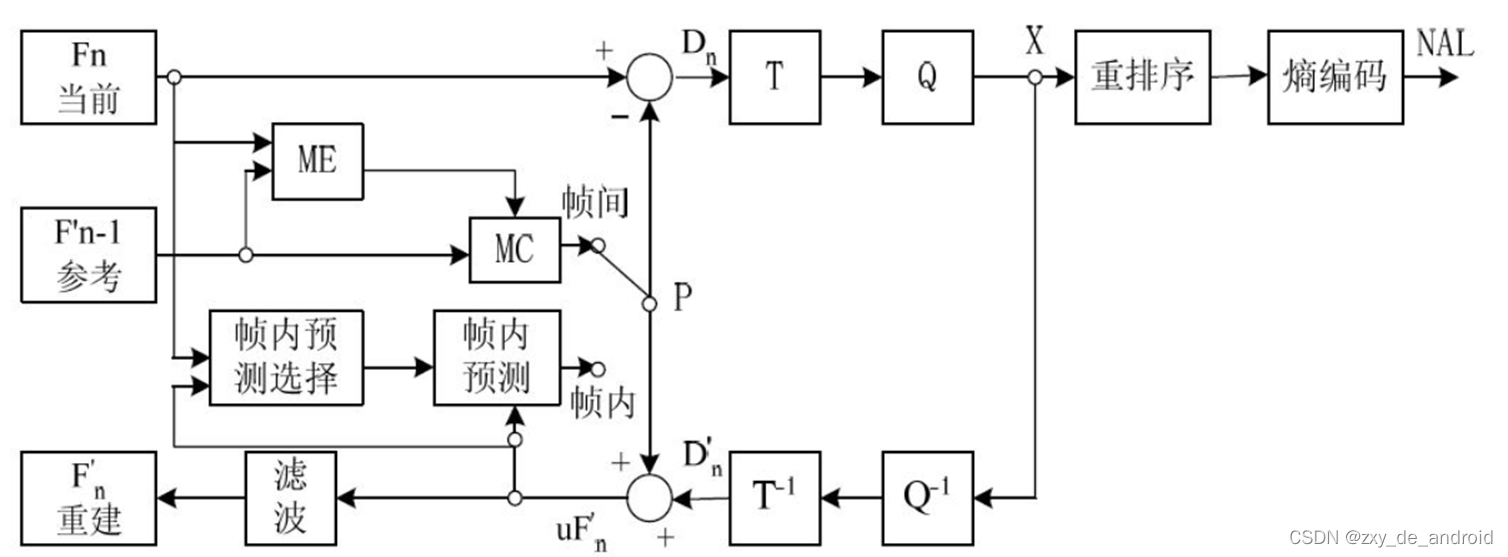
2 、编码器流程图
三 、H264压缩技术
H264压缩技术主要采用了以下几种方法对视频数据进行压缩
- 帧内预测压缩,解决的是空域数据冗余问题。
- 帧间预测压缩(运动估计与补偿),解决的是时域数据冗徐问题。
- 整数离散余弦变换(DCT),将空间上的相关性变为频域上无关的数据然后进行量化,CABAC压缩。
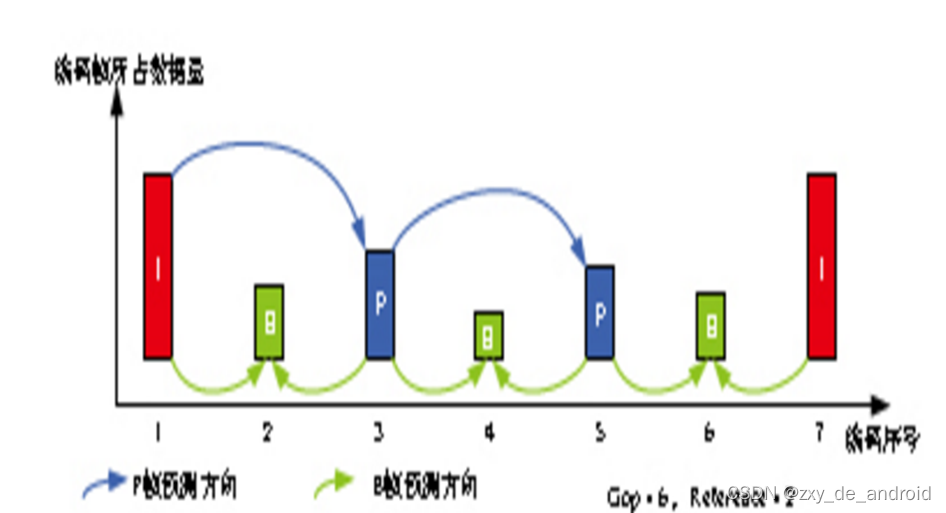
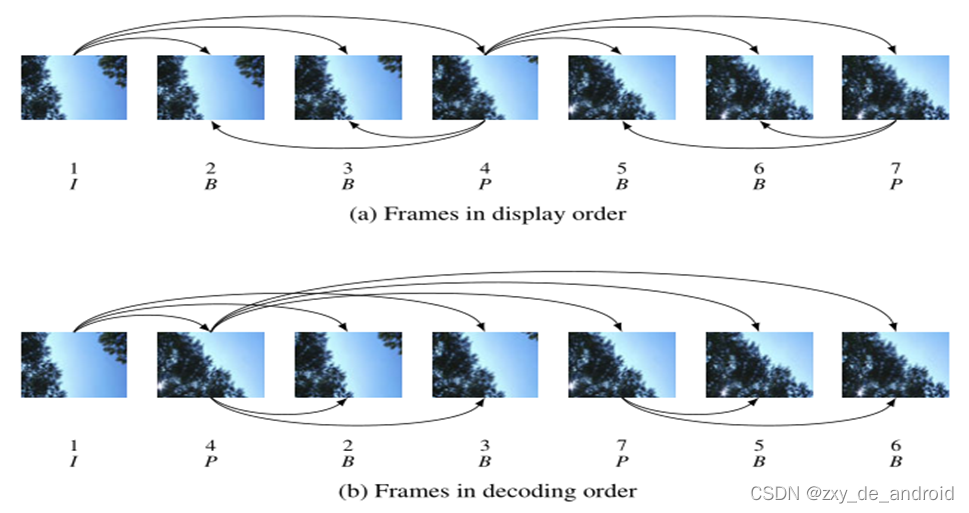
经过压缩后的帧分为:I帧,P帧和B帧
4. I帧:关键帧,采用帧内压缩技术。
5. P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。采用帧音压缩技术。
6. B帧:双向参考帧,在压缩时,它即参考前而的帧,又参考它后面的帧。采用帧间压缩技术。
7. 除了I/P/B帧外,还有图像序列GOP
1 、帧内预测压缩
(1)、宏块划分
- 通过摄像头采集到的视频帧(按每秒 30 帧算),被送到 H264 编码器的缓冲区中。编码器先要为每一幅图片划分宏块。
以下面这张图为例:

- 划分宏块
H264默认是使用 16X16 大小的区域作为一个宏块,也可以划分成 4X4 大小

- 划分好宏块后,计算宏块的象素值

- 以此类推,计算一幅图像中每个宏块的像素值,所有宏块都处理完后如下面的样子。

- 划分子块
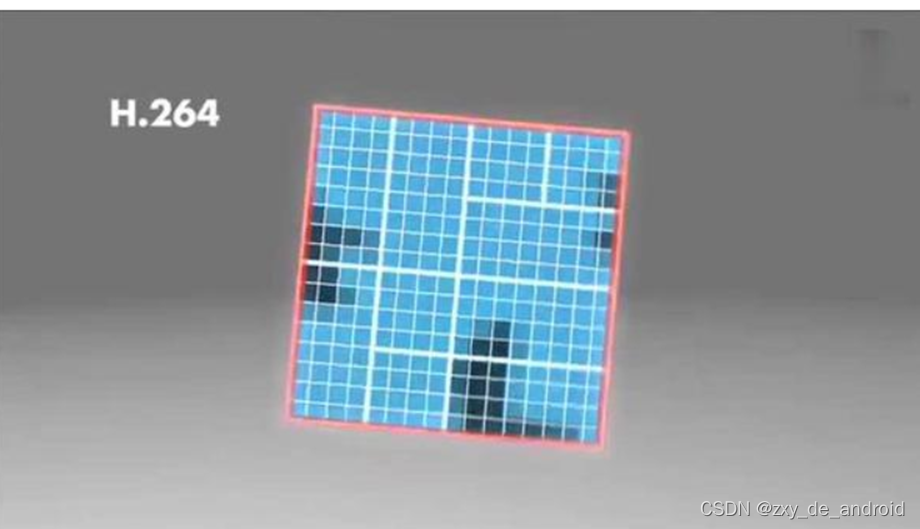
H264对比较平坦的图像使用 16X16 大小的宏块。但为了更高的压缩率,还可以在 16X16 的宏块上更划分出更小的子块。子块的大小可以是 8X16、 16X8、 8X8、 4X8、 8X4、 4X4非常的灵活。
- 左图中,红框内的 16X16 宏块中大部分是蓝色背景,而三只鹰的部分图像被划在了该宏块内,为了更好的处理三只鹰的部分图像,H264就在 16X16 的宏块内又划分出了多个子块。
(2)、帧内预测
-
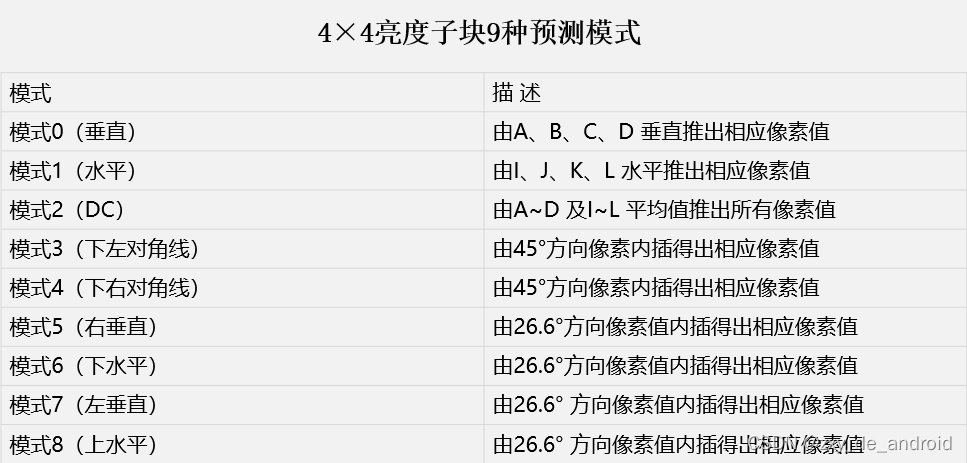
在帧内预测模式中,预测块P是基于已编码重建块和当前块形成的。对亮度像素而言,P块用于4×4子块或者16×16宏块的相关操作。4×4亮度子块有9种可选预测模式,独立预测每一个4×4亮度子块,适用于带有大量细节的图像编码;16×16亮度块有4种预测模式,预测整个16×16亮度块,适用于平坦区域图像编码;色度块也有4种预测模式,类似于16×16亮度块预测模式。编码器通常选择使P块和编码块之间差异最小的预测模式。
-
4×4亮度子块9种预测模式
-
4×4亮度预测模式:
如下图1所示,4×4亮度块的上方和左方像素A~M为已编码和重构像素,用作编解码器中的预测参考像素。a~p为待预测像素,利用A~M值和9种模式实现。其中模式2(DC预测)根据A~M中已编码像素预测,而其余模式只有在所需预测像素全部提供才能使用。如下图2箭头表明了每种模式预测方向。对模式3~8,预测像素由A~M加权平均而得。例如,模式4中,d=round(B/4+C/2+D/4)。
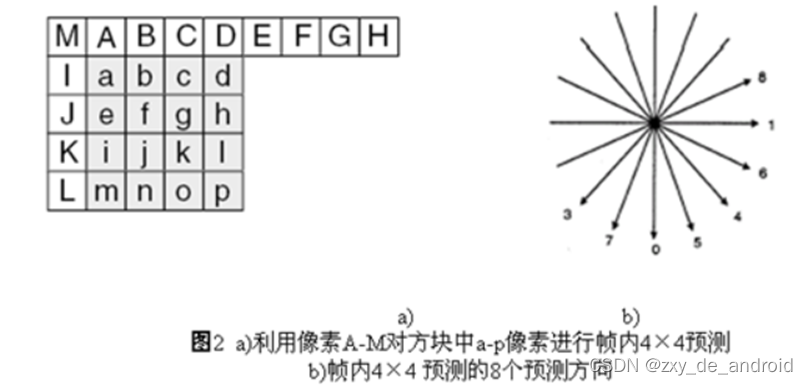
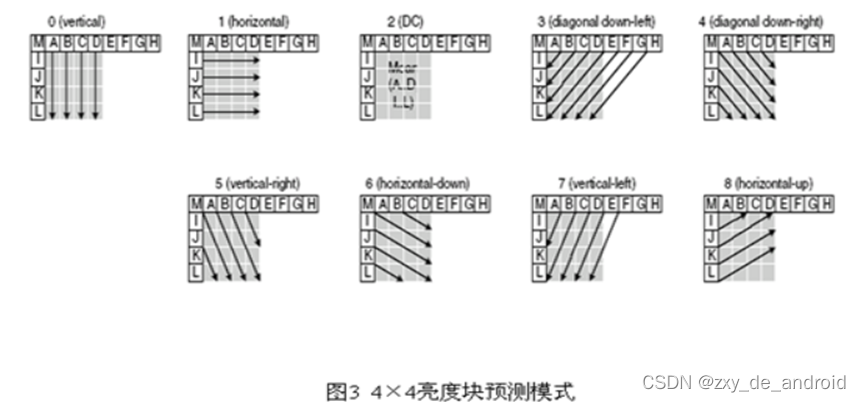
-
16×16亮度块4种预测模式
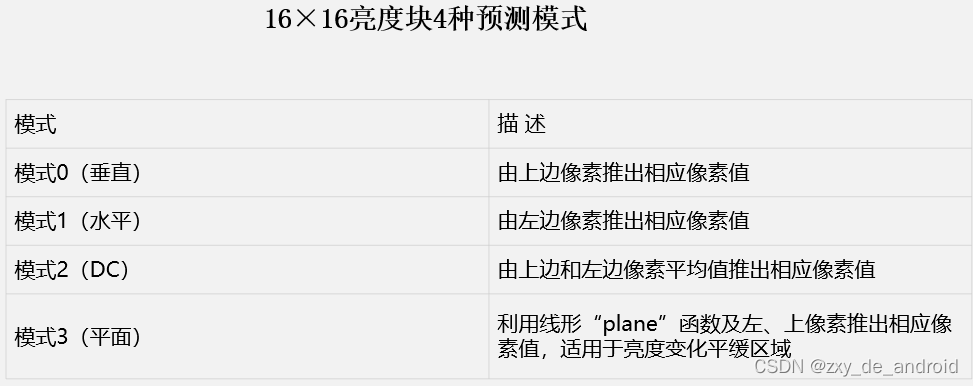
-
16×16亮度块预测模式
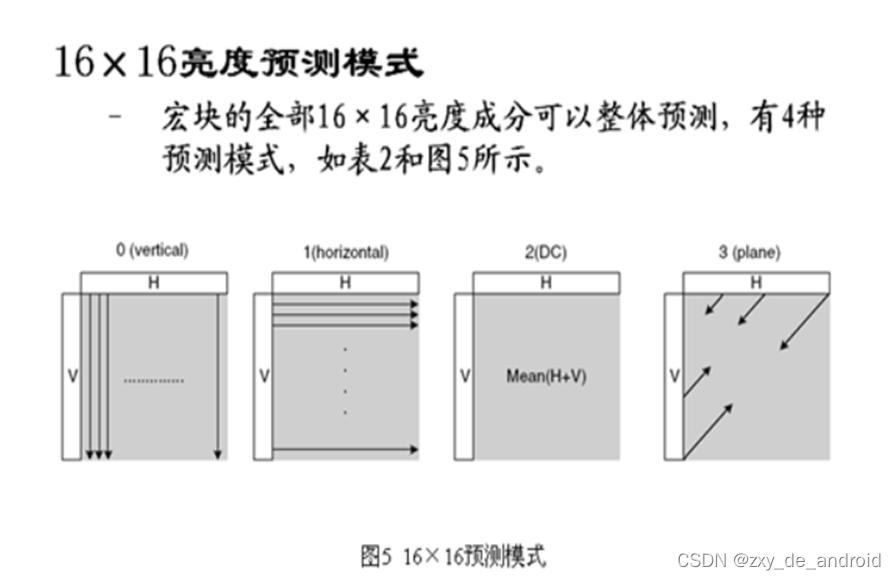

-
8×8色度块预测模式
8x8的色度块预测,对于色度块是亮度块的四分之一,也就是8x8的,那就只有一种了,预测模式也跟亮度16x16块的类似,有四种,只不过具体的序号不一样而已。是0代表DC,1代表horizontal,2代表vertical,3代表plane。
plane的算法和上面16x16的类似,只不过系数变了,而且两个色度块用的方式一定都是一样的。
帧内预测模式的选择
亮度和色度的帧内预测,都有多种预测策略,因此实际应用中要选择最优的帧内预测策略。
对于色度块预测,只能采用8x8的分块大小,只需要比较4中模式的代价(用RDO模型),选择代价最小的模式即可。
对于亮度块预测,可以采用16x16和4x4的块大小,所以需要先后计算出9中4x4预测模式的最小代价(RDO模型)和4中16x16预测模式的最小代价(SATD公式),然后从中选择较小的预测模式。
2 、帧间预测压缩
(1)、帧分组
-
帧分组
对于视频数据主要有两类数据冗余,一类是时间上的数据冗余,另一类是空间上的数据冗余。其中时间上的数据冗余是最大的。下面我们就先来说说视频数据时间上的冗余问题。
为什么说时间上的冗余是最大的呢?假设摄像头每秒抓取30帧,这30帧的数据大部分情况下都是相关联的。也有可能不止30帧的的数据,可能几十帧,上百帧的数据都是关联特别密切的。
对于这些关联特别密切的帧,其实我们只需要保存一帧的数据,其它帧都可以通过这一帧再按某种规则预测出来,所以说视频数据在时间上的冗余是最多的。
为了达到相关帧通过预测的方法来压缩数据,就需要将视频帧进行分组。那么如何判定某些帧关系密切,可以划为一组呢?我们来看一下例子,下面是捕获的一组运动的台球的视频帧,台球从右上角滚到了左下角

-
H264编码器会按顺序,每次取出两幅相邻的帧进行宏块比较,计算两帧的相似度。如下图:

-
通过宏块扫描与宏块搜索可以发现这两个帧的关联度是非常高的。进而发现这一组帧的关联度都是非常高的。因此,上面这几帧就可以划分为一组。其算法是:在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内,我们认为这样的图可以分到一组。
在这样一组帧中,经过编码后,我们只保留第一帖的完整数据,其它帧都通过参考上一帧计算出来。我们称第一帧为IDR/I帧,其它帧我们称为P/B帧,这样编码后的数据帧组我们称为GOP -
在H264编码器中将帧分组后,就要计算帧组内物体的运动矢量了。还以上面运动的台球视频帧为例,我们来看一下它是如何计算运动矢量的。
H264编码器首先按顺序从缓冲区头部取出两帧视频数据,然后进行宏块扫描。当发现其中一幅图片中有物体时,就在另一幅图的邻近位置(搜索窗口中)进行搜索。如果此时在另一幅图中找到该物体,那么就可以计算出物体的运动矢量了。下面这幅图就是搜索后的台球移动的位置。
-
通过上图中台球位置相差,就可以计算出台图运行的方向和距离。H264依次把每一帧中球移动的距离和方向都记录下来就成了下面的样子。

-
通过上图中台球位置相差,就可以计算出台图运行的方向和距离。H264依次把每一帧中球移动的距离和方向都记录下来就成了下面的样子。

-
运动矢量计算出来后,将相同部分(也就是绿色部分)减去,就得到了补偿数据。我们最终只需要将补偿数据进行压缩保存,以后在解码时就可以恢复原图了。压缩补偿后的数据只需要记录很少的一点数据。如下所示:

-
我们把运动矢量与补偿称为帧间压缩技术,它解决的是视频帧在时间上的数据冗余。
-
与I帧相似程度极高 达到95%以上 编码成B帧相似程度70%编码成P帧
(2)、DCT离散余弦变换
DCT将图像分成由不同频率组成的小块,然后进行量化。在量化过程中,舍弃高频分量,剩下的低频分量被保存下来用于后面的图像重建。
简单介绍一下整个图像压缩过程
- 将图像分解为8*8的图像块
- 将表示像素的RGB系统转换成YUV系统
- 然后从左至右,从上至下对每个图像块做DCT变换,舍弃高频分量,保留低频分量
- 对余下的图像块进行量化压缩,由压缩后的数据所组成的图像大大缩减了存储空间
- 解压缩时对每个图像块做DCT反转换(IDCT),然后重建一幅完整的图像
由于舍弃了某些频率的图像,所以最终呈现出来的图像清晰度会有差异,如图。
(3)、CABAC
上面的帧内压缩是属于有损压缩技术。也就是说图像被压缩后,无法完全复原。而CABAC属于无损压缩技术。
无损压缩技术大家最熟悉的可能就是哈夫曼编码了,给高频的词一个短码,给低频词一个长码从而达到数据压缩的目的。MPEG-2中使用的VLC就是这种算法,我们以 A-Z 作为例子,A属于高频数据,Z属于低频数据。看看它是如何做的。
(4)、I帧
I帧:关键帧,采用帧内压缩技术。你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)
I帧特点:
- 它是一个全帧压缩编码帧。它将全帧图像信息进行JPEG压缩编码及传输;
- 解码时仅用I帧的数据就可重构完整图像;
- I帧描述了图像背景和运动主体的详情;
- I帧不需要参考其他画面而生成;
- I帧是P帧和B帧的参考帧(其质量直接影响到同组中以后各帧的质量);
- I帧是帧组GOP的基础帧(第一帧),在一组中只有一个I帧;
- I帧不需要考虑运动矢量;
- I帧所占数据的信息量比较大。
(5)、P帧
P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。采用帧音间缩技术。P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧的画面差别的数据)
P帧特点:
- P帧是I帧后面相隔1~2帧的编码帧;
- P帧采用运动补偿的方法传送它与前面的I或P帧的差值及运动矢量(预测误差);
- 解码时必须将I帧中的预测值与预测误差求和后才能重构完整的P帧图像;
- P帧属于前向预测的帧间编码。它只参考前面最靠近它的I帧或P帧;
- P帧可以是其后面P帧的参考帧,也可以是其前后的B帧的参考帧;
- 由于P帧是参考帧,它可能造成解码错误的扩散;
- 由于是差值传送,P帧的压缩比较高。
(6)、B帧
B帧:双向参考帧,在压缩时,它即参考前而的帧,又参考它后面的帧。采用帧间压缩技术。B帧记录的是本帧与前后帧的差别(具体比较复杂,有4种情况),换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累~。
B帧特点:
- B帧是由前面的I或P帧和后面的P帧来进行预测的;
- B帧传送的是它与前面的I或P帧和后面的P帧之间的预测误差及运动矢量;
- B帧是双向预测编码帧;
- B帧压缩比最高,因为它只反映参考帧间运动主体的变化情况,预测比较准确;加大B帧的数量可以有效地提高视频数据的压缩比,但是在实时互动的环境下,过多的B帧会引起延时,因为B帧会过分的依赖于前后帧,在网络好的环境下,可以正常的传输帧,这样没有什么问题,但是在网络不好的时候,B帧会等待其他帧到来,会引起延时。
- B帧不是参考帧,不会造成解码错误的扩散。
(7)、IDR帧
-
IDR (Instantaneous Decoding Refresh)全称:即时解码刷新
-
I和IDR帧都是使用帧内预测的。它们都是同一个东西而已,在编码和解码中为了方便,要首个I帧和其他I帧区别开,所以才把第一个首个I帧叫IDR,这样就方便控制编码和解码流程。IDR帧的作用是立刻刷新,使错误不致传播,从IDR帧开始,重新算一个新的序列开始编码。而I帧不具有随机访问的能力,这个功能是由IDR承担。IDR会导致DPB(参考帧列表——这是关键所在)清空,而I不会。IDR图像一定是I图像,但I图像不一定是IDR图像。一个序列中可以有很多的I图像,I图像之后的图像可以引用I图像之间的图像做运动参考。一个序列中可以有很多的I图像,I图像之后的图象可以引用I图像之间的图像做运动参考。
对于IDR帧来说,在IDR帧之后的所有帧都不能引用任何IDR帧之前的帧的内容,与此相反,对于普通的I-帧来说,位于其之后的B-和P-帧可以引用位于普通I-帧之前的I-帧。从随机存取的视频流中,播放器永远可以从一个IDR帧播放,因为在它之后没有任何帧引用之前的帧。但是,不能在一个没有IDR帧的视频中从任意点开始播放,因为后面的帧总是会引用前面的帧。 -
I帧不用参考任何帧,但是之后的P帧和B帧是有可能参考这个I帧之前的帧的。IDR就不允许这样,例如:

-
作用:
H.264引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
(8)、GOP序列
一个序列就是一段内容差异不太大的图像编码后生成的一串数据流。当运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个 I 帧,然后一直 P 帧、B 帧了。当运动变化多时,可能一个序列就比较短了,比如就包含一个 I 帧和 3、4个P帧。
GOP:两个I帧之间是一个图像序列,在一个图像序列中只有一个I帧。如下图所示: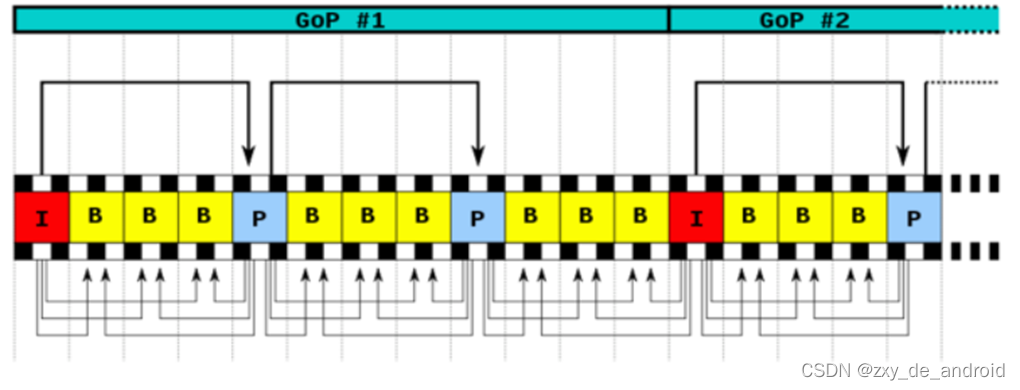
四 、H264分层
-
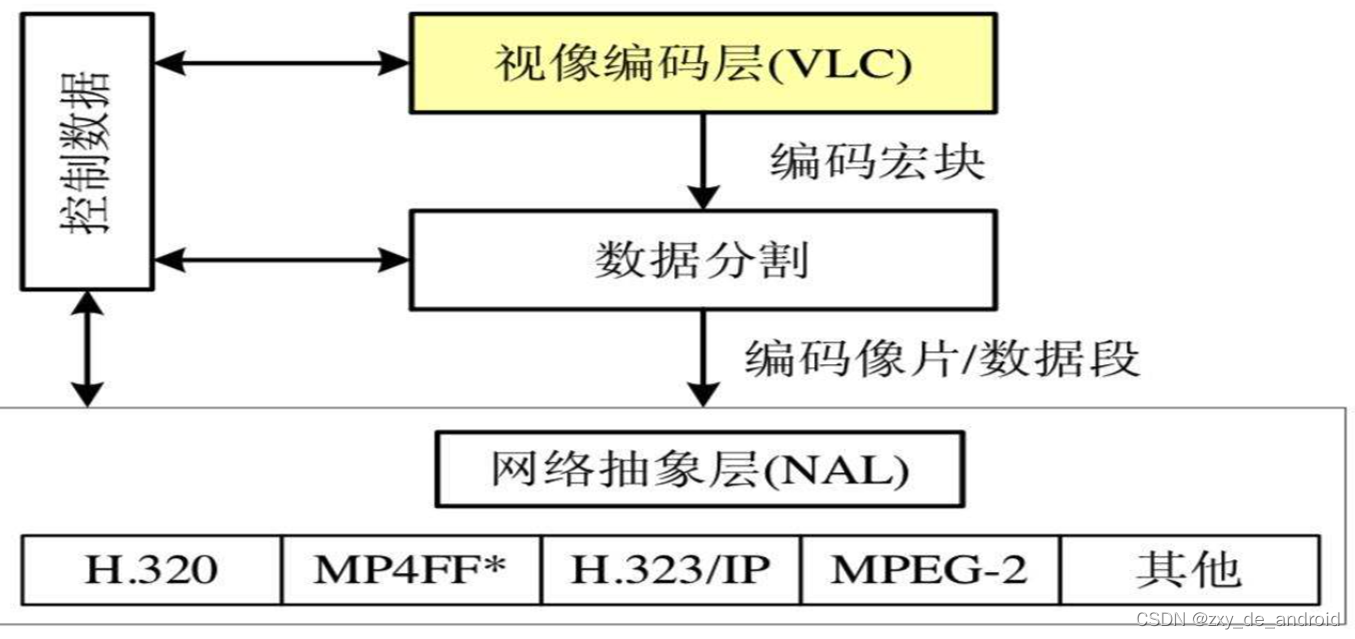
H264的主要目标是为了有高的视频压缩比和良好的网络亲和性,为了达成这两个目标,H264的解决方案是将系统框架分为两个层面,分别是视频编码层面(VCL)和网络抽象层面(NAL),如图
-
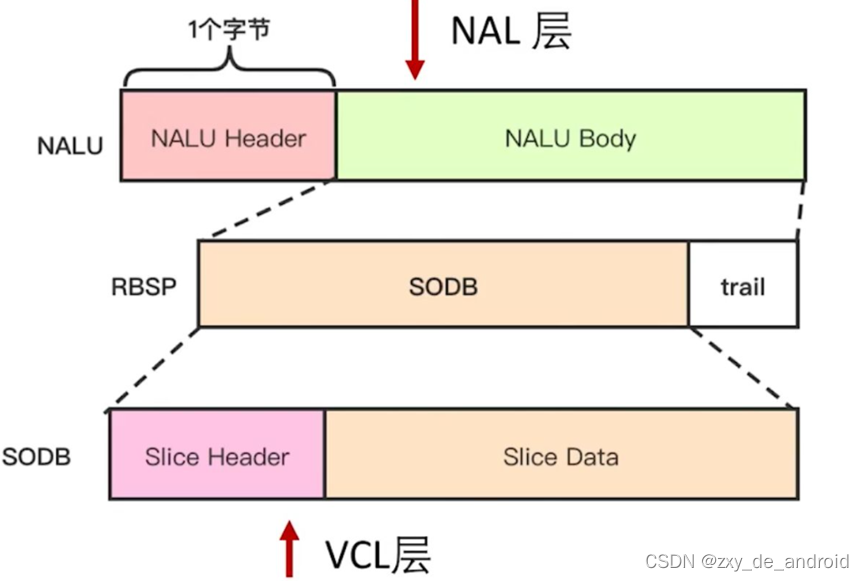
VLC层是对核心算法引擎、块、宏块及片的语法级别的定义,负责有效表示视频数据的内容,最终输出编码完的数据SODB;
-
NAL层定义了片级以上的语法级别(如序列参数集参数集和图像参数集,针对网络传输,后面会描述到),负责以网络所要求的恰当方式去格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。NAL层将SODB打包成RBSP然后加上NAL头组成一个NALU单元,具体NAL单元的组成也会在后面详细描述。
-
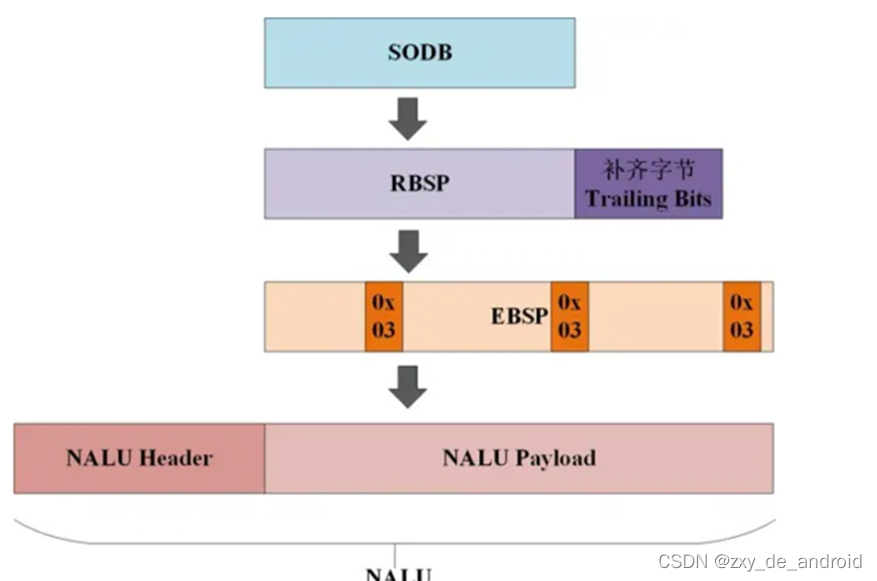
这里说一下SODB与RBSP的关联,具体结构如图所示:
SODB: 数据比特串,是编码后的原始数据;
RBSP: 原始字节序列载荷,是在原始编码数据后面添加了结尾比特,一个bit“1”和若干个比特“0”,用于字节对齐。
1 、VCL
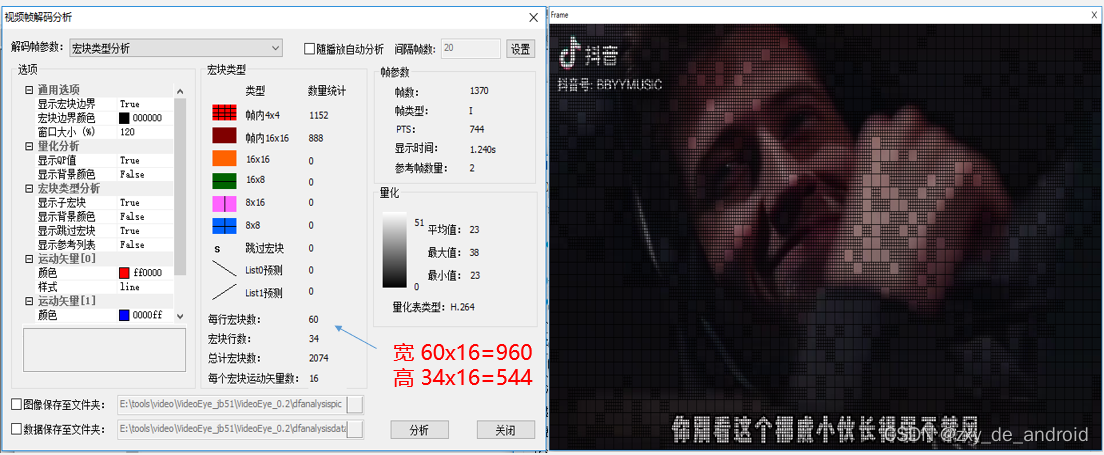
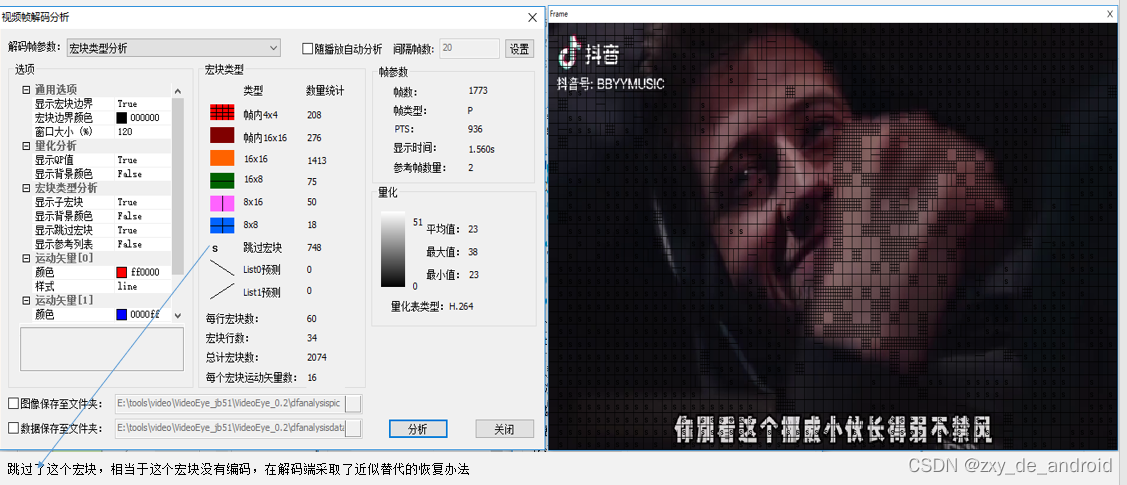
(1)、宏块解析
- H264的 NAL单元 与片,宏之间的联系
其实到这里可能就比较难理解了,为什么数据NAL单元中有这么多数据类型,这个SLICE又是什么东西,为什么不直接是编码后出来的 原始字节序列载荷,所以 我觉得在这里再讲述帧所细分的一些片和宏的概念应该是比较合适的,也是能够参照上下文更能理解这些概念的位置,又能给这些困惑做一个合理一点的解释,所以在此做一个描述:
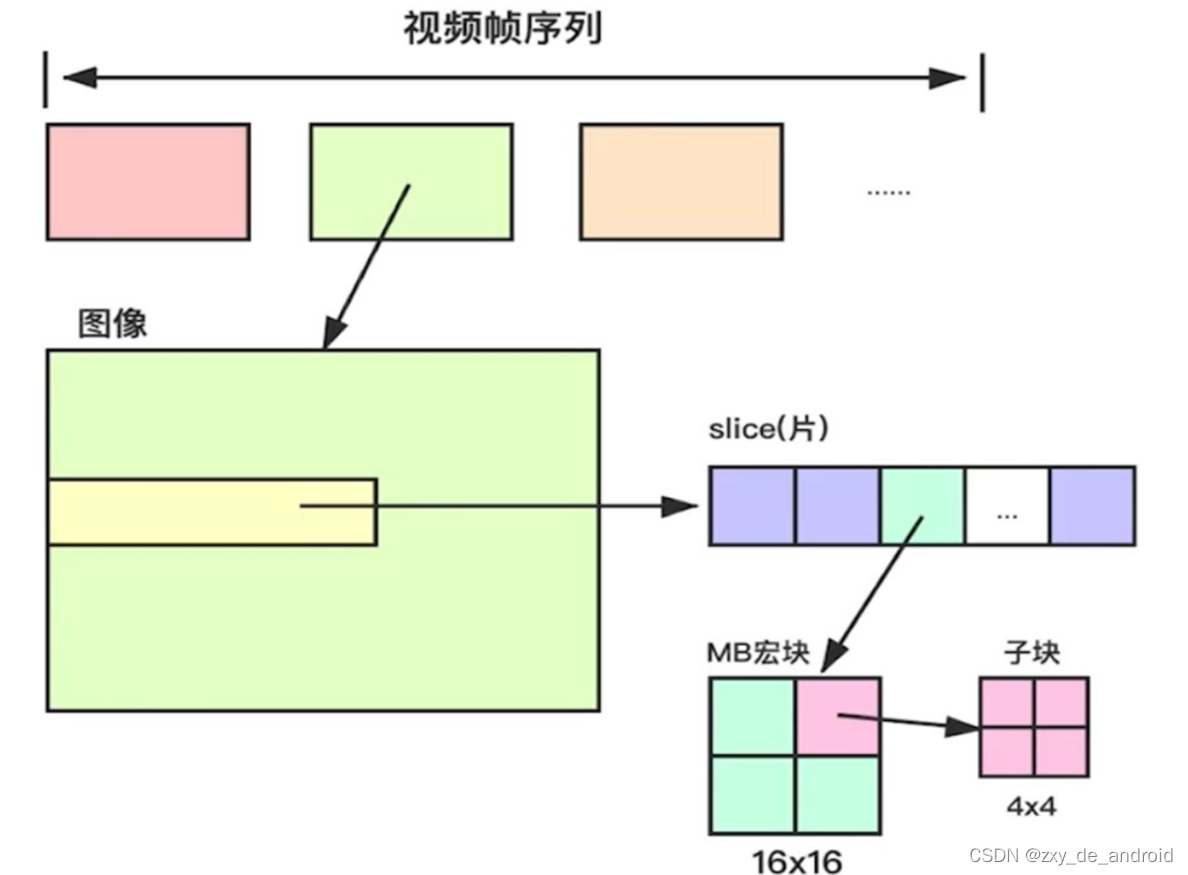
从数据层次角度来说,一幅原始的图片可以算作广义上的一帧,帧包含片组和片,片组由片来组成,片由宏块来组成。
H264中,以16x16的宏块为编码最小单元,一个宏块可以被分成多个4x4或8x8的子块,同一个宏块内,像素的相似程度会比较高;若16x16的宏块中,像素相差较大,那么就需要继续细分 - 视频帧序列
视频帧序列分析

- frame与slice、macroblock的关系
frame和宏块间的关系:
I帧只包含I宏块
P帧包含I宏块和P宏块
B帧包含I宏块、P宏块、B宏块
slice和宏块的关系:
I slice只包含I宏块
P slice包含P宏块和/或I宏块
B sliceB宏块和/或I宏块。
SP:包含P宏块和/或I宏块,用于不同编码流之间进行切换。
SI:包含SI宏块(一种特殊类型的帧内编码宏块),用于不同编码流之间进行切换。
I帧、B帧、P帧和对应类型的slice之间的关系:
当帧内slice全部为I像片时,则此帧为I帧
当全部为P slice或和I slice的组合时,则为P帧
当为B slice或和I、P slice的组合时,则为B帧
2 、NAL
- H264码流结构
我认为在具体讲述NAL单元前,十分有必要先了解一下H264的码流结构;在经过编码后的H264的码流如图4所示, 从图中我们需要得到一个概念,H264码流是由一个个的NAL单元组成,其中SPS、PPS、IDR和SLICE是NAL单元某一类型的数据。如下图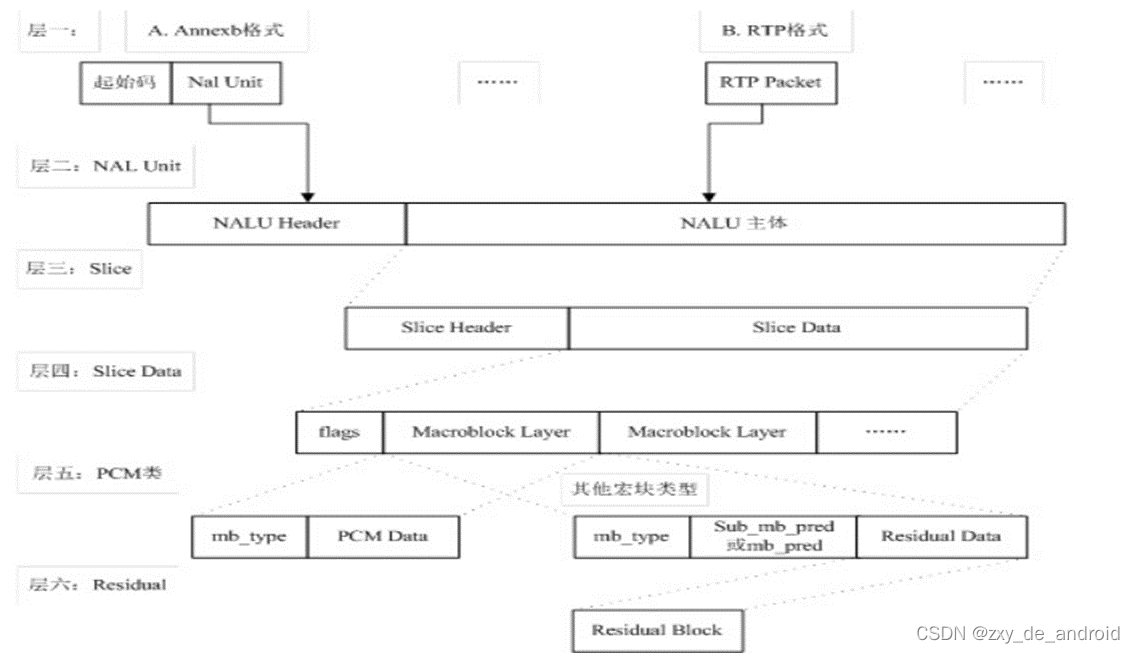
(1)、NAL头解析
-
NAL头的组成
NAL单元的头部是由forbidden_bit(1bit),nal_reference_bit(2bits)(优先级),nal_unit_type(5bits)(类型)三个部分组成的,组成如图6所示: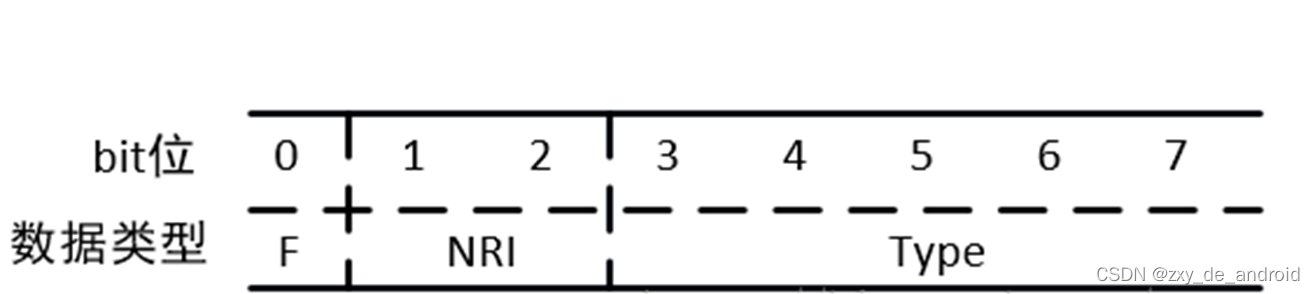
-
F(forbiden):禁止位,占用NAL头的第一个位,当禁止位值为1时表示语法错误;
-
NRI:参考级别,占用NAL头的第二到第三个位;值越大,该NAL越重要。
-
NAL单元数据类型
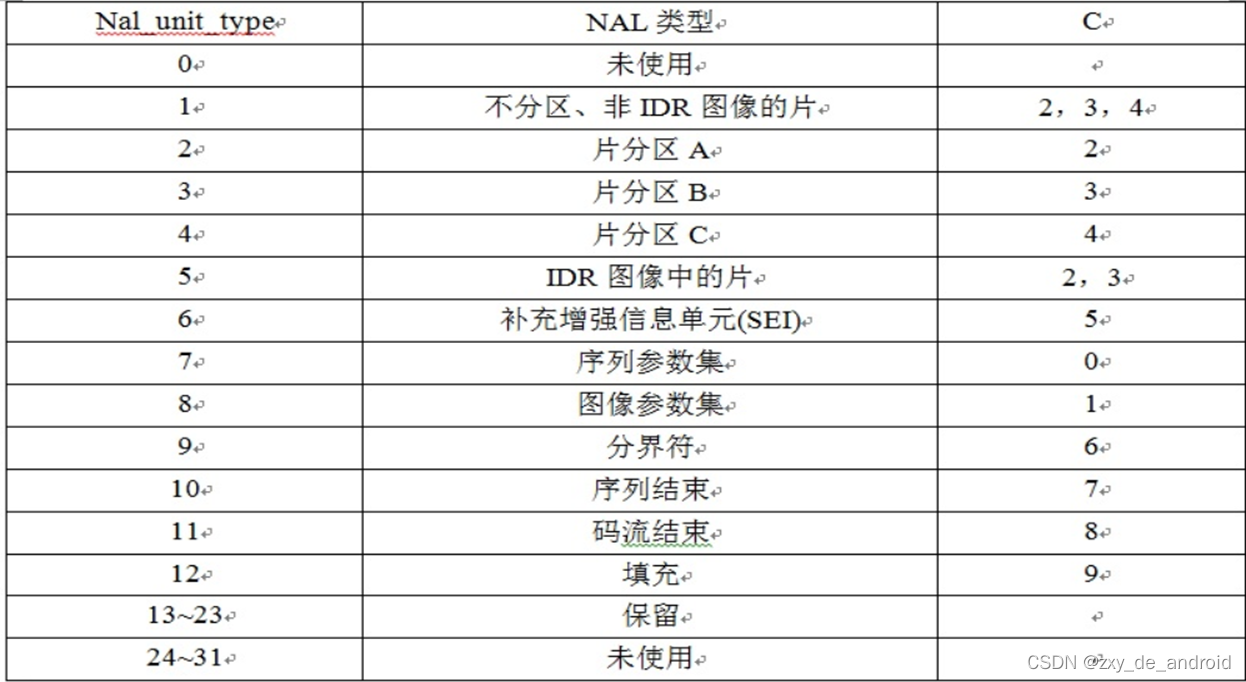
NAL类型主要就是下面图中这些类型每个类型都有特殊的作用
-
NAL头解析
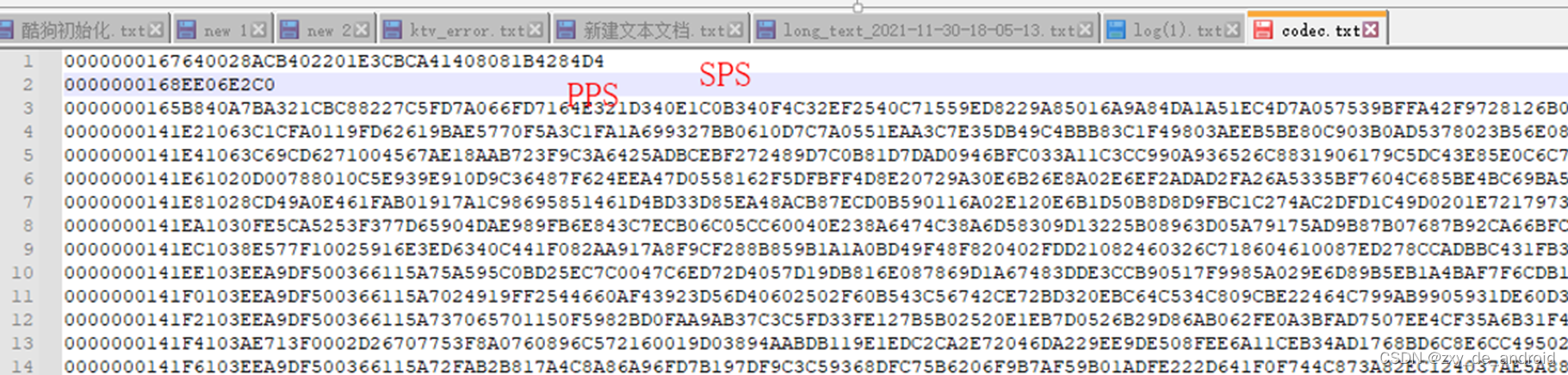 0X67 二进制 0110 0111:禁止位:0 ,NRI:3, TYPE:7 ,对应类型 SPS
0X67 二进制 0110 0111:禁止位:0 ,NRI:3, TYPE:7 ,对应类型 SPS
0X68 二进制 0110 1000:禁止位:0 ,NRI:3, TYPE:8 ,对应类型 PPS
0X65 二进制 0110 0101:禁止位:0 ,NRI:3, TYPE:5 ,对应类型 IDR帧
0X41 二进制 0100 0001:禁止位:0 ,NRI:2, TYPE:1 ,对应类型 非IDR帧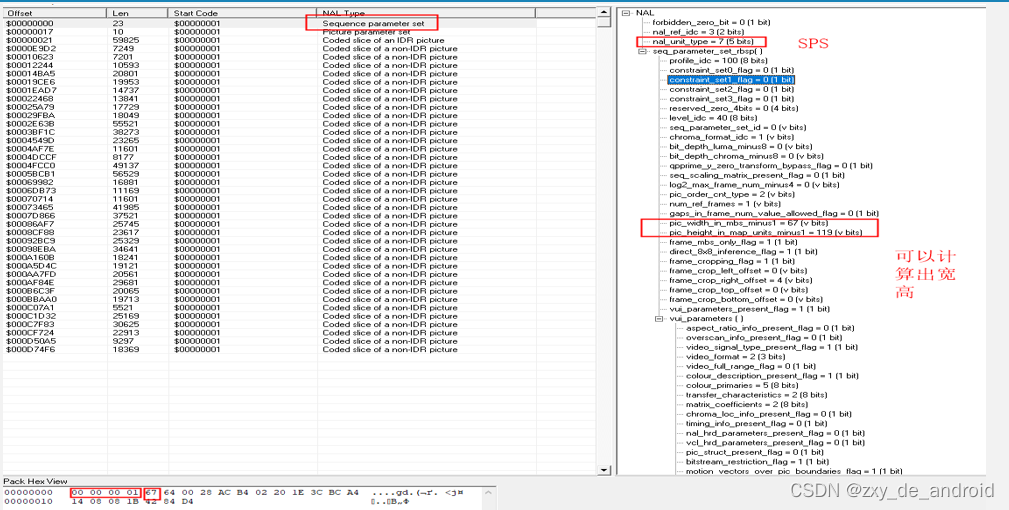
-
I/P/B帧,合起来介绍的原因是,他们是依据VLC的slice区分的,这块太复杂不做讲解,另一个原因是就算不了解slice、macroblock也不影响对H264格式的理解。
-
IDR帧。I帧的一种,告诉解码器,之前依赖的解码参数集合(接下来要出现的SPS\PPS等)可以被刷新了。
-
SEI,英文全称Supplemental Enhancement Information,翻译为“补充增强信息”,提供了向视频码流中加入额外信息的方法(这里可以放自定义的数据)。这部分参数可作为H264的比特流数据而被传输,每一个SEI信息被封装成一个NAL单元。SEI对于解码器来说可能是有用的,但是对于基本的解码过程来说,并不是必须的。
-
SPS,全称Sequence Paramater Set,翻译为“序列参数集”。SPS中保存了一组编码视频序列(Coded Video Sequence)的全局参数。因此该类型保存的是和编码序列相关的参数。SPS对如标识符、帧数以及参考帧数目、解码图像尺寸和帧场模式等 解码参数进行标识记录。
-
PPS,全称Picture Paramater Set,翻译为“图像参数集”。该类型保存了整体图像相关的参数。PPS对如熵编码类型、有效参考图像的数目和初始化等解码参数进行标志记录。
-
AU分隔符,AU全称Access Unit,它是一个或者多个NALU的集合,代表了一个完整的帧。
AUD
一般文档没有对AUD进行描叙,其实这是一个帧开始的标志,字节顺序为:00 00 00 01 09 f0
从结构上看,有start code, 所以确实是一个NALU,类型09在H264定义里就是AUD(分割器)。大部分播放器可以在没有AUD的情况下正常播放。
紧随AUD,一般是SPS/PPS/SEI/IDR的组合或者简单就是一个SLICE,也就是一个帧的开始。像Flash这样的播放器,每次需要一个完整的帧数据,那么把2个AUD之间的数据按照格式打包给播放器就可以了。
H.264编码时,在每个NAL前添加起始码 0x000001,解码器在码流中检测到起始码,当前NAL结束。为了防止NAL内部出现0x000001的数据,h.264又提出’防止竞争 emulation prevention"机制,在编码完一个NAL时,如果检测出有连续两个0x00字节,就在后面插入一个0x03。当解码器在NAL内部检测到0x000003的数据,就把0x03抛弃,恢复原始数据。
0x000000 >>>>>> 0x00000300
0x000001 >>>>>> 0x00000301
0x000002 >>>>>> 0x00000302
0x000003 >>>>>> 0x00000303
总的来说H264的码流的打包方式有两种,一种为annex-b byte stream format 的格式,这个是绝大部分编码器的默认输出格式,就是每个帧的开头的3~4个字节是H264的start_code,0x00000001或者0x000001。
另一种是原始的NAL打包格式,就是开始的若干字节(1,2,4字节)是NAL的长度,而不是start_code,此时必须借助某个全局的数据来获得编 码器的profile,level,PPS,SPS等信息才可以解码。
熵编码:
利用信源的统计特性进行码率压缩的编码,称之为熵编码,也叫做统计特性
基本思想:使前后的码字之间尽量更加随机,减少前后相关性,更加接近其信源的香农熵;
熵编码具有消除数据之间统计冗余的功能,在编码端作为最后一道工序,将语法元素写入输出码流
H264中熵编码主要采用两种类型:CAVLA和CABAC。
(2)、SPS解析
- pic_width_in_mbs_minus1加1是指以宏块为单元的每个解码图像的宽度。
- pic_height_in_map_units_minus1 的语义依赖于变量frame_mbs_only_flag,规定如下:-— 如果 frame_mbs_only_flag 等于0,
- pic_height_in_map_units_minus1加1就表示以宏块为单位的一场的高度。-— 否则(frame_mbs_only_flag等于1),pic_height_in_map_units_minus1加1就表示以宏块为单位的一帧的高度。变量 FrameHeightInMbs 由下列公式得出:FrameHeightInMbs = ( 2 – frame_mbs_only_flag ) * PicHeightInMapUnits。
- mb_adaptive_frame_field_flag 等于0表示在一个图像的帧和场宏块之间没有交换。mb_adaptive_frame_field_flag 等于1表示在帧和帧内的场宏块之间可能会有交换。当mb_adaptive_frame_field_flag没有特别规定时,默认其值为0。
- direct_8x8_inference_flag 表示在某节中规定的B_Skip、B_Direct_16x16和B_Direct_8x8亮度运动矢量的计算过程使用的方法。当frame_mbs_only_flag 等于0时direct_8x8_inference_flag 应等于1。
- frame_cropping_flag 等于1表示帧剪切偏移参数遵从视频序列参数集中的下一个值。frame_cropping_flag 等于0表示不存在帧剪切偏移参数。
- vui_parameters_present_flag 等于1 表示存在如附录E 提到的vui_parameters( ) 语法结构。vui_parameters_present_flag 等于0表示不存在如附录E提到的vui_parameters( ) 语法结构。
- profile_idc和level_idc是指比特流所遵守的配置和级别。
- constraint_set0_flag 等于1是指比特流遵从某节中的所有规定。
- constraint_set0_flag 等于0是指该比特流可以遵从也可以不遵从某节中的所有规定。当profile_idc等于100、110、122或144时,constraint_set0_flag、constraint_set1_flag和constraint_set2_flag都应等于0。
- log2_max_frame_num_minus4的值应在0-12范围内(包括0和12),这个句法元素主要是为读取另一个句法元素 frame_num 服务的,frame_num 是最重要的句法元素之一,它标识所属图像的解码顺序 。这个句法元素同时也指明了 frame_num 的所能达到的最大值: MaxFrameNum = 2*exp( log2_max_frame_num_minus4 + 4 ) 。
- pic_order_cnt_type 是指解码图像顺序的计数方法。pic_order_cnt_type 的取值范围是0到2(包括0和2)。
- log2_max_pic_order_cnt_lsb_minus4表示用于某节规定的图像顺序数解码过程中的变量MaxPicOrderCntLsb的值,
- num_ref_frames规定了可能在视频序列中任何图像帧间预测的解码过程中用到的短期参考帧和长期参考帧、互补参考场对以及不成对的参考场的最大数量。num_ref_frames 的取值范围应该在0到MaxDpbSize。
- gaps_in_frame_num_value_allowed_flag 表示某节给出的frame_num 的允许值以及在某节给出的frame_num 值之间存在推测的差异的情况下进行的解码过程。
(3)、PPS解析
- seq_parameter_set_id是指活动的序列参数集。变量seq_parameter_set_id的值应该在0到31的范围内(包括0和31)。
- entropy_coding_mode_flag 用于选取语法元素的熵编码方式,在语法表中由两个标识符代表,具体如下:如果entropy_coding_mode_flag 等于0,那么采用语法表中左边的描述符所指定的方法。
- pic_order_present_flag等于1 表示与图像顺序数有关的语法元素将出现于条带头中,pic_order_present_flag 等于0表示条带头中不会出现与图像顺序数有关的语法元素。
- num_slice_groups_minus1加1表示一个图像中的条带组数。当num_slice_groups_minus1 等于0时,图像中所有的条带属于同一个条带组。
- num_ref_idx_l0_active_minus1表示参考图像列表0 的最大参考索引号,该索引号将用来在一幅图像中num_ref_idx_active_override_flag 等于0 的条带使用列表0 预测时,解码该图像的这些条带。当MbaffFrameFlag等于1时,num_ref_idx_l0_active_minus1 是帧宏块解码的最大索引号值,而2 *num_ref_idx_l0_active_minus1 + 1是场宏块解码的最大索引号值。num_ref_idx_l0_active_minus1 的值应该在0到31的范围内(包括0和31)。
- weighted_pred_flag等于0表示加权的预测不应用于P和SP条带。weighted_pred_flag等于1表示在P和SP条带中应使用加权的预测。
- weighted_bipred_idc等于0表示B条带应该采用默认的加权预测。weighted_bipred_idc等于1表示B条带应该采用具体指明的加权预测。weighted_bipred_idc 等于2表示B 条带应该采用隐含的加权预测。weighted_bipred_idc 的值应该在0到2之间(包括0和2)。
- pic_init_qp_minus26表示每个条带的SliceQPY 初始值减26。当解码非0值的slice_qp_delta 时,该初始值在条带层被修正,并且在宏块层解码非0 值的mb_qp_delta 时进一步被修正。pic_init_qp_minus26 的值应该在-(26 + QpBdOffsetY ) 到 +25之间(包括边界值)。pic_init_qs_minus26表示在SP 或SI 条带中的所有宏块的SliceQSY 初始值减26。当解码非0 值的slice_qs_delta 时,该初始值在条带层被修正。pic_init_qs_minus26 的值应该在-26 到 +25之间(包括边界值)。
- chroma_qp_index_offset表示为在QPC 值的表格中寻找Cb色度分量而应加到参数QPY 和 QSY 上的偏移。chroma_qp_index_offset的值应在-12 到 +12范围内(包括边界值)。
- deblocking_filter_control_present_flag等于1 表示控制去块效应滤波器的特征的一组语法元素将出现在条带头中。deblocking_filter_control_present_flag 等于0 表示控制去块效应滤波器的特征的一组语法元素不会出现在条带头中,并且它们的推定值将会生效。
- constrained_intra_pred_flag等于0 表示帧内预测允许使用残余数据,且使用帧内宏块预测模式编码的宏块的预测可以使用帧间宏块预测模式编码的相邻宏块的解码样值。constrained_intra_pred_flag 等于1 表示受限制的帧内预测,在这种情况下,使用帧内宏块预测模式编码的宏块的预测仅使用残余数据和来自I或SI宏块类型的解码样值。
- redundant_pic_cnt_present_flag等于0 表示redundant_pic_cnt 语法元素不会在条带头、图像参数集中指明(直接或与相应的数据分割块A关联)的数据分割块B和数据分割块C中出现。redundant_pic_cnt_present_flag等于1表示redundant_pic_cnt 语法元素将出现在条带头、图像参数集中指明(直接或与相应的数据分割块A关联)的数据分割块B和数据分割块C中。
学习笔记,不足之处请帮忙指出,谢谢














 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









