







摘要:
问题:
3DMRI 脑肿瘤分割
方法:
描述了一个编码器解码器的结构,由于训练数据集大小有限,添加变分自动编码器分支以重建输入图像本身,以便使共享解码器正规化并对解码器层施加额外约束。
结果:
2018年挑战第一名
介绍:
前面描述的是脑肿瘤等级,以及介绍数据集
贡献:
1.在这项工作中,我们描述了我们用于多模式3D MRI的体积3D脑肿瘤分割的语义分割方法,该方法赢得了BraTS 2018挑战。
2.我们遵循CNN的编码器 - 解码器结构,使用非对称大型编码器来提取深度图像特征,并且解码器部分重建密集分割掩模。
3.我们还将变分自动编码器(VAE)分支添加到网络以与分段一起重建输入图像,以便使共享编码器正规化。 在推理时,仅使用主分段编码 - 解码器部分。
相关工作:
2017年brats:
1.讲到了EMMA,brats2017的第一名,
2.讲到了Wang等人用的逐级分割网络,第二名(大的编码器,和小的解码器,跟本文类似)
2018年brats:
1.Isensee et al. [12]第二名(证明了只要对Unet进行一个小的修改,就可以得到一个有竞争力的结果)
2.McKinly et al. [17] and Zhou et al. [23]共享第三名
共同点:
这些作者使用了128x128x128的块,batchsize为2,另外这些作者还使用了自己的一些额外的数据集,这些对enhancing部分有一定的提升
我们的网络:
我们使用的块比他们的都大,160x192x128,batchsize为1为了适应GPU的内存,我们输出3个肿瘤的子区域,直接用sigmoid,我们不用几个网络的集成,或者用softmax进行多分类,我们用一个额外的分支去正则化解码器,我们没有使用额外的训练集.
方法:
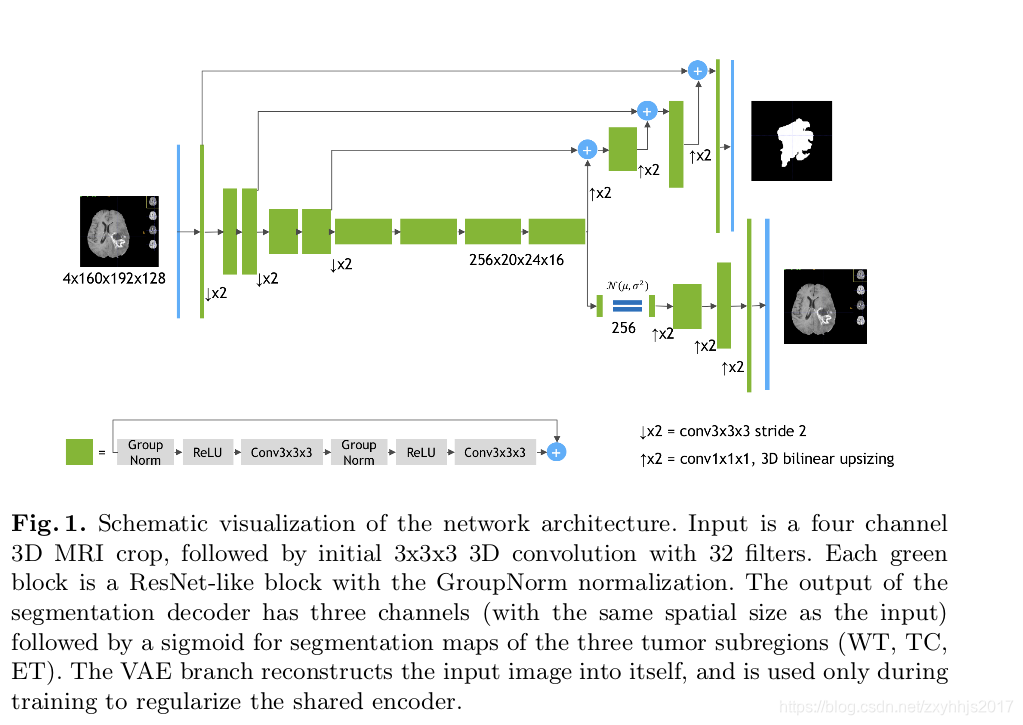
整体描述:
使用了重编码器,小的解码器来分割,还加入了一个重建图像的解码器(用来让编码器更好的提取特征,这里不是特别懂,为什么加重建就能更好的提起特征呢?不一定吧,这个多任务学习应该是它自己试出来的吧)
编码器部分:
使用了Resnet的跳跃连接层,每两个卷积层,使用一次残差块,后面加上relu和 group normalization。我们遵循常见的CNN方法逐步缩小图像尺寸(2倍的下采样),同时将特征宽度增加2,为了缩小尺寸,所有卷积均为3x3x3,初始滤波器数等于32.编码器最后的特征大小为256x20x24x16,并且在空间上比输入图像小8倍。
解码器部分:
解码器结构类似于编码器结构,但是都是单个block(指的应该不是像解码器那样,两个卷积块加残差组成一个block)。 每个解码器将特征数量减少2倍(使用1x1x1卷积)并将空间维度加倍(使用3D双线性上采样),然后加上编码器的输出(feature map大小相等的层)。 解码器的末端具有与原始图像相同的空间大小,并且特征的数量等于初始输入特征大小,接着是1x1x1卷积成3个通道和Sigmoid函数(应该是3个通道,每个通道对应一个sigmoid值,最后判断哪个概率最大选哪个)。
变分解码器部分(图像重建部分):
从编码器末端输出开始,我们首先将输入减少到256的低维空间(计算出来均值方差,128表示平均值,128表示std)。然后,从具有给定均值和标准的高斯分布中抽取样本,并且 按照与解码器相同的架构重建为输入图像维度,不使用来自编码器的跳跃连接。 VAE部件结构如表1所示。

LOSS:
loss使用的是分割损失加L2正则化,加高斯分布的KL散度如下图所示:
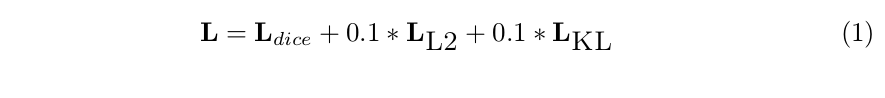
结果以及实验设置:
数据集:
Brats2018, 285个样本(210HGG和75LGG),大小240x240x155
测试集:
191个样本
类别:the enhancing tumor, the peritumoral edema, and the necrotic and non-enhancing tumor core.(3类)
预处理以及优化详见原文:https://arxiv.org/abs/1810.11654v1
训练:
- 随机采样160x192x128,确保大部分图像内容包括在里面,
- 多模型集成:(与2017年EMMAl类似,采用了其中的方法)
- 沿着3D轴做镜像翻转:
- 平均8个翻转的分割概率,
- 最后集成了10个模型,得到最后的结果
这么做确实有提升(1%)
实验结果:
验证集:
测试集:

时间:
- 每一个epoch(285个样本),花费时间9分钟 显卡为(NVIDIA Tesla V100 32GB).训练300个epoch需要两天时间.
- 如果在NVIDIA DGX-1服务器上训练,(包括8块V100),只需要6个小时,比单模型快了7.8倍
- 测试的时候0.4秒一个样本














 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









